一、写在前面
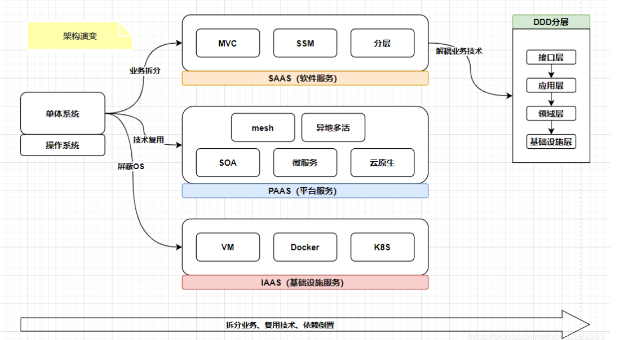
今天的软件相对之前的软件,需求越来越复杂,变化越来越快。软件架构不断的在演进,一方面是为了适应新的需求,一方面也在寻找软件简单化解决方案,通过架构的规范是的软件更容易维护,逻辑更清晰。所以架构一直在追求易维护、可扩展。从早期的modle1、modle2,到现在这种微服务架构,一直在追求一个能让软件开发变得简单的软件架构,但往往事与愿违。往往软件在开发初期,架构合理、分层清晰,但进过多年维护后,系统变得一团乱码。
究其原因,主要是大家面向业务开发,直达业务实现,往往是脚本式,面向过程的开发,而不是从软件架构的角度去编写程序。其很大原因是大多数公司业务至上原则,业务为王,而要架构更好的软件,势必会花费更多的时间打磨,很多老板不愿承担这成本。
设计的很好的架构,为什么到最后就维护的一团乱码?真的是开发人员技能的问题吗? 当然,从直接的原因看是因为开发人员的问题,但深究背后的原因,我们不难发现这是业务与技术之间的悖论。业务需求是在寻找业务之间的关联关系,业务是耦合的;而技术一直在寻找解耦,追求高内聚低耦合的架构(无论是现在的微服务、还是之前的分层架构、还是组件化模块化,无不在践行这个理念)。这两个追去看起来是天然不可调和的。 如果开发人员只关注了业务的逻辑,按照业务思维去开发系统,久了之后,自然而然就会让系统走向了耦合。
那有没有一种可能,调和业务和架构之间的矛盾呢?答案是:有,DDD(Domain Driven Design,领域驱动设计。)
二、什么是DDD?
什么是DDD(Domain Driven Design),看过很多书上定义,晦涩难懂,我们看一下他原始的定义:
- •It isa way of thinking and a set of priorities, aimed at accelerating softwareprojects that have to deal with Complicated Domains.
- •A ModelDriven softwaredesign approach used to tackle the complexity of software projects.
- •Collection of principles and patterns that help developers craft ElegantSystems.
看不懂,我也看不懂。
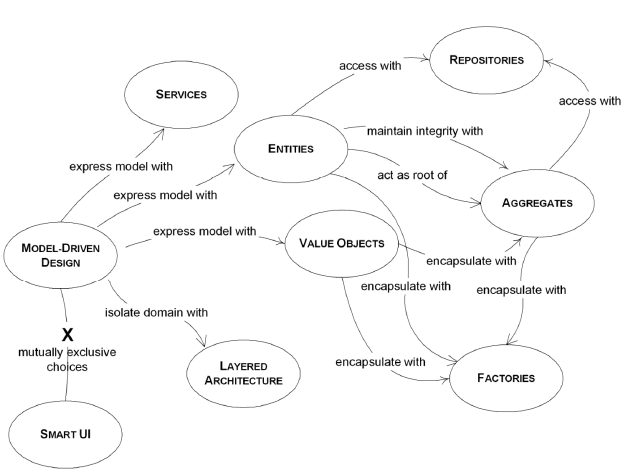
大致的意思是:是一种解决复杂软件的思维方式,是一种思想;以业务为主导,自顶向下的进行业务领域划分,业务模型驱动架构设计。
DDD的核心概念
Domain: A sphere of knowledge or activity.What an organization does and the world it does it in.
