编程范式:
1. 面向过程编程: 核心是“过程”,“过程”指的是解决问题的步骤;就相当于在设计一条流水线
优点:复杂问题流程化,进而简单化
缺点:可扩展性差,前一发动全身
2. 面向对象:核心是“对象”,对象就是特征与技能的结合体
优点: 可扩展性强
缺点: 编程复杂度高
应用场景: 用户需求经常变化,如:互联网应用、游戏、企业内部应用
类:
类就是一系列对象相似的特征与技能的结合体(相当于一个模板),特征用变量表示,技能用函数表示
强调: 站在不同的角度,得到的分类是不一样的
在程序中: 一定是先定义类,后调用类产生对象
定义类、产生对象的方法如下:
"""定义类""" class Student: # 类的首字母大写 school = "Luffycity" def learn(self): print("is learning") def eat(self): print("is eating") def sleep(self): print("is sleeping") """调用类产生对象""" stu1 = Student() # Student() 不是执行类体的代码,而是得到一个返回值,这个返回值就是产生的对象;这个过程也叫“实例化” stu2 = Student() # 类名调用一次就是实例化一次 stu3 = Student() print(stu1) print(stu2) print(stu3) # 输出结果: # <__main__.Student object at 0x0000001F205C6438> # <__main__.Student object at 0x0000001F205C66D8> # <__main__.Student object at 0x0000001F205C6668>
类的使用:
定义类时,在类定义阶段它内部的代码就能够运行,如下:
class Student: # 类的首字母大写 school = "Luffycity" # 特征 print("test") def learn(self): # 技能 print("is learning") def eat(self): print("is eating") def sleep(self): print("is sleeping") # 运行结果: # test
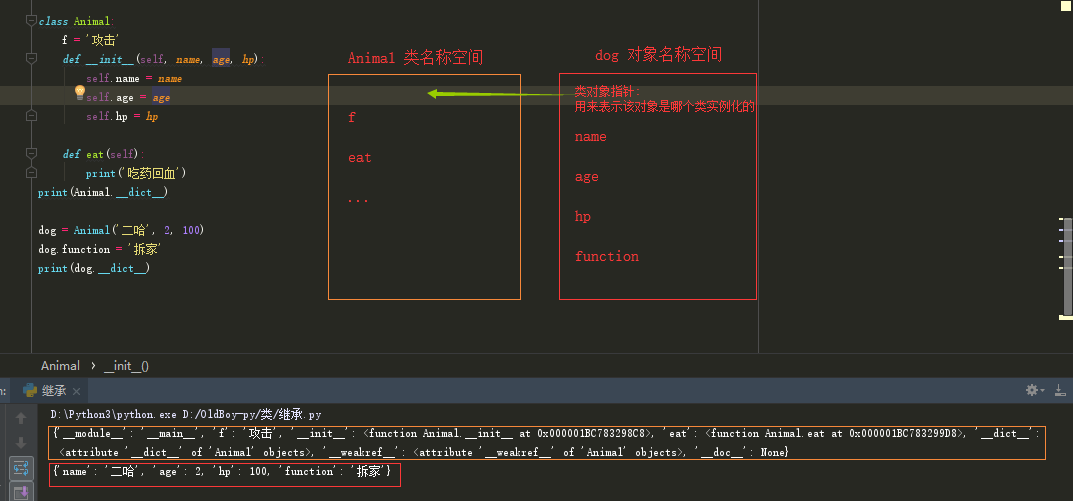
查看类里面的名称空间:
class Student: # 类的首字母大写 school = "Luffycity" # 类的数据属性 def learn(self): # 类的函数属性 print("is learning") def eat(self): print("is eating") def sleep(self): print("is sleeping") print(Student.__dict__) print(Student.__dict__["school"]) print(Student.__dict__["learn"])
"""查看""" print(Student.school) print(Student.learn) """类定义完后增加属性""" Student.country = "China" # 往Student这个类里面增加了 country = "China" print(Student.__dict__) print(Student.country) """删除""" del Student.country print(Student.__dict__) """修改""" Student.country = "Greater China" print(Student.country) # 打印结果: # {'__module__': '__main__', 'school': 'Luffycity', 'learn': <function Student.learn at 0x000000711C26B9D8>, 'eat': <function Student.eat at 0x000000711C26BA60>, 'sleep': <function Student.sleep at 0x000000711C26BD90>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None} # Luffycity # <function Student.learn at 0x000000711C26B9D8> # Luffycity # <function Student.learn at 0x000000711C26B9D8> # {'__module__': '__main__', 'school': 'Luffycity', 'learn': <function Student.learn at 0x000000711C26B9D8>, 'eat': <function Student.eat at 0x000000711C26BA60>, 'sleep': <function Student.sleep at 0x000000711C26BD90>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None, 'country': 'China'} # China # {'__module__': '__main__', 'school': 'Luffycity', 'learn': <function Student.learn at 0x000000711C26B9D8>, 'eat': <function Student.eat at 0x000000711C26BA60>, 'sleep': <function Student.sleep at 0x000000711C26BD90>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None} # Greater China
