终于又开新专栏啦(其实是填坑),相信很多同学对kafka都有一定的了解了,我们以前在RabbitMQ的选型中,也提到过两者的对比,那么今天我们就正式开始Kafka的学习吧,老规矩,先来一篇手把手安装教程,因为后续主要是用于自身学习,所以还是以windows的安装为例
一、环境与下载
在进行后续步骤前需要保证环境中已经安装并配置了JDK,存在JDK后,再进行kafka的下载,
我们可以通过kafka其官网:https://kafka.apache.org/downloads来进行下载,目前的发布版本为3.5.1,且推荐的Scala版本2.13,那我们此次就用这个版本。
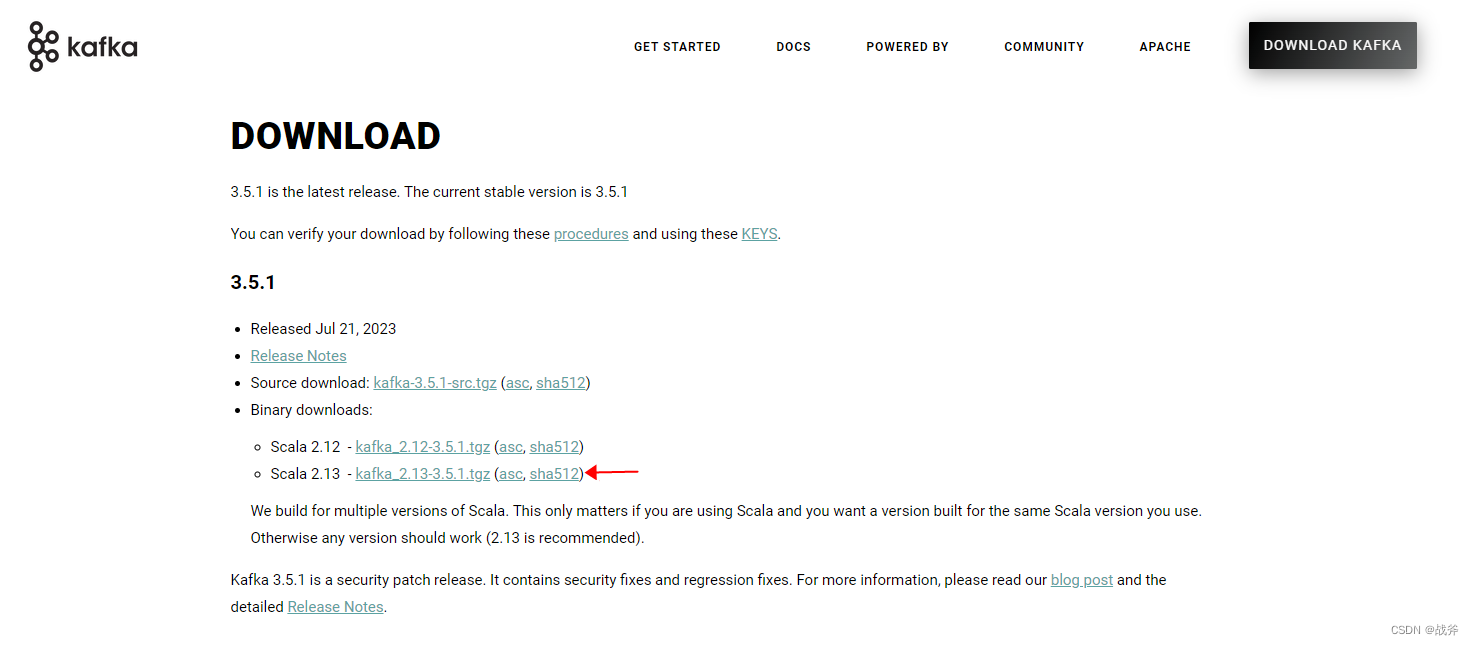
当然,笔者也知道很多小伙伴打不开网页,所以笔者也把这份包给上传上来了(如果没被CSDN下架的话),点此下载
二、安装
解压后请务必将其放在目录较浅的位置,否则在后续执行命令时可能会提示输入行太长,如下,我们不仅将其解压后的文件直接放在E盘根目录,而且缩写了其名字。
此时我们来到它目录下的bin目录,bin目录本级存的是在linux下的运行脚本,其下还有个windows子目录
在该windos目录下,就是windows使用的批处理脚本了
我们都知道 kafka 的运行需要 Zookeeper ,但是不需要我们额外安装,其本身就包含了Zookeeper的服务
三、启动
启动Kafka有两个必要的服务:Zookeeper 和 Kafka 本身。
1. 启动ZK
