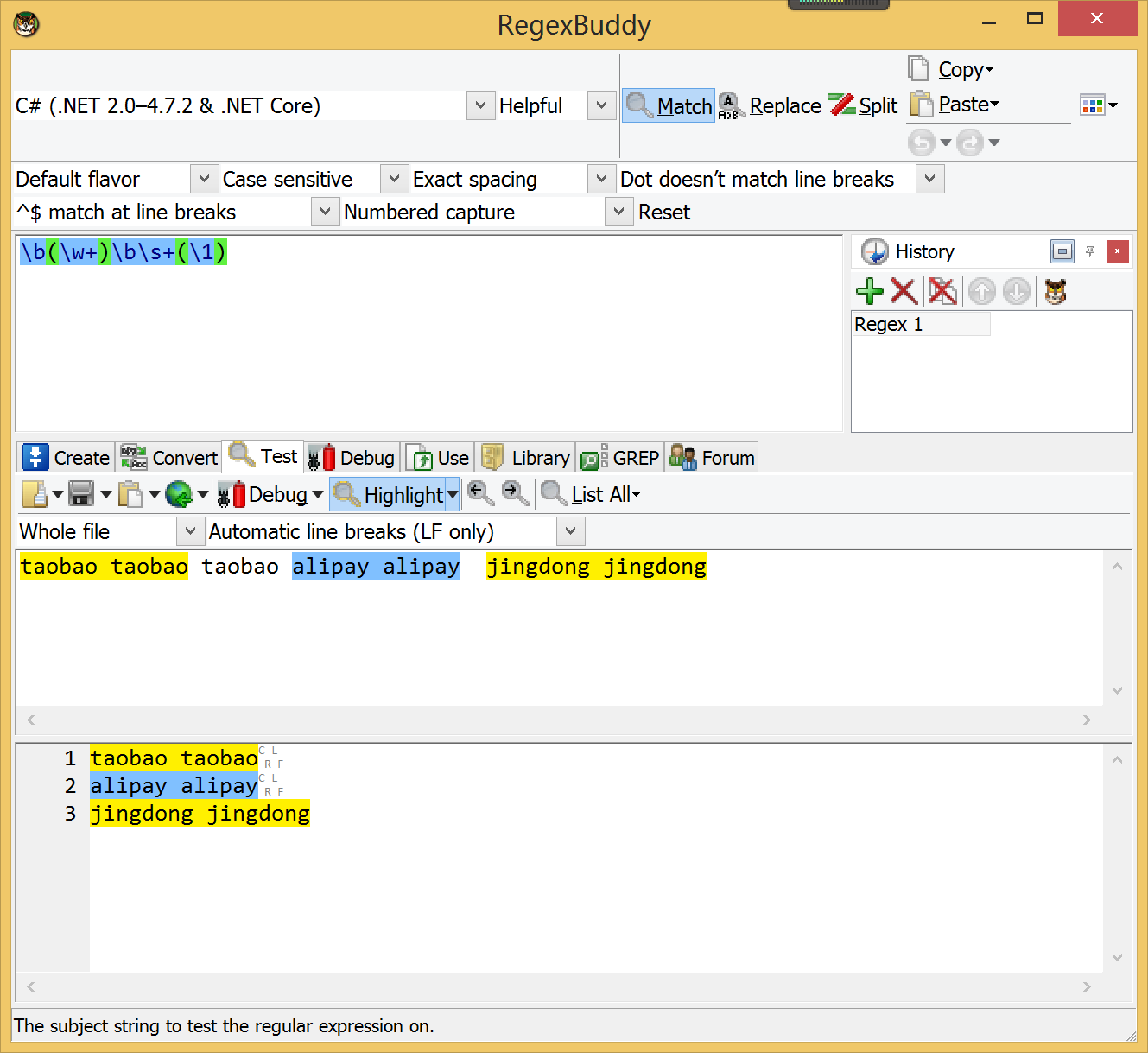
一般来说,递归的正则表达式用来匹配任意嵌套层次的结构或左右对称的结构。例如匹配:
((((()))))
(hello (world) good (boy) bye)
<p>hello world <strong>hello world</strong> </p>
abc.def.ghij...stu.vwx.yz
abcdcba
123454321
递归正则在正则表达式里算是比较灵活的部分,换句话说就是可能会比较难。下面这个正则表达式是在网上流传的非常广泛的递归正则的示例,它用来匹配嵌套任意次数的括号,括号内可以有其它字符,比如可以匹配(a(bc)de)、(abc(bc(def)c)de)。
# 使用了x修饰符,忽略正则表达式内的空白符号
/\( ( (?>[^()]+) | (\g<0>) )* \)/x
这似乎看不怎么懂?其实即使知道了正则递归的方式,也还是很难看懂(至少,我分析了很久)。
难懂的原因大概是因为这里使用的固化分组在多选分支|中属于一个技巧性的写法,而且分组外还使用了量词*,这些结合起来就太难懂了。
正因为网上到处流传这个例子,曾使我多次对递归正则的学习望而却步。这里我也不去解释这个递归正则的含义,因为"太学术化"或者说"太装xyx逼",而一般递归正则完全可以写的很简单但却能实现目标。
如何写出简单易懂版本的递归正则并且理解递归正则的匹配方式,正是本文的目标。在后文,我介绍了一个更加简单、更加容易理解的版本,同样能实现这个递归匹配的需求。
为了解释清楚递归正则,本文会以循序渐进的方式逐步深入到递归正则的方方面面。所以,篇幅可能稍大,其中大量篇幅都用在了解释分析递归正则是如何递归匹配上。
注:
本文以Ruby的正则表达式来介绍递归正则,但对其它支持递归正则的语言也是能通用的。例如Perl、PHP、Python(自带的re不提供,但第三方库regex提供递归正则)等。
理解反向引用\N和\g
首先通过正则表达式的反向引用的用法来逐步引入递归正则表达式的用法。
正则表达式(abc|def) and \1xyz可以匹配字符串"abc and abcxyz"或"def and defxyz",但是不能匹配"abc and defxyz"或def and abcxyz。这是因为,反向引用在引用的时候,只能引用之前分组捕获成功后的那个结果。
reg = /(abc|def) and \1xyz/
reg =~ "abc and abcxyz" #=>0
reg =~ "def and defxyz" #=>0