类内部定义的变量是类的数据属性 ,定义的函数是其函数属性
类的用途:
1. 对属性的操作
2. 实例化产生一个个对象 (利用 Student() 方法)
对象的使用方法:
利用 init 方法来为对象定制自己独有的特征
class Student: school = "Luffycity" def __init__(self,name,gender,age): # 实例化的时候就会自动调用 __init__函数 self.Name = name self.Gender = gender self.Age = age # 字典形式 """ stu1.Name = "苍老师" stu1.Gender = "女" stu1.Age = 18 """ def learn(self): print("is learning") def eat(self): print("is eating") def sleep(self): print("is sleeping") stu1 = Student("苍老师","女",18)
stu2 = Student("武藤兰","男",38) """ 有__init__函数时的实例化步骤: 1. 先产生一个空对象stu1(不带自己独特属性的对象) 2. 触发__init__函数,触发方式为:Student.__init__() , 这是一个函数,就需要按照函数的方式进行传参,即: Student.__init__(stu1,name,gender,age) (第一步生成的对象stu1传入self的位置) Student.__init__(stu1,name,gender,age) 产生的效果如__init__函数中的注释所示。 (添加独有属性后,对象的内存地址不变)
3. 返回 带自己独特属性的对象stu1 """ """ stu1 = Student("苍老师","女",18) 这是在给一个对象定制一个属性,与类添加属性一个道理,往对象里面添加属性也涉及到名称空间的变动,只不过这个名称空间是stu1的名称空间(因为是往stu1这个对象里面添加的新属性) """ print(stu1.__dict__) # 打印结果: # {'Name': '苍老师', 'Gender': '女', 'Age': 18} """ 通过__init__的方法, stu1这个对象不但拥有类共有的那些特征和技能,并且也有了自己独有的属性""" """查看""" print(stu1.Name) print(stu1.Gender) # 打印结果: # 苍老师 # 女 """改""" stu1.Name = "苍井空" print(stu1.__dict__) print(stu1.Name) # 打印结果: # {'Name': '苍井空', 'Gender': '女', 'Age': 18} # 苍井空 """增加""" stu1.job = "adult video" print(stu1.__dict__) print(stu1.job) # 打印结果: # {'Name': '苍井空', 'Gender': '女', 'Age': 18, 'job': 'adult video'} # adult video """删除""" del stu1.job print(stu1.__dict__) # 打印结果: # {'Name': '苍井空', 'Gender': '女', 'Age': 18}
类中的数据属性是所有对象共有的;
类中的函数属性:是绑定给对象使用的,而且绑定到不同的对象是不同的绑定方法
还以上面的代码为例:
print(Student.school,id(Student.school)) print(stu1.school,id(stu1.school)) # 打印结果: # Luffycity 586247585648 # Luffycity 586247585648 """类中的数据属性是所有对象共有的,用的都是同一块内存地址"""
"""类中的函数属性:是绑定给对象,而且绑定到不同的对象是不同的绑定方法"""
print(Student.learn)
print(stu1.learn)
print(stu2.learn)
# 打印结果: (函数的内存地址也不一样)
# <function Student.learn at 0x0000005FB155BA60> # 类名.功能名 是一个函数的内存地址,就是一个函数,那就按函数的方法去执行,而且函数不会自动传参的
# <bound method Student.learn of <__main__.Student object at 0x0000005FB15667B8>> # 对象.功能名是一种绑定方法,所以能够自动传参
# <bound method Student.learn of <__main__.Student object at 0x0000005FB15667F0>> # 功能跟不同对象的绑定方法不一样
把上述例子中类的代码稍微修改,如下:
class Student: school = "Luffycity" def __init__(self, name, gender, age): # 实例化的时候就会自动调用 __init__函数 self.Name = name self.Gender = gender self.Age = age # 字典形式 def learn(self): print("%s is learning" % self.Name) def eat(self): print("%s is eating" % self.Name) def sleep(self): print("%s is sleeping" % self.Name) stu1 = Student("苍老师", "女", 18) stu2 = Student("武藤兰","男",38)
调用 Student.learn() 函数的方法:(此函数需传入参数)
Student.learn(stu1) # Student.learn()就是一个普通的函数,所以可以利用函数的调用方式去执行它;函数的参数要传入上一步产生的stu1, 因为在类中定义learn()函数时,里面有参数self # 执行结果: # 苍老师 is learning
调用stu1.learn()函数的方法: (此函数无需传入参数,因为learn功能只需传入参数self,而stu1会自动传入self)
"""调用stu1.learn()函数""" stu1.learn() # 这个函数调用的是类Student下的learn的功能,stu1会作为参数自动传入到self这个形参中 # 执行结果: # 苍老师 is learning
即: 类中的函数属性是绑定给对象使用的,绑定到不同的对象是不同的绑定方法,对象调用绑定方式时,会把对象本身当做第一个参数,传入self
类中定义的功能(即 函数)是给对象使用的(绑定给对象使用的),而且是哪个对象来调用就把哪个对象作为参数自动传入到self中(这是 绑定关系),这样 哪个对象在调用就是哪个对象在执行类中的功能;类如果自己使用还需要自己传入对象(传入到self中),会比较笨拙
对象只存放自己独有的特征,相似的特征都放在类里面;这涉及到对象的属性查找问题,如果对象中的属性跟类中的属性重名,则以对象中的属性为准(类似于函数中变量的先局部后全局)(例外,属性不会去全局里面找,因为你是在调用类,或者说这是类的调用)
"""有重名""" stu1.x = "CN" Student.x = "中国" print(stu1.x) print(Student.x) # 打印结果: # CN # 中国 """无重名时,对象调用类中的""" Student.x = "中国" print(stu1.x) print(Student.x) # 打印结果: # 中国 # 中国
补充说明1:
1. 站在不同角度,定义出的类是不同的
2. 现实中的类并不完全等同于程序中的类,比如现实中的公司类,在程序中有时需拆分成部门类、业务类等
3. 有时为了变成需求,程序中可能会定义现实中不存在的类,比如策略类,现实中不存在,但在程序中是一个很常见的类
补充说明2:
Python中一切皆对象,并且在Python3中统一了类与类型的概念
class Student: school = "Luffycity" def __init__(self, name, gender, age): # 实例化的时候就会自动调用 __init__函数 self.Name = name self.Gender = gender self.Age = age # 字典形式 def learn(self): print("%s is learning" % self.Name) def eat(self): print("%s is eating" % self.Name) def sleep(self): print("%s is sleeping" % self.Name) print(type([1,2])) print(list) # [1,2] 和 list是Python中的列表这个数据类型 print(Student) # Student 是我们自己创建的类 # 打印结果: # <class 'list'> # <class 'list'> # <class '__main__.Student'> """ Python3中统一了类与类型的概念 """ # 站在类的角度考虑下面已学过的知识 list1 = [1,2,3] # 这种方法的本质是 list1 = list([1,2,3]) 即 调用list这个类并传入参数[1,2,3],进而产生list1这个对象,并且[1,2,3]放入到了list1的命名空间中; list1中独有的特征就是[1,2,3] list2 = [] # 同理, list2 = list() list1.append(4) # 这行代码的含义是:list1这个对象调用了list这个类下面的 append() 这个功能(函数)。 print(list1) """ list1.append(4) 其实就相当于 list.append(list1,4) 即 list这个类调用其内部的append()函数,并把list1这个对象传入到self这个形参中 """ list.append(list1,5) print(list1) # 打印结果: # [1, 2, 3, 4] # [1, 2, 3, 4, 5] list2.append(1) # list2.append(1) : 添加的1只能添加到list2中,不会添加到list1中,因为是list2这个对象在调用append(1)这个功能 print(list2) # 打印结果: # [1] """所以,在Python中一切皆对象"""
