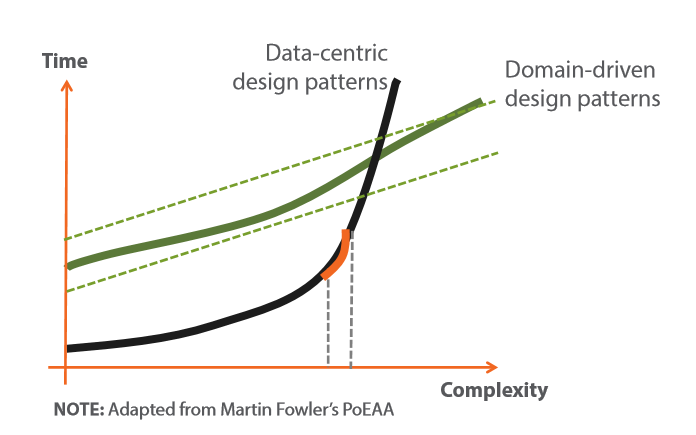
寒假快结束的时候,对软件架构设计感到了很多疑惑,微软的各种例子中虽然给出了样例代码,但是却没有一个总的指导纲领,只知道这些例子都是贯彻落实“领域驱动设计”这么一个概念的。那到底什么是领域驱动设计?如何实践领域驱动设计?领域驱动设计好处都有啥?带着这样的问题,我剁手买了一本书:《领域驱动设计:软件核心复杂性应对之道》并开始了阅读。
模型驱动设计
在平常,我们使用的最多的开发思路就是 CRUD,各种信息管理系统都可以看作是对数据库增删查改的封装,在应对小的项目的时候,CRUD 可真是神器,不管三七二十一,一把梭,第一期就完成了。但是随着客户需求的变更与增多,问题随之而来。为什么会导致这样的问题?作者给出的解释是,开发人员对业务没有深入的理解。就像是原来做一些很难的数学题一样,看到书后的参考答案(用户的最终目标),然后就开始尝试各种拼凑得出答案,虽然最后终于把答案拼装出来了,但是因为完全不懂原理,一旦题目做了一些变动,就会变得束手无策。作者在书中也举了很多类似的例子,例如开发团队一开始不太理解电子电路设计相关的知识,导致做出来的东西让对方感觉很奇怪,而且没法适应业务的变化。
应对这个问题的解决方案就是对业务领域进行建模。在书中,作者反复提到了模型驱动设计(Model Driven Design)这个名词,这里的模型,指的就是领域模型。构建领域模型需要一位对业务领域相当熟悉的专家跟开发团队共同努力。专家将自己的业务领域相关的知识拿出来与开发团队一起共享,这样开发团队才能正确认识到正在开发的东西要如何实现业务规则。
那么如何描述这么一个领域模型呢?作者的建议是使用“统一的语言”,这里的统一的语言主要是指开发团队要跟领域专家使用相同的术语指代同一个东西,这主要是为了避免交流过程中产生的理解上的障碍。就比如,大家在一起讨论地瓜这个东西怎么烹饪才好吃,结果每个人的说法都让对方感到非常奇怪,因为有的人认为地瓜指的是“沙葛”,有的人以为地瓜是说的“红薯”。
将统一的语言跟模型绑定起来,在谈论领域模型的时候,都必须使用“统一的语言”进行描述,除此之外,在团队内部的交流中,更是应该始终坚持使用统一的语言进行交流,如果发现现有统一的语言用来讨论业务需求有些困难,就应该考虑是不是建模上面出现了偏差。作者强调:
要认识到, UBIQUITOUS LANGUAGE 的更改就是对模型的更改。
领域专家应该抵制不合适或无法充分表达领域理解的术语或结构,开发人员应该密切关注那些将会妨碍设计的有歧义和不一致的地方。
领域模型还应该被文档化,作为口头交流和代码的补充。代码能够在很大程度上展现出模型的细节设计,但参与项目的人员还需要看到这个模型的全貌。开发团队内的交流可以帮助其他人理解模型的整体设计,在编码过程中起到指导作用,但是需要了解领域模型并不只是开发团队,所以,文档化的模型也是必要的。作者还建议,文档应该尽可能的少,主要用作口头交流跟代码的补充说明,同时还应该时时保持更新。当然了,最重要的是,文档同样应该使用前面提到的统一的语言。
基于模型驱动设计的架构
领域模型最终还是要通过代码来进行实现,如果之前构建的模型跟代码脱节了,那这个模型驱动设计就变得名存实亡了。基于关注分离的这个原则,我们应该将代码中涉及到领域建模的部分分离出来。例如,一个医疗报销信息管理系统中,业务领域主要包括报销审批的流程控制、各部门预算管理,而像导出 Excel 报表之类的东西,并不是业务领域关注的重点,所以报销审批跟预算管理部分的代码应该与报表导出之类的代码分离。
实现分离领域模型的技术我们非常的熟悉,就是分层架构。作者建议,应该将项目代码按照“用户界面层”、“应用层”、“领域层(模型层)”、基础设施层进行划分。