reg =~ "def and abcxyz" #=>nil
reg =~ "abc and defxyz" #=>nil
但是,如果使用\g<1>来代替\1,那么就能匹配这四种情形的字符串(Perl中使用(?1)对应这里的\g<1>):
reg = /(abc|def) and \g<1>xyz/
reg =~ "abc and abcxyz" #=>0
reg =~ "def and defxyz" #=>0
reg =~ "def and abcxyz" #=>0
reg =~ "abc and defxyz" #=>0
\g<1>和\1的区别在于:\1在反向引用的时候,引用的是该分组捕获到的结果值,\g<1>则不是反向引用,而是直接将索引号为1的分组捕获重新执行捕获分组的匹配操作。相当于是/(abc|def) and (abc|def)xyz/。
所以,\1相当于是在引用的位置插入索引号为1的分组捕获的结果,\g<1>相当于是在此处插入索引号为1的分组捕获表达式,让其能再次进行分组表达式这部分的匹配操作。

如果把分组捕获表达式看作是函数的定义,那么开始匹配时表示调用该函数进行分组捕获。而反向引用\N则是在引用位置处插入该函数的返回值,\g<name>则表示在此处再次调用该函数进行匹配。
\g<name>的name可以是数值型的分组索引号,也可以是命名捕获的名称索引,还可以是0表示整个正则表达式自身。
/(abc|def) and \g<1>xyz/
/(?<var>abc|def) and \g<var>xyz/
/(abc|def) and \g<0>xyz/ # 错误正则,稍后分析
=begin
# Perl、Python(regex,非re)、PHP与之对应的方式:
\g<0> -> (?R)或(?0)
\g<N> -> (?N)
\g<name> -> (?P>name)或(?&name)
=end
前面两种好理解,第三种使用\g<0>就不太能理解了,继续向下看。
初探递归正则:递归正则匹配什么
\g<0>表示正则表达式自身,所以这相当于是递归正则表达式,假如进行第一轮正则表达式替换的话,相当于:
/(abc|def) and (abc|def) and \g<0>xyzxyz/
当然,这里只是为了帮助理解才将\g<0>替换成正则表达式,但它不会真的直接替换正则表达式的定义。就像函数调用时,不会在调用函数的地方替换成函数定义里的代码再去执行,函数定义了就能多次复用。
不管怎样,不难发现这里已经出现了无限递归的可能性,因为替换一轮后的正则表达式中再次包含了\g<0>,它可以再次进行第二轮替换、第三轮替换......
