Oracle 正则表达式
正则表达式就是由普通字符(例如字符a到z)以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
本文详细地列出了能在正则表达式中使用,以匹配文本的各种字符。当你需要解释一个现有的正则表达式时,可以作为一个快捷的参考。
一. 匹配字符
| 字符类 | 匹配的字符 | 举 例 |
|---|---|---|
| \d | 从0-9的任一数字 | \d\d匹配72,但不匹配aa或7a |
| \D | 任一非数字字符 | \D\D\D匹配abc,但不匹配123 |
| \w | 任一单词字符,包括A-Z,a-z,0-9和下划线 | \w\w\w\w匹配Ab-2,但不匹配∑£$%*或Ab_@ |
| \W | 任一非单词字符 | \W匹配@,但不匹配a |
| \s | 任一空白字符,包括制表符,换行符,回车符,换页符和垂直制表符 | 匹配在HTML,XML和其他标准定义中的所有传统空白字符 |
| \S | 任一非空白字符 | 空白字符以外的任意字符,如A%&g3;等 |
| . | 任一字符 | 匹配除换行符以外的任意字符除非设置了MultiLine先项 |
| […] | 括号中的任一字符 | [abc]将匹配一个单字符,a,b或c. |
| [a-z] | 将匹配从a到z的任一字符 | |
| [^…] | 不在括号中的任一字符 | [^abc]将匹配一个a、b、c之外的单字符,可以a,b或A、B、C |
| [a-z] | 将匹配不属于a-z的任一字符,但可以匹配所有的大写字母 |
二.重复字符
| 重复字符 | 含 义 | 举 例 |
|---|---|---|
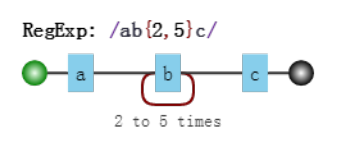
| {n} | 匹配前面的字符n次 | x{2}匹配xx,但不匹配x或xxx |
| {n,} | 匹配前面的字符至少n次 | x{2}匹配2个或更多的x,如xxx,xxx.. |
| {n,m} | 匹配前面的字符至少n次,至多m次。如果n为0,此参数为可选参数 | x{2,4}匹配xx,xxx,xxxx,但不匹配xxxxx |
| ? | 匹配前面的字符0次或1次,实质上也是可选的 | x?匹配x或零个x |
| + | 匹配前面的字符0次或多次 | x+匹配x或xx或大于0的任意多个x |
| * | 匹配前面的字符0次或更多次 | x*匹配0,1或更多个x |
三、定位字符
| 定位字符 | 描 述 |
|---|---|
| ^ | 随后的模式必须位于字符串的开始位置,如果是一个多行字符串,则必须位于行首。对于多行文本(包含回车符的一个字符串)来说,需要设置多行标志 |
| $ | 前面的模式必须位于字符串的未端,如果是一个多行字符串,必须位于行尾 |
| \A | 前面的模式必须位于字符串的开始位置,忽略多行标志 |
| \z | 前面的模式必须位于字符串的未端,忽略多行标志 |
| \Z | 前面的模式必须位于字符串的未端,或者位于一个换行符前 |
| \b | 匹配一个单词边界,也就是一个单词字符和非单词字符中间的点。要记住一个单词字符是[a-zA-Z0-9]中的一个字符。位于一个单词的词首 |
| \B | 匹配一个非单词字符边界位置,不是一个单词的词首 |
注:定位字符可以应用于字符或组合,放在字符串的左端或右端
四、分组字符
分组字符和定义举例
4.1() 捕获组
()此字符可以组合括号内模式所匹配的字符,它是一个捕获组,也就是说模式匹配的字符作为最终设置了ExplicitCapture选项――默认状态下字符不是匹配的一部分
举例:
输入字符串为:ABC1DEF2XY
匹配3个从A到Z的字符和1个数字的正则表达式:([A-Z]{3}\d)
将产生两次匹配:Match 1=ABC1;Match 2=DEF2
每次匹配对应一个组:Match1的第一个组=ABC;Match2的第1个组=DEF
有了反向引用,就可以通过它在正则表达式中的编号以及C#和类Group,GroupCollection来访问组。如果设置了ExplicitCapture选项,就不能使用组所捕获的内容。
4.2 (?:) 非捕获组
(?:)此字符可以组合括号内模式所匹配的字符,它是一个非捕获组,这意味着模式所的字符将不作为一个组来捕获,但它构成了最终匹配结果的一部分。它基本上与上面的组类型相同,但需要设定了选项ExplicitCapture
示例:
输入字符串为:1A BB SA1 C
匹配一个数字或一个A到Z的字母,接着是任意单词字符的正则表达式为:(?:\d|[A-Z]\w)
它将产生3次匹配:第1次匹配=1A;第2次匹配=BB;第3次匹配=SA,但是没有组被捕获
4.3(?)捕获组命名
(?
