goroutine
goroutine是由Go运行时管理的轻量级线程。
go f(x, y, z)在一个新的goroutine中开始执行f(x, y,z)。
goroutines运行在相同的地址空间中,所以对共享的内存访问必须同步。sync包提供了基本的同步原语(synchronization primitives),比如互斥锁(mutual exclusion locks)。
goroutines运行在相同的地址空间中,没有内存隔离,不同的goroutines可以访问同一个内存地址。这样对共享的内存的访问就可能出现问题,比如有一个全局变量A,goroutine 1开始修改A的数据,但是还没修改完,goroutine 2就开始读取A的数据了,这样读到的数据可能是不准确的,如果goroutine 2中也要修改A的数据,那A的数据就处于一种更不确定的状态了。所以需要使用互斥锁,当goroutine 1开始修改A的数据之前,先加个锁,表示这块内存已经被锁上了,等修改完A的数据再将锁解开。在goroutine 1修改数据A但还没修改完的期间,goroutine 2需要修改/读取A的内容,发现已经加锁,就会进入休眠状态,直到变量A的锁被解开才会执行goroutine 2中的修改/读取。
package main
import (
"fmt"
"time"
)
func main() {
go say("a")
say("b")
}
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(2000 * time.Millisecond)
fmt.Println(s, time.Now().Format("15:04:05.000000"))
}
}执行go run goroutine.go的时候,会在主goroutine中执行main函数,当执行到go say("a")的时候,会在一个新的goroutine中执行say("a")(称这个子goroutine为goroutine 1),然后主goroutine中继续执行say("b"),主goroutine和goroutine 1中的函数执行是并发的。
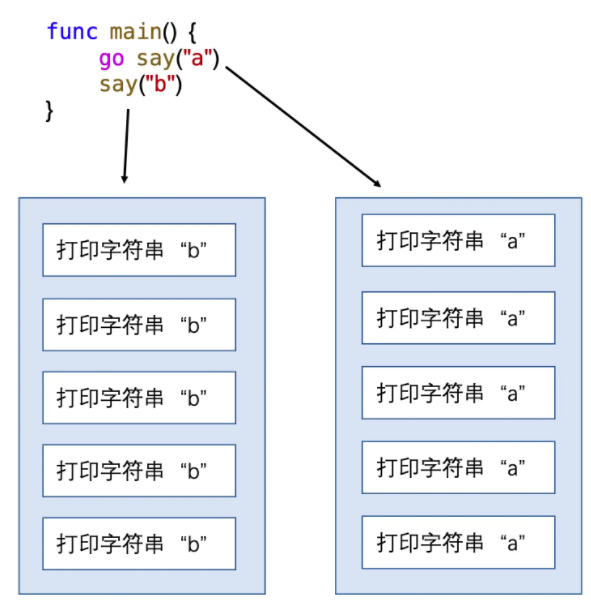
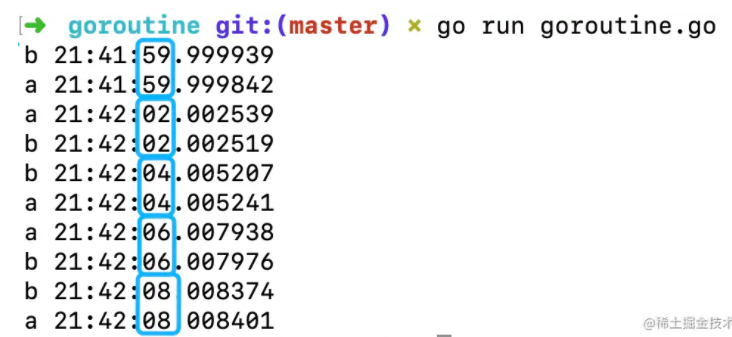
因为是并发执行,打印出的字符串a和字符串b的顺序是无法确定的。
(仔细观察的话会发现打印的前2条数据的时间戳,b的时间戳在a的后面,但是先打印出了b,这说明这次执行中,两者的fmt.Println函数的执行(直到输出到终端)时间不同,先拿到了字符串a,但是打印字符串a的fmt.Println执行比打印字符串b的函数执行稍稍慢了一点,所以b先出现在了输出界面上。可能背后还有更复杂的原因,这里不作深究。)
通道
