编程范式
编程是 程序 员 用特定的语法+数据结构+算法 组成的代码来告诉计算机如何执行任务的过程 。
一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大路通罗马,实现一个任务的方式有很多种不同的方式, 对这些不同的编程方式的特点进行归纳总结得出来的编程方式类别,即为编程范式。 不同的编程范式本质上代表对各种类型的任务采取的不同的解决问题的思路, 大多数语言只支持一种编程范式,当然也有些语言可以同时支持多种编程范式。 两种最重要的编程范式分别是面向过程编程和面向对象编程。
面向过程:核心是过程二字,过程指的是解决问题的步骤,设计一条流水线,机械式的思维方式。
优点:复杂的问题流程化,进而简单化。
缺点:可扩展性差
面向对象:核心就是对象二字,对象就是特征与技能的结合体。
优点:可扩展性强
缺点:编程复杂度高
应用场景:用户需求经常变化,互联网应用,游戏,企业内部应用
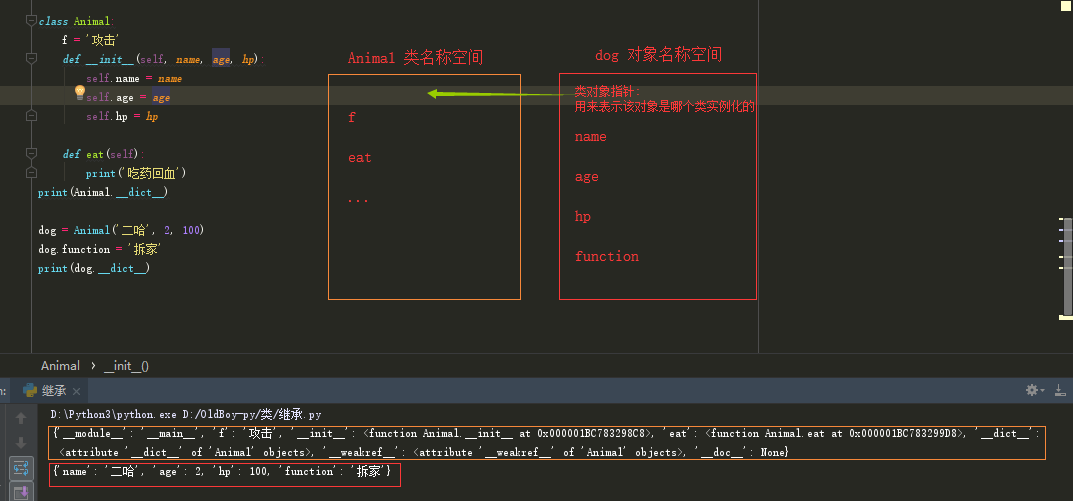
类:
类就是一系列对象相似的特征与技能的结合体。
站在不同的角度,得到的分类是不一样的。
在程序中:一定得先定义类,后调用类来产生对象
1 class luffystudent: 2 school = 'luffycity' # 数据属性 3 4 def learn(self): # 函数属性 5 print('is learning') 6 7 def eat(self): # 函数属性 8 print('is sleeping') 9 10 # 查看类的名称空间 11 print(luffystudent.__dict__) 12 print(luffystudent.__dict__['school']) 13 print(luffystudent.__dict__['eat']) 14 # 查 15 # print(luffystudent.__dict__['school']) 16 print(luffystudent.school) 17 # print(luffystudent.__dict__['eat']) 18 print(luffystudent.eat) 19 20 # 增 21 luffystudent.county = 'China' 22 print(luffystudent.county) 23 24 # 删 25 del luffystudent.county 26 print(luffystudent.__dict__) 27 28 # 改 29 luffystudent.school = 'LUffycity' 30 print(luffystudent.school)
补充说明:
站的角度不同,定义出的类是截然不同的:
现实中的类并不完全等于程序中的类,比如现实中的公司类,在程序中有时需要拆分部门类;业务类等:
有时为了编程需求,程序中也可能定义现实中不存在的类,比如策略类,现实中并不存在,但是在程序中却是一个很常见的类
1 # __init__改方法是在对象产生之后才会执行,只用来对象进行初始化操作,可以有任意代码,但一定不能有返回值 2 class luffystudent: 3 school = 'luffycity' # 数据属性 4 5 def __init__(self,name,sex,age): 6 self.Name = name 7 self.Sex = sex 8 self.Age = age 9 10 def learn(self):# 函数属性 11 print('%s is learning'% self.Name) 12 13 def eat(self): # 函数属性 14 print('is sleeping') 15 # 类中的数据属性:是所有对象共有的! 16 # 类中的函数属性:是绑定给对象使用的,绑定到不同的对象是不同的绑定方法 17 stu1 = luffystudent('周瑜','男','20') 18 stu2 = luffystudent('刘备','男','18') 19 stu3 = luffystudent('小乔','女','20') 20 luffystudent.learn(stu1)
继承(什么是继承?)