示例:
输入字符串为:Characters in Sienfeld included Jerry Seinfeld,Elaine Benes,Cosno Kramer and George Costanza能够匹配它们的姓名,并在一个组llastName中捕获姓的正则表达式为:\b[A-Z][a-z]+(?
它产生了4次匹配:First Match=Jerry Seinfeld; Second Match=Elaine Benes; Third Match=Cosmo Kramer; Fourth Match=George Costanza
每一次匹配都对应了一个lastName组:
第1次匹配:lastName group=Seinfeld
第2次匹配:lastName group=Benes
第3次匹配:lastName group=Kramer
第4次匹配:lastName group=Costanza
不管是否设置了选项ExplictCapture,组都将被捕获
4.4(?=) 正声明
(?=) 正声明.声明的右侧必须是括号中指定的模式。此模式不构成最终匹配的一部分
示例:
正则表达式\S+(?=.NET)要匹配的输入字符串为:The languages were Java,C#.NET,VB.NET,C,Jscript.NET,Pascal
将产生如下匹配:
C#
VB
JScript
4.5 (?!)负声明
(?!) 负声明。它规定模式不能紧临着声明的右侧。此模式不构成最终匹配的一部分
示例:
\d{3}(?![A-Z])要匹配的输入字符串为:123A 456 789111C
将产生如下匹配:
456
789
4.6 (?<=) 反向正声明
(?<=) 反向正声明。声明的左侧必须为括号内的指定模式。此模式不构成最终匹配的一部分
示例:
正则表达式(?<=New\s)([A-Z][a-z]+)要匹配的输入字符串为:The following states,New Mexico,West Virginia,Washington, New England
它将产生如下匹配:
Mexico
England
4.7 (?<=) 反向负声明
(?<!) 反向正声明。声明的左侧必须不能是括号内的指定模式。此模式不构成最终匹配的一部分
示例:
正则表达式(?<!1)\d{2}([A-Z])要匹配的输入字符串如下:123A456F789C111A
它将实现如下匹配:
56F
89C
4.8 (?>)非回溯组
(?>) 非回溯组。防止Regex引擎回溯并且防止实现一次匹配
示例:
假设要匹配所有以“ing”结尾的单词。输入字符串如下:He was very trusing
正则表达式为:.*ing
它将实现一次匹配――单词trusting。“.”匹配任意字符,当然也匹配“ing”。所以,Regex引擎回溯一位并在第2个“t”停止,然后匹配指定的模式“ing”。但是,如果禁用回溯操作:(?>.*)ing
它将实现0次匹配。“.”能匹配所有的字符,包括“ing”――不能匹配,从而匹配失败
五、决策字符
5.1 正则表达式决策字符
(?(regex)yes_regex|no_regex) 如果表达式regex匹配,那么将试图匹配表达式yes。否则匹配表达式no。正则表达式no是可先参数。注意,作出决策的模式宽度为0.这意味着表达式yes或no将从与regex表达式相同的位置开始匹配
示例:
正则表达式(?(\d)\dA|(A-Z)B)要匹配的输入字符串为:1A CB3A5C 3B
它实现的匹配是:
1A
CB
3A
5.2 组决策字符
(?(group name or number)yes_regex|no_regex) 如果组中的正则表达式实现了匹配,那么试图匹配yes正则表达式。否则,试图匹配正则表达式no。no是可先的参数
示例:
正则表达式(\d7)?-(?(1)\d\d[A-Z]|[A-Z][A-Z]要匹配的输入字符串为:
77-77A 69-AA 57-B
它实现的匹配为:
77-77A
-AA
注:上面表中列出的字符强迫处理器执行一次if-else决策
六、替换字符
- $group 用group指定的组号的值
- ${name} 被一个(?