那么,对于/(abc|def) and \g<0>xyz/这个递归的正则表达式来说,它能匹配什么样的字符串呢?这才是理解正则递归时最需要关心的。
可以将上面的\g<0>看作是一个占位符,首先它可以匹配"abc and _xyz"或者def and _xyz这种格式的字符串,这里我用了_表示\g<0>占位符。递归一轮的话,它可以匹配"abc and def and _xyzxyz",这里又会继续递归下去,将没完没了。所以这里先将该正则匹配什么字符串的问题保留,稍后再回头分析。
事实上,/(abc|def) and \g<0>xyz/是错误的正则表达式,它会提示我们,递归没有终点:
/(abc|def) and \g<0>xyz/
#=>SyntaxError: never ending recursion
所以,使用递归正则必须要保证递归能够有终点。
保证正则递归的终点
怎么保证递归正则的终点呢?只要给\g<>这部分做一个量词的限定即可,比如:
\g<0>+ # 错误正则
\g<0>{3} # 错误正则
\g<0>{,3} # 错误正则
\g<0>* # 正确正则
\g<0>? # 正确正则
\g<0>{0} # 正确正则
pat|\g<0> # 正确正则
(\g<0>)* # 正确正则
(\g<0>)? # 正确正则
...
\g<0>+表示递归至少1轮,但是这里已经错了,因为递归多次的时候,\g<0>这个占位符及其量词+将始终保留在最后一轮的结果中,于是导致无限递归。同理\g<0>{3}这种表示严格递归三次的方式也是错误的,因为递归第三次后仍然保留了\g<0>{3}占位符及其量词{3},这也将无限递归。
所以,只有\g<0>*和\g<0>?和\g<0>{0}和pat|\g<0>等这种能在量词数量选择意义上表示递归0次的方式才是正确的正则表达式语法,因为无论递归多少次,最后一次的占位符的量词都可以是0次,从而达到递归的终点,即停止递归。
所以,修改前面的正则表达式,假如使用?量词修饰\g<>:
/(abc|def) and \g<0>?xyz/
再探递归正则:递归正则匹配什么
回到之前遗留的问题,现在这个正确的递归正则表达式/(abc|def) and \g<0>?xyz/能匹配什么样的字符串呢?