通道(channels)是一个类型化的管道(conduit),可以通过<-(通道运算符)来使用通道,对值进行发送和接收。
可选的<-操作符指定了通道的方向,如果给出了一个方向,通道就是定向的,否则就是双向的。
chan T // 可以被用来发送和接收类型为T的值 chan <- float64 // 只能被用来发送float64类型的值 <-chan int // 只能被用来接收int类型的值
如果有<-操作符的话,数据按照箭头的方向流动。
通道在使用前必须被创建:
make(chan int, 100)
通过内置的make函数创建一个新的、初始化的通道,接收的参数是通道类型和一个可选的容量。容量设置缓存区的大小。如果容量是0或者省略了,通道就是非缓存的,只在发送方和接收方都准备好的时候才能通信成功。否则通道就是缓存的,发送方的缓存区没有满,或者接收方的缓存区不为空,就能不阻塞地进行通信。
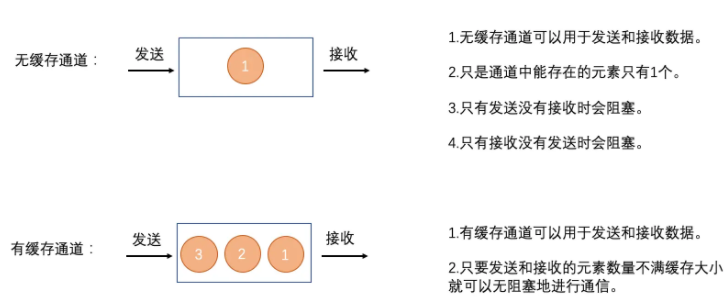
“发送方的缓存区没有满,或者接收方的缓存区不为空,就能不阻塞地进行通信。“这句话直白一点说,就是如果缓存区满了,就不能再往通道中发送数据了(chan <- 数据 ),如果缓存区是空的,就不能从通道中接收数据了(<-chan)。
1.无缓存通道例子:
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func main() {
example1()
wg.Wait() // 等待所有goroutines执行完成
}
func example1() {
chan1 := make(chan int)
wg.Add(1)
go a(chan1) // 向通道中发送数字1、2
wg.Add(1)
go b(chan1) // 等待1秒之后,从通道中拿数据,拿到的是数字2
fmt.Println("接收数据A", <-chan1) // 这里拿到的是数字1
}
func a(chan1 chan int) {
defer wg.Done()
chan1 <- 1
chan1 <- 2
}
func b(chan1 chan int) {
defer wg.Done()
time.Sleep(time.Second)
fmt.Println("接收数据B", <-chan1)
}如果把以下这两句注释掉,运行代码就会报错:fatal error: all goroutines are asleep - deadlock!。
wg.Add(1)
go b(chan1) // 等待1秒之后,从通道中拿数据
把这句注释掉,代码变成了往无缓存通道中发送了2个元素,但是只接收了1个元素。由于向通道中发送的元素2没被接收,通道会阻塞,sync包又在等待数字2的发送(chan1 <- 2)完成,就造成了死锁。
最终在无缓存通道中的元素个数为0,无缓存通道就不会阻塞。
2.有缓存通道例子:
...