| 层次 | 作用 |
|---|---|
| 用户界面层 | 与客户端发生交互的地方,客户端可以是使用系统的人,还可以是其他调用本软件接口的系统 |
| 应用层 | 软件需要完成的与业务领域无关的工作在这里进行,例如信息管理系统打印报表的功能就属于应用层 |
| 领域层 | 整个业务软件的核心,负责表达业务相关的概念与规则 |
| 基础设施层 | 可以看作是整个系统的后勤部门,例如:为应用层提供打印能力,为领域层提供数据持久化的能力 |
各个层次内保持高内聚,各个层次间保持低耦合,而且耦合方向必须是高层依赖低层,例如上层调用下层的公共函数接口。只有做到这样,才能够帮助我们更好的集中注意力开发当前的层次,尤其是专注于领域层的设计,这将是领域驱动设计的精髓所在。
当然,软件架构的技术不止分层一种,这里作者提到的只是最普遍的做法,只要能够达到将领域层分离的目的,使用其他的方式也是可以的。
软件模型
当我们完成了领域建模部分的分离后,我们就应该全身心的专注于使用代码进行领域建模了。这里需要我们自己设计的模型主要分为下面几类:实体(Entity)、值对象(Value Object)、服务(Service)、模块(Module)。
实体与值对象
模型驱动设计把业务对象分为两类:实体与值对象,区分一个对象在业务领域中到底属于实体还是值对象的方法非常简单——能否仅通过标识区别。这里标志类似于业务模型中的主键,可以是对象的某个属性,还可以是几个属性的组合,有时候,还可能是通过序列生成器生成的唯一 ID,一个对象是否拥有这样的标志,主要取决于我们的业务需要。
举个例子,早餐店卖袋装豆浆,店铺不关心袋装豆浆的编号,只要有存货,就可以接着卖下去;而店内的座位则不同,因为店员需要知道订单要送到哪个座位上,这时候,我们的系统就不得不关注座位的编号。所以,在上面的系统中,座位应该被设计成实体,编号不同的座位应该加以区别。但是情况并不往往都是这样,假如上面的店铺店员不够用,店长决定改成让客人自己去餐台领餐的模式,这时候座位在我们的系统也就不需要跟订单关联,那么座位号也就会变得无关紧要,这时候再把座位设计为实体就会显得多余。
那什么样的东西应该设计为值对象呢?考虑一个在学生信息管理系统中的名字类型:
public class Name
{
string FirstName;
string LastName;
}
根据我们的常识,姓氏与名字一样的姓名应该是等价的,不管这个姓名对象我们手动 new 出来的,还是从数据库中读取并反序列化出来的,只要跟另一个姓名对象中的对应字段的值相等,那么这两个对象就是可以相互替换的。像这种情况,姓名对象在我们的领域模型中就应该是一个值对象。同时,值对象应该是不可变的,不包含标识,而且应该足够简单。再让我们回顾一下上面用 C# 代码定义的姓名类,可以发现他距离我们对值对象的定义还有些差距——没有重现比较规则、字段可变。与其去再去定义一堆重写的方法跟属性的访问控制器,不如尝试一下 .Net 家族中 F#,或者 JVM 系的 Kotlin。
// 使用 F# 定义姓名类
type Name = { FirstName: string; LastName: string}
let nameA = { FirstName="a"; LastName="b"}
let nameB = { FirstName="a"; LastName="b"}
printf "%A" (nameA = nameB)
// --> true
服务