Model: A system of abstractions thatdescribes selected aspects of a domain and ignores extraneous detail. Explainsa complex domain in a simple way. A model is a distilled form of domainknowledge, assumptions, rules and choices.
他的核心概念是Domain(领域)和 Model(模型)
一句话DDD是已经解决复杂软件的思想,核心思想是面向对象(OO),其核心概念是Domain(领域)和 Model(模型)。
三、为什么要用DDD?
- 面向对象设计,数据行为绑定,告别贫血模型;
- 降低复杂度,分而治之;
- 优先考虑领域模型,而不是切割数据和行为;
- 准确传达业务规则,业务优先;
- 代码即设计;
- 它通过边界划分将复杂业务领域简单化,帮我们设计出清晰的领域和应用边界,可以很容易地实现业务和技术统一的架构演进;
- 领域知识共享,提升协助效率;
- 增加可维护性和可读性,延长软件生命周期;
- 中台化的基石。
四、DDD的主要模式
五、DDD 常见的落地架构
5.1 分层架构
分层的作用,从上往下:
- 用户交互层:负责向用户展现信息以及解释用户命令。RESTFul、rpc 请求或mq 消息等对外提供数据服务或指令服务。
- 业务应用层:很薄的一层,用来协调应用的活动和向领域层下达指令,它不包含业务逻辑,也不不保留业务对象的状态,但它保有应用任务的进度状态。 但在应用服务的实现中,它负责编排、转发、校验等。
- 领域层:核心层又称为模型层,本层包含关于领域的信息,负责表达业务概念。在这里保留业务对象的状态以及业务规则,即包含了该领域所有复杂的业务知识抽象和规则定义,对业务对象和它们状态的持久化被委托给了基础设施层。该层主要精力要放在领域对象分析上,可以从实体,值对象,聚合(聚合根),领域服务,领域事件,仓储,工厂等方面入手。
- 基础设施层:本层作为其他层的支撑库存在。它提供了层间的通信,实现对业务对象的持久化,包含对用户界面层的支撑库等作用。主要有 2 方面内容,一是为领域模型提供持久化机制,当软件需要持久化能力时候才需要进行规划;一是对其他层提供通用的技术支持能力,如消息通信,通用工具,配置等的实现。
5.2 六边形架构
主动适配:指来⾃于UI、命令⾏等输⼊型命令, controller就是⼀种端⼝,端⼝的具体实现就是应⽤逻辑⾃身。因此端⼝和具体实现都在应⽤系统的内部。
被动适配:指访问存储设备,外部服务等。每种访问就是⼀种端⼝,具体实现是各个具体的中间件。因此端⼝在整个应⽤系统的⾥部,具体实现在系统的外部。
每⼀种输⼊和输出都是⼀个端⼝,每个端⼝都有具体的实现逻辑,因此整个应⽤系统的架构就是⼀些列的端⼝+适配逻辑组成,架构图就是⼀个多边形形状。有⼏个端⼝需要根据应⽤系统的具体情况⽽定,只是六个端⼝⽐较形象⽽得名为六边形架构。
特点:
- 外层依赖内层使得依赖更合理。端⼝就是接⼝,依赖接⼝编程。借此保证了应⽤和实现细节之间的隔离。
- 可测试更好
5.3 洋葱架构
洋葱架构针对六边形架构更进⼀步把内层的业务逻辑分为了DDD概念的应⽤服务层、领域服务层和领域模型层。
特点:
(1)围绕独⽴的领域模型构建应⽤
(2)内层定义接⼝,外层实现接⼝