按照之前的分析,它能匹配的字符串的模式类似于abc and _?xyz或者def and _?xyz。
如果量词?取0次,那么该递归正则匹配的是"abc and xyz"或"def and xyz":
reg = /(abc|def) and \g<0>?xyz/
reg =~ "abc and xyz" #=> 0
reg =~ "def and xyz" #=> 0
如果量词?取1次,那么该递归一轮后的正则模式为abc and abc and _?xyzxyz,其中任何一个"abc"替换成"def"都是满足条件的。那么这里又有了\g<>量词的次数选择问题。
假如这里量词?取0次,也就是从开始到现在总体递归了一轮。那么该递归正则匹配到是:
reg = /(abc|def) and \g<0>?xyz/
reg =~ "abc and abc and xyzxyz" #=> 0
reg =~ "abc and def and xyzxyz" #=> 0
reg =~ "def and def and xyzxyz" #=> 0
reg =~ "def and abc and xyzxyz" #=> 0
如果递归一轮后的量词?继续取1次呢?那么下一轮递归仍将会有量词次数选择的问题。
至此,应该理解了递归正则的基本匹配方式。不过这里使用的\g<0>递归还很基础,下面将继续逐步深入。
深入递归(1):括号分组内的\g
前面的递归示例中是将能表示递归的表达式\g<0>部分放在分组的外面,这种情况下,只有\g<0>这种形式才能算是递归,如果是\g<1>或\g<name>,就算不上是递归,充其量也就是个表达式的调用。
但是,当需要使用递归正则来解决问题的时候,递归表达式往往是在分组内部而不是在分组外部的。所以,前面解释的递归方式其实非常少见。于是,要使用递归正则,还得继续深入探索。
首先看一个非常简单的组内递归正则表达式:
/(abc\g<1>?xyz)+/
这个表达式中,进行了一个分组捕获,这个分组首先匹配abc字符,然后在分组捕获内使用了表达式\g<1>?(注意这个?是不能少的,当然?也可以换成其它的前面解释过的量词),紧随其后的是匹配字符xyz。由于这里的\g<1>?放在1号索引对应的分组捕获的内部,所以就形成了一个递归的正则表达式。
问题是,这个正则表达式能匹配什么样的字符串呢?要学会递归正则表达式,必须会分析它能够匹配什么类型的字符串。
仍然,以占位符的方式来表示\g<1>,那么该递归正则表达式匹配的字符串模式为:"abc_?xyz" * N,这个* N表示重复N次,因为这种表达式的括号分组外面有一个+符号。
如果量词?选择为0次,也就是不进行递归,则匹配字符串"abcxyz" * N:
/(abc\g<1>?xyz)+/ =~ "abcxyz" #=> 0
/(abc\g<1>?xyz)+/ =~ "abcxyzabcxyz"
#=> 0
/(abc\g<1>?xyz)+/ =~ "abcxyzabcxyzabcxyz"
#=> 0
/(abc\g<1>?xyz)+/ =~ "abcxyz" * 10
#=> 0
如果量词?选择为1次,那么进行一轮递归后,匹配的字符串模式为:"abcabc_?xyzxyz" * N。再次进行?量词的次数选择,假如选0次,那么匹配的字符串是"abcabcxyzxyz" * N:
/(abc\g<1>?xyz)+/ =~ "abcabcxyzxyz" #=> 0
/(abc\g<1>?xyz)+/ =~ "abcabcxyzxyzabcabcxyzxyz"
#=> 0
/(abc\g<1>?xyz)+/ =~ "abcabcxyzxyz" * 3
#=> 0
再继续分析一轮递归。假设这是?量词选择1次,那么进行第二轮的递归,匹配的字符串模式为:"abcabcabc_?xyzxyzxyz" * N。
至此,应该不难推测出递归正则表达式/(abc\g<1>?xyz)+/匹配的字符串的模式:
"abcxyz" * N
"abcabcxyzxyz" * N
"abcabcabcxyzxyzxyz" * N
# 归纳后,即匹配如下通用模式:n和N均大于等于1
("abc" * n + "xyz" * n) * N
将目光集中于刚才的递归正则表达式/(abc\g<1>?xyz)+/,如果能通过这个正则表达式直接推测匹配何种类型字符串呢?
量词+或其它可能的量词先不看,先将焦点放在分组捕获。这个分组捕获匹配的是abc_?xyz,如果要进行递归N轮,那么每一轮都是abc_?xyz这种模式,直接将其替换到该正则中去观察:abc(abc_?xyz)*xyz,其中(abc_?xyz)*表示这部分重复0或N次。当然替换后的这部分不是标准的正则,只是为了有助于理解才将不同地方的概念混在一起,我想并不会对你的理解造成歧义。
这样理解起来就不难了。当然这个递归正则比较简单,如果把上面的\g<1>?换成\g<1>*,看上去又会更复杂一点。那么它匹配什么样的字符串呢?