在领域建模的过程中,往往需要封装一些操作和过程,这是时候就需要使用服务来表示这些操作。举个例子,在医疗报销信息管理系统中,员工登记好的报销单需要提交给相应的主管人员审批才能生效。假设我们把提交这个操作作为员工实体的职责之一,但是这样做的话,员工对象可能还需要了解需要提交到哪位主任那里,如果我们的系统需要定义多种审核规则的话,那员工实体需要了解的东西就会变得很多。显然,将提交审核的操作封装为一个服务将会是一个更好的做法,员工实体只需要关注本年度自己的余额会被扣除就好了,而具体由哪位主任去审核,均由我们的报销单提交服务负责处理。除了用来封装业务领域的操作,服务还可以用来封装领域层提供给上层(应用层)的接口,作为领域层的边界。
但并不是所有的我们分析出来的服务都属于领域层。还是上面的例子,当审核提交成功的时候,需要给员工发个通知,我们可以在界面上弹个消息通知一下,或者使用短信通知一下,像这样的通知服务,就不属于业务领域的一部分。
服务往往是使用一个动词来命名,而且,这个动词应该出现在“统一的语言
中,服务的调用参数与返回结果也应该是领域对象。服务并不是把属于实体或值对象的职责据为己有的一个对象,而是对业务领域中一个有着重要作用的操作或者过程封装。同时,服务应该做到无状态,任何时候调用服务的任一个实例而不必关注服务实例的历史状态。
模块
原文使用了 Module 这个词语,根据我的理解,这里 Module 对应到 C# 中指的是 NameSpace,在 Java 中指 package,在 Angular 中指 NgModule。模块不仅仅只是对代码的划分,同时还是对领域概念的划分。在对代码进行组织的时候,需要考虑到代码在领域层面的关联性。
聚合
上面提到了,使用模块可以将不同的领域概念划分,这仍然只是一个粗粒度的划分,在模块的内部我们还需要面对实体对象间错综复杂的联系(单向关联、双向关联)。具体的复杂性体现在,对一个对象的一些属性的修改,可能会导致新的对象的生成或者旧的对象的销毁,有时还可能伴随着对一些其他对象的修改。像这种牵一发而动全身的事情是我们在开发过程中最不希望看见的,那么应该如何知道,对一个对象修改的影响范围是从何处开始,又到哪里终止呢?聚合模式给出了一个解决方案。
在聚合模式中,我们把几个关联度较高的对象划分成一个聚合,每个聚合中有一个小组长,我们把小组长叫做聚合根(Root),聚合的内部对象间可以相互引用,但要是想从聚合外引用里面的对象,这是不被允许的,从外部只能引用聚合根。如果要从外界访问聚合内部的实体,只能从聚合根那里获得一个不可变的引用,如果要访问聚合内部的值对象,也只能从聚合根那里获得值对象的一个拷贝。聚合内部的对象也只能由聚合根创建,一旦聚合根销毁,聚合内的全部实体跟值对象也都会一起被销毁。这也就是说,从聚合的外部不能随意的创建、删除或者修改属于某个聚合内部的对象,聚合变成了我们修改数据的最小单元。
规则确实比较多,但是正是这些规则帮助我们简化了对对象生命周期的管理。在没有垃圾回收器的 Rust 语言中,也使用了类似的概念实现了对对象生命周期管理的能力。不过聚合除了管理对象生命周期之外还有贯彻落实业务规则的能力。比如在我们上面的学生信息管理系统中,姓名很可能是属于学生作为聚合根的聚合中的一个实体,所以姓名对象的创建、修改操作由学生来控制,这样的话,我们就可以把“姓名必须使用汉字”、“姓名长度不能超过 30 个汉字”这样的业务规则交由学生来处理。
工厂(Factory)
正如上面所提到的,聚合根管理着整个聚合内对象的创建工作。这部分工作我们完全可以放在聚合根类型的构造函数中进行,然而一旦聚合内部的对象比较多,并且初始化过程比较复杂的话,这无疑会给构造函数带来很大压力——承担着一个初始化复杂对象集合的责任。而且这仅仅只是创建,别忘了聚合根还负责校验用来创建聚合内对象的数据是否符合业务规则的这一重任。如此想来,将创建聚合的工作交给其他的对象来做可能更好一些。注意到创建复杂对象并不是领域层中定义的业务的一部分,但这项工作确实又应该划入领域层,所以我们需要向领域层引入一个新的概念——工厂。工厂用来创建领域中复杂的对象。