(3)依赖的⽅向指向圆⼼(注意:洋葱架构提倡不破坏耦合⽅向的依赖都是合理的,外层可以依赖直接内层,也可以依赖更⾥⾯的层)
(4)所有的应⽤代码可以独⽴于基础设施编译和运⾏
六、DDD基本概念
实体
书中定义:
实体(Entity), 主要由标识定义的对象。它可以是任何事物,只要满足两个条件即可,一是它在整个生命周期中具有连续性;二是它的区别并不是由那些对用户非常重要的属性决定的。
比较晦涩难懂
在DDD的领域模型中,实体具有业务行为且有唯一标识符的对象。在不同的设计阶段实体是可以改变的,但是根据唯一标识符始终能定位到这个唯一对象。
唯一标识符可以是用户指定的,也可以是通过应用程序生成的,如:UUID或者通过持久化机制生成的主键ID序列值(Sequence),当然也可以是限界上下文中传递的过来的,但无论是哪一种生产方式都要具备全局唯一性(比如客户的ID,一个客户的ID在全公司是唯一的)。
实体的可变性主要体现在不同的设计阶段,实体会根据所处阶段的侧重点不同,发生一定地形态变化。
- 实体的业务形态
在战略规划时,实体是领域模型的一个重要对象。领域模型中的实体是多个属性、操作或行为的载体。在事件风暴中,我们可以根据命令、操作或者事件,找出产生这些行为的业务实体对象,进而按照一定的业务规则将依存度高和业务关联紧密的多个实体对象和值对象进行聚类,形成聚合。你可以这么理解,实体和值对象是组成领域模型的基础单元。
- 实体的代码形态
在 DDD 里,这些实体类通常采用充血模型,与这个实体相关的所有业务逻辑都在实体类的方法中实现,跨多个实体的领域逻辑则在领域服务中实现。
- 实体的运行形态
实体以 DO(领域对象)的形式存在,每个实体对象都有唯一的 ID。我们可以对一个实体对象进行多次修改,修改后的数据和原来的数据可能会大不相同。但是,由于它们拥有相同的 ID,它们依然是同一个实体。比如客户是客户上下文的一个实体,通过唯一的客户ID 来标识,不管这个客户的数据如何变化,客户的 ID 一直保持不变,他始终是同一个客户。
- 实体的数据库形态
在领域模型映射到数据模型时,一个实体可能对应 0 个、1 个或者多个数据库持久化对象。大多数情况下实体与持久化对象是一对一。在某些场景中,有些实体只是暂驻静态内存的一个运行态实体,它不需要持久化。比如,基于通过多个属性计算处理来的报价兑现。 而在有些复杂场景下,实体与持久化对象则可能是一对多或者多对一的关系。比如,用户
user与角色role两个持久化对象可生成权限实体,一个实体对应两个持久化对象,这是一对多的场景。再比如,有些场景为了避免数据库的联表查询,提升系统性能,会将客户信息 customer 和账户信息 account 两类数据保存到同一张数据库表中,客户和账户两个实体可根据需要从一个持久化对象中生成,这就是多对一的场景。
值对象
值对象(Value Object),用于描述领域的某个方面而本身没有概念的对象称为值对象,值对象被实例化之后用来表示一些设计元素,对于这些设计元素,我们只关心它们是什么,不关心它是谁。
在 DDD 中用来描述领域的特定方面,并且是一个没有标识符的对象,叫作值对象。也可理解为是若干个用于描述目的、具有整体概念和不可修改的属性的集合。在领域建模的过程中,值对象可以保证属性归类的清晰和概念的完整性,避免属性零碎。 值对象可以非常容易地创建、测试、使用、优化和维护,因此我们应该尽量使用值对象来建模而不是实体对象。在定义值对象时我们需要考虑其是否具备以下特性:
- 它度量或者描述了领域中的一件东西
- 它可以作为不变量
- 它将不同的相关的属性组合成一个概念整体(Conceptual Whole)
- 它度量和描述改变时,可以用另外一个值对象予以替换
- 它可以和其他值对象进行相等性比较(因为没有唯一标识符)
- 它不会对协作对象造成副作用
一个人拥有名字和年龄属性,这里的名字和年龄不是一个具体能够映射成对象的东西,年龄是一个度量概念,名字是一个描述概念,把这些概念整合成一个概念整体就是值对象的具体表现形式。
除了没有唯一标识符外,值对象和实体对象另外一个比较大的区别就是,值对象具有不变性。体现到我们代码层面就是,在值对象初始化之后,任何方法都不能对该对象的属性状态进行修改。
- 值对象的业务形态
值对象是 DDD 领域模型中的一个基础对象,它跟实体一样都来源于事件风暴所构建的领域模型,都包含了若干个属性,它与实体一起构成聚合。值对象的属性集虽然在物理上独立出来了,但在逻辑上它仍然是实体属性的一部分,用于描述实体的特征。在值对象中也有部分共享的标准类型的值对象,它们有自己的限界上下文,有自己的持久化对象,可以建立共享的数据类微服务,比如数据字典。
- 值对象的代码形态
值对象在代码中有这样两种形态。如果值对象是单一属性,则直接定义为实体类的属性;如果值对象是属性集合,则把它设计为 Class 类,Class 将具有整体概念的多个属性归集到属性集合,这样的值对象没有 ID,会被实体整体引用。
我们看一下下面这段代码,Person 这个实体有若干个单一属性的值对象,比如 id、name、sex 等属性;同时它也包含多个属性的值对象,比如地址 address。
public class Person {
/**
* 值对象,人员唯一标识ID
*/
public String id;
/**
* 单一属性值对象,名字
*/
public String name;
/**
* 单一属性值对象,性别
*/
public String sex;
/**
* 单一属性值对象,年龄
*/
public int age;
/**
* 属性集值对象,被实体引用
*/
public Address address;
//TODO:方法(操作或行为)
/**
* 值对象,无唯一标识ID
*/
public class Address {
/**
* 值对象,省
*/
public String province;
/**
* 值对象,市
*/
public String city;
/**
* 值对象,县
*/
public String county;
/**
* 值对象,街道
*/
public String street;
//TODO:方法(操作或行为)
}
}
- 值对象的运行形态
值对象实例化的对象则相对简单和乏味。除了值对象数据初始化和整体替换的行为外,其它业务行为就很少了。值对象嵌入到实体的话,有这样两种不同的数据格式,也可以说是两种方式,分别是属性嵌入的方式和序列化大对象的方式。
引用单一属性的值对象或只有一条记录的多属性值对象的实体,可以采用属性嵌入的方式嵌入。引用一条或多条记录的多属性值对象的实体,可以采用序列化大对象的方式嵌入。比如,人员实体可以有多个通讯地址,多个地址序列化后可以嵌入人员的地址属性。值对象创建后就不允许修改了,只能用另外一个值对象来整体替换。
