一、http请求的顺序处理方式
在高并发场景下,为了降低系统压力,都会使用一种让请求排队处理的机制。本文就介绍在Go中是如何实现的。
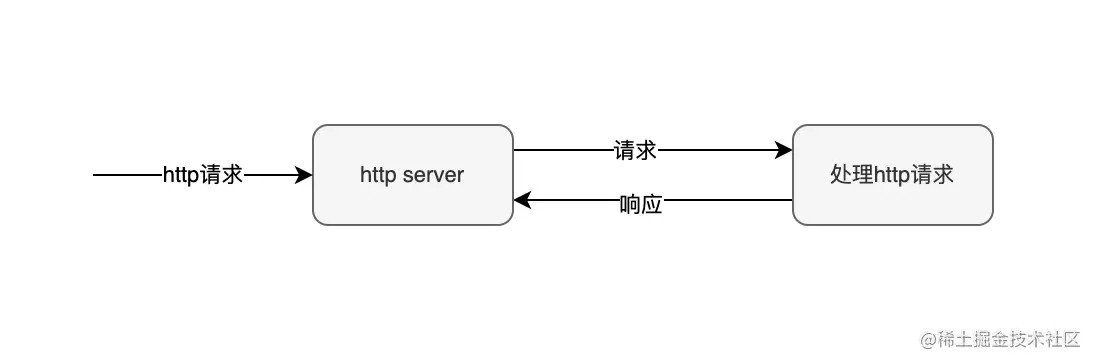
首先,我们看下正常的请求处理逻辑。 客户端发送请求,web server接收请求,然后就是处理请求,最后响应给客户端这样一个顺序的逻辑。如下图所示:
代码实现如下:
package main
import (
"fmt"
"net/http"
)
func main() {
myHandler := MyHandler{}
http.Handle("/", &myHandler)
http.ListenAndServe(":8080", nil)
}
type MyHandler struct {
}
func (h *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello Go"))
}
在浏览器中输入 http://localhost:8080/,就能在页面上显示出“Hello Go”的页面来。
通常情况下,大家在开发web系统的时候,一般都是这么处理请求。接下来我们看在高并发下如何实现让请求进行排队处理。
二、http请求的异步处理方式--排队处理
让http请求进入到队列,我们也称为异步处理方式。其基本思想就是将接收到的请求的上下文(即request和response)以及处理逻辑包装成一个工作单元,然后将其放到队列,然后该工作单元等待消费的工作线程处理该job,处理完成后再返回给客户端。 流程如下图:
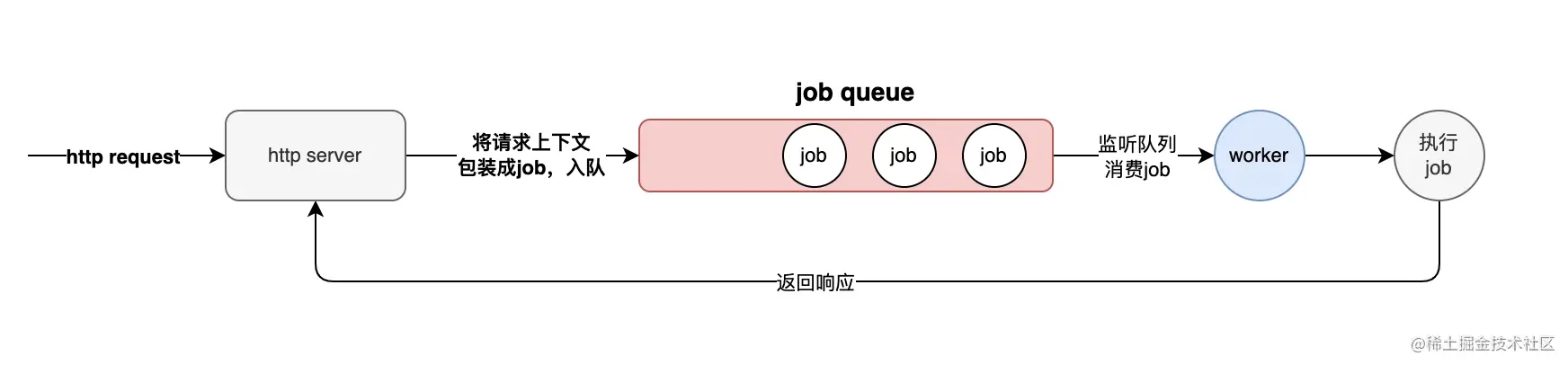
该实现中会有三个关键的元素:工作执行单元、队列、消费者。下面我们逐一看下各自的职责及实现。
工作单元
该工作单元主要是封装请求的上下文信息(request和response)、请求的处理逻辑以及该工作单元是否被执行完成的状态。
请求的处理逻辑实际上就是原来在顺序处理流程中的具体函数,如果是mvc模式的话就是controller里的一个具体的action。
在Go中实现通信的方式一般是使用通道。所以,在工作单元中有一个通道,当该工作单元执行完具体的处理逻辑后,就往该通道中写入一个消息,以通知主协程该次请求已完成,可以返回给客户端了。
所以,一个http请求的处理逻辑看起来就像是下面这样:
func (h *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
将w和r包装成工作单元job
将job入队
等待job执行完成
本次请求处理完毕
}
下面我们看下工作单元的具体实现,这里我们将其定义为一个Job结构体:
type Job struct {
DoneChan chan struct{}
handleJob func(j FlowJob) error //具体的处理逻辑
}
