近日,谷歌在其 GitHub 页面发布博文介绍一款名为 VLOGGER AI 的新模型,用户只需要输入一张肖像照片和一段音频内容,该模型可以让这些人物&ldqu

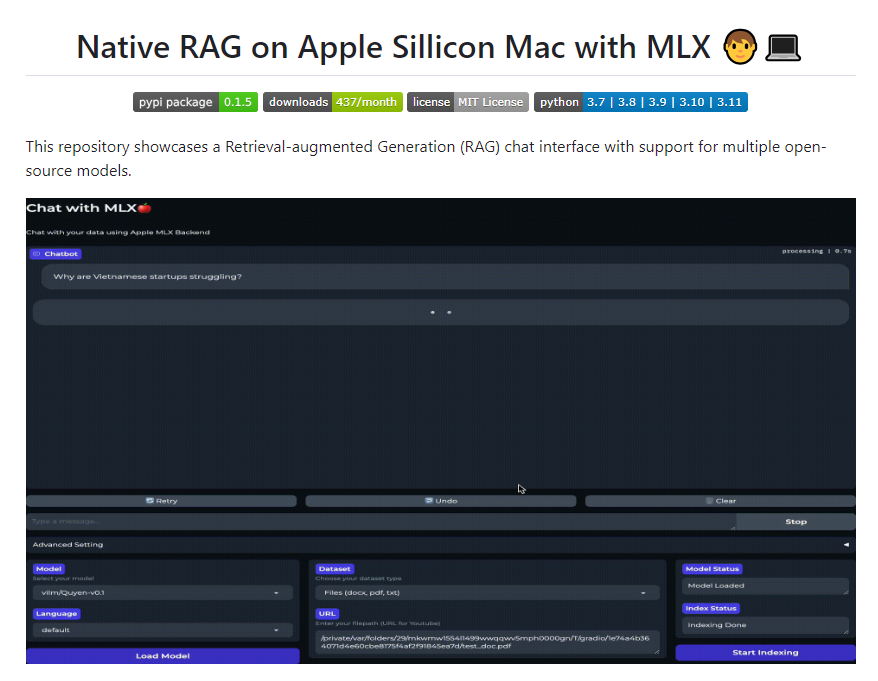
近日,谷歌在其 GitHub 页面发布博文介绍一款名为 VLOGGER AI 的新模型,用户只需要输入一张肖像照片和一段音频内容,该模型可以让这些人物“动起来”,富有面部表情地朗读音频内容。

VLOGGER AI 是一种适用于虚拟肖像的多模态 Diffusion 模型,使用 MENTOR 数据库进行训练,该数据库中包含超过 80 万名人物肖像,以及累计超过 2200 小时的影片,从而让 VLOGGER 生成不同种族、不同年龄、不同穿着、不同姿势的肖像影片。

研究人员表示:“和此前的多模态模型相比,VLOGGER AI 的优势在于不需要对每个人进行训练,不依赖于人脸检测和裁剪,可以生成完整的图像(而不仅仅是人脸或嘴唇),并且考虑了广泛的场景(例如可见躯干或不同的主体身份),这些对于正确合成交流的人类至关重要”。

除了将静态人物进行动态转化之外,还可以针对不同语言系统进行口型的转换,比如将一则英语播报的主播转换为西班牙语的口型。这将有助于视频主播将内容注入更多的语言场景。
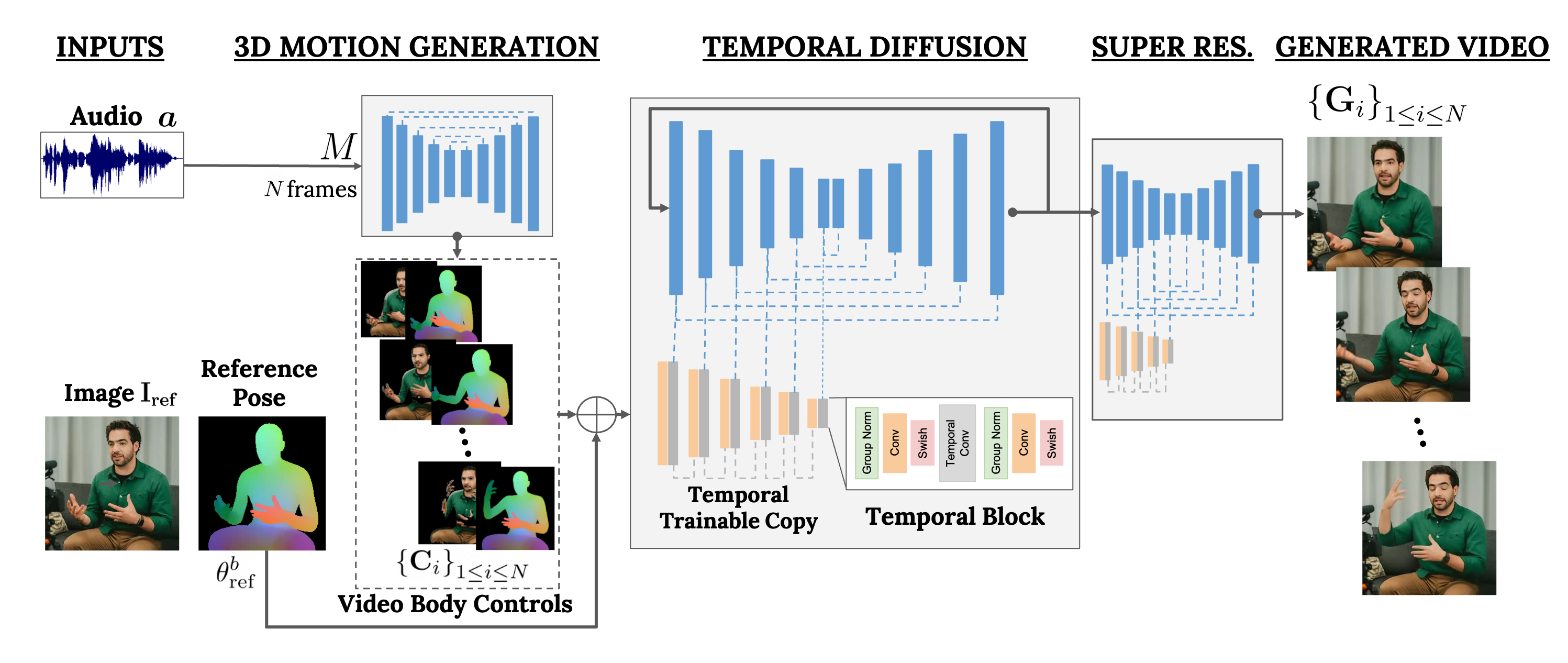
谷歌的研究团队认为,可以将 VLOGGER 应用于将 AI 聊天机器人具象可视化,比如让机器人拥有可视化的人物躯干,AI 就可以通过语音、手势和眼神交流以自然的方式与人类互动。 VLOGGER 的应用场景包括可以用于学术报告、教育场域和视频旁白等等 AI 数字人的应用领域。
围观项目主页:
https://enriccorona.github.io/vlogger/