以属性嵌入的方式形成的人员实体对象,地址值对象直接以属性值嵌入人员实体中。
| id | name | age | sex | province | city | county | street |
|---|---|---|---|---|---|---|---|
| 1 | holmium | 30 | 1 | 陕西 | 西安 | 长安 | 秦岭 |
以序列化大对象的方式形成的人员实体对象,地址值对象被序列化成大对象 Json 串后,嵌入人员实体中。
| id | name | age | sex | address |
|---|---|---|---|---|
| 1 | holmium | 30 | 1 | {"address": {"province": "陕西","city": "西安","county": "长安","street": "秦岭"}} |
很多关系型数据库都支持了json格式存储和解析,配合json格式实现列存储可以很好的兼容这种嵌入实体模式。
- 值对象的数据库形态 DDD 引入值对象是希望实现从“数据建模为中心”向“领域建模为中心”转变,减少数据库表的数量和表与表之间复杂的依赖关系,尽可能地简化数据库设计,提升数据库性能。值对象在数据库持久化方面简化了设计,它的数据库设计大多采用非数据库范式,值对象的属性值和实体对象的属性值保存在同一个数据库实体表中。具体体现在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计。
把地址信息以一个序列化大对象的方式嵌入用户表时就是一种很好的应用案例场景。即减少了单独设计一张地址表,也体现出了地址信息不具备任何业务行为的特性。
- 如何创建一个值对象 值对象是一把双刃剑,它的优势是可以简化数据库设计,提升数据库性能。但如果值对象使用不当,它的优势就会很快变成劣势。
序列化大对象嵌入实体: 值对象采用序列化大对象的方法简化了数据库设计,减少了实体表的数量,可以简单、清晰地表达业务概念。这种设计方式虽然降低了数据库设计的复杂度,但却无法满足基于值对象的快速查询,会导致搜索值对象属性值变得异常困难。
属性嵌入实体: 值对象采用属性嵌入的方法提升了数据库的性能,但如果实体引用的值对象过多,则会导致实体堆积一堆缺乏概念完整性的属性,这样值对象就会失去业务涵义,操作起来也不方便。
实体和值对象之间的关系
唯一的身份标识和可变性特征将实体对象和值对象进行了区分。本质上,实体是看得到、摸得着的实实在在的业务对象,实体具有业务属性、业务行为和业务逻辑。而值对象只是若干个属性的集合,只有数据初始化操作和有限的不涉及修改数据的行为,基本不包含业务逻辑。
实体和值对象是微服务底层的最基础的对象,一起实现实体最基本的核心领域逻辑。同时实体对象和值对象共同构成了聚合。
在设计的时候应该用实体对象还是值对象,我觉得本着一个是否具有业务行为的原则就够了,有业务行为的就用实体对象,没有业务行为的就设计成值对象。
实体VS值对象
- 等值判断标准不同。
每个实体都有自己的唯一标识,判断两个实体是否一样的标准是判断这两个实体的标识是否一样。值对象没有自己的唯一标识,判断两个值对象相等的标准是判断他们的每个属性是否有相同的值。是否拥有唯一的身份标识是实体和值对象的本质区别。
- 生命周期不同。
实体处于连续变化中,它有一个状态变更的历史。值对象没有,从被创建出来到被丢弃掉这个过程。也就是值对象不能单独的存在,或者说它单独存在是没有意义的。它必须归属于一个或多个实体。