var wg sync.WaitGroup
func main() {
example2()
wg.Wait() // 等待所有goroutines执行完成
}
func example2() {
chan1 := make(chan int, 2)
wg.Add(1)
go a(chan1) // 向通道中发送数字1、2、3
fmt.Println("接收数据", <-chan1)
}
func a(chan1 chan int) {
defer wg.Done()
chan1 <- 1
chan1 <- 2
chan1 <- 3
}
func b(chan1 chan int) {
defer wg.Done()
time.Sleep(time.Second)
fmt.Println("接收数据", <-chan1)
}以上代码向容量为2的缓存通道中发送了3个元素,但是只接收了1个,此时通道中还有2个元素,不会阻塞。
如果在a函数的最后一行再加上一句chan1 <- 4,再执行代码,就会报错fatal error: all goroutines are asleep - deadlock!。因为发送了4个元素,只接收了1个元素,还剩3个元素没被接收,3 > 2,缓存已经满了,由于代码中没有别的地方来接收元素,通道阻塞,但是sync包又在等待chan1 <- 4的完成,所以会造成死锁。
最终在有缓存通道中的元素个数小于等于容量,有缓存通道就不会阻塞。
3.使用通道在goroutines间进行通信的例子:
func main() {
example3()
}
func example3() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c
fmt.Println(x, y, x+y)
}
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum
}这段代码将数组的内容分为两部分,在两个goroutines中分别进行计算,最后再进行求和。
这里两个子goroutines是与主goroutine并发执行的,但主goroutine中的x, y := <-c, <-c依然拿到了两个子goroutines中往通道发送的数据(c <- sum)。这是因为通道的发送和接收会阻塞,直到另一边准备好。

x拿到的是先计算完的和,y拿到的是后计算完的和,x,y的值是不确定的,可能是-5 17 或者 17 -5,就看哪个子goroutine中的计算先完成。
Range 和 Close
发送方可以close一个通道来表明没有更多的值会被发送。接收方可以通过赋值第二个参数给接收表达式,测试一个通道是否已经被关闭。
执行如下语句:
v, ok := <-ch
如果没有更多的值要接收,并且通道已经关闭了,ok的值就为false。
for i := range c循环,从通道中重复地接收值,直到通道关闭。
注意:
- 只有发送方可以关闭一个通道,接收方不可以。在一个已经关闭的通道上进行发送会导致一个错误(panic)。
- 通道不像文件,不需要总是关闭它们。关闭只有必须告诉接收方不会再来更多值时,才是必须的,比如终止一个
range循环。
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c {
fmt.Println(i)
}
}
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
// 必须在遍历结束之后关闭通道
// 否则 for i := range c 会一直等待通道关闭
close(c)
}以上代码求斐波那契数列,依次将求得的值发送到通道。
如果把close(c) 语句注释掉,运行代码,就会报错:fatal error: all goroutines are asleep - deadlock!。因为for i := range c一直在等通道关闭,但是整个执行过程中并没有关闭通道,造成了死锁。
Select
select语句让一个goroutine等待多个通信操作。
一个select 会阻塞,直到它的cases中的一个可以运行,然后它就会执行该case。如果多个通信都准备好了,就会随机选择一个。
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}上述代码还是实现一个斐波那契数列的计算。
在子goroutine(称之为goroutine 1)中循环10次,依次从通道c中接收数据,循环结束之后,将数字0发送到通道quit。
在主goroutine中,调用fibonacci函数:
-
c <- x是向通道中发送数据,只要有地方从通道中接收数据,向通道中发送数据就能继续运行。每次在goroutine 1的循环中<-c,主goroutine中的select语句中的case c <- x中的语句就会执行。 <-quit是从通道中接收数据,只要有地方向通道中发送数据,从通道中接收数据就能继续运行。当goroutine 1中循环结束之后quit <- 0,case <-quit中的语句就会执行。
一个select中的default case,在没有其他case准备好的时候就会运行。
package main
import (
"fmt"
"time"
)
func main() {
tick := time.Tick(100 * time.Millisecond)
boom := time.After(500 * time.Millisecond)
for {
select {
case <-tick:
fmt.Println("tick.")
case <-boom:
fmt.Println("BOOM!")
return
default:
fmt.Println(" .")