)组匹配的最后子串的值 -
\[ 代表一个字符$ \]
- $^ 代表输入字符串匹配之前的所有文本
- $’ 代表输入字符串匹配之后的所有文本
- $+ 代表最后捕获的组
- $_ 代表整个的输入字符串
注:以上为常用替换字符,不全
七、转义序列
\ 匹配字符“\”
. 匹配字符“.”
* 匹配字符“*”
+ 匹配字符“+”
? 匹配字符“?”
| 匹配字符“|”
( 匹配字符“(”
) 匹配字符“)”
{ 匹配字符“{”
} 匹配字符“}”
^ 匹配字符“^”
$ 匹配字符“$”
\n 匹配换行符
\r 匹配回车符
\t 匹配制表符
\v 匹配垂直制表符
\f 匹配换面符
\nnn 匹配一个8进数字,nnn指定的ASCII字符。如\103匹配大写的C
\xnn 匹配一个16进数字,nn指定的ASCII字符。如\x43匹配大写的C
\unnnn 匹配由4位16进数字(由nnnn表示)指定的Unicode字符
\cV 匹配一个控制字符,如\cV匹配Ctrl-V
八、选项标志
- I IgnoreCase
- M Multiline
- N ExplicitCapture
- S SingleLine
- X IgnorePatternWhitespace
注:选项本身的信作含义如下表所示:
标 志 名 称:
- IgnoreCase 使模式匹配不区分大小写。默认的选项是匹配区分大小写
- RightToLeft 从右到左搜索输入字符串。默认是从左到右以符合英语等的阅读习惯,但不符合阿拉伯语或希伯来语的阅读习惯
- None 不设置标志。这是默认选项
- Multiline 指定^和$可以匹配行首和行尾,以及字符串的开始和结尾。这意味着可以匹配每个用换行符分隔的行。但是,字符“.”仍然不匹配换行符
- SingleLine 规定特殊字符“.”匹配任意的字符,包括换行符。默认情况下,特殊字符“.”不匹配换行符。通常与MultiLine选项一起使用
- ECMAScript. ECMA(European Coputer Manufacturer’s Association,欧洲计算机生产商协会)已经定义了正则表达式应该如何实现,而且已经在ECMAScript规范中实现,这是一个基于标准的JavaScript。这个选项只能与IgnoreCase和MultiLine标志一起使用。与其它任何标志一起使用,ECMAScript都将产生异常
- IgnorePatternWhitespace 此选项从使用的正则表达式模式中删除所有非转义空白字符。它使表达式能跨越多行文本,但必须确保对模式中所有的空白进行转义。如果设置了此选项,还可以使用“#”字符来注释下则表达式
- Complied 它把正则表达式编译为更接近机器代码的代码。这样速度快,但不允许对它进行任何修改
九、oracle的正则表达式(regular expression)简单介绍
目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境。
Oracle 10g正则表达式提高了SQL灵活性。有效的解决了数据有效性, 重复词的辨认, 无关的空白检测,或者分解多个正则组成
的字符串等问题。
Oracle 10g支持正则表达式的四个新函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和REGEXP_REPLACE。
它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
9.1 REGEXP_REPLACE
REGEXP_REPLACE(source_string,pattern,replace_string,position,occurtence,match_parameter)函数(10g新函数)
描述:字符串替换函数。相当于增强的replace函数。Source_string指定源字符表达式;pattern指定规则表达式;replace_string指定用于替换的字符串;position指定起始搜索位置;occurtence指定替换出现的第n个字符串;match_parameter指定默认匹配操作的文本串。
其中replace_string,position,occurtence,match_parameter参数都是可选的。
9.2 REGEXP_SUBSTR
REGEXP_SUBSTR(source_string, pattern[,position [, occurrence[, match_parameter]]])函数(10g新函数)
描述:返回匹配模式的子字符串。相当于增强的substr函数。Source_string指定源字符表达式;pattern指定规则表达式;position指定起始搜索位置;occurtence指定替换出现的第n个字符串;match_parameter指定默认匹配操作的文本串。
其中position,occurtence,match_parameter参数都是可选的
match_option的取值如下:
- ‘c’ 说明在进行匹配时区分大小写(缺省值);
- 'i' 说明在进行匹配时不区分大小写;
- 'n' 允许使用可以匹配任意字符的操作符;
- 'm' 将x作为一个包含多行的字符串。
9.3 REGEXP_LIKE
REGEXP_LIKE(source_string, pattern[, match_parameter])函数(10g新函数)
描述:返回满足匹配模式的字符串。相当于增强的like函数。Source_string指定源字符表达式;pattern指定规则表达式;match_parameter指定默认匹配操作的文本串。
其中position,occurtence,match_parameter参数都是可选的
9.4 REGEXP_INSTR
REGEXP_INSTR(source_string, pattern[, start_position[, occurrence[, return_option[, match_parameter]]]])函数(10g新函数)
描述: 该函数查找 pattern ,并返回该模式的第一个位置。您可以随意指定您想要开始搜索的 start_position。 occurrence 参数默认为 1,除非您指定您要查找接下来出现的一个模式。return_option 的默认值为 0,它返回该模式的起始位置;值为 1 则返回符合匹配条件的下一个字符的起始位置
9.5 特殊字符:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 'n' 或 'r'。
'.' 匹配除换行符 n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
'+' 匹配前面的子表达式一次或多次。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m= <出现次数 <=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
' |' 指明两项之间的一个选择。例子'^([a-z]+ |[0-9]+)$'表示所有小写字母或数字组合成的字符串。
9.6 num捕获引用
num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
正则表达式的一个很有用的特点是可以保存子表达式以后使用, 被称为Backreferencing. 允许复杂的替换能力