- 不可变性不同。
实体状态是可以变化的。但是值对象的状态是不可变的。当一个实体的值对象需要变化的时候,需要用另一个值对象替换掉当前的值对象。
- 实体需要单独的表来存储,值对象不需要单独的表。
服务
当我们分析领域并试图定义构成模型的主要对象时,我们发现有些方面的领域很难映射成对象。对象要通常考虑的是拥有属性,对象会管理它的内部状态并暴露行为。在我们开发通用语言时,领域中的主要概念被引入到语言中,语言中的名词很容易被映射成对象。语言中对应那些名词的动词变成那些对象的行为。但是有些领域中的动作,它们是一些动词,看上去却不属于任何对象。它们代表了领域中的一个重要的行为,所以不能忽略它们或者简单的把它们合并到某个实体或者值对象中。给一个对象增加这样的行为会破坏这个对象,让它看上去拥有了本该属于它的功能。但是,要使用一种面向对象语言,我们必须用到一个对象才行。我们不能只拥有一个单独的功能,它必须附属于某个对象。通常这种行为类的功能会跨越若干个对象,或许是不同的类。例如,为了从一个账户向另一个 账户转钱,这个功能应该放到转出的账户还是在接收的账户中?感觉放在这两个中的哪一个也不对劲。当这样的行为从领域中被识别出来时,最佳实践是将它声明成一个服务。这样的对象不再拥有内置的状态了,它的作用是为了简化所提供的领域功能。服务所能提供的协调作用是非常重要的,一个服务可以将服务于实体和值对象的相关功能进行分组。最好显式声明服务,因为它创建了领域中的一个清晰的特性,它封装了一个概念。把这样的功能放入实体或者值对象都会导致混乱,因为那些对象的立场将变得不清楚。服务担当了一个提供操作的接口。服务在技术框架中是通用的,但它们也能被运用到领域层中。一个服务不是在执行服务的对象,而与被执行操作的对象相关。在这种情况下,一个服务通常变成了多个对象的一个链接点。这也是为什么行为很自然地依附于一个服务而不是被包含到其他领域对象的一个原因。如果这样的功能被包含进领域对象,就会在领域对象和成为操作受益者的对象之间建立起一个密集的关联网。众多对象间的高耦合度是糟糕设计的一个信号,因为这会让代码很难阅读与理解,更重要的是,这会导致很难进行变更。 一个服务应该不是对通常属于领域对象的操作的替代。我们不应该为每一个需要的操作来建立一个服务。但是当一个操作凸现为一个领域中的重要概念时,就需要为它建立一个服务了。以下是服务的 3个特征:
- 服务执行的操作涉及一个领域概念,这个领域概念通常不属于一 个实体或者值对象。
- 被执行的操作涉及到领域中的其他的对象。
- 操作是无状态的。
模块
对一个大型的复杂项目而言,模型趋向于越来越大。模型到达了一个作为整体很难讨论的点,理解不同部件之间的关系和交互变得很 困难。基于此原因,很有必要将模型组织进模块。模块被用来作为组织相关概念和任务以便降低复杂性的一种方法。模块在许多项目中被广泛使用。如果你查看模快包含的内容以及那些模块间的关系,就会很容易从中掌握大型模型的概况。理解了模型间的交互之后,人们就可以开始处理模块中的细节了。这是管理复杂性的简单有效的方法。
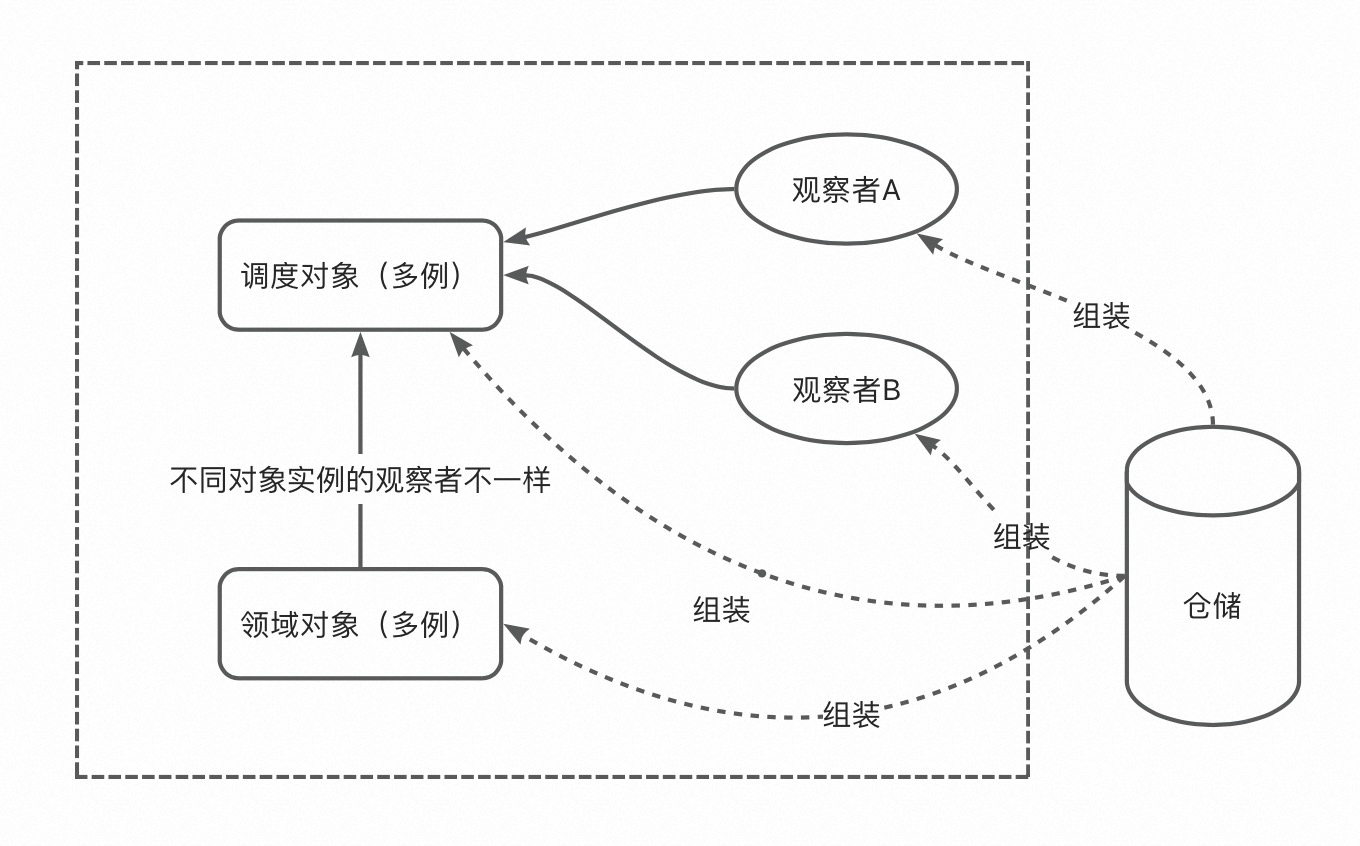
聚合
