在平常的一些的小规模的数据的过滤、清洗过程中使用最多的就是正则表达式,但是随着数据规模的增大,正则表达式就显得有些心有余力不足了。
正则表达式在一个 10k 的词库中查找 15k 个关键词的时间差不多是 0.165 秒。但是对于 Flashtext 而言只需要 0.002 秒。因此,在这个问题上 Flashtext的速度大约比正则表达式快 82 倍。
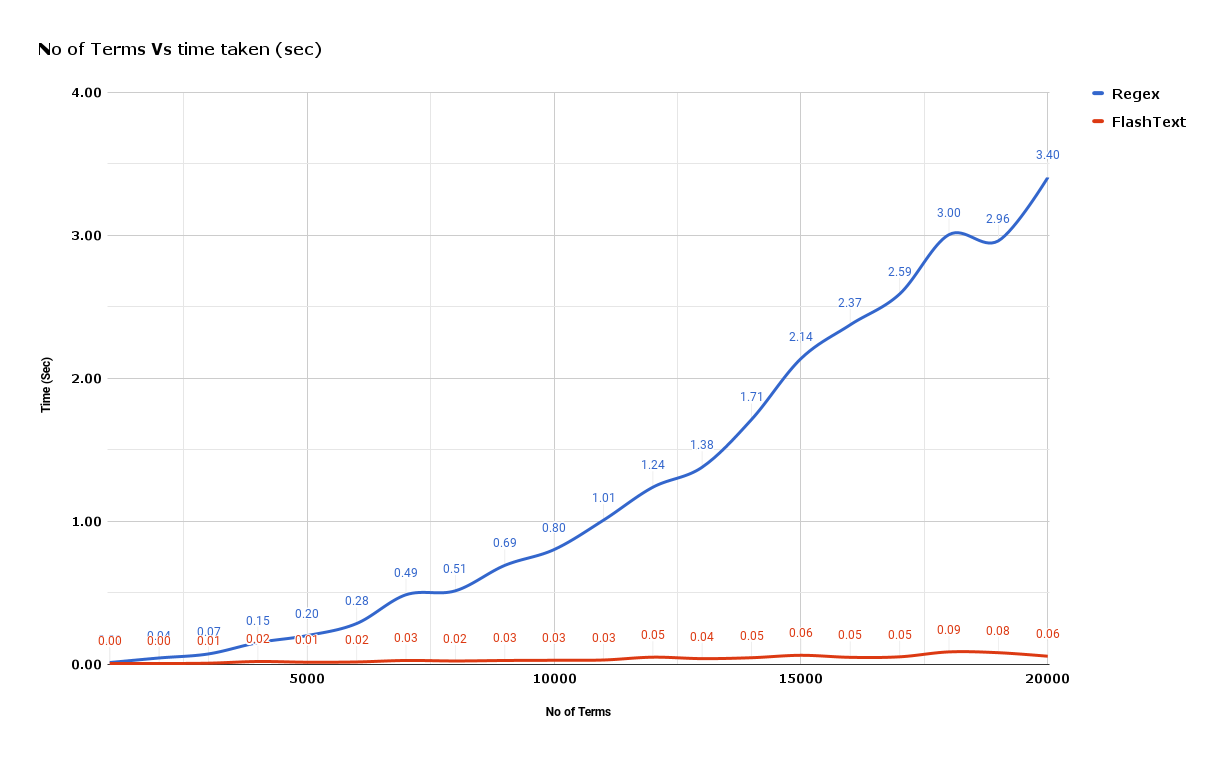
从上面的示例图的性能对比中,可以发现随着我们需要处理的字符越来越多,正则表达式的处理速度几乎都是线性增加的。然而,Flashtext 几乎是一个常量。
1、准备flashtext环境
通过pip的方式来安装flashtext,或是其他的方式也是可以的,这里默认使用的是清华大学的镜像站。
pip install flashtext -i https://pypi.tuna.tsinghua.edu.cn/simple
在准备好flashtext环境以后,来看一下flashtext重要的使用过程,帮助我们能更好的完成数据清洗操作。
2、添加关键词
这里添加关键词时是通过单个关键词的来添加到关键词词库中,使用add_keyword函数来添加。第一次参数表示需要添加的关键词,第二个参数则表示为第一个关键词的别名,如果关键词被找到了则显示为别名的形式,若是没有使用第二个参数作为别名则还是显示原有的名称。
from flashtext import KeywordProcessor
# 初始化关键词库处理器
processor = KeywordProcessor()
# 常规方式添加关键词
processor.add_keyword('Python')
# 别名方式添加关键词
processor.add_keyword('Scala', 'Java')
这样分别使用两种方式已经将需要的关键词添加到词库处理器中了。
3、提取关键词
通过上一步添加关键词,现在词库处理器中已经存在有关键词的信息了,再使用extract_keywords将关键词提取出来即可。
# 在一个字符串中提取出关键词信息
found = processor.extract_keywords('I like Python and Scala.')