同样的分析方式,将/(abc\g<1>*xyz)+/看作是"abc_*xyz" * N的结构,然后对*取值,假设取值3次,所以递归后的结果看上去类似于:
"abc(abc_*xyz)(abc_*xyz)(abc_*xyz)xyz" * N
上面的每个括号里都可以对量词*做选择,但要到达递归的终点,最后(可能是递归了好多轮后)每一个递归里的*都必须取值0次才能终结这个递归。
所以,假如现在这3个括号里的每个*都选择0次,那么匹配的字符串模式类似于:
"abc(abcxyz)(abcxyz)(abcxyz)xyz" * N
# 即等价于:n和N均大于等于1
( "abc" + "abcxyz" * n + "xyz" ) * N
例如:
/(abc\g<1>*xyz)+/ =~ ( "abc" + "abcxyz" * 1 + "xyz" ) * 1
#=> 0
/(abc\g<1>*xyz)+/ =~ ( "abc" + "abcxyz" * 1 + "xyz" ) * 2
#=> 0
/(abc\g<1>*xyz)+/ =~ ( "abc" + "abcxyz" * 4 + "xyz" ) * 2
#=> 0
假如上面三个括号里第一个括号里的*取值1次,后面两个括号里的*取值0次,那么再次递归后,匹配的字符串模式类似于:
"abc(abc(abc_*xyz)xyz)(abcxyz)(abcxyz)xyz" * N
没错,又要做量词的次数选择。假如这次*取0次,那么将终结本次递归匹配,它匹配的字符串模式为:
"abc(abc(abcxyz)xyz)(abcxyz)(abcxyz)xyz" * N
那么如果*不是按照上面的次数进行选择的,那么匹配的字符串模式是怎样的?
没有答案,唯一准确的答案就是回归这个正则表达式的含义:它匹配的字符串模式为(abc\g<1>*xyz)+。
深入递归(2):写递归正则(入门)
前面一直都是根据给定的递归正则表达式去分析能匹配什么样的字符串,这对于理解递归正则有所帮助。但是我们更想要掌握的是如何根据字符串写出递归的正则表达式。
一般来说,要使用递归正则去匹配,往往是要匹配嵌套的一些东西,如果不是匹配嵌套内容,很可能不会想到要去用递归正则。这里,假设也要去匹配嵌套的东西。
先从简单的嵌套开始。比如,如何匹配无限嵌套的空括号()、(())、((())),即"(" * n + ")" * n?
分析一下。如果不递归的话,那就是匹配一对小括号(),所以这两小括号字符必须要在分组内,即(\(\))。(如果使用\g<0>来递归的话,则可以不用在分组内,不过这里先不考虑这种情况。)
按照前文多次对递归正则表达式匹配何种字符串的分析,用占位符替代要递归的话,要匹配的嵌套括号的字符串模式大概是这样的:(_)。所以递归表达式\g<1>要在\(和\)的中间,即(\(\g<1>\))。
这里还少了个量词来保证递归的终点。那么使用什么样的量词呢?
使用\g<1>*肯定没问题,只要*号每次递归都只选择量词1次,并且最后一轮递归选择0次终结递归即可,那么匹配的模式是((_*))、(((_*)))等等,这正好符合嵌套匹配。
/(\(\g<1>*\))/ =~ "(" * 1 + ")" * 1
#=> 0
/(\(\g<1>*\))/ =~ "(" * 3 + ")" * 3
#=> 0
/(\(\g<1>*\))/ =~ "(" * 10 + ")" * 10
#=> 0
看别人写的递归正则,往往会在分组后加上*号量词,即(\(\g<1>*\))*,针对于这种模式的嵌套,其实这个*是多余的,它要匹配成功,这个量词必须只能选0或1次。如果选择多于1次,那么匹配的字符串模式就变成了"((_*))" * N,更标准一点的表示方式是( "(" * n + ")" * n ) * N,当然,前面也说了,这还有无数种其他的匹配可能。
所以,在这里我不在分组的后面加*或+这样的量词。要继续刚才的讨论。
使用\g<1>?这种量词方式可以吗?当然可以,上面分析\g<1>*的时候,是说当每一轮递归时的*次数选择都是1次或0次,就能匹配无限嵌套的小括号。对于\g<1>?来说当然也可以,因为?也可以表示0或1次。