继承指的是类与类之间的关系,是一种什么“是”什么的关系,继承的功能之一就是用来解决代码重用问题
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可以成为基类或超类,新建的类称为派生类或子类
python中类的继承分为:单继承和多继承
1 class ParentClass1: #定义父类 2 pass 3 4 class ParentClass2: #定义父类 5 pass 6 7 class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass 8 pass 9 10 class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类 11 pass
查看继承类
1 >>> SubClass1.__bases__ #__base__只查看从左到右继承的第一个子类,__bases__则是查看所有继承的父类 2 (<class '__main__.ParentClass1'>,) 3 >>> SubClass2.__bases__ 4 (<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现。
1 >>> ParentClass1.__bases__ 2 (<class 'object'>,) 3 >>> ParentClass2.__bases__ 4 (<class 'object'>,)
继承与抽象(先抽象再继承)
继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构。
继承与重用性
在开发程序的过程中,如果我们定义了一个类A,然后又想新建立另外一个类B,但是类B的大部分内容与类A的相同时
我们不可能从头开始写一个类B,这就用到了类的继承的概念。
通过继承的方式新建类B,让B继承A,B会‘遗传’A的所有属性(数据属性和函数属性),实现代码重用
再看属性查找
提示:像g1.life_value之类的属性引用,会先从实例中找life_value然后去类中找,然后再去父类中找...直到最顶级的父类。那么如何解释下面的打印结果呢?
1 class Foo: 2 def f1(self): 3 print('from Foo.f1') 4 5 def f2(self): 6 print('from Foo.f2') 7 self.f1() # b.f1() 8 9 class Bar(Foo): 10 def f1(self): 11 print('from Bar.f1') 12 13 b = Bar() 14 b.f2() 15 16 # 输出 17 from Foo.f2 18 from Bar.f1
派生
当然子类也可以添加自己新的属性或者在自己这里重新定义这些属性(不会影响到父类),需要注意的是,一旦重新定义了自己的属性且与父类重名,那么调用新增的属性时,就以自己为准了。
继承的实现原理
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如
1 F.mro() #等同于F.__mro__ 2 [<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, 3 <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
在python2中》经典类:没有继承object的类,以及它的子类都称之为经典类
class Foo:
pass
class Bar(Foo):
pass
在python2中》新式类:继承object的类,以及它的子类都称之为新式类
class Foo(object):
pass
class Bar(Foo):
pass
在python3中》新式类:一个类没有继承object类,默认就继承object
class Foo():
pass
print(Foo.__bases__)
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如果继承了多个父类,那么属性的查找方式有两种,分别是:深度优先和广度优先
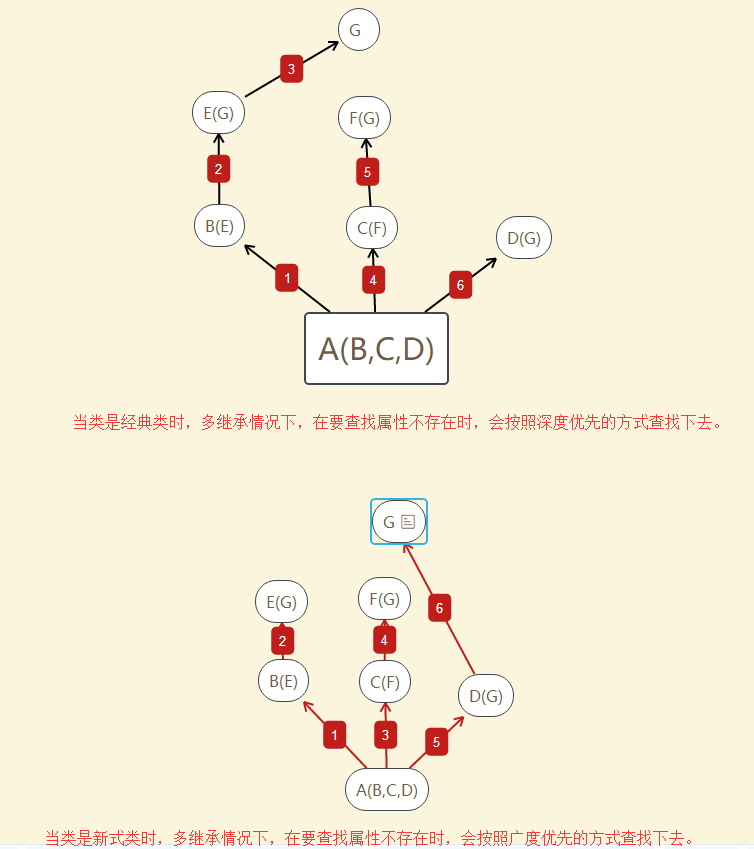
代码如下:
1 class A(object): 2 def test(self): 3 print('from A') 4 5 class B(A): 6 def test(self): 7 print('from B') 8 9 class C(A): 10 def test(self): 11 print('from C') 12 13 class D(B): 14 def test(self): 15 print('from D') 16 17 class E(C): 18 def test(self): 19 print('from E') 20 21 class F(D,E): 22 # def test(self): 23 # print('from F') 24 pass 25 f1=F() 26 f1.test() 27 print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 28 29 #新式类继承顺序:F->D->B->E->C->A 30 #经典类继承顺序:F->D->B->A->E->C 31 #python3中统一都是新式类 32 #pyhon2中才分新式类与经典类
在子类中调用父类的方法
在子类派生出的新方法中,往往需要重用父类的方法,我们有两种方式实现
方式一:指名道姓,即父类名.父类方法()
1 class Vehicle: #定义交通工具类 2 Country='China' 3 def __init__(self,name,speed,load,power): 4 self.name=name 5 self.speed=speed 6 self.load=load 7 self.power=power 8 9 def run(self): 10 print('开动啦...') 11 12 class Subway(Vehicle): #地铁 13 def __init__(self,name,speed,load,power,line): 14 Vehicle.__init__(self,name,speed,load,power) # 指名道姓 15 self.line=line 16 17 def run(self): 18 print('地铁%s号线欢迎您' %self.line) 19 Vehicle.run(self) 20 21 line13=Subway('中国地铁','180m/s','1000人/箱','电',13) 22 line13.run()
方式二:super()
1
2 class A: 3 def f1(self): 4 print('from A') 5 super().f1() 6 7 class B: 8 def f1(self): 9 print('from B') 10 11 class C(A, B): 12 pass 13 14 print(C.mro()) 15 c= C() 16 c.f1()
A没有继承B,但是A内super会基于C.mro()继续往后找输出:
[<class '__main__.C'>,
<class '__main__.A'>,
<class '__main__.B'>,
<class 'object'>]
from A
from B
这两种方式的区别是:方式一是跟继承没有关系的,而方式二的super()是依赖于继承的,并且即使没有直接继承关系,super仍然会按照mro继续往后查找
组合与重用性
组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合
1 class Equip: 2 3 def fire(self): 4 print('release Fire skill') 5 6 class Riven: # 英雄Riven的类,一个英雄需要有装备,因而需要组合Equip类 7 camp = 'Noxus' 8 9 def __init__(self,nickname): 10 self.nickname = nickname 11 self.equip = Equip() # 用Equip类产生一个装备,赋值给实例的equip属性 12 13 r1 = Riven('兔女郎') 14 r1.equip.fire()
输出:
release Fire skill
组合与继承都是有效地利用已有类的资源的重要方式。但是二者的概念和使用场景皆不同,
1.继承的方式
通过继承建立了派生类与基类之间的关系,它是一种'是'的关系,比如白马是马,人是动物。
当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好,比如老师是人,学生是人
2.组合的方式
用组合的方式建立了类与组合的类之间的关系,它是一种‘有’的关系,比如教授有生日,教授教python和linux课程,教授有学生s1、s2、s3...
