CentOS7更换yum为阿里源
1 备份本地源mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2 获取阿里源配置文件
CentOS 6wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-6.repo
或者curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-6.repo
CentOS 7wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
或者curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
CentOS 8wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo
或者curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo
3 更新cacheyum makecache
4 其他
非阿里云ECS用户会出现 Couldn't resolve host 'mirrors.cloud.aliyuncs.com' 信息,不影响使用。用户也可自行修改相关配置: eg:
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
然后执行 yum clean all,再次执行 yum makecache 重新缓存
部署hadoop集群环境前的准备
本文使用Linux版本为centos7,准备3个节点,来部署hadoop集群前要做一些准备工作
具体分配规划如下所示:
| 节点名称 | 节点IP |
| ----------|------------|
| hadoop01 | 192.168.56.10 |
| hadoop02 | 192.168.56.20 |
| hadoop03 | 192.168.56.30 |
使用终端工具secureCRT链接上3台机器,切换成root用户进行如下配置:
-
关闭防火墙
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #禁止防火墙启动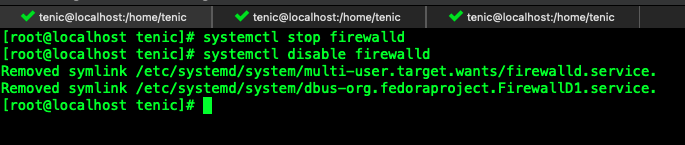
-
关闭selinux
编辑 /etc/sysconfig/selinux 文件 ,修改SELINUX=disabled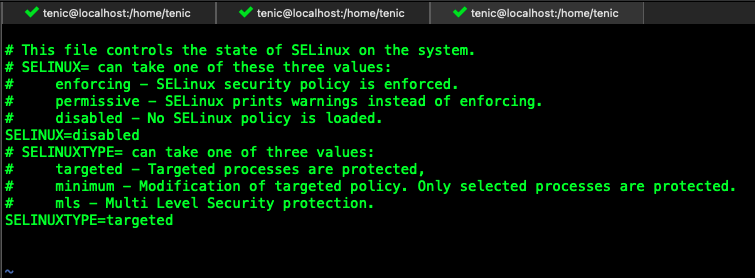
-
修改主机名称
编辑 /etc/hostname文件,3台机器分别修改成自己规划的名称
第一台 hadoop01
第二台 hadoop02
第三台 hadoop03 -
修改主机映射文件和名称
编辑 /etc/hosts文件,添加其他机器的配置信息到映射文件里
192.168.56.10 hadoop01
192.168.56.20 hadoop02
192.168.56.30 hadoop03 -
同步三台机器时间,使用阿里云时间同步器
三台机器都安装ntpdate
yum -y install ntpdate阿里云时钟同步服务器
ntpdate ntp4.aliyun.com创建一个定时任务,这样就可以自动帮我们同步到阿里云的时钟服务的时间
crontab -e
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
- 添加一个专门用来处理大数据相关的用户,例如我们设置账号为hadoop ,密码为123456,那就分别在3台机器上进行如下操作:
useradd hadoop
passwd hadoop,输入一个密码,123456
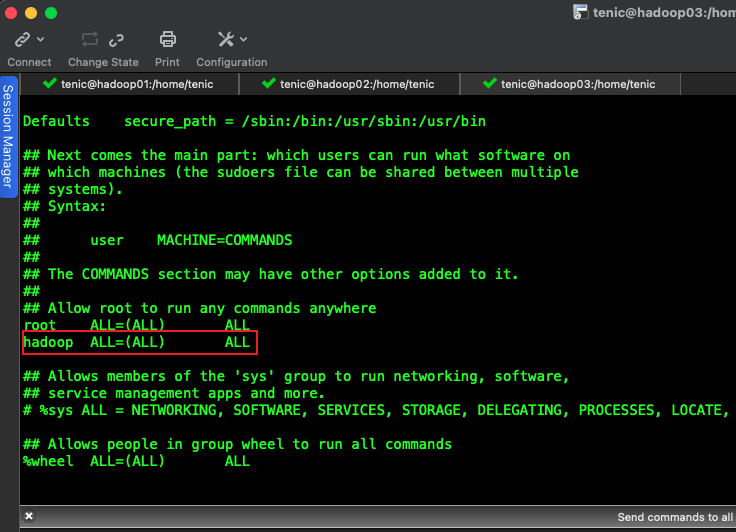
新增用户,添加root权限,省去执行权限问题
visudo
新增如下内容
hadoop ALL=(ALL) ALL
我们为这个账号创建2个文件夹,方便以后我们对的工具或者代码的管理,例如我们在根目录创建一个bigdata文件夹,
下边创建一个soft,用于放置我们上传的安装包,代码等。再创建一个install,用于放置我们安装的软件。
注意要对这2个文件夹分配所属人到我们新增加的账户 hadoop
mkdir -p /bigdata/soft
mkdir -p /bigdata/install
chown -R hadoop:hadoop /bigdata
-
免密登陆准备
