一般情况下:
csv 文件 sep = “,” # 以逗号分割
txt 文件 sep = “\t” #以制表符分割
其他文件 sep = " " #以空格分割
具体情况,具体调整
sep= 文件中的字段分离符,用于文件数据文本的读取和保存过程中指定分割符号。
补充:用R语言把超大文本文件拆分成几个小文本文件
近一段时间一直在研究一些医院的数据。
前两天遇到一个尴尬:想打开一个仅有3G左右的文本文件(有时候必须要打开,直接传到数据库满足不了需求),破电脑(4G内存的电脑)就是打不开(用的Notepad++)。
就是这造型:
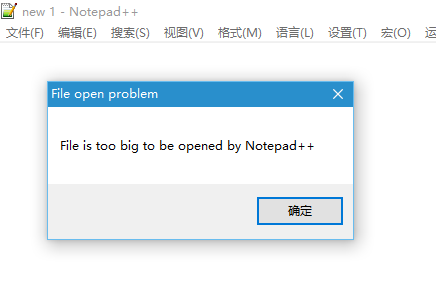
上网搜了一些方法,下了一些比较不常用的文本处理工具和其它工具,也不理想。
得知好多人在许多场景都需要打开或者拆分8G甚至10G以上的文本文件,于是想着自己研究一下。
下面就是我用R来拆分大文本的过程
虽然方法比较笨,但是简单轻巧、思路清晰。
1.首先把你想要拆分的大文本文件放到R的当前工作目录下
我的文件名在这里叫details.txt。
2.用函数split_file()来拆分大文本文件
split_file()函数是自定义的一个函数,用来拆分超大文本文件。
它总共有两个参数filename和eachfile_lines_num,即split_file(filename,eachfile_lines_num)。
filename是指需要拆分的超大文本的名字,eachfile_lines_num是指拆分完的每一个文件中有多少行数据。
split_file()会返回一个数值,代表了总共拆分成的小文本的数量。
split_file()拆分出来的文件会放置在R当前的工作目录下。
使用如:
split_file("details.txt",1000000),它把名为details.txt的超大文本文件拆分为每个文件只有1000000行的一个个的小文本文件。
split_file()的细节:
file_split <- function(filename,eachfile_lines_num){ #建立函数
c <- file(filename,"r") #建立链接
varnames <- paste("splitfile", 1:1000, sep = "_") #建立尽可能多但不要太多的动态变量名
i <- 1 #初始值
while(TRUE){
assign(varnames[i],value = readLines(c,n = eachfile_lines_num)) #分别把从filename中读出来的数据存放在变量中
write.table(get(varnames[i]),paste(varnames[i],".txt",sep = "")) #分别把存放在变量中的数据写出到文件中
if (length(get(varnames[i])) < eachfile_lines_num) break
else i <- i + 1 #判断循环停止条件
}
return(i) #返回文件数量
}
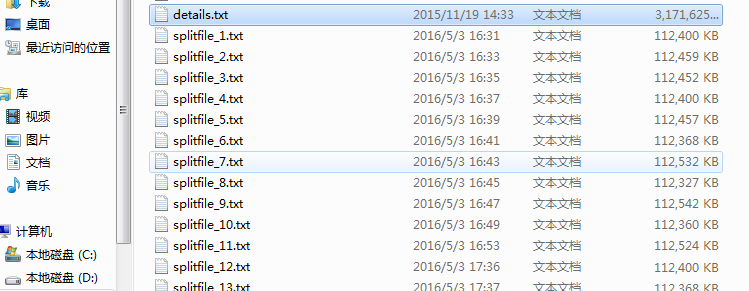
我执行完file_split("details.txt",500000)之后得到了30多个文件:
3.对拆分的文件进行处理
由于过程中用到了readLines(),因此拆出来的文件每一行是一个字符串,有引号。
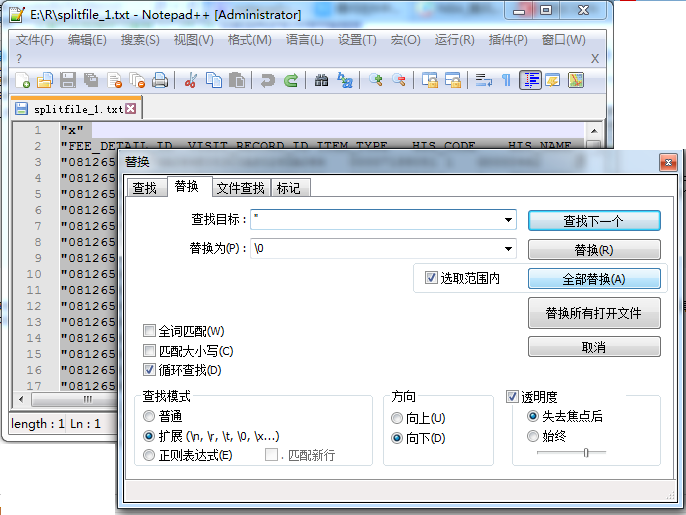
这好像不符合要求,只需用Windows记事本或notepad++或其他文本处理应用处理一下就行。
在notepad++中执行“搜索 -> 替换”把双引号替换成\0就行了。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持好代码网。如有错误或未考虑完全的地方,望不吝赐教。