# 结果
print(found)
# ['Python', 'Java']
结果出来了,跟我们预想的是一样的,并Scala也显示为了Java。
4、替换关键词
替换关键词使用的是replace_keywords函数,前提是词库中拥有别名的词才能被替换,就像上面的Scala被显示成了的Java一样。
替换一个字符串中的Scala关键词,由于Scala对应的别名是Java,所以一个字符串中的Scala应该被替换为Java。
replaced = processor.replace_keywords('I like Scala.')
# 结果
print(replaced)
# I like Java.
# Scala 果真就被替换为了Java。
5、获取所有关键词
有些时候,在KeywordProcessor词库处理器中添加了哪些关键词可能自己都记不清楚了,这个时候可以使用get_all_keywords函数来获取当前的所有关键词。
all_keywords = processor.get_all_keywords()
# 结果
print(all_keywords)
# {'python': 'Python', 'scala': 'Java'}
6、批量的添加关键词
当关键词库需要更多的关键词的时候,可以通过列表或是字典的方式来进行批量的添加。对应的函数分别是add_keywords_from_list、add_keywords_from_dict函数。
# 初始化一个字典通过用来做批量添加
dict_ = {
'java': ['java_ee', 'java_se', 'java_me'],
'python': ['pandas', 'all']
}
# 通过字典的方式来批量添加关键词
processor.add_keywords_from_dict(dict_)
# 从批量添加的关键词中匹配关键词
result = processor.extract_keywords('looking for java_ee and pandas.')
# 结果
print(result)
# ['java', 'python']
# 通过列表的方式批量添加关键词
processor.add_keywords_from_list(['scala', 'python', 'scala', 'go'])