总结:
当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好
接口与归一化设计
1.什么是接口
hi boy,给我开个查询接口。。。此时的接口指的是:自己提供给使用者来调用自己功能的方式\方法\入口,j
2. 为何要用接口
接口提取了一群类共同的函数,可以把接口当做一个函数的集合。
然后让子类去实现接口中的函数。
这么做的意义在于归一化,什么叫归一化,就是只要是基于同一个接口实现的类,那么所有的这些类产生的对象在使用时,从用法上来说都一样。
归一化的好处在于:
- 归一化让使用者无需关心对象的类是什么,只需要的知道这些对象都具备某些功能就可以了,这极大地降低了使用者的使用难度。
- 归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合
- 就好象linux的泛文件概念一样,所有东西都可以当文件处理,不必关心它是内存、磁盘、网络还是屏幕(当然,对底层设计者,当然也可以区分出“字符设备”和“块设备”,然后做出针对性的设计:细致到什么程度,视需求而定)。
- 再比如:我们有一个汽车接口,里面定义了汽车所有的功能,然后由本田汽车的类,奥迪汽车的类,大众汽车的类,他们都实现了汽车接口,这样就好办了,大家只需要学会了怎么开汽车,那么无论是本田,还是奥迪,还是大众我们都会开了,开的时候根本无需关心我开的是哪一类车,操作手法(函数调用)都一样
模仿interface
在python中根本就没有一个叫做interface的关键字,如果非要去模仿接口的概念
可以借助第三方模块:http://pypi.python.org/pypi/zope.interface
也可以使用继承,其实继承有两种用途
一:继承基类的方法,并且做出自己的改变或者扩展(代码重用):实践中,继承的这种用途意义并不很大,甚至常常是有害的。因为它使得子类与基类出现强耦合。
二:声明某个子类兼容于某基类,定义一个接口类(模仿java的Interface),接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子类继承接口类,并且实现接口中的功能
1 class Interface:#定义接口Interface类来模仿接口的概念,python中压根就没有interface关键字来定义一个接口。 2 def read(self): #定接口函数read 3 pass 4 5 def write(self): #定义接口函数write 6 pass 7 8 9 class Txt(Interface): #文本,具体实现read和write 10 def read(self): 11 print('文本数据的读取方法') 12 13 def write(self): 14 print('文本数据的读取方法') 15 16 class Sata(Interface): #磁盘,具体实现read和write 17 def read(self): 18 print('硬盘数据的读取方法') 19 20 def write(self): 21 print('硬盘数据的读取方法') 22 23 class Process(Interface): 24 def read(self): 25 print('进程数据的读取方法') 26 27 def write(self): 28 print('进程数据的读取方法')
上面的代码只是看起来像接口,其实并没有起到接口的作用,子类完全可以不用去实现接口 ,这就用到了抽象类
抽象类
1 什么是抽象类
与java一样,python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化
2 为什么要有抽象类
如果说类是从一堆对象中抽取相同的内容而来的,那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。
比如我们有香蕉的类,有苹果的类,有桃子的类,从这些类抽取相同的内容就是水果这个抽象的类,你吃水果时,要么是吃一个具体的香蕉,要么是吃一个具体的桃子。。。。。。你永远无法吃到一个叫做水果的东西。
从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。
从实现角度来看,抽象类与普通类的不同之处在于:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。这一点与接口有点类似,但其实是不同的,即将揭晓答案
抽象类与接口
抽象类的本质还是类,指的是一组类的相似性,包括数据属性(如all_type)和函数属性(如read、write),而接口只强调函数属性的相似性。
抽象类是一个介于类和接口直接的一个概念,同时具备类和接口的部分特性,可以用来实现归一化设计
多态
多态指的是一类事物有多种形态,比如
动物有多种形态:人,狗,猪
多态性
一 什么是多态动态绑定(在继承的背景下使用时,有时也称为多态性)
多态性是指在不考虑实例类型的情况下使用实例,多态性分为静态多态性和动态多态性
静态多态性:如任何类型都可以用运算符+进行运算
二 为什么要用多态性(多态性的好处)
其实大家从上面多态性的例子可以看出,我们并没有增加什么新的知识,也就是说python本身就是支持多态性的,这么做的好处是什么呢?
