前言
哈喽,大家好,我是asong;前几天逛github发现了一个有趣的并发库-conc,其目标是:
- 更难出现goroutine泄漏
- 处理panic更友好
- 并发代码可读性高
从简介上看主要封装功能如下:
- 对
waitGroup进行封装,避免了产生大量重复代码,并且也封装recover,安全性更高 - 提供
panics.Catcher封装recover逻辑,统一捕获panic,打印调用栈一些信息 - 提供一个并发执行任务的
worker池,可以控制并发度、goroutine可以进行复用,支持函数签名,同时提供了stream方法来保证结果有序 - 提供
ForEach、map方法优雅的处理切片
接下来就区分模块来介绍一下这个库;
仓库地址:https://github.com/sourcegraph/conc
Go语言标准库有提供sync.waitGroup控制等待goroutine,我们一般会写出如下代码:
func main(){
var wg sync.WaitGroup
for i:=0; i < 10; i++{
wg.Add(1)
go func() {
defer wg.Done()
defer func() {
// recover panic
err := recover()
if err != nil {
fmt.Println(err)
}
}
// do something
handle()
}
}
wg.Wait()
}上述代码我们需要些一堆重复代码,并且需要单独在每一个func中处理recover逻辑,所以conc库对其进行了封装,代码简化如下:
func main() {
wg := conc.NewWaitGroup()
for i := 0; i < 10; i++ {
wg.Go(doSomething)
}
wg.Wait()
}
func doSomething() {
fmt.Println("test")
}conc库封装也比较简单,结构如下:
type WaitGroup struct {
wg sync.WaitGroup
pc panics.Catcher
}其自己实现了Catcher类型对recover逻辑进行了封装,封装思路如下:
type Catcher struct {
recovered atomic.Pointer[RecoveredPanic]
}recovered是原子指针类型,RecoveredPanic是捕获的recover封装,封装了堆栈等信息:
type RecoveredPanic struct {
// The original value of the panic.
Value any
// The caller list as returned by runtime.Callers when the panic was
// recovered. Can be used to produce a more detailed stack information with
// runtime.CallersFrames.
Callers []uintptr
// The formatted stacktrace from the goroutine where the panic was recovered.
// Easier to use than Callers.
Stack []byte
}提供了Try方法执行方法,只会记录第一个panic的goroutine信息:
func (p *Catcher) Try(f func()) {
defer p.tryRecover()
f()
}
func (p *Catcher) tryRecover() {
if val := recover(); val != nil {
rp := NewRecoveredPanic(1, val)
// 只会记录第一个panic的goroutine信息
p.recovered.CompareAndSwap(nil, &rp)
}
}提供了Repanic()方法用来重放捕获的panic:
func (p *Catcher) Repanic() {
if val := p.Recovered(); val != nil {
panic(val)
}
}
func (p *Catcher) Recovered() *RecoveredPanic {
return p.recovered.Load()
}waitGroup对此也分别提供了Wait()、WaitAndRecover()方法:
func (h *WaitGroup) Wait() {
h.wg.Wait()
// Propagate a panic if we caught one from a child goroutine.
h.pc.Repanic()
}
func (h *WaitGroup) WaitAndRecover() *panics.RecoveredPanic {
h.wg.Wait()
// Return a recovered panic if we caught one from a child goroutine.
return h.pc.Recovered()
}wait方法只要有一个goroutine发生panic就会向上抛出panic,比较简单粗暴;
waitAndRecover方法只有有一个goroutine发生panic就会返回第一个recover的goroutine信息;
总结:conc库对waitGrouop的封装总体是比较不错的,可以减少重复的代码;
worker池
conc提供了几种类型的worker池:
- ContextPool:可以传递context的pool,若有goroutine发生错误可以cancel其他goroutine
- ErrorPool:通过参数可以控制只收集第一个error还是所有error
- ResultContextPool:若有goroutine发生错误会cancel其他goroutine并且收集错误
- RestultPool:收集work池中每个任务的执行结果,并不能保证顺序,保证顺序需要使用stream或者iter.map;
我们来看一个简单的例子:
import "github.com/sourcegraph/conc/pool"
func ExampleContextPool_WithCancelOnError() {
p := pool.New().
WithMaxGoroutines(4).
WithContext(context.Background()).
WithCancelOnError()
for i := 0; i < 3; i++ {
i := i
p.Go(func(ctx context.Context) error {
if i == 2 {
return errors.New("I will cancel all other tasks!")
}
<-ctx.Done()
return nil
})
}
err := p.Wait()
fmt.Println(err)
// Output:
// I will cancel all other tasks!