如调整一个模式到新的位置或者指示被代替的字符或者单词的位置. 被匹配的子表达式存储在临时缓冲区中,
缓冲区从左到右编号, 通过数字符号访问。 下面的例子列出了把名字 aa bb cc 变成cc, bb, aa.
语句:
Select REGEXP_REPLACE('aa bb cc','(.) (.) (.*)', '3, 2, 1') FROM dual;
结果:
cc, bb, aa
9.7 转义符
字符簇:
- [[:alpha:]] 任何字母。
- [[:digit:]] 任何数字。
- [[:alnum:]] 任何字母和数字。
- [[:space:]] 任何白字符。
- [[:upper:]] 任何大写字母。
- [[:lower:]] 任何小写字母。
- [[:punct:]] 任何标点符号。
- [[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
9.8 各种操作符的运算优先级
优先级从左到右,从上到下依次降低
(), (?, (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
| “或”操作
十、测试数据示例
10.1 测试数据
create table test(mc varchar2(60));
insert into test values('112233445566778899');
insert into test values('22113344 5566778899');
insert into test values('33112244 5566778899');
insert into test values('44112233 5566 778899');
insert into test values('5511 2233 4466778899');
insert into test values('661122334455778899');
insert into test values('771122334455668899');
insert into test values('881122334455667799');
insert into test values('991122334455667788');
insert into test values('aabbccddee');
insert into test values('bbaaaccddee');
insert into test values('ccabbddee');
insert into test values('ddaabbccee');
insert into test values('eeaabbccdd');
insert into test values('ab123');
insert into test values('123xy');
insert into test values('007ab');
insert into test values('abcxy');
insert into test values('The final test is is is how to find duplicate words.');
commit;
10.2 测试示例
10.2.1 REGEXP_LIKE
select * from test where regexp_like(mc,'^a{1,3}');
select * from test where regexp_like(mc,'a{1,3}');
select * from test where regexp_like(mc,'^a.*e$');
select * from test where regexp_like(mc,'^[[:lower:]] |[[:digit:]]');
select * from test where regexp_like(mc,'^[[:lower:]]');
Select mc FROM test Where REGEXP_LIKE(mc,'[^[:digit:]]');
Select mc FROM test Where REGEXP_LIKE(mc,'^[^[:digit:]]');
10.2.2 REGEXP_INSTR
Select REGEXP_INSTR(mc,'[[:digit:]]$') from test;
Select REGEXP_INSTR(mc,'[[:digit:]]+$') from test;
Select REGEXP_INSTR('The price is $400.','$[[:digit:]]+') FROM DUAL;
Select REGEXP_INSTR('onetwothree','[^[[:lower:]]]') FROM DUAL;
Select REGEXP_INSTR(',,,,,','[^,]*') FROM DUAL;
Select REGEXP_INSTR(',,,,,','[^,]') FROM DUAL;
10.2.3 REGEXP_SUBSTR
SELECT REGEXP_SUBSTR(mc,'[a-z]+') FROM test;
SELECT REGEXP_SUBSTR(mc,'[0-9]+') FROM test;
SELECT REGEXP_SUBSTR('aababcde','^a.*b') FROM DUAL;
10.2.4 REGEXP_REPLACE
Select REGEXP_REPLACE('Joe Smith','( ){2,}', ',') AS RX_REPLACE FROM dual;
Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '3, 2, 1') FROM dual;
SQL> select * from test;
ID MC
-------------------- ------------------------------------------------------------
A AAAAA
a aaaaa
B BBBBB
b bbbbb
SQL> select * from test where regexp_like(id,'b','i'); --不区分数据大小写
ID MC
-------------------- ------------------------------------------------------------
B BBBBB
b bbbbb
General Information
Anchoring Characters Character Class Description
^ Anchor the expression to the start of a line
$ Anchor the expression to the end of a line
十一、官方说明(英文原版说明)
Equivalence Classes Character Class Description
= = Oracle supports the equivalence classes through the POSIX '[==]' syntax. A base letter and all of its accented versions
