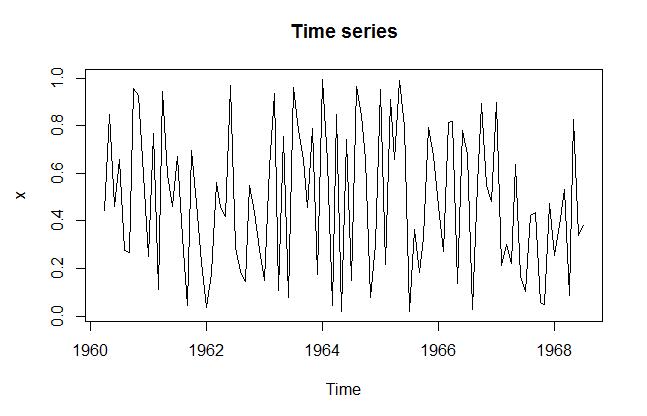
数据
GDP csv文件,存储1879~2019年河南省GDP数据绘图 读取数据, 首先将excel 格式的转化为 csv 格式 再读取
h
数据
GDP.csv文件,存储1879~2019年河南省GDP数据
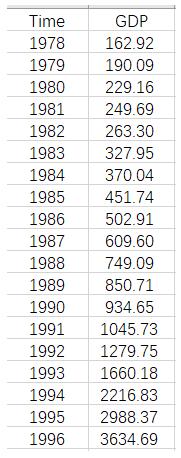
绘图
# 读取数据, 首先将excel 格式的转化为 csv 格式 再读取 h <- read.table(file = "C:/Users/PYY/Desktop/GDP.csv",sep = ",",header = T) # 转化为时间序列数据 GDP=ts(h$GDP,start = 1978,frequency = 1) # 绘图 plot(GDP)

补充:ts函数
ts() 函数:
通过一向量或者矩阵创建一个一元的或多元的时间序列(time series),为ts型对象。
调用格式:
ts(data = NA, start = 1, end = numeric(0), frequency = 1, deltat = 1, ts.eps = getOption("ts.eps"), class, names)
参数说明:
data:一个向量或者矩阵
start:第一个观测值的时间,为一个数字或者是一个由两个整数构成的向量
end:最后一个观测值的时间,指定方法和start相同
frequency:单位时间内观测值的频数(频率)
deltat:两个观测值间的时间间隔。frequency和deltat必须并且只能给定其中一个
ts.eps:序列之间的误差限,如果序列之间的频率差异小于ts.eps,则认为这些序列的频率相等
class:对象的类型。一元序列的缺省值是“ts”,多元序列的缺省值是c(“mts”,“ts”)
names:一个字符型向量,给出多元序列中每个一元序列的名称,缺省data中每列数据的名称或者Series 1,Series 2, 。。。
举个栗子:
ts(1:26, start=1986) #最简单的形式 Time Series: Start = 1986 End = 2011 Frequency = 1
运行结果:
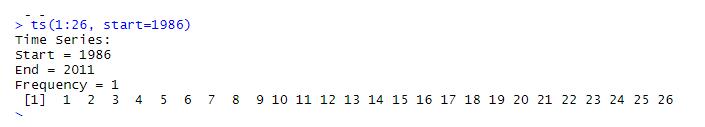
ts(1:26, frequency = 12, start=c(1986,10)) #frequency = 12时,为月份
运行结果:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持好代码网。如有错误或未考虑完全的地方,望不吝赐教。