由于是3台服务搭建集群,hadoop启动以后,namenode是通过SSH(Secure Shell)来启动和停止各个节点上的各种守护进程的,所以我们需要配置一下免密登陆
三台机器上都生成密钥信息
ssh-keygen -t rsa,然后是3个回车Enter现在是3台机器都生成了各自的密钥,我们在其中1台上复制粘贴其他2台的密钥,我们3台都同时执行下边命令来进行复制
ssh-copy-id hadoop01
然后在复制这个密钥文件到其他2台就可以实现3台有相同的密钥文件scp authorized_keys hadoop02:$PWDscp authorized_keys hadoop03:$PWD验证一把,在hadoop01上输入ssh hadoop02,查看是否当前机器变成了hadoop02
-
安装JDK
我们将本地的jdk文件上传到hadoop01,并对其进行解压和配置profile文件cd /bigdata/softtar -zxf jdk-8u141-linux-x64.tar.gz -C /bigData/install将hadoop01机器上的jdk复制到其他机器上去
scp -r /bigdata/install/jdk1.8.0_141 hadoop@hadoop02:/bigdata/installscp -r /bigdata/install/jdk1.8.0_141 hadoop@hadoop03:/bigdata/install编辑配置文件,执行命令 sudo vim /etc/profile
export JAVA_HOME=/bigdata/install/jdk1.8.0_141export PATH=$PATH:$JAVA_HOME/bin激活一下profile文件 source /etc/profile
~/.bash_profile失效
环境变量准备
在~/.bash_profile下配置了环境变量相关的路径信息,比如$HOME/bin路径。就是说会把$HOME/bin目录下的命令添加到环境变量中去。
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
交代一下背景情况:
创建了一台虚拟机,里面有多个账户,比如有tenic/hadoop账户,在hadoop账户下边的$HOME目录下的bin文件夹下创建了一个命令,
且命令有在hadoop用户的~/.bash_profile中定义环境变量到相应的bin路径。
使用secureCRT/xshell登录到虚拟机时使用的是tenic,然后切换到hadoop用户。执行hadoop用户bin目录下的命令时,提示命令不存在的问题。
解决方法一:
su 是最简单的用户切换命令,通过该命令可以实现任何身份的切换,包括从普通用户切换为 root 用户、从 root 用户切换为普通用户以及普通用户之间的切换。
我们看一下su的帮助信息
hadoop@hadoop01 ~]$ su --help
Usage:
su [options] [-] [USER [arg]...]
Change the effective user id and group id to that of USER.
A mere - implies -l. If USER not given, assume root.
Options:
-m, -p, --preserve-environment do not reset environment variables
-g, --group <group> specify the primary group
-G, --supp-group <group> specify a supplemental group
-, -l, --login make the shell a login shell
-c, --command <command> pass a single command to the shell with -c
--session-command <command> pass a single command to the shell with -c
and do not create a new session
-f, --fast pass -f to the shell (for csh or tcsh)
-s, --shell <shell> run shell if /etc/shells allows it
-h, --help display this help and exit
-V, --version output version information and exit
For more details see su(1).