可扩展性:
使用类可以将数据与专门操作该数据的功能捆绑在一起
例题1:
编写一个学生类,产生多个学生对象
要求: 有一个计数器(属性),统计总共实例化了多少个对象
代码如下:
class Student: school = "luffycity" count = 0 def __init__(self,name,gender,age): self.name = name self.gender = gender self.age = age # self.count += 1 # 这种方式是不可行的,因为每次添加count时都添加到了对象的特有属性里面,再产生下一个对象时,新产生的对象并不知道上一个对象count的值是多少;而且由于 __init__ 里面没有对 count 这个变量赋值,所以 self.count 会向类的公共属性里面去寻找count 的值 """正确写法""" Student.count += 1 # 在 __init__函数里面对类Student的公共属性count进行处理;count变量并没有添加到对象命名空间中(没有添加到对象的独有属性中),count一直都是在类Student的命名空间里 def learn(self): print("%s is learning" %self.name) """ 分析要求: 每次实例化都会触发 __init__ 函数,所以可以考虑在 __init__ 上进行计数 首先在类的公共属性上添加一个 count = 0 """ stu1 = Student("neo","male",18) stu2 = Student("苍老师","female",16) stu3 = Student("美奈子","female",17) print(stu1.count) # 此时的 stu1.count 调用的是类 Student中的变量count,stu1中是没有count这个变量的 print(stu2.count) print(stu3.count) print(stu1.__dict__) print(stu2.__dict__) print(stu3.__dict__) print(Student.count) # 打印结果: # 3 # 3 # 3 # {'name': 'neo', 'gender': 'male', 'age': 18} # {'name': '苍老师', 'gender': 'female', 'age': 16} # {'name': '美奈子', 'gender': 'female', 'age': 17} # 3
例题二:
模仿LOL定义两个英雄类
要求:
英雄需要有昵称、攻击力、生命值等属性
实例化出两个英雄对象
英雄之间可以互殴,被打的一方掉血,血量小于0则判定为死亡
以下是自己写的:(只定义了一个英雄类)
class Hero: def __init__(self,name,attack,life): self.name = name self.attack = attack self.life = life def fighted(self,attacked = 0): self.life -= attacked if self.life <= 0: print("%s is dead" %self.name) else: print("%s is alive" %self.name) kasaa = Hero("卡萨丁",1000,2000) kayle = Hero("凯尔",1300,1500) kayle.fighted(kasaa.attack) kayle.fighted(kasaa.attack)
示例代码:
class Garen: camp = "Demacia" def __init__(self,nickname,attack,life): self.nickname = nickname self.attack = attack self.life = life def attacking(self,enemy): enemy.life -= self.attack class Riven: camp = "Noxus" def __init__(self,nickname,attack,life): self.nickname = nickname self.attack = attack self.life = life def attacking(self,enemy): enemy.life -= self.attack garen = Garen("草丛伦",30,100) riven = Riven("瑞雯雯",50,80) print(riven.life) garen.attacking(riven) # 英雄(对象)之间的交互 print(riven.life) # 运行结果 # 80 # 50
上述代码中有大量重复的代码,利用“继承”来解决。(转下篇文章)