1、Apache Linkis 介绍
Linkis 在上层应用和底层引擎之间构建了一层计算中间件。通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问Spark, Presto, Flink 等底层引擎,同时实现跨引擎上下文共享、统一的计算任务和引擎治理与编排能力。
MySQL/Spark/Hive/Presto/Flink 等底层引擎,同时实现变量、脚本、函数和资源文件等用户资源的跨上层应用互通。作为计算中间件,Linkis 提供了强大的连通、复用、编排、扩展和治理管控能力。通过计算中间件将应用层和引擎层解耦,简化了复杂的网络调用关系,降低了整体复杂度,同时节约了整体开发和维护成本。
2.1 计算中间件概念
没有Linkis之前
上层应用以紧耦合方式直连底层引擎,使得数据平台变成复杂的网状结构
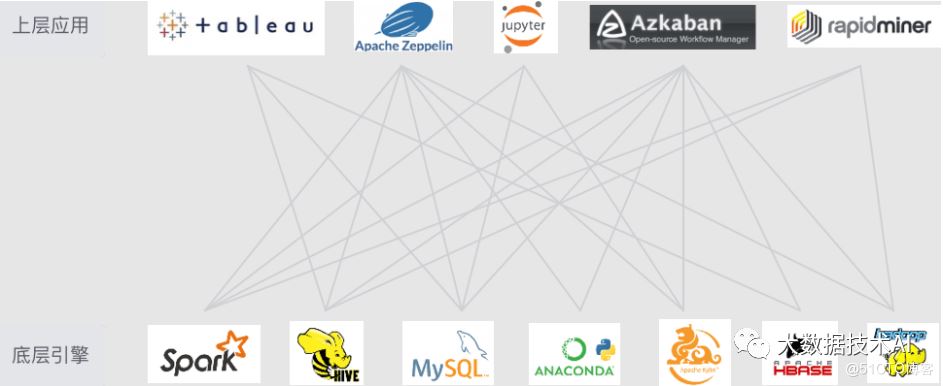
有Linkis之后
通过计算中间件将应用层和引擎层解耦,以标准化可复用方式简化复杂的网状调用关系,降低数据平台复杂度

2.2 整体架构
Linkis 在上层应用和底层引擎之间构建了一层计算中间件。通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问Spark, Presto, Flink 等底层引擎。
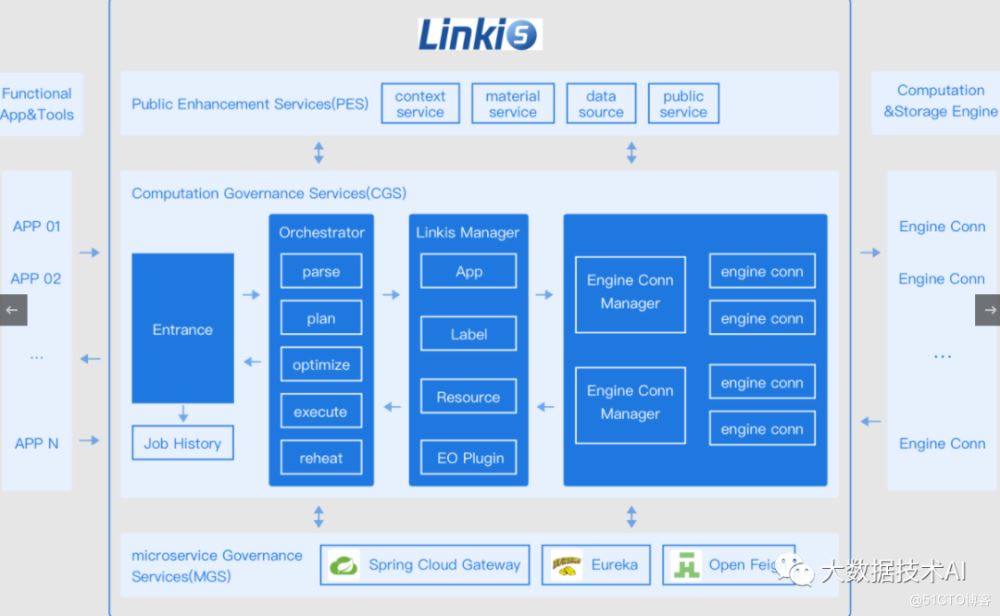
2.3 核心特点
- 丰富的底层计算存储引擎支持。目前支持的计算存储引擎:Spark、Hive、Python、Presto、ElasticSearch、MLSQL、TiSpark、JDBC和Shell等。正在支持中的计算存储引擎:Flink(>=1.0.2版本已支持)、Impala等。支持的脚本语言:SparkSQL, HiveQL, Python, Shell, Pyspark, R, Scala 和JDBC 等。
- 强大的计算治理能力。基于Orchestrator、Label Manager和定制的Spring Cloud Gateway等服务,Linkis能够提供基于多级标签的跨集群/跨IDC 细粒度路由、负载均衡、多租户、流量控制、资源控制和编排策略(如双活、主备等)支持能力。
- 全栈计算存储引擎架构支持。能够接收、执行和管理针对各种计算存储引擎的任务和请求,包括离线批量任务、交互式查询任务、实时流式任务和存储型任务;
- 资源管理能力。ResourceManager 不仅具备 Linkis0.X 对 Yarn 和 Linkis EngineManager 的资源管理能力,还将提供基于标签的多级资源分配和回收能力,让 ResourceManager 具备跨集群、跨计算资源类型的强大资源管理能力。
- 统一上下文服务。为每个计算任务生成context id,跨用户、系统、计算引擎的关联管理用户和系统资源文件(JAR、ZIP、Properties等),结果集,参数变量,函数等,一处设置,处处自动引用;
- 统一物料。系统和用户级物料管理,可分享和流转,跨用户、系统共享物料。
2.4 支持的引擎类型
引擎 | 引擎版本 | Linkis 0.X 版本要求 | Linkis 1.X 版本要求 | 说明 |