从帮助文档中可以看到,su后边可以添加多个可选入参,其中有一个 [-] 表示shell也跟着一起变更,
也就是说使用 [-] 选项表示在切换用户身份的同时,连当前使用的环境变量也切换成指定用户的。
解决方法二:
我们在2个用户的/.bashrc文件下添加一个echo语句,可以查看到,当切换用户不使用[-]时,会加载切换用户的/.bashrc环境变量,
所以我们可以在~/.bashrc文件中添加上我们想要添加的环境变量。如下边的图所示: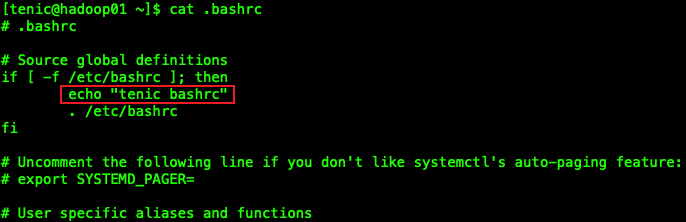
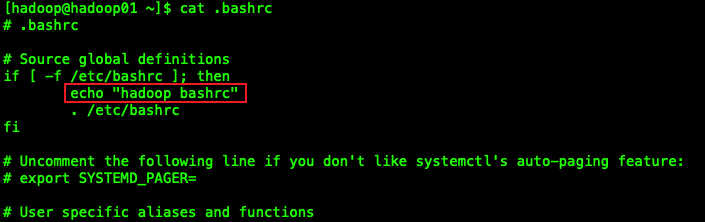
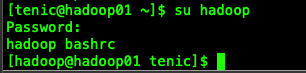
我们在我们想要切换的用户的~/.bahsrc中添加上相应的环境变量路径上去就可以了。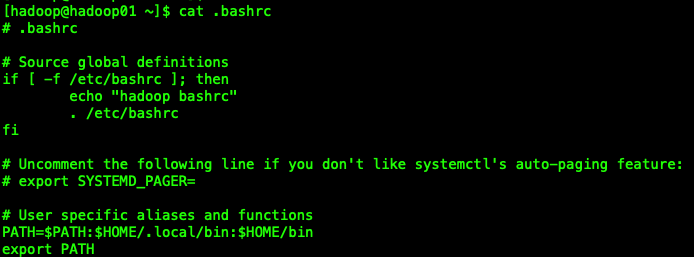
从我们打印出的$PATH路径可以看出,目前环境变量信息已经添加上我们切换用户的路径了。

centos7 安装docker
1.卸载系统自带的docker软件
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2.按装docker必须依赖的包
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
3.添加docker仓库信息
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
4.安装docker engine-community
sudo yum install docker-ce docker-ce-cli containerd.io
如果提示您接受GPG密码,输入y
5.添加镜像加速地址(可以找阿里云获取其他平台的镜像加速地址)
sudo makdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors":["https://xxxxx.mirror.aliyuncs.com"]
}
EOF
6.启动docker,并设置为开机启动
sudo systemclt start docker
sudo systemctl enable dockerdocker安装nginx和tomcat
- 下载nginx和tomcat的镜像信息
docker pull nginx
docker pull tomcat
- 创建nginx和tomcat需要挂载的目录
mkdir -p /bigdata/install/nginx/www /bigdata/install/nginx/conf/ /bigdata/install/nginx/logs
mkdir -p /bigdata/install/tomcat/webapps1/ROOT \
/bigdata/install/tomcat/webapps2/ROOT \
/bigdata/install/tomcat/logs/log1 \
/bigdata/install/tomcat/logs/log2
- 启动2台tomcat 作负载均衡
docker run --name tomcat1 \
-v /bigdata/install/tomcat/webapps1:/usr/local/tomcat/webapps \
-v /bigdata/install/tomcat/logs/log1:/usr/local/tomcat/logs \
-d tomcat
docker run --name tomcat2 \
-v /bigdata/install/tomcat/webapps2/:/usr/local/tomcat/webapps \
-v /bigdata/install/tomcat/logs/log2:/usr/local/tomcat/logs \
-d tomcat
- 获取tomcat容器的ip信息
docker inspect tomcat1|grep "IPAddress"
docker inspect tomcat2|grep "IPAddress"
- 配置nginx.conf
cd /bigdata/install/nginx/conf
vi nginx.conf
##复制如下内容到文件中去
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" "$upstream_addr"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
upstream tomcat {
server 172.17.0.2:8080;##上一步查到的IP和端口
server 172.17.0.3:8080;##上一步查到的IP和端口
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://tomcat/;
proxy_redirect off;
index index.html index.htm;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Real-Port $remote_port;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
include /etc/nginx/conf.d/*.conf;
}
- 启动nginx
docker run -p 80:80 --name nginx \
-v /bigdata/install/nginx/www:/usr/share/nginx/html \
-v /bigdata/install/nginx/conf/nginx.conf:/etc/nginx/nginx.conf \