constitute an equivalence class. For example, the equivalence class '[=a=]' matches ?nd ?The equivalence classes are valid only
inside the bracketed expression
11.1 Match Options Character Class Description
- c Case sensitive matching
- i Case insensitive matching
- m Treat source string as multi-line activating Anchor chars
- n Allow the period (.) to match any newline character
11.2 Posix Characters Character Class Description
- [:alnum:] Alphanumeric characters
- [:alpha:] Alphabetic characters
- [:blank:] Blank Space Characters
- [:cntrl:] Control characters (nonprinting)
- [:digit:] Numeric digits
- [:graph:] Any [:punct:], [:upper:], [:lower:], and [:digit:] chars
- [:lower:] Lowercase alphabetic characters
- [:print:] Printable characters
- [:punct:] Punctuation characters
- [:space:] Space characters (nonprinting), such as carriage return, newline, vertical tab, and form feed
- [:upper:] Uppercase alphabetic characters
- [:xdigit:] Hexidecimal characters
11.3 Quantifier Characters Character Class Description
'*' Match 0 or more times
'?' Match 0 or 1 time
'+' Match 1 or more times
{m} Match exactly m times
{m,} Match at least m times
{m, n} Match at least m times but no more than n times
\n Cause the previous expression to be repeated n times
11.4 Alternative Matching And Grouping Characters Character Class Description
| Separates alternates, often used with grouping operator ()
( ) Groups subexpression into a unit for alternations, for quantifiers, or for backreferencing (see "Backreferences" section)
[char] Indicates a character list; most metacharacters inside a character list are understood as literals, with the exception of
character classes, and the ^ and - metacharacters
十二 英文示例Demo
Table CREATE TABLE test (
testcol VARCHAR2(50));
INSERT INTO test VALUES ('abcde');
INSERT INTO test VALUES ('12345');
INSERT INTO test VALUES ('1a4A5');
INSERT INTO test VALUES ('12a45');
INSERT INTO test VALUES ('12aBC');
INSERT INTO test VALUES ('12abc');
INSERT INTO test VALUES ('12ab5');
INSERT INTO test VALUES ('12aa5');
INSERT INTO test VALUES ('12AB5');
INSERT INTO test VALUES ('ABCDE');
INSERT INTO test VALUES ('123-5');
INSERT INTO test VALUES ('12.45');
INSERT INTO test VALUES ('1a4b5');
INSERT INTO test VALUES ('1 3 5');
INSERT INTO test VALUES ('1 45');
INSERT INTO test VALUES ('1 5');
INSERT INTO test VALUES ('a b c d');
INSERT INTO test VALUES ('a b c d e');
INSERT INTO test VALUES ('a e');
INSERT INTO test VALUES ('Steven');
INSERT INTO test VALUES ('Stephen');
INSERT INTO test VALUES ('111.222.3333');
INSERT INTO test VALUES ('222.333.4444');
INSERT INTO test VALUES ('333.444.5555');
INSERT INTO test VALUES ('abcdefabcdefabcxyz');
COMMIT;
12.1 REGEXP_COUNT
Syntax REGEXP_COUNT(<source_string>,
-- match parameter:
- 'c' = case sensitive
- 'i' = case insensitive search
- 'm' = treats the source string as multiple lines
- 'n' = allows the period (.) wild character to match newline
- 'x' = ignore whitespace characters
Count's occurrences based on a regular expression SELECT REGEXP_COUNT(testcol, '2a', 1, 'i') RESULT
FROM test;
SELECT REGEXP_COUNT(testcol, 'e', 1, 'i') RESULT
FROM test;
12.2 REGEXP_INSTR
Syntax REGEXP_INSTR(<source_string>,