工厂的实现有很多种,在设计模式相关的书籍中提到了很多设计工厂的方法,如何设计工厂并不是模型驱动设计的关注点,我们更关注工厂能不能封装构建复杂对象的创建过程并且能够根据聚合的业务规则正确的创建一个聚合中的全部对象并返回聚合根。当然,我们设计的工厂应该尽可能的避免太复杂的依赖关系,否则这就打破了我们使用聚合的意义。举个例子,在我们的学生信息管理系统系统中,学生成绩单实体的创建需要依赖学生实体的相关信息,比如学生的联系方式跟姓名等信息。这时候我们就可以把学生成绩单工厂作为学生实体的一个方法,这样可以避免把学生实体中的一些信息提取到其他的地方。但是如果,学生成绩单的创建依赖一个序列生成服务,那么把这个工厂单独作为一个对象会更合适一些。
除了创建全新的对象外,更加常见的场景是我们需要从数据库的数据中重建对象,尤其是重建实体,存入数据库前的实体跟从数据库中重建的实体如果标识相同的话,应该是同一个对象。为了应对这个场景,我们引入了一个新的领域设计模型——仓储(Repository)。
仓储(Repository)
数据持久化在大部分的项目中可以说是一个非常常见的操作了,但是这一操作往往涉及到对数据库相关软件包的依赖,这将极大的破坏领域模型的纯洁性。另一方面,如果允许开发人员随便的通过数据库驱动包直接从数据库中获取对象而无视聚合的规则,混乱的问题又将卷土重来。为此,我们将向领域层中引入新的模型——仓储。仓储的工作主要就是这些:
- 数据持久化
- 支持按照聚合的规则查询领域对象
- 支持返回非领域对象的查询(比如数据库中的汇总查询)
在我看来,仓储的实现大多数情况下并不需要自己动手,在 Java 中,我们有 Hibernate,在 .Net 中,有 EF 跟 NHibernate。关于是否需要基于 EF 之上实现仓储模式的讨论已经有很多了,在这里我也不好给出一个肯定的结论。虽然 EF 并没有像 JPA 那样提供可选实现的接口,但是 EF Provider 本身就可以看作是一种提供给外部可供自由实现的接口,不过并不是所有的开发人员都能很轻松的实现这样的接口就是了。所以我个人认为基于 EF 之上重新实现一个仓储可能会更好一些。
设计关联
写到这里,基本就把领域驱动设计中设计的几种模型都列举了出来,但是在我们的领域层中,领域对象之间的关联的设计也是非常重要的。用 UML 描述的话,就是类与类之间的关联关系。通常,双向关联往往在代码中意味着循环引用,而循环引用确实又不好处理。在书中,作者提出了一种使用查询来代替双向关联的做法,比如在我们的学生信息管理系统中,班级实体中有个学生实体列表,学生实体有个班级属性。如果在处理班级跟学生之间的双向关联感到了棘手的话,不妨把这个列表属性变成学生仓储的一个查询方法。这样,在我们的模型中,他们仍然可以保持双向关联的业务逻辑,但是在代码中,这种双向关联就变成了单向的。
总结
领域驱动设计本质上就是模型驱动设计,我们使用实体、值对象、模块、聚合、服务、工厂、仓储这些元素设计我们的领域模型,在这个过程中,我们必须从始至终的使用“统一的语言”。在设计过程中,我们需要始终关注业务本身去设计模型,不断的去学习理解业务规则并保持领域层的纯洁性有助于我们构建出正确的符合业务原理的领域模型。
另一方面,通过对这本书的阅读,我也终于能够理解工厂、服务、仓储这些概念出现的原因了,而不是上课老师给的代码里面的带着各种后缀的类名。