-v /bigdata/install/nginx/logs:/var/log/nginx \
-d nginx
- 添加静态页面,区分不同的tomcat
cd /bigdata/install/tomcat/webapps1/ROOT
vi index.html
##复制以下内容,贴入文件
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>docker deployment</title>
</head>
<body>
<h1>hello, world!--by tomcat1</h1>
<h1>hello, tenic</h1>
</body>
</html>
tomcat2的配置页面同理,只是将tomcat1修改为tomcat2
- 访问页面,可以看到有2个页面在替换


shell定时上传linux日志信息到hdfs
从标题可以分析出来,我们要使用到shell,还要推送日志信息到hdfs上。
- 定义出上传的路径和临时路径,并配置好上传的log日志信息。
这里我使用了上一节配置的nginx的error.log
#上传log日志文件的存放路径
/bigdata/logs/upload/log/
#上传log日志文件的临时路径
/bigdata/logs/upload/templog/
将nginx的error.log放在上传log日志的文件夹下边,如下图所示
- 在~/bin目录下创建我们的shell脚本文件
vi uploadFileToHdfs.sh
##复制如下内容,并保存退出
#!/bin/bash
#set java env
export JAVA_HOME=/bigdata/install/jdk1.8.0_141
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/bigdata/install/hadoop-3.1.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录
log_src_dir=/bigdata/logs/upload/log/
#待上传文件存放的目录
log_toupload_dir=/bigdata/logs/upload/templog/
#日志文件上传到hdfs的根路径
date1=`date -d last-day +%Y_%m_%d`
hdfs_root_dir=/data/log/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == *.log ]]; then
date=`date +%Y_%m_%d_%H_%M_%S`
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"temp_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"temp_$fileName"$date
#将待上传的文件path写入一个列表文件will
echo $log_toupload_dir"temp_$fileName"$date >> $log_toupload_dir"will."$date
fi
done
#找到列表文件will
ls $log_toupload_dir | grep will |grep -v "_DOING_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表will改名为will_DOING_
mv $log_toupload_dir$line $log_toupload_dir$line"_DOING_"
#读列表文件will_DOING_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_DOING_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_DOING_" $log_toupload_dir$line"_DONE_"
done
- 执行脚本,查看结果
sh uploadFileToHdfs.sh
shell脚本添加新用户、删除用户
使用shell脚本添加新用户,设置密码,和删除用户
#!/bin/bash
read -p "是否要添加用户? 是(0)否(1)" USERADD
if [ $USERADD -eq 0 ];then
C=1
while [ $C -eq 1 ];do
read -p "请输入添加账户账户名:" UNAME #添加用户名#
id $UNAME &> /dev/null #查看用户是否存在#
if [ $? -eq 0 ];then
echo "账户已存在! "
else
read -p "请输入添加账户密码:" PASSWD #添加密码#
useradd $UNAME &> /dev/null #创建用户#
echo "$PASSWD" | passwd --stdin $UNAME &> /dev/null #创建用户密码#
if [ $? -eq 0 ];then
echo " $UNAME 创建成功! "
else
echo " $UNAME 创建失败! "
fi
fi
read -p "您是否还继续添加?是(1)否(0)" C #设定变量“C”以实现删除代码循环执行#
done
else
DEL=1
while [ $DEL -eq 1 ];do
read -p "请输入要删除的用户名:" UNAME #要删除的用户名#
id $UNAME &> /dev/null
if [ $? -eq 0 ];then #删除用户查询是否存在#
userdel -r $UNAME #删除用户#
echo " $UNAME 删除成功! "
else
echo "未找到用户$UNAME!"