Job结构体中有一个handleJob,其类型是一个函数,即处理请求的逻辑部分。DoneChan通道用来让该单元进行阻塞等待,并当handleJob执行完毕后发送消息通知的。
下面我们再看看该Job的相关行为:
// 消费者从队列中取出该job时 执行具体的处理逻辑
func (job *Job) Execute() error {
fmt.Println("job start to execute ")
return job.handleJob(job)
}
// 执行完Execute后,调用该函数以通知主线程中等待的job
func (job *Job) Done() {
job.DoneChan <- struct{}{}
close(job.DoneChan)
}
// 工作单元等待自己被消费
func (job *Job) WaitDone() {
select {
case <-job.DoneChan:
return
}
}
队列
队列主要是用来存储工作单元的。是处理请求的主协程和消费协程之间的纽带。队列具有列表、容量、当前元素个数等关键元素组成。如下:
type JobQueue struct {
mu sync.Mutex
noticeChan chan struct{}
queue *list.List
size int
capacity int
}
其行为主要有入队、出队、移除等操作。定义如下:
// 初始化队列
func NewJobQueue(cap int) *JobQueue {
return &JobQueue{
capacity: cap,
queue: list.New(),
noticeChan: make(chan struct{}, 1),
}
}
// 工作单元入队
func (q *JobQueue) PushJob(job *Job) {
q.mu.Lock()
defer q.mu.Unlock()
q.size++
if q.size > q.capacity {
q.RemoveLeastJob()
}
q.queue.PushBack(job)
q.noticeChan <- struct{}{}
}
// 工作单元出队
func (q *JobQueue) PopJob() *Job {
q.mu.Lock()
defer q.mu.Unlock()
if q.size == 0 {
return nil
}
q.size--
return q.queue.Remove(q.queue.Front()).(*Job)
}
// 移除队列中的最后一个元素。
// 一般在容量满时,有新job加入时,会移除等待最久的一个job
func (q *JobQueue) RemoveLeastJob() {
if q.queue.Len() != 0 {
back := q.queue.Back()
abandonJob := back.Value.(*Job)
abandonJob.Done()
q.queue.Remove(back)
}
}
// 消费线程监听队列的该通道,查看是否有新的job需要消费