}在创建pool时有如下方法可以调用:
p.WithMaxGoroutines()配置pool中goroutine的最大数量p.WithErrors:配置pool中的task是否返回errorp.WithContext(ctx):配置pool中运行的task当遇到第一个error要取消p.WithFirstError:配置pool中的task只返回第一个errorp.WithCollectErrored:配置pool的task收集所有error
pool的基础结构如下:
type Pool struct {
handle conc.WaitGroup
limiter limiter
tasks chan func()
initOnce sync.Once
}limiter是控制器,用chan来控制goroutine的数量:
type limiter chan struct{}
func (l limiter) limit() int {
return cap(l)
}
func (l limiter) release() {
if l != nil {
<-l
}
}pool的核心逻辑也比较简单,如果没有设置limiter,那么就看有没有空闲的worker,否则就创建一个新的worker,然后投递任务进去;
如果设置了limiter,达到了limiter worker数量上限,就把任务投递给空闲的worker,没有空闲就阻塞等着;
func (p *Pool) Go(f func()) {
p.init()
if p.limiter == nil {
// 没有限制
select {
case p.tasks <- f:
// A goroutine was available to handle the task.
default:
// No goroutine was available to handle the task.
// Spawn a new one and send it the task.
p.handle.Go(p.worker)
p.tasks <- f
}
} else {
select {
case p.limiter <- struct{}{}:
// If we are below our limit, spawn a new worker rather
// than waiting for one to become available.
p.handle.Go(p.worker)
// We know there is at least one worker running, so wait
// for it to become available. This ensures we never spawn
// more workers than the number of tasks.
p.tasks <- f
case p.tasks <- f:
// A worker is available and has accepted the task.
return
}
}
}这里work使用的是一个无缓冲的channel,这种复用方式很巧妙,如果goroutine执行很快避免创建过多的goroutine;
使用pool处理任务不能保证有序性,conc库又提供了Stream方法,返回结果可以保持顺序;
Stream
Steam的实现也是依赖于pool,在此基础上做了封装保证结果的顺序性,先看一个例子:
func ExampleStream() {
times := []int{20, 52, 16, 45, 4, 80}
stream := stream2.New()
for _, millis := range times {
dur := time.Duration(millis) * time.Millisecond
stream.Go(func() stream2.Callback {
time.Sleep(dur)
// This will print in the order the tasks were submitted
return func() { fmt.Println(dur) }
})
}
stream.Wait()
// Output:
// 20ms
// 52ms
// 16ms
// 45ms
// 4ms
// 80ms
}stream的结构如下:
type Stream struct {
pool pool.Pool
callbackerHandle conc.WaitGroup
queue chan callbackCh
initOnce sync.Once
}queue是一个channel类型,callbackCh也是channel类型 - chan func():
type callbackCh chan func()
在提交goroutine时按照顺序生成callbackCh传递结果:
func (s *Stream) Go(f Task) {
s.init()
// Get a channel from the cache.
ch := getCh()
// Queue the channel for the callbacker.
s.queue <- ch
// Submit the task for execution.
s.pool.Go(func() {
defer func() {
// In the case of a panic from f, we don't want the callbacker to
// starve waiting for a callback from this channel, so give it an
// empty callback.
if r := recover(); r != nil {
ch <- func() {}
panic(r)
}
}()
// Run the task, sending its callback down this task's channel.
callback := f()
ch <- callback
})
}
var callbackChPool = sync.Pool{
New: func() any {
return make(callbackCh, 1)
},
}
func getCh() callbackCh {
return callbackChPool.Get().(callbackCh)
}
func putCh(ch callbackCh) {
callbackChPool.Put(ch)
}ForEach和map
ForEach
conc库提供了ForEach方法可以优雅的并发处理切片,看一下官方的例子:
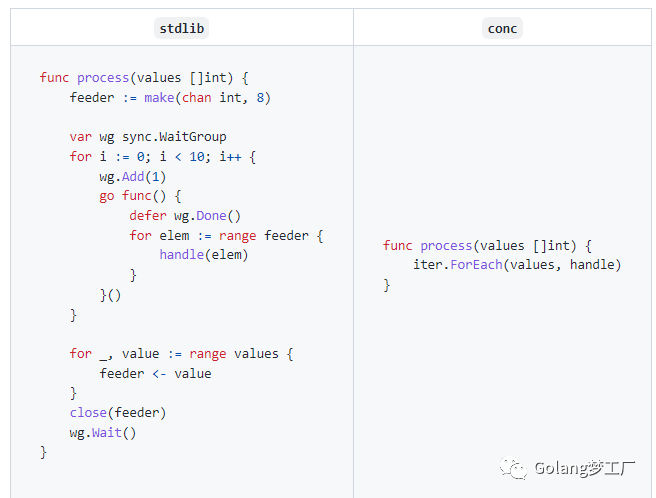
conc库使用泛型进行了封装,我们只需要关注handle代码即可,避免冗余代码,我们自己动手写一个例子:
func main() {
input := []int{1, 2, 3, 4}
iterator := iter.Iterator[int]{
MaxGoroutines: len(input) / 2,
}
iterator.ForEach(input, func(v *int) {
if *v%2 != 0 {
*v = -1
}
})
fmt.Println(input)
}ForEach内部实现为Iterator结构及核心逻辑如下:
type Iterator[T any] struct {
MaxGoroutines int
}
func (iter Iterator[T]) ForEachIdx(input []T, f func(int, *T)) {
if iter.MaxGoroutines == 0 {
// iter is a value receiver and is hence safe to mutate
iter.MaxGoroutines = defaultMaxGoroutines()
}
numInput := len(input)
if iter.MaxGoroutines > numInput {
// No more concurrent tasks than the number of input items.