- Find words beginning with 's' or 'r' or 'p' followed by any 4 alphabetic characters: case insensitive
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 1, 0, 'i') RESULT FROM dual;
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 1, 1, 'i') RESULT
FROM dual;
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 2, 0, 'i') RESULT
FROM dual;
SELECT REGEXP_INSTR('500 Oracle Pkwy, Redwood Shores, CA', '[o][[:alpha:]]{3}', 1, 2, 1, 'i') RESULT
FROM dual;
- Find the position of try, trying, tried or tries
SELECT REGEXP_INSTR('We are trying to make the subject easier.', 'tr(y(ing)?|(ied)|(ies))') RESULTNUM
FROM dual;
- Using Sub-Expression option
SELECT testcol, REGEXP_INSTR(testcol, 'ab', 1, 1, 0, 'i', 0)
FROM test;
SELECT testcol, REGEXP_INSTR(testcol, 'ab', 1, 1, 0, 'i', 1)
FROM test;
SELECT testcol, REGEXP_INSTR(testcol, 'a(b)', 1, 1, 0, 'i', 1)
FROM test;
12.3 REGEXP_LIKE
Syntax REGEXP_LIKE(<source_string>,
- AlphaNumeric Characters
SELECT * FROM test
WHERE REGEXP_LIKE(testcol, '[[:alnum:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alnum:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alnum:]]{5}');
- Alphabetic Characters
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alpha:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alpha:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:alpha:]]{5}');
- Control Characters
INSERT INTO test VALUES ('zyx' || CHR(13) || 'wvu');
COMMIT;
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:cntrl:]]{1}');
Digits
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:digit:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:digit:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:digit:]]{5}');
- Lower Case
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]{2}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:lower:]]{5}');
- Printable Characters
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:print:]]{5}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:print:]]{6}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:print:]]{7}');
- Punctuation
TRUNCATE TABLE test;
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:punct:]]');
- Spaces
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:space:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:space:]]{2}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:space:]]{3}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:space:]]{5}');
- Upper Case
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:upper:]]');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:upper:]]{2}');
SELECT *
FROM test
WHERE REGEXP_LIKE(testcol, '[[:upper:]]{3}');
Values Starting with 'a%b' SELECT testcol
FROM test
WHERE REGEXP_LIKE(testcol, '^ab*');
- 'a' is the third value
SELECT testcol
FROM test
WHERE REGEXP_LIKE(testcol, '^..a.');
- Contains two consecutive occurances of the letter 'a' or 'z'
SELECT testcol
FROM test
WHERE REGEXP_LIKE(testcol, '([az])\1', 'i');
- Begins with 'Ste' ends with 'en' and contains either 'v' or 'ph' in the center
SELECT testcol
FROM test
WHERE REGEXP_LIKE(testcol, '^Ste(v|ph)en$');
- Use a regular expression in a check constraint
CREATE TABLE mytest (c1 VARCHAR2(20),