/(\(\g<1>?\))/ =~ "(" * 1 + ")" * 1
#=> 0
/(\(\g<1>?\))/ =~ "(" * 3 + ")" * 3
#=> 0
/(\(\g<1>?\))/ =~ "(" * 10 + ")" * 10
#=> 0
这两种递归正则表达式,都是符合要求的,都能匹配无限嵌套的小括号。
下面是命名捕获版本的:
/(?<var>\(\g<var>?\))/ =~ "(" * 3 + ")" * 3
#=> 0
也能直接使用\g<0>作为嵌套表达式,这时甚至可以去掉分组:
/(?<var>\(\g<0>?\))/ =~ "(" * 3 + ")" * 3
#=> 0
# 去掉分组,直接递归这种本身
/\(\g<0>?\)/ =~ "(" * 3 + ")" * 3
#=> 0
这样看上去,写递归正则好像也不难。其实嵌套模式简单的递归正则确实不难,只要理解递归的含义基本上就能写出来。再看另一个示例。
深入递归(3):写递归正则(进阶)
假设要匹配的字符串模式为:(abc(d(xy)e)fgh),其中每个括号内的字符长度任意。这似乎正是本文开头所举的例子。
这一个递归写起来其实非常非常简单:
# 为了可读性,使用了x修饰符忽略表达式内的空白符号
/\( [^()]* \g<0>* [^()]* \)/x
# 匹配:
reg = /\( [^()]* \g<0>* [^()]* \)/x
reg =~ "(abc(d(xy)e)fgh)" #=> 0
reg =~ "(abc(d(xy)))" #=> 0
reg =~ "((()e)fgh)" #=> 0
reg =~ "((()))" #=> 0
其中\([^()]*和[^()]*\)是头和尾,中间使用\g<0>来无限嵌套头和尾。逻辑其实很简单。
相比于网上流传的版本/\( ( (?>[^()]+) | (\g<0>) )* \)/x,此处所给出的写法应该容易理解的多。
再回头扩充刚才的递归匹配需求,如果需要匹配的字符串是ab(abc(d(xy)e)fgh)df这种模式呢?另一个问题,这种字符串模式和(abc(d(xy)e)fgh)有什么区别呢?
仔细比对一下,(abc(d(xy)e)fgh)按左右括号划分配对的话,它左右刚好能够成对数:(abc (d (xy ) e) fgh)(这里用一个空格分隔,从内向外互相成对)。但ab(abc(d(xy)e)fgh)df按左右括号划分配对的话,得到的是ab( abc( d( xy )e )fgh )df,显然,它中间多了一层无法成对的内容xy。
为了写出按照这种成对划分的递归表达式,先不考虑多出来无法成对的xy这一层。那么对应的递归正则表达式为:
/[^()]* \( \g<0>* \) [^()]*/x
其中[^()]*\(是头部,\)[^()]*是尾部,中间用\g<0>*实现头尾成对的无限嵌套。
再来考虑中间多出来的无法成对的xy这部分。其实直接将这部分放在\g<0>*的左边或右边都无所谓。例如:
# 放\g<0>*的左边
/[^()]* \( [^()]* \g<0>* \) [^()]*/x
# 放\g<0>*的右边
/[^()]* \( \g<0>* [^()]* \) [^()]*/x
没错,写递归的正则表达式就是这么简单粗暴。
只是,现实并不这么美好,上面将多余的无法配对的部分放在了递归表达式的左边或右边,但有时候这样是不行的。
解决多余无法成对内容的更通用方法是使用二选一的分支结构,即|结合递归表达式一起使用,参见下一小节。
深入递归(4):递归结合二选一分支
要处理上面多出的无法成对的数据,可以通过二选一结构|改写成如下更通用的方式:
/[^()]* \( \g<0>* \) [^()]* |./x
进行匹配测试:
reg = /[^()]* \( \g<0>* \) [^()]* |./x
reg =~ "ab(abc(d(xy)e)fgh)df"
#=> 0
当递归正则表达式结合了|提供的二选一分支功能时,|左边或右边(和\g<>相反的那一边)都可以用来提供这些"孤儿"数据。