1.增加了程序的灵活性
以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal)
2.增加了程序额可扩展性
通过继承animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用
封装
从封装本身的意思去理解,封装就好像是拿来一个麻袋,把小猫,小狗,小王八,还有alex一起装进麻袋,然后把麻袋封上口子。照这种逻辑看,封装=‘隐藏’,这种理解是相当片面的
这种自动变形的特点:
- 类中定义的__x只能在内部使用,如self.__x,引用的就是变形的结果。
- 这种变形其实正是针对外部的变形,在外部是无法通过__x这个名字访问到的。
- 在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:_子类名__x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。
这种变形需要注意的问题是:
1、这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如a._A__N
2、变形的过程只在类的定义是发生一次,在定义后的赋值操作,不会变形
3、在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的
封装不是单纯意义的隐藏
1:封装数据
将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口,然后我们可以在接口附加上对该数据操作的限制,以此完成对数据属性操作的严格控制。
2:封装方法:
目的是隔离复杂度
类中定义的函数分成两大类
一:绑定方法(绑定给谁,谁来调用就自动将它本身当作第一个参数传入):
绑定到类的方法:用classmethod装饰器装饰的方法。
为类量身定制
类.boud_method(),自动将类当作第一个参数传入
(其实对象也可调用,但仍将类当作第一个参数传入)绑定到类的方法:用classmethod装饰器装饰的方法。
为类量身定制
类.boud_method(),自动将类当作第一个参数传入
(其实对象也可调用,但仍将类当作第一个参数传入)
二:非绑定方法:用staticmethod装饰器装饰的方法
- 不与类或对象绑定,类和对象都可以调用,但是没有自动传值那么一说。就是一个普通工具而已
注意:与绑定到对象方法区分开,在类中直接定义的函数,没有被任何装饰器装饰的,都是绑定到对象的方法,可不是普通函数,对象调用该方法会自动传值,而staticmethod装饰的方法,不管谁来调用,都没有自动传值一说
非绑定方法
在类内部用staticmethod装饰的函数即非绑定方法,就是普通函数
statimethod不与类或对象绑定,谁都可以调用,没有自动传值效果
import settings import time import hashlib class People: def __init__(self,name, age, sex): self.id = self.create_id() self.name = name self.age = age self.sex = sex def tell_info(self): # 绑定到对象的方法 print('Name:%s Age:%s Sex:%s'%(self.name,self.age,self.sex)) @classmethod def from_conf(cls): obj = cls(settings.name, settings.age, settings.sex ) return obj @classmethod def create_id(cls): m = hashlib.md5(str(time.time()).encode('utf-8')) return m.hexdigest() p = People.from_conf() p.tell_info() print(p.id)
isinstance(obj,cls)检查obj是否是类 cls 的对象
class Foo(object):
pass
obj = Foo()
isinstance(obj, Foo) # 判断obj是不是Foo的实列
issubclass(sub, super)检查sub类是否是 super 类的派生类
class Foo(object):
pass
class Bar(Foo):
pass
issubclass(Bar, Foo) # 判断Foo是不是Bar的父类反射
1 什么是反射
反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力(自省)。这一概念的提出很快引发了计算机科学领域关于应用反射性的研究。它首先被程序语言的设计领域所采用,并在Lisp和面向对象方面取得了成绩。
2 python面向对象中的反射:通过字符串的形式操作对象相关的属性。python中的一切事物都是对象(都可以使用反射)
四个可以实现自省的函数 下列方法适用于类和对象(一切皆对象,类本身也是一个对象)
hasattr(object,name)
判断object中有没有一个name字符串对应的方法或属性