fi
read -p "您是否继续?是(1)否(0)" DEL #设定变量“DEL”以实现删除代码循环执行#
done
fiCentos7 Mysql 的安装和卸载
安装部分
使用root用户,进入到/bigdata/soft目录,下载的文件会到这个目录,并安装wget工具
cd /bigdata/soft
yum -y install wget
使用wget命令下载MySQL的rpm包
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
安装MySQL
yum -y install mysql57-community-release-el7-10.noarch.rpm
安装MySQL Server
yum -y install mysql-community-server
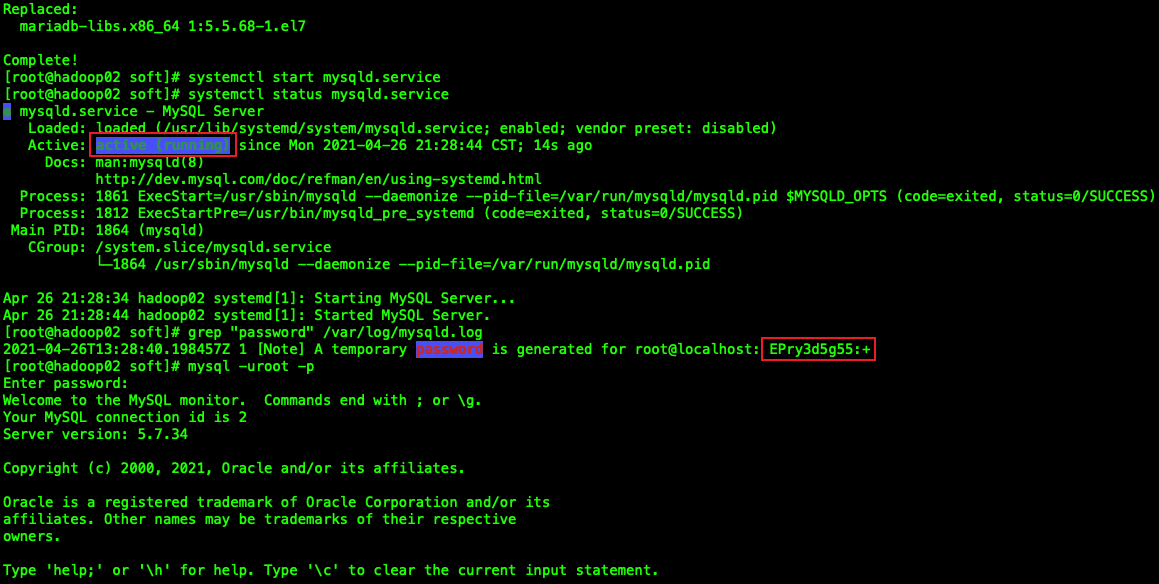

通过DBeaverEE 连接测试成功!
删除部分
上面我们在CentOS 7当中已经安装好了5.7版本的mysql服务;
如果以后我们不需要mysql了,或者mysql安装失败了需要重新安装,那么我们需要将mysql卸载掉
使用root用户,执行下边命令
##停止mysql服务
systemctl stop mysqld.service
##列出要删除的mysql相关的包
yum list installed mysql*
## 卸载rpm包,使用yum remove卸载,后边依次加入上图的包名,包名之间有空格
yum remove mysql57-community-release-el7-10.noarch \
mysql-community-common-5.7.28-1.el7.x86_64 \
mysql-community-client-5.7.28-1.el7.x86_64 \
mysql-community-libs-compat-5.7.28-1.el7.x86_64 \
mysql-community-libs-5.7.28-1.el7.x86_64 \
mysql-community-server-5.7.28-1.el7.x86_64
##查看是否卸载干净
yum list installed mysql*
##查找mysql剩余文件
find / -name mysql
##删除查找到的文件
rm -rf /var/lib/mysql/
rm -rf /usr/share/mysql/
rm -rf /etc/selinux/targeted/active/modules/100/mysql
##删除日志文件
rm -rf /root/.mysql_history
rm -f /var/log/mysqld.log
Shell 基本语法
变量命名
定义变量时,变量名不加美元符号($)
注意,变量名和等号之间不能有空格,同时,变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
使用变量
使用一个定义过的变量,只要在变量名前面加美元符号即可
a=10
echo "a=$a"
返回结果:
a=10
只读变量
使用readonly命令可以将变量定义为只读变量,只读变量的值不能被改变
#!/bin/bash
myUrl="https://cnblogs.com/tenic"
readonly myUrl
myUrl="https://www.google.com"
返回结果
myUrl: readonly variable
删除变量
使用unset命令可以删除变量,删除后不能再次使用
unset myUrl
shell 字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
- 单引号
str='this is a string'
echo $str
返回结果:
this is a string
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
- 双引号
your_name='tenic'
str="Hello, I know you are \"$your_name\"! \n"
echo -e $str
输出结果为:
Hello, I know you are "tenic"!