例如,上面示例中,当递归进行到发现xy这部分是多余的时候将无法继续匹配,这时候将可以从二选一的另一个分支来匹配这个多余的数据。
但是这个二选一分支带来了一个新的问题:只要有无法匹配的,都可以去另一个分支匹配。假如右边的分支是个.,这就相当于多了一个万能箱,什么都可以从这里匹配。
但如果无法匹配的多余字符是右括号或左括号这个必须的字符呢?少了任何一个括号,都不再算是成对的嵌套结构,但却因为二选一分支而匹配成功。
如何解决这个问题?第一,需要保证另一分支不是万能的.;第二,需将整个结构做位置锚定。例如:
/\A ( [^()]* \( \g<1>* \) [^()]* | [^()] ) \Z/x
注意,上面加了括号分组,所以\g<0>随之改变成\g<1>,因为递归的时候并不需要将锚定也包含进来。
当然,上面示例中二选一分支的另一个分支所使用的是单字符匹配[^()],如果有多个连续的多余字符,这会导致多次选中该分支。为了减少匹配的测试次数,可以将其直接写成[^()]*。
/\A ( [^()]* \( \g<1>* \) [^()]* | [^()]* ) \Z/x
但这有可能会在匹配失败的时候导致大量的回溯,从而性能暴降。例如,如下失败的匹配:
reg = /\A([^()]* \( \g<1>* \) [^()]* | [^()]* )\Z/x
# 匹配失败性能暴降
(st=Time.now) ; (reg =~ "ab(abc(d(xy)e)fghdf") ; (Time.now - st)
#=> 1.7730072
(st=Time.now) ; (reg =~ "ab(abc(d(xy)e)fghdffds") ; (Time.now - st)
#=> 47.5858051
# 匹配成功则无影响
(st=Time.now) ; (reg =~ "ab(abc(d(xy)e)fgh)df") ; (Time.now - st)
#=> 5.9e-06
从结果发现,就这么短的字符串,第一个匹配失败竟需要花费1.8秒,第二个字符串更夸张,仅仅只是多了3个字符,耗费的时间飙升到47秒。
解决方法有很多种,这里提供两种:一种是将*号直接移到分组外,这虽然并不等价,但并不影响最终的匹配结果;另一种是将该多选分支使用固化分组或占有优先的模式。
reg1 = /\A([^()]* \( \g<1>* \) [^()]* | [^()] )*\Z/x
reg2 = /\A([^()]* \( \g<1>* \) [^()]* | (?>[^()]*) )\Z/x
# 匹配成功
(st=Time.now) ; (reg1 =~ "ab(abc(d(xy)e)fgh)df") ; (Time.now - st)
#=> 6.1e-06
(st=Time.now) ; (reg2 =~ "ab(abc(d(xy)e)fgh)df") ; (Time.now - st)
#=> 5.8e-06
# 匹配失败
(st=Time.now) ; (reg1 =~ "ab(abc(d(xy)e)fghdf") ; (Time.now - st)
#=> 8.46e-05
(st=Time.now) ; (reg2 =~ "ab(abc(d(xy)e)fghdf") ; (Time.now - st)
#=> 0.0004223
深入递归(5):小心递归中的分组捕获
在介绍示例之前,先验证一下结论。
在递归过程中,可能也会有分组捕获的表达式,所以,递归正则设置的相关变量值是最后一次分组捕获对应的状态。例如:
reg = /(abc|def) and \g<0>?xyz/
# 只递归一轮
reg =~ "abc and def and xyzxyz" #=> 0
# $~表示本次所匹配到的所有字符串
$~
#=> #<MatchData "abc and def and xyzxyz" 1:"def">
# $1表示第一个分组捕获所对应的内容
$1 #=> "def"
上面结果可以看出,在递归过程中,最后一轮的递归操作(此处示例即第一轮递归)设置了一些正则匹配时的变量,它会覆盖在它之前的递归设置的结果。