func (q *JobQueue) waitJob() <-chan struct{} {
return q.noticeChan
}
这里我们主要解释一下入队的操作流程:
- 1 首先是队列的元素个数size++
- 2 判断size是否超过最大容量capacity
- 3 若超过最大容量,则将队列中最后一个元素移除。因为该元素等待时间最长,认为是超时的情况。
- 4 将新接收的工作单元放入到队尾。
- 5 往noticeChan通道中写入一个消息,以便通知消费协程处理Job。
由以上可知,noticeChan是队列和消费者协程之间的纽带。下面我们来看看消费者的实现。
消费者协程
消费者协程的职责是监听队列,并从队列中获取工作单元,执行工作单元的具体处理逻辑。在实际应用中,可以根据系统的承载能力启用多个消费协程。在本文中,为了方便讲解,我们只启用一个消费协程。
我们定义一个WorkerManager结构体,负责管理具体的消费协程。该WorkerManager有一个属性是工作队列,所有启动的消费协程都需要从该工作队列中获取工作单元。代码实现如下:
type WorkerManager struct {
jobQueue *JobQueue
}
func NewWorkerManager(jobQueue *JobQueue) *WorkerManager {
return &WorkerManager{
jobQueue: jobQueue,
}
}
func (m *WorkerManager) createWorker() error {
go func() {
fmt.Println("start the worker success")
var job FlowJob
for {
select {
case <-m.jobQueue.waitJob():
fmt.Println("get a job from job queue")
job = m.jobQueue.PopJob()
fmt.Println("start to execute job")
job.Execute()
fmt.Print("execute job done")
job.Done()
}
}
}()
return nil
}
在代码中我们可以看到,createWorker中的逻辑实际是一个for循环,然后通过select监听队列的noticeChan通道,当获取到工作单元时,就执行工作单元中的handleJob方法。执行完后,通过job.Done()方法通知在主协程中还等待的job。这样整个流程就形成了闭环。
完整代码
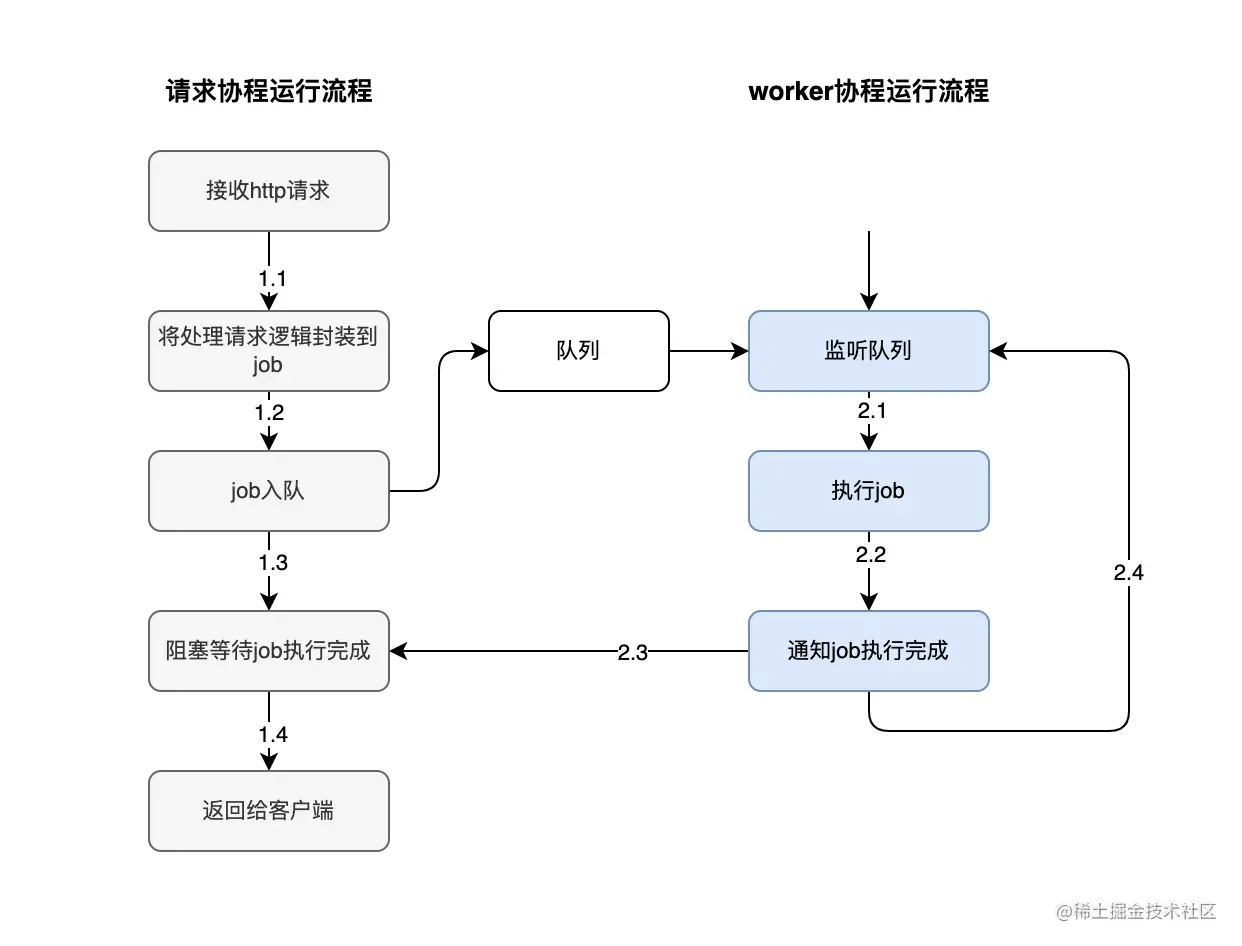
我们现在看下整体的处理流程,如下图:
现在我们写一个测试demo。在这里我们定义了一个全局的flowControl结构体,以作为队列和工作协程的管理。代码如下:
package main
import (
"container/list"
"fmt"