CHECK (REGEXP_LIKE(c1, '^[[:alpha:]]+$')));
- Identify SSN
CREATE TABLE ssn_test (
ssn_col VARCHAR2(20));
INSERT INTO ssn_test VALUES ('111-22-3333');
INSERT INTO ssn_test VALUES ('111=22-3333');
INSERT INTO ssn_test VALUES ('111-A2-3333');
INSERT INTO ssn_test VALUES ('111-22-33339');
INSERT INTO ssn_test VALUES ('111-2-23333');
INSERT INTO ssn_test VALUES ('987-65-4321');
COMMIT;
SELECT ssn_col
from ssn_test
WHERE REGEXP_LIKE(ssn_col,'^[0-9]{3}-[0-9]{2}-[0-9]{4}$');
12.4 REGEXP_REPLACE
Syntax REGEXP_REPLACE(<source_string>,
<replace_string>,
- Looks for the pattern xxx.xxx.xxxx and reformats pattern to (xxx) xxx-xxxx
col testcol format a15
col result format a15
SELECT testcol, REGEXP_REPLACE(testcol,
'([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})',
'(\1) \2-\3') RESULT
FROM test
WHERE LENGTH(testcol) = 12;
- Put a space after every character
SELECT testcol, REGEXP_REPLACE(testcol, '(.)', '\1 ') RESULT
FROM test
WHERE testcol like 'S%';
Replace multiple spaces with a single space SELECT REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA', '( ){2,}', ' ') RESULT
FROM dual;
- Insert a space between a lower case character followed by an upper case character
SELECT REGEXP_REPLACE('George McGovern', '([[:lower:]])([[:upper:]])', '\1 \2') CITY
FROM dual;
Replace the period with a string (note use of '\') SELECT REGEXP_REPLACE('We are trying to make the subject easier.','\.',' for you.') REGEXT_SAMPLE
FROM dual;
Demo CREATE TABLE t(
testcol VARCHAR2(10));
INSERT INTO t VALUES ('1');
INSERT INTO t VALUES ('2 ');
INSERT INTO t VALUES ('3 new ');
- col newval format a10
SELECT LENGTH(testcol) len, testcol origval,
REGEXP_REPLACE(testcol, '\W+$', ' ') newval,
LENGTH(REGEXP_REPLACE(testcol, '\W+$', ' ')) newlen
FROM t;
12.5 REGEXP_SUBSTR
Syntax REGEXP_SUBSTR(source_string, pattern[, position [, occurrence[, match_parameter]]])
- Searches for a comma followed by one or more occurrences of non-comma characters followed by a comma
SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA', ',[^,]+,') RESULT
FROM dual;
- Look for http:// followed by a substring of one or more alphanumeric characters and optionally, a period (.)
col result format a50
SELECT REGEXP_SUBSTR('Go to http://www.oracle.com/products and click on database',
'http://([[:alnum:]]+\.?){3,4}/?') RESULT
FROM dual;
- Extracts try, trying, tried or tries
SELECT REGEXP_SUBSTR('We are trying to make the subject easier.','tr(y(ing)?|(ied)|(ies))')
FROM dual;
- Extract the 3rd field treating ':' as a delimiter
SELECT REGEXP_SUBSTR('system/pwd@orabase:1521:sidval',
'[^:]+', 1, 3) RESULT
FROM dual;
- Extract from string with vertical bar delimiter
CREATE TABLE regexp (
testcol VARCHAR2(50));
INSERT INTO regexp
(testcol)
VALUES
('One|Two|Three|Four|Five');
SELECT * FROM regexp;
SELECT REGEXP_SUBSTR(testcol,'[^|]+', 1, 3)
FROM regexp;
- Equivalence classes
SELECT REGEXP_SUBSTR('iSelfSchooling NOT ISelfSchooling', '[[=i=]]SelfSchooling') RESULT
FROM dual;
- Parsing Demo set serveroutput on
DECLARE
x VARCHAR2(2);
y VARCHAR2(2);
c VARCHAR2(40) := '1:3,4:6,8:10,3:4,7:6,11:12';
BEGIN
x := REGEXP_SUBSTR(c,'[^:]+', 1, 1);
y := REGEXP_SUBSTR(c,'[^,]+', 3, 1);
dbms_output.put_line(x ||' '|| y);
END;
/