1 # 反射:通过字符串映射到对象的属性 2 class People: 3 def __init__(self,name,age): 4 self.name = name 5 self.age = age 6 7 def talk(self): 8 print('%s is talking'%self.name) 9 10 11 obj = People('zhou',18) 12 13 print(hasattr(obj,'name')) # obj.name 14 print(hasattr(obj,'talk')) # obj.talk 15 16 print(getattr(obj,'name',None)) 17 print(getattr(obj,'talk',None)) 18 # 增 19 setattr(obj,'sex','male') # obj.sex = 'male' 20 print(obj.sex) 21 # 删 22 delattr(obj,'age') # del obj.age
反射应用
1 class Service: 2 def run(self): 3 while True: 4 inp = input('>>:').strip() # inp get a.txt 5 cmds= inp.split() # cmds = ['get' , 'a.txt'] 6 if hasattr(self, cmds[0]): 7 func = getattr(self, cmds[0]) 8 func(cmds) 9 10 def get(self, cmds): 11 print('get......', cmds) 12 13 def put(self, cmds): 14 print('put.......', cmds) 15 16 obj = Service() 17 obj.run()
item 系列
1 class Foo: 2 def __init__(self,name): 3 self.name = name 4 5 def __getitem__(self, item): 6 print('getitem....') 7 return self.__dict__.get(item) 8 9 10 def __setitem__(self, key, value): 11 # print('setitem......') 12 # print(key,value) 13 self.__dict__[key] = value 14 15 def __delitem__(self, key): 16 # print('delitem......') 17 # print(key) 18 del self.__dict__[key] 19 20 obj = Foo('zhou') 21 # print(obj.__dict__) 22 # 查看属性 23 # obj.属性名 24 print(obj['namexxx']) 25 # 设置属性 26 # obj.sex = 'male' 27 obj['sex'] = 'male' 28 print(obj.__dict__) 29 # 删除属性 30 # del obj.name 31 del obj['name'] 32 print(obj.__dict__)
__str__ 方法
1 class People: 2 def __init__(self,name,age): 3 self.name = name 4 self.age = age 5 6 def __str__(self): 7 return '<name:%s,age:%s>'%(self.name,self.age) 8 9 obj = People('zhou',18) 10 print(obj)
__del__
析构方法,当对象在内存中被释放时,自动触发执行。
注:如果产生的对象仅仅只是python程序级别的(用户级),那么无需定义__del__,如果产生的对象的同时还会向操作系统发起系统调用,即一个对象有用户级与内核级两种资源,比如(打开一个文件,创建一个数据库链接),则必须在清除对象的同时回收系统资源,这就用到了__del__。
1 # f.close() # 回收操作系统资源 2 class Open: 3 def __init__(self,filename): 4 print('open file.....') 5 self.filename = filename 6 7 def __del__(self): 8 print('回收操作系统资源:self.close()') 9 10 f = Open('setting.py') 11 del f # f.__del__() 12 print('------main-------')
元类
三个参数
参数一:字符串形式的命令
参数二:全局作用域(字典形式),如果不指定,默认为globals()
参数三:局部作用域(字典形式),如果不指定,默认为locals()
1 #可以把exec命令的执行当成是一个函数的执行,会将执行期间产生的名字存放于局部名称空间中 2 g={ 3 'x':1, 4 'y':2 5 } 6 l={} 7 8 exec(''' 9 global x,z 10 x=100 11 z=200 12 13 m=300 14 ''',g,l) 15 16 print(g) #{'x': 100, 'y': 2,'z':200,......} 17 print(l) #{'m': 300}
python 一切皆对象,对象怎么用?