# 通过get_all_keywords查看一下所有关键词
all_keywords = processor.get_all_keywords()
# 结果
print(all_keywords)
# {'python': 'python', 'pandas': 'python', 'scala': 'scala', 'java_ee': 'java', 'java_se': 'java', 'java_me': 'java', 'all': 'python', 'go': 'go'}
发现所有的关键词已经添加到词库处理器中,并且重复的不会再次添加。
7、批量删除关键词
批量删除词库处理器中的关键词同样是有两种方式,一个是列表、另一个是字典。对应的函数分别是remove_keywords_from_list、remove_keywords_from_dict函数。
# 批量移除列表中的关键词
processor.remove_keywords_from_list(['python','java_ee','java_me'])
# 批量移除字典中的关键词
processor.remove_keywords_from_dict({'python': ['pandas','all']})
# 通过get_all_keywords查看一下所有关键词
all_keywords = processor.get_all_keywords()
# 结果
print(all_keywords)
# {'scala': 'scala', 'java_se': 'java', 'go': 'go'}
发现需要移除的关键词已经被全部移除了。
8、执行效率对比
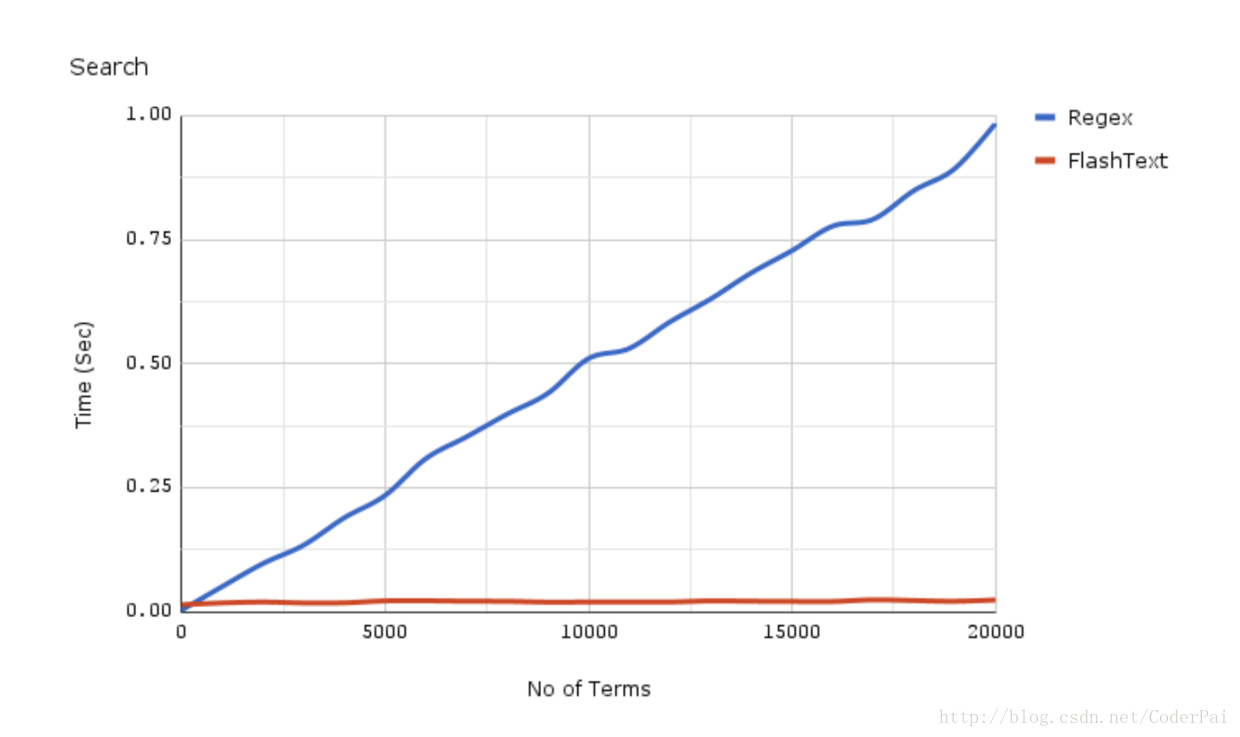
为了更可观的展示效果,找了两个flashtext在搜索和替换关键词过程中的效率对比图可以一目了然。
flashtext、正则表达式搜索效率对比
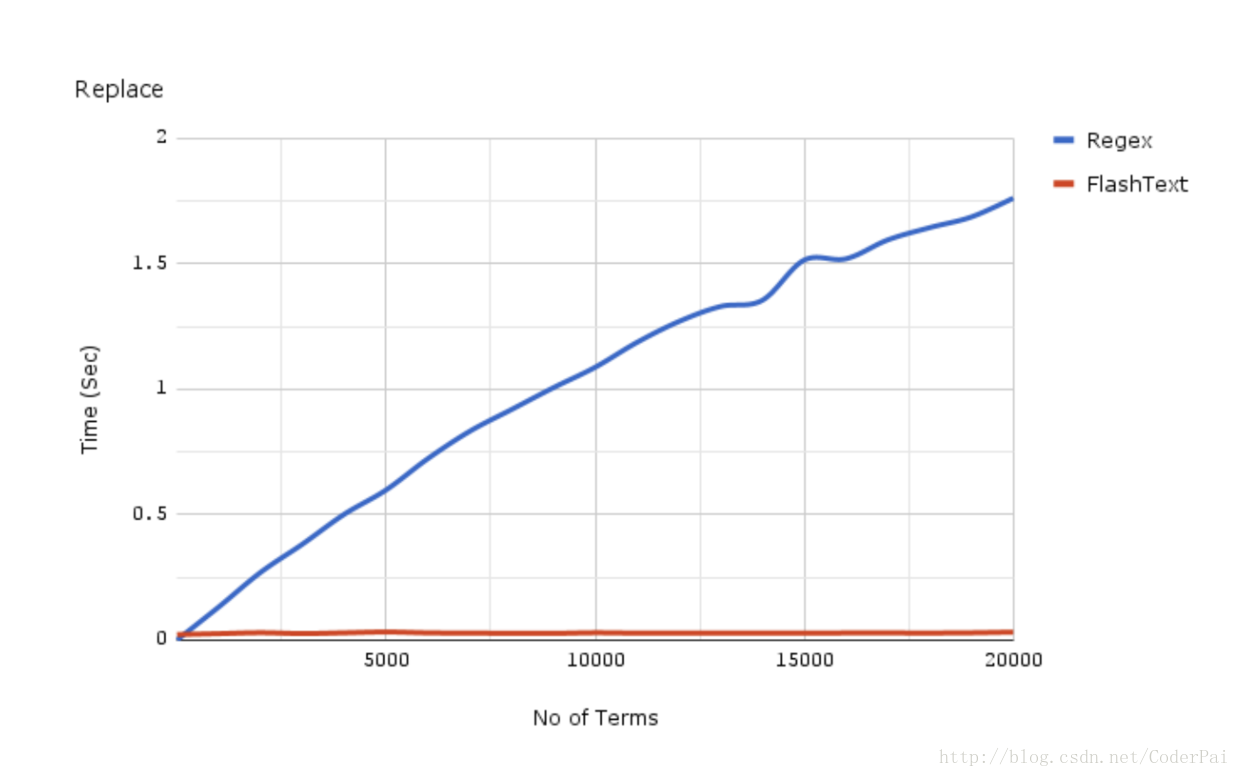
flashtext、正则表达式搜索替换对比
以上就是详解Python中的数据清洗工具flashtext的详细内容,更多关于Python数据清洗的资料请关注好代码网其它相关文章!