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
- 拼接字符串
your_name="tenic"
# 使用双引号拼接
greeting="hello, "$your_name" !"
greeting_1="hello, ${your_name} !"
echo $greeting $greeting_1
# 使用单引号拼接
greeting_2='hello, '$your_name' !'
greeting_3='hello, ${your_name} !'
echo $greeting_2 $greeting_3
输出结果为:
hello, tenic ! hello, tenic !
hello, tenic ! hello, ${your_name} !
- 获取字符串长度
string="abcd"
echo ${#string} #输出 4
- 提取子字符串
以下实例从字符串第 2 个字符开始截取 4 个字符:
string="cnblogs is a great site"
echo ${string:1:4} # 输出 nblo
注意:第一个字符的索引值为 0。
- 查找子字符串
查找字符 i 或 o 的位置(哪个字母先出现就计算哪个):
string="cnblogs is a great site"
echo `expr index "$string" io` # 输出 4
注意: 以上脚本中 ` 是反引号,而不是单引号 ',不要看错了哦。
Shell 注释
-
单行注释
以 # 开头的行就是注释,会被解释器忽略。
通过每一行加一个 # 号设置多行注释, -
多行注释
当需要注释多行代码时,可以使用:<<EOF... EOF格式
EOF可以使用其他符号,比如!或者'
:<<!
注释内容。。。
注释内容。。。
注释内容。。。
!
传输参数
我们在执行shell脚本的时候,可以向shell脚本中传递参数,在shell脚本中使用这些传入的参数
在脚本中使用 $N,N代表数字,1,2,3
echo "接收的第一个参数是:$1"
echo "接收的第二个参数是:$2"
使用特殊字符来处理参数接收
echo '测试$*'
for i in "$*";do
echo i;
done
echo '测试$@'
for i in "$@";do
echo i
done
返回结果
./demo1.sh a b c
测试$*
a b c
测试$@
a
b
c
$* 与 $@ 区别:
相同点:都是引用所有参数。
不同点:只有在双引号中体现出来。假设在脚本运行时写了三个参数 1、2、3,,则 " * " 等价于 "1 2 3"(传递了一个参数),而 "@" 等价于 "1" "2" "3"(传递了三个参数)。
默认是只有9个参数,那如果我们要取第10个参数要怎么取呢?
echo "第10个参数${10}"
算术运算符
shell和其他编程一样,支持包括:算术,关系,布尔,字符串等运算符。
原生bash不支持简单的数学运算,单是可以通过其他命令来实现,例如expr
expr是一款表达式计算工具,使用它能完成表达式求值操作。
使用expr表达式时要注意:
操作数和运算符之间要有空格,eg:2 + 2,而不能写成2+2
完整的表达是要被`包含
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20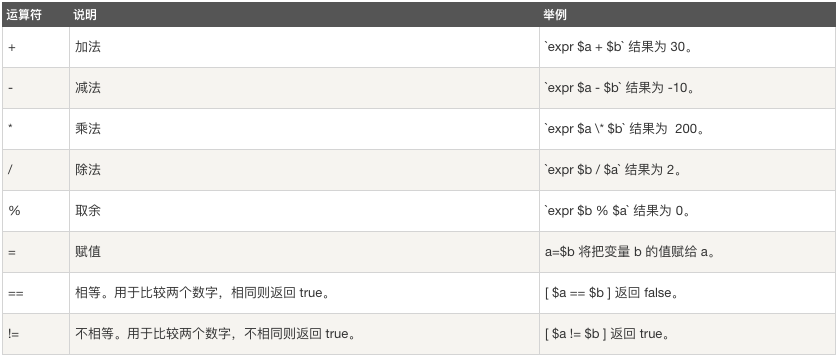
布尔运算符
下表列出了常用的布尔运算符,假定变量 a 为 10,变量 b 为 20
逻辑运算符
以下介绍 Shell 的逻辑运算符,假定变量 a 为 10,变量 b 为 20
字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 "abc",变量 b 为 "efg"
程序流程
1.条件分支结构
1.1 if条件分支
常用的判定条件运算符:
只支持数字,不支持字符串,除非字符串的值是数字
#! /bin/bash
a=20
b=10
#单if模式
if [ $a -gt $b ];then
echo "a大于b"
fi
#双分支模式
scores=66
if [ $scores -gt 60 ];then
echo "成绩合格"
else
echo "成绩不合格"
fi
#多分支结构
scores02=95
if [ $scores02 -gt 90 ];then
echo "成绩优秀"
elif [ $scores02 -gt 80 ];then
echo "成绩良好"
elif [ $scores02 -gt 70 ];then