Flink | 1.12.2 | >=dev-0.12.0, PR #703 尚未合并 | >=1.0.2 | Flink EngineConn。支持FlinkSQL 代码,也支持以Flink Jar 形式启动一个新的Yarn 应用程序。 |
Impala | >=3.2.0, CDH >=6.3.0" | >=dev-0.12.0, PR #703 尚未合并 | ongoing | Impala EngineConn. 支持Impala SQL 代码. |
Presto | >= 0.180 | >=0.11.0 | ongoing | Presto EngineConn. 支持Presto SQL 代码. |
ElasticSearch | >=6.0 | >=0.11.0 | ongoing | ElasticSearch EngineConn. 支持SQL 和DSL 代码. |
Shell | Bash >=2.0 | >=0.9.3 | >=1.0.0_rc1 | Shell EngineConn. 支持Bash shell 代码. |
MLSQL | >=1.1.0 | >=0.9.1 | ongoing | MLSQL EngineConn. 支持MLSQL 代码. |
JDBC | MySQL >=5.0, Hive >=1.2.1 | >=0.9.0 | >=1.0.0_rc1 | JDBC EngineConn. 已支持MySQL 和HiveQL,可快速扩展支持其他有JDBC Driver 包的引擎, 如Oracle. |
Spark | Apache 2.0.0~2.4.7, CDH >=5.4.0 | >=0.5.0 | >=1.0.0_rc1 | Spark EngineConn. 支持SQL, Scala, Pyspark 和R 代码. |
Hive | Apache >=1.0.0, CDH >=5.4.0 | >=0.5.0 | >=1.0.0_rc1 | Hive EngineConn. 支持HiveQL 代码. |
Hadoop | Apache >=2.6.0, CDH >=5.4.0 | >=0.5.0 | ongoing | Hadoop EngineConn. 支持Hadoop MR/YARN application. |
Python | >=2.6 | >=0.5.0 | >=1.0.0_rc1 | Python EngineConn. 支持python 代码. |
TiSpark | 1.1 | >=0.5.0 | ongoing | TiSpark EngineConn. 支持用SparkSQL 查询TiDB. |
2、Apache Linkis 快速部署
2.1 注意事项
因为mysql-connector-java驱动是GPL2.0协议,不满足Apache开源协议关于license的政策,因此从1.0.3版本开始,提供的Apache版本官方部署包,默认是没有mysql-connector-java-x.x.x.jar的依赖包,安装部署时需要添加依赖到对应的lib包中。
Linkis1.0.3 默认已适配的引擎列表如下:
引擎类型 | 适配情况 | 官方安装包是否包含 |
Python | 1.0已适配 | 包含 |
Shell | 1.0已适配 | 包含 |
Hive | 1.0已适配 | 包含 |
Spark | 1.0已适配 | 包含 |
2.2 确定环境
2.2.1 依赖
引擎类型 | 依赖环境 | 特殊说明 |
Python | Python环境 | 日志和结果集如果配置hdfs://则依赖HDFS环境 |
JDBC | 可以无依赖 | 日志和结果集路径如果配置hdfs://则依赖HDFS环境 |
Shell | 可以无依赖 | 日志和结果集路径如果配置hdfs://则依赖HDFS环境 |
Hive | 依赖Hadoop和Hive环境 | |
Spark | 依赖Hadoop/Hive/Spark |
要求:安装Linkis需要至少3G内存。
默认每个微服务JVM堆内存为512M,可以通过修改SERVER_HEAP_SIZE来统一调整每个微服务的堆内存,如果您的服务器资源较少,我们建议修改该参数为128M。如下:
vim ${LINKIS_HOME}/deploy-config/linkis-env.sh
# java application default jvm memory.
export SERVER_HEAP_SIZE="128M"2.2.2 环境变量
官网示例:
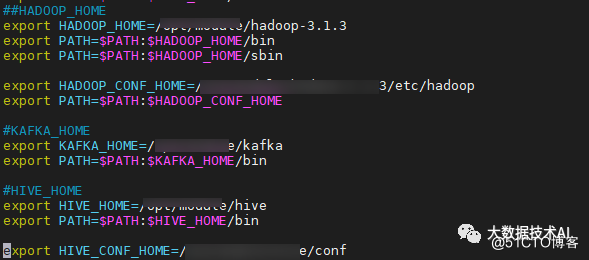
#JDK export JAVA_HOME=/nemo/jdk1.8.0_141 ##如果不使用Hive、Spark等引擎且不依赖Hadoop,则不需要修改以下环境变量 #HADOOP export HADOOP_HOME=/appcom/Install/hadoop export HADOOP_CONF_DIR=/appcom/config/hadoop-config #Hive export HIVE_HOME=/appcom/Install/hive export HIVE_CONF_DIR=/appcom/config/hive-config #Spark export SPARK_HOME=/appcom/Install/spark export SPARK_CONF_DIR=/appcom/config/spark-config/ export PYSPARK_ALLOW_INSECURE_GATEWAY=1 # Pyspark必须加的参数
示例:
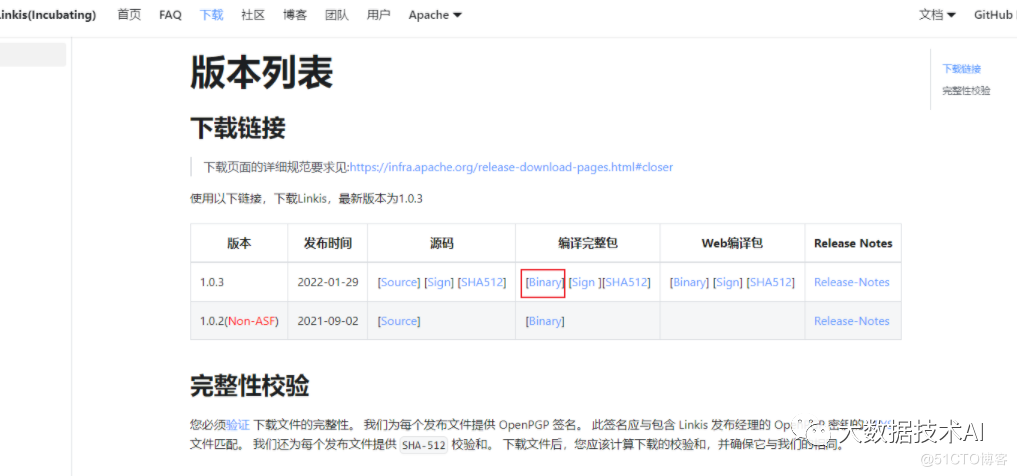
2.3 安装包下载
https://linkis.apache.org/zh-CN/download/main
2.4 不依赖HDFS的基础配置修改
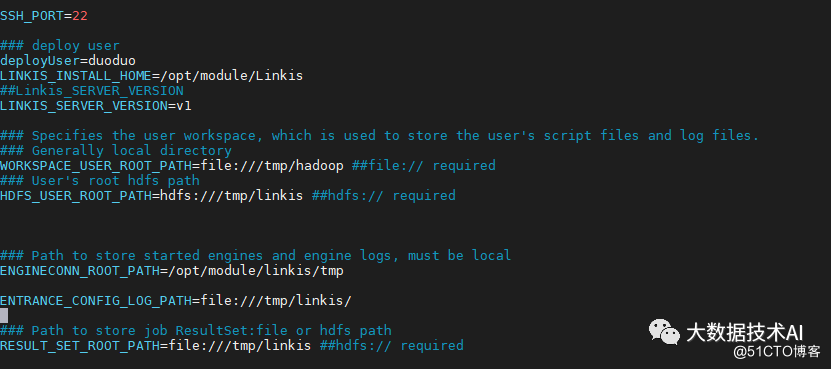