再来看一个示例。现在有个需求:匹配任何长度的回文字符串(palindrome),比如1234321、abcba、好不好、abccba、好、好好、123321,该示例只能使用二选一的分支来实现。
这里简单分析一下,如何通过递归正则来实现该需求。
假设要匹配的这个字符串是abcdcba,先把多余的字符d去掉,那么要匹配的是abccba,这也是我们想要匹配的一种字符串模式。首先,左右配对的部分必须是完全一致的数据,这个递归正则其实很容易实现,用占位符来描述,大概模式为:(.)_*\1。将其替换成递归正则表达式:
/(.) \g<0>* \1/x
再来考虑多余的那个字符,直接将其放在二选一分支的另一分支即可:因为二选一分支,所以这里的\g<0>就可以不用量词修饰来保证递归的终点
/(.) \g<0> \1 |./x
最后,加上位置锚定。
/\A ( (.) \g<1> \2|.) \Z/x
似乎已经没问题了,去测试匹配下:
/\A ( (.) \g<1> \2|.) \Z/x =~ "abcba"
#=> nil
结果却并不如想象中那样成功。
不过,这个正则表达式的逻辑确实是没有问题的。例如,使用grep -P(使用PCRE)执行等价的正则去匹配回文字符串。
$ grep -P "^((.)(?1)\2|.)$" <<<"abcdcba"
abcdcba
# 下面的则失败
$ grep -P "^((.)(?1)\2|.)$" <<<"abcdcbad"
但是这个"正确的"正则表达式在Ruby中却无法达到目标。这是因为Ruby中的递归也会设置分组捕获,每个\2所反向引用的就不再是每轮递归中同层次的分组捕获(.)的内容了,而是真正的从左向右的第二个分组捕获括号所捕获的内容。
好在,Ruby提供了更加灵活的分组捕获的引用控制。除了\N这种方式的反向引用,也可以通过\k<N>或\k<name>来引用,灵活之处在于\k<>支持递归层次的偏移,例如\k<name+0>表示取当前递归层次里的name分组捕获,\k<name+1>和\k<name-1>分别表示取当前递归层的下一层和上一层里的name分组捕获。
所以,在Ruby中改一下这个正则表达式就能正常工作:
/\A ( (.) \g<1> \k<2+0>|.) \Z/x =~ "abcba"
#=> 0
/\A ( (.) \g<1> \k<2+0>|.) \Z/x =~ "abcbaa"
#=> nil
当然,用命名捕获也是可以的:
/\A (?<i> (?<j>.) \g<i> \k<j+0>|.) \Z/x
最后,可以将上面的正则表达式改动一番。上面正则中,多选分支的.一直都是放在尾部的(放头部也没问题),但下面这种将多选分支和递归表达式嵌在一个分组内也是很常见的用法。下面这两种递归正则表达式是等价的。
/\A (?<i> (?<j>.) \g<i> \k<j+0>|.) \Z/x
/\A (?<i> (?<j>.) (?:\g<i>|.) \k<j+0> ) \Z/x
(?:\g<i>|.)进行了分捕获的分组,分组将它们两绑定在一个组内,如果不分组将会出错,因为|的优先级太低。
不要滥用递归正则
虽然递归正则确实能解决一些特殊需求,但是能不用尽量不用,因为递归正则要配合量词来修饰递归表达式,这本身不是问题,但是递归表达式很多时候在分组内,而分组本身可能也会用量词去修饰,这样两个量词一结合,一不小心可能就出现大量的回溯,导致匹配效率疯狂下降。
前文已经演示过一个这样的现象,仅仅只是多了3个字符,匹配失败竟然需要多花费40多秒,而且随着字符的增多,匹配失败所需时间飙升的更快。这绝对是我们要去避免的。
所以,当写出来的递归正则表达式里又是分组、又是量词,看上去还"乱七八糟"的结合在一起,很可能会出现性能不佳的问题。这时候可能需要去调试优化,以便写出高性能的递归正则,但这可能会耗去大量的时间。
所以,尽量想其它方法来解决递归正则想要实现的匹配需求,或者只写看上去就很简单的递归正则。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html