echo "成绩中等"
elif [ $scores02 -gt 60 ];then
echo "成绩及格"
else
echo "成绩不及格"
fi
1.2 case条件分支
用case语句匹配一个值于一个模式,如果匹配成功,执行匹配的命令
取值后面必须位单词 in,每一模式必须以右括号结束。取值可以为变量或常数。匹配发现取值符合某一模式后,其间所有命令开始执行直至;;(类似java中的break)。
取值将检测匹配每一个模式,一旦匹配,则执行完匹配模式相应命令后,不在继续其他模式。如果无一匹配模式,使用* (类似java中的default)捕获该值,在执行后面的命令。
#!/bin/bash
a=20
case $a in
10) echo "a的值是10"
;;
20)echo "a的值是20"
;;
*) echo "a的值不是10也不是20"
;;
esac
循环结构
1.for循环
使用循环遍历1-5
#! /bin/bash
echo "第一种方式"
for i in 1 2 3 4 5; do
echo $i
done
echo "第二种方式"
for i in (1..5); do
echo $i
done
echo "使用循环遍历1-5中的奇数,1-5,步长是2"
for i in (1..5..2);do
echo $i
done
echo "使用遍历访问目录下的内容"
for i in 'ls /';do
echo $i
done
2.while循环
计算1加到10的值
#!/bin/bash
sum=0
i=1
while [ $i -ge 10 ];do
sum=$[sum + i]
i=$[i + 1]
done
echo $sum
每个1秒打印一次系统时间
#!/bin/bash
while true;do
date
sleep 1
done
break和continue
break是结束所有循环
#!/bin/bash
i=1
while true; do
if [ $i -gt 10 ];then
break;
fi
echo $i
date
sleep1
i=$[i + 1]
done
continue是结束本次,进入下次循环
#!/bin/bash
for i in (1..20);do
if test $[ i % 3] -eq 0;then
continue
fi
echo $i
done
3 util 循环
until 循环执行一系列命令直至条件为 true 时停止。
until 循环与 while 循环在处理方式上刚好相反。
一般 while 循环优于 until 循环,但在某些时候—也只是极少数情况下,until 循环更加有用。
until condition
do
command
done
condition 一般为条件表达式,如果返回值为 false,则继续执行循环体内的语句,否则跳出循环
函数
#!/bin/bash
print(){
echo "this is my first function"
}
echo "调用函数print开始"
print
echo "调用函数print结束"
- 函数传参
调用函数时可以向其传递参数,在函数体内部,通过$n的形式来获取参数的值,注意:$10不能获取到第10个参数,要使用${10}来获取
#!/bin/bash
print(){
echo "第一个参数是:$1"
echo "第10个参数是:${10}"
}
print 1 2 3 4 5 6 7 8 9 10 11
- 返回值
add(){
return $[ $1 + $2 ]
}
add 1 2
echo $? # $?可以获取最后命令执行的结果作为返回值使用
数组
特点
bash中的数组只支持一维数组
初始化时不需要定义数组大小
数组元素的下标由0开始
用括号表示,元素用空格符号分隔开
- 读取数组
#!/bin/bash
arr01=(1 3 "a" "abc")
echo "数组第一个元素${arr01[0]}"
echo "数组最后一个元素${arr01[10]}"
echo "读取数组全部数据${arr01[*]}"
echo "读取数组的长度:${#arr01[*]}"
arr01[3]="dff"
echo "修改后的数组全部数据为${arr01[*]}"
- 遍历数组
for i in ${arr01[*]};do
echo $i
done
函数引用
使用source 来加载另外一个shell脚本
或者使用 .来加载
#! /bin/bash
source ./demo11.sh
for i in ${arr01[*]};do
echo $i
done