vi deploy-config/linkis-env.sh #SSH_PORT=22 #指定SSH端口,如果单机版本安装可以不配置 deployUser=hadoop #指定部署用户 LINKIS_INSTALL_HOME=/appcom/Install/Linkis # 指定安装目录 WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop # 指定用户根目录,一般用于存储用户的脚本文件和日志文件等,是用户的工作空间。 RESULT_SET_ROOT_PATH=file:///tmp/linkis # 结果集文件路径,用于存储Job的结果集文件 ENGINECONN_ROOT_PATH=/appcom/tmp #存放ECP的安装路径,需要部署用户有写权限的本地目录 ENTRANCE_CONFIG_LOG_PATH=file:///tmp/linkis/ #ENTRANCE的日志路径 ## LDAP配置,默认Linkis只支持部署用户登录,如果需要支持多用户登录可以使用LDAP,需要配置以下参数: #LDAP_URL=ldap://localhost:1389/ #LDAP_BASEDN=dc=webank,dc=com
2.5 修改数据库配置
vi deploy-config/db.sh

2.6 安装
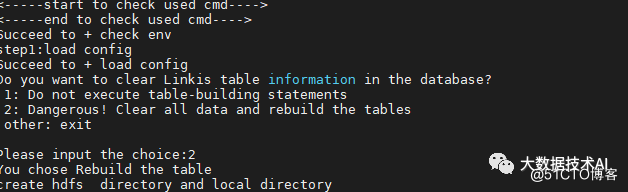
执行安装脚本:sh bin/install.sh
install.sh脚本会询问您是否需要初始化数据库并导入元数据。
因为担心用户重复执行install.sh脚本,把数据库中的用户数据清空,所以在install.sh执行时,会询问用户是否需要初始化数据库并导入元数据。
2.7 检查是否安装成功

2.8 快速启动Linkis
启动服务
sh sbin/linkis-start-all.sh
查看是否启动成功
可以在Eureka界面查看服务启动成功情况,查看方法:
使用http://${EUREKA_INSTALL_IP}:${EUREKA_PORT}, 在浏览器中打开,查看服务是否注册成功。
如果您没有在config.sh指定EUREKA_INSTALL_IP和EUREKA_INSTALL_IP,则HTTP地址为:http://127.0.0.1:20303
默认会启动8个Linkis微服务,其中图下linkis-cg-engineconn服务为运行任务才会启动


2.9 问题集
1、telnet
<-----start to check used cmd----> check command fail need 'telnet' (your linux command not found) Failed to + check env
解决:sudo yum -y install telnet
2、connection exception
mkdir: Call From hadoop01/192.168.88.111 to hadoop01:9820 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused Failed to + create hdfs:///tmp/linkis directory
解决:启动HDFS
到此这篇关于Apache Linkis 中间件架构及快速安装的文章就介绍到这了,更多相关Apache Linkis 中间件内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!