time.Sleep(50 * time.Millisecond)
}
}
}每隔100毫秒,通道tick就会收到一次数据,case <-tick中的语句会执行,打印一次tick.;500毫秒之后,通道boom会收到数据,case <-boom中的语句会执行,打印BOOM!,并且使用return结束程序的执行。在这期间,由于for语句是一直在循环的,当通道tick和通道boom中都没收到数据时,就会执行default中的语句:打印一个点并且等待50毫秒。
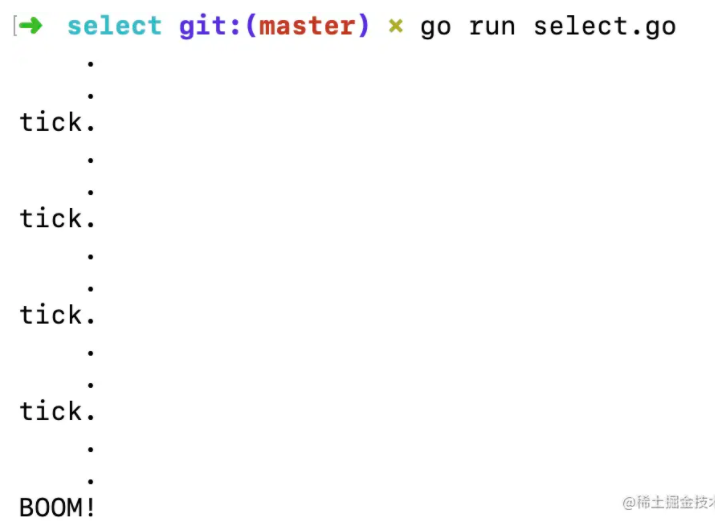
粗略看了下time.Tick和time.After代码,两者返回的值都是类型为<-chan Time的通道,使用轮询,在满足时间条件之后,向通道中发送当前时间。如果想看通道中传递的时间数据的话,可以使用以下代码:
package main
import (
"fmt"
"time"
)
func main() {
tick := time.Tick(100 * time.Millisecond)
boom := time.After(500 * time.Millisecond)
var x, y time.Time
for {
select {
case x, _ = <-tick:
fmt.Println(x, "tick.")
case y, _ = <-boom:
fmt.Println(y, "BOOM!")
return
default:
fmt.Println(" .")
time.Sleep(50 * time.Millisecond)
}
}
}sync.Mutex
如果我们想要避免冲突,确保一次只有一个goroutine可以访问一个变量(这个概念称为互斥),则可以使用互斥锁(mutex)。
Go的标准库提供了互斥的使用,需要用到sync.Mutex和它的两个方法Lock和Unlock。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
c := SafeCounter{v: make(map[string]int)}
for i := 0; i < 1000; i++ {
go c.Inc("somekey")
}
time.Sleep(time.Second)
fmt.Println(c.Value("somekey"))
}
type SafeCounter struct {
mu sync.Mutex
v map[string]int
}
// 使用给定的key递增计数器
func (c *SafeCounter) Inc(key string) {
c.mu.Lock()
// 锁住之后,一次只能有一个goroutine可以访问映射c.v
c.v[key]++
c.mu.Unlock()
}
// 返回 给定key的 计数器的当前值
func (c *SafeCounter) Value(key string) int {
c.mu.Lock()
// 锁住之后,一次只能有一个goroutine可以访问映射c.v
defer c.mu.Unlock()
return c.v[key]
}官方留的两道练习题
官方留了两道练习题,没有给出完整的代码。可以作为了解了以上知识之后的练手。
等价的二叉树
有很多不同的二叉树,存储着相同的值的序列。例如,下图两棵二叉树存储的序列是1, 1, 2, 3, 5, 8, 13。

1.实现Walk函数。
2.测试Walk函数。
函数tree.New(k)构造了一个随机结构(但总是排序的)的二叉树来存储值k,2k,3k,...,10k。
创建一个新的通道ch并开始遍历:
go Walk(tree.New(1), ch)
然后打印树中包含的10个值,应该是数字1,2,3,...,10。
3.实现Same函数,使用Walk来决定t1和t2是否存储相同的值。
4.测试Same函数:
Same(tree.New(1), tree.New(1))应该返回true,Same(tree.New(1), tree.New(2))应该返回false。
代码实现
主要部分代码如下:
package main
import (
"equbintrees/tree"
"fmt"
)
func main() {
tree1 := tree.New(1)
tree2 := tree.New(2)
fmt.Println(Same(tree1, tree2))
}
// 函数遍历树 t,将树中的所有值依次发送到通道中
func Walk(t *tree.Tree, ch chan int) {
if t == nil {
return
}
if t.Left != nil {
Walk(t.Left, ch)
}
ch <- t.Value
if t.Right != nil {
Walk(t.Right, ch)
}
}
// 判断两棵树是否包含相同的值