"net/http"
"sync"
)
func main() {
flowControl := NewFlowControl()
myHandler := MyHandler{
flowControl: flowControl,
}
http.Handle("/", &myHandler)
http.ListenAndServe(":8080", nil)
}
type MyHandler struct {
flowControl *FlowControl
}
func (h *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
fmt.Println("recieve http request")
job := &Job{
DoneChan: make(chan struct{}, 1),
handleJob: func(job *Job) error {
w.Header().Set("Content-Type", "application/json")
w.Write([]byte("Hello World"))
return nil
},
}
h.flowControl.CommitJob(job)
fmt.Println("commit job to job queue success")
job.WaitDone()
}
type FlowControl struct {
jobQueue *JobQueue
wm *WorkerManager
}
func NewFlowControl() *FlowControl {
jobQueue := NewJobQueue(10)
fmt.Println("init job queue success")
m := NewWorkerManager(jobQueue)
m.createWorker()
fmt.Println("init worker success")
control := &FlowControl{
jobQueue: jobQueue,
wm: m,
}
fmt.Println("init flowcontrol success")
return control
}
func (c *FlowControl) CommitJob(job *Job) {
c.jobQueue.PushJob(job)
fmt.Println("commit job success")
}
之前有一篇文章是优先级队列,实际上就是该队列的高级实现版本,可以将不同的请求按优先级分配到不同的队列中。有兴趣的同学可参考:Go实战 单队列到优先级队列的实现
总结
通过将请求的上下文信息封装到一个工作单元中,并将其放入到队列中,然后通过消息通道的方式阻塞等待消费者执行完毕。同时在队列中通过设置队列的容量以解决请求过多而给系统造成压力的问题。
以上就是Go http请求排队处理实战的详细内容,更多关于Go http请求排队的资料请关注好代码网其它相关文章!