iter.MaxGoroutines = numInput
}
var idx atomic.Int64
// 通过atomic控制仅创建一个闭包
task := func() {
i := int(idx.Add(1) - 1)
for ; i < numInput; i = int(idx.Add(1) - 1) {
f(i, &input[i])
}
}
var wg conc.WaitGroup
for i := 0; i < iter.MaxGoroutines; i++ {
wg.Go(task)
}
wg.Wait()
}可以设置并发的goroutine数量,默认取的是GOMAXPROCS ,也可以自定义传参;
并发执行这块设计的很巧妙,仅创建了一个闭包,通过atomic控制idx,避免频繁触发GC;
map
conc库提供的map方法可以得到对切片中元素结果,官方例子:
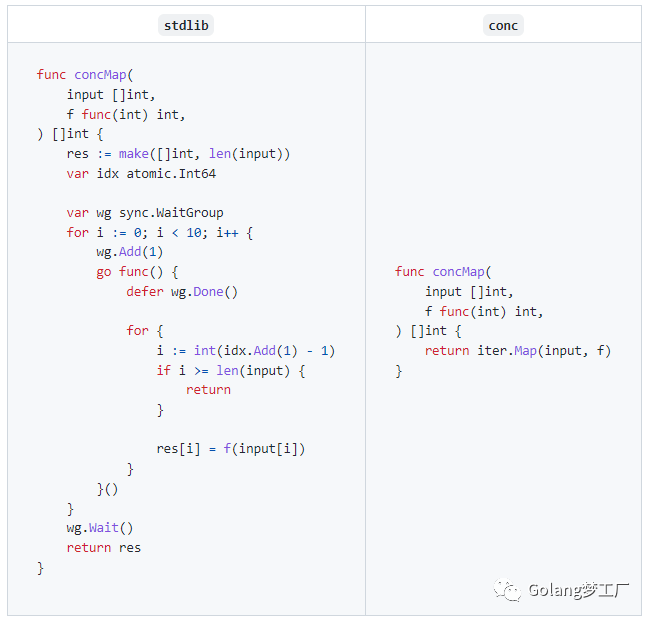
使用map可以提高代码的可读性,并且减少了冗余代码,自己写个例子:
func main() {
input := []int{1, 2, 3, 4}
mapper := iter.Mapper[int, bool]{
MaxGoroutines: len(input) / 2,
}
results := mapper.Map(input, func(v *int) bool { return *v%2 == 0 })
fmt.Println(results)
// Output:
// [false true false true]
}map的实现也依赖于Iterator,也是调用的ForEachIdx方法,区别于ForEach是记录处理结果;
总结
花了小半天时间看了一下这个库,很多设计点值得我们学习,总结一下我学习到的知识点:
- conc.WatiGroup对Sync.WaitGroup进行了封装,对Add、Done、Recover进行了封装,提高了可读性,避免了冗余代码
- ForEach、Map方法可以更优雅的并发处理切片,代码简洁易读,在实现上Iterator中的并发处理使用atomic来控制只创建一个闭包,避免了GC性能问题
- pool是一个并发的协程队列,可以控制协程的数量,实现上也很巧妙,使用一个无缓冲的channel作为worker,如果goroutine执行速度快,避免了创建多个goroutine
- stream是一个保证顺序的并发协程队列,实现上也很巧妙,使用sync.Pool在提交goroutine时控制顺序,值得我们学习;
到此这篇关于一文带你了解Go语言实现的并发神库conc的文章就介绍到这了,更多相关Go语言并发库conc内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!