func Same(t1, t2 *tree.Tree) bool {
ch1 := make(chan int)
ch2 := make(chan int)
go Walk(t1, ch1)
go Walk(t2, ch2)
var count int
for {
if <-ch1 == <-ch2 {
count++
// 这里的count等于10,是因为题目要求里面随机生成的树的节点个数就是10个
// 一般的树可以给树添加一个Len属性表示节点个数,用Len属性来判断
if count == 10 {
return true
}
} else {
return false
}
}
}网络爬虫
使用Go的并发功能来并发网络爬虫。
修改Crawl函数来并发获取URLs,并且相同的URL不会获取2次。
提示:你可以使用映射缓存已经获取到的URL,但是只使用映射对于并发使用来说是不安全的。
代码实现
这部分我尝试实现了下,主要思路是在递归的过程中,将遍历到链接中包含的urls发送到通道ch中,用for urls := range ch遍历通道中的元素,以此来等待所有发送到通道中的urls都被接收,在递归过程中判断深度是否达到4,达到4之后调用close(ch)关闭通道。
但是有问题,因为不能仅凭 深度是否达到 来判断 是否关闭通道。给出的例子实际只有4层链接,如果设置深度需要到达到5,当递归到尽头的时候就应该关闭通道了,但是因为没有达到深度5,没有关闭通道,for urls := range ch还会继续等通道接收数据,但已经不会再往通道中发送数据了,造成死锁。总之,手动调用close(ch)来正确关闭通道有点难,因为很难找到递归和并发请求时不会再往通道中发送数据的那个时机。
我从这个链接找到了大佬的代码实现:https://rmoff.net/2020/07/03/learning-golang-some-rough-notes-s01e10-concurrency-web-crawler/
主要思路就是使用sync.WaitGroup,用Add方法添加WaitGroup计数,用wg.Wait()等待所有的goroutines执行结束。
主要部分代码如下:
func main() {
wg := &sync.WaitGroup{}
wg.Add(1)
go Crawl("https://golang.org/", 5, fetcher, wg)
wg.Wait()
}
type URLs struct {
c map[string]bool // 用于存放表示一个链接是否被抓取过的映射
mux sync.Mutex // 使用互斥锁在并发的执行中进行安全的读写
}
var u URLs = URLs{c: make(map[string]bool)}
// 检查链接是否已经被抓取过
func (u URLs) IsCrawled(url string) bool {
fmt.Printf("\n Checking if %v has been crawled…", url)
u.mux.Lock()
defer u.mux.Unlock()
if _, ok := u.c[url]; ok == false {
fmt.Printf("…it hasn't\t")
return false
}
fmt.Printf("…it has\t")
return true
}
// 将链接标记为抓取过
func (u URLs) Crawled(url string) {
u.mux.Lock()
u.c[url] = true
u.mux.Unlock()
}
// 递归地请求抓去url的数据,直到一个最大深度
func Crawl(url string, depth int, fetcher Fetcher, wg *sync.WaitGroup) {
defer wg.Done()
if depth <= 0 {
return
}
if u.IsCrawled(url) == true {
return
}
fmt.Printf("\n➡️ Crawling %v", url)
body, urls, err := fetcher.Fetch(url)
u.Crawled(url)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("\n\t->✅ found: %s %q\n", url, body)
for _, z := range urls {
wg.Add(1)
go Crawl(z, depth-1, fetcher, wg)
}
}源码地址
https://github.com/renmo/myBlog/tree/master/2022-05-31-goroutine
以上就是Go语言学习教程之goroutine和通道的示例详解的详细内容,更多关于Go语言 goroutine 通道的资料请关注好代码网其它相关文章!