聚合是一个用来定义对象所有权和边界的领域模式。一个模型会包含众多的领域对象。不管在设计时做了多少考虑,我们都会看到许多对象会跟其他的对象发生关联,形成了一个复杂的关系网。这些关联的类型有很多种。对模型中的每个可导航的关联而言,都应该有对应的软件机制来强调它。领域对象间实际的关联在代码中结束,有时甚至却在数据库中。来自模型的挑战是通常不让它们尽量完整,而是让它们尽量地简单和容易理解。这意味着,直到模型中嵌入了对领域的深层理解,否则就要时常对模型中的关系进行消减和简化。
一个1 对多的关联关系就更复杂了,因为它涉及到了相关的多个对象。这种关系可以被简单转化成一个对象和一组其他对象之间的一 个关联,虽然这并不总能行得通。
因此,使用聚合。聚合是针对数据变化可以考虑成一个单元的一组相关的对象。聚合使用边界将内部和外部的对象划分开来。每个聚合有一个根。这个根是一个实体,并且它是外部可以访问的唯一的对象。根可以保持对任意聚合对象的引用,并且其他的对象可以持有任意其他的对象,但一个外部对象只能持有根对象的引用。如果边界内有其他的实体,那些实体的标识符是本地化的,只在聚合内有意义。
工厂
实体和聚合通常会很大很复杂,根实体的构造函数内的创建逻辑也会很复杂。实际上通过构造器努力构建一个复杂的聚合也与领域本身通常做的事情相冲突,在领域中,某些事物通常是由别的事物创建的。但是当对象构建是一个很费力的过程时,对象创建涉及了好多的知识,包括:关于对象内部结构的,关于所含对象之间的关系的以及应用其上的规则等。这意味着对象的每个客户程序将持有关于对象构建的专有知识。这破坏了领域对象和聚合的封装。如果客户程序属于应用层,领域层的一部分将被移到了外边,扰乱整个设计。
一个对象的创建可能是它自身的主要操作,但是复杂的组装操作不应该成为被创建对象的职责。组合这样的职责会产生笨拙的设计,也很难让人理解。
因此,有必要引入一个新的概念,这个概念可以帮助封装复杂的对象创建过程,它就是工厂(Factory)。工厂用来封装对象创建所必需的知识,它们对创建聚合特别有用。当聚合的根建立时,所有聚合包含的对象将随之建立,所有的不变量得到了强化。 将创建过程原子化非常重要。如果不这样做,创建过程就会存在对某个对象执行了一半操作的机会,将这些对象置于未定义的状态,对聚合而言更是如此。当根被创建时,所有对象服从的不变量也必 须被创建完毕,否则,不变量将不能得到保证。
工厂方法是一个对象的方法,包含并隐藏了必要的创建其他对象的知识。这在一个客户程序试图创建一个属于某聚合的对象时是很有 用的。解决方案是给聚合的根增加一个方法,这个方法非常关心对象的创建,强化所有的不变量,返回对那个对象的引用或者拷贝。
资源库
在一个面向对象 的语言中,我们必须保持对一个对象的引用以便能够使用它。为了 获得这样的引用,客户程序必须创建一个对象或者通过导航已有的 关联关系从另一个对象中获得它。例如,为了从一个聚合中获得一 个值对象,客户程序需要向聚合的根发送请求。问题是现在客户程 序必须先拥有一个对根的引用。对大型的应用而言,这会变成一个 问题因为我们必须保证客户始终对需要的对象保持一个引用,或者是对关注的对象保有引用。在设计中使用这样的规则将强制要求对象持有一系列它们可能其实并不需要保持的一系列的引用。这增加 了耦合性,创建了一系列本不需要的关联。
因此, 使用一个资源库,它的目的是封装所有获取对象引用所需的 逻辑。领域对象不需处理基础设施,以得到领域中对其他对象的所 需的引用。只需从资源库中获取它们,于是模型重获它应有的清晰 和焦点。
点关注,不迷路。
如果您喜欢这篇文章,请不要忘记点赞、关注、转发,谢谢!如果您有任何高见,欢迎在评论区留言讨论……