1、都可以被引用, x = obj
2、都可以当作函数的参数传入
3、都可以当作函数的返回值
4、都可以当作容器类的元素, l = [func,time,obj,1]
1 class Foo: # 类也是对象 2 pass 3 obj = Foo() 4 print(type(obj)) 5 print(type(Foo)) 6 7 class Bar: 8 pass 9 print(type(Bar))
定义类的两种方式:
方式一:class
1 class Chinese: # Chinese = type(.....) 2 country = 'China' 3 4 def __init__(self,name,age): 5 self.name = name 6 self.age = age 7 8 def talk(self): 9 print('%s is talking'%self.name) 10 11 print(Chinese) 12 obj = Chinese('zhou',18) 13 print(obj,obj.name,obj.age)
方式二:type
定义类的三要素:类名,类的基类名,类的名称
1 class_name = 'Chinese' 2 class_bases = (object,) 3 class_body = ''' 4 country = 'China' 5 6 def __init__(self,name,age): 7 self.name = name 8 self.age = age 9 10 def talk(self): 11 print('%s is talking'%self.name) 12 ''' 13 class_dic = {} 14 exec(class_body,globals(),class_dic) 15 Chinese1 = type(class_name,class_bases,class_dic) 16 print(Chinese1) 17 obj1 = Chinese1('zhou',18) 18 print(obj1,obj1.name,obj1.age)
输出结果:
<class '__main__.Chinese'>
<__main__.Chinese object at 0x0000015768C67EF0> zhou 18
<class '__main__.Chinese'>
<__main__.Chinese object at 0x0000015768C67FD0> zhou 18
我们看到,type 接收三个参数:
- 第 1 个参数是字符串 ‘Foo’,表示类名
- 第 2 个参数是元组 (object, ),表示所有的父类
- 第 3 个参数是字典,这里是一个空字典,表示没有定义属性和方法
补充:若Foo类有继承,即class Foo(Bar):.... 则等同于type('Foo',(Bar,),{})
五 自定义元类控制类的行为
一个类没有声明自己的元类,默认他的元类就是type,除了使用元类type,用户也可以通过继承type来自定义元类(顺便我们也可以瞅一瞅元类如何控制类的行为,工作流程是什么)1 class Mymeta(type): 2 def __init__(self,class_name,class_bases,class_dic): 3 # istitle 判断首字母是不是大写 4 if not class_name.istitle(): 5 raise TypeError('类名的首字母必须是大写') 6 if '__doc__' not in class_dic or not class_dic['__doc__'].strip(): 7 raise TypeError('必须有注释,且注释不能为空') 8 9 super(Mymeta,self).__init__(class_name,class_bases,class_dic) 10 class Chinese(object,metaclass=Mymeta): 11 ''' 12 xxx 13 ''' 14 country = 'China' 15 16 def __init__(self,name,age): 17 self.name = name 18 self.age = age 19 def talk(self): 20 print('%s is talking'%self.name)
__call__方法
1 class Foo: 2 def __call__(self, *args, **kwargs): 3 print(self) 4 print(args) 5 print(kwargs) 6 obj = Foo() 7 obj(1,2,3,a=1,b=2,c=3) # obj.__call__(obj,1,2,3,a=1,b=2,c=3) 8 # 元类内部也应有一个__call__方法,会在调用Foo时触发执行 9 Foo(1,2,x=1) # Foo.__call__(Foo,1,2,x = 1)
应用
1 class Mymeta(type): 2 def __init__(self,class_name,class_bases,class_dic): 3 # istitle 判断首字母是不是大写 4 if not class_name.istitle(): 5 raise TypeError('类名的首字母必须是大写') 6 if '__doc__' not in class_dic or not class_dic['__doc__'].strip(): 7 raise TypeError('必须有注释,且注释不能为空') 8 9 super(Mymeta,self).__init__(class_name,class_bases,class_dic) 10 def __call__(self, *args, **kwargs): 11 print(self) # self = Chinese 12 print(args) # args = ('zhou') 13 print(kwargs) # kwargs = {'age':18} 14 # 1 , 先造一个空对象obj 15 obj = object.__new__(self) 16 # 2 ,初始化obj 17 self.__init__(obj, *args, **kwargs) 18 # 3 ,返回obj 19 return obj 20 21 class Chinese(object,metaclass=Mymeta): 22 ''' 23 xxx 24 ''' 25 country = 'China' 26 27 def __init__(self,name,age): 28 self.name = name 29 self.age = age 30 def talk(self): 31 print('%s is talking'%self.name) 32 33 obj = Chinese('zhou',18)# Chinese.__call__(Chinese,'zhou',18)