在Kafka的根目录中,进入config目录。您将看到一个名为zookeeper.properties的文件。
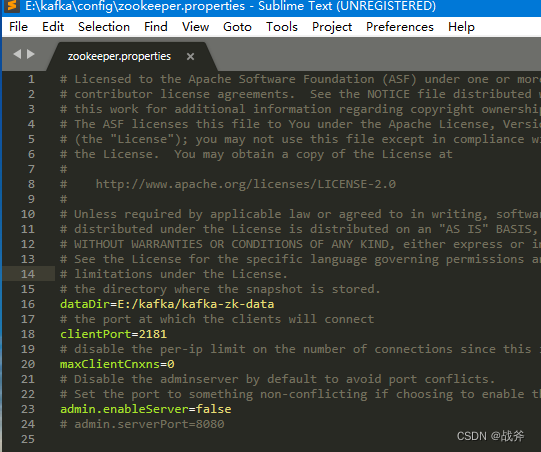
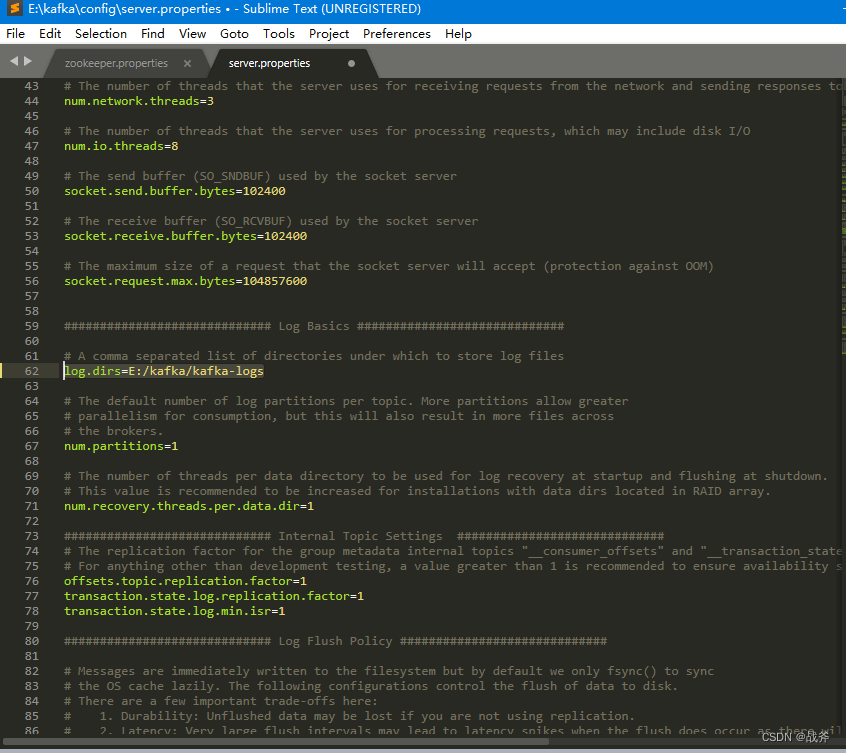
使用文本编辑器打开该文件并更改dataDir的值,即ZK数据的存储位置,例如:
在保存过后,我们回到ZK启动脚本的目录下,并在目录位置输入cmd,回车进入命令行
然后在命令行中输入 以下命令来启动 ZK
zookeeper-server-start.bat ../../config/zookeeper.properties
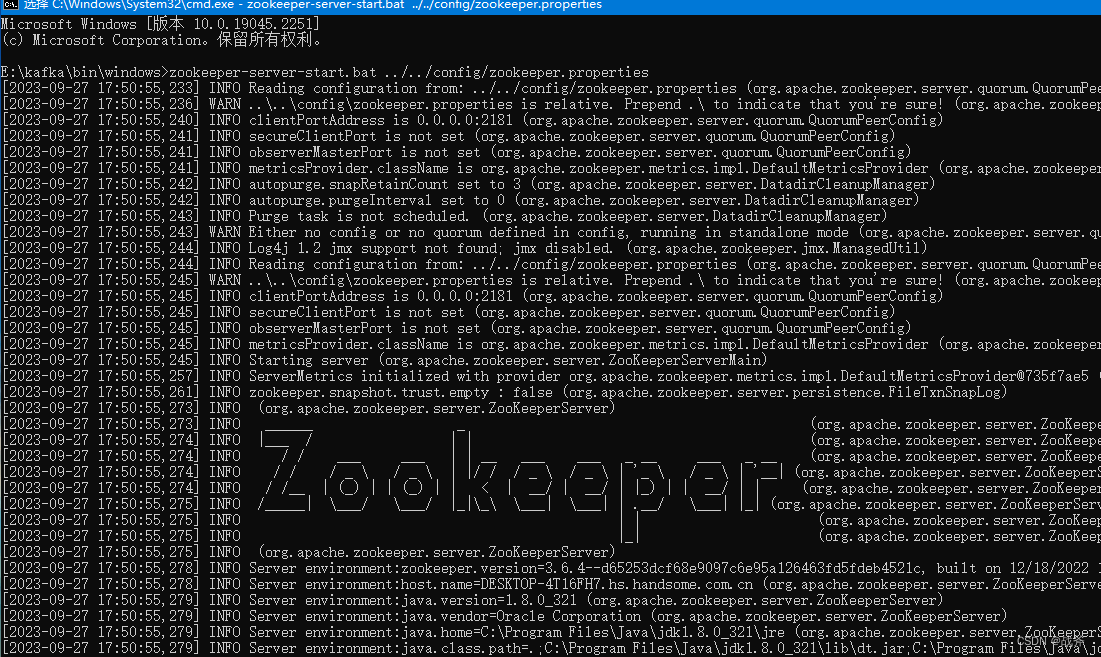
如果没有报错就是启动成功了。
2. 启动Kafka
在Kafka的根目录中,进入config目录,您将看到一个名为server.properties的文件。
使用文本编辑器打开该文件并更改以下参数的值:
broker.id:每台Kafka服务器需要一个唯一的broker.id值。listeners:Kafka默认使用9092端口,可以更改此端口。log.dirs:Kafka默认使用/tmp/kafka-logs作为数据存储目录,可以更改此目录,我们提前创建目录,然后设置该目录为日志目录,如下:
保存并关闭文件后,回到目录E:\kafka\bin\windows,使用以下命令启动Kafka服务器
kafka-server-start.bat ../../config/server.properties
Kafka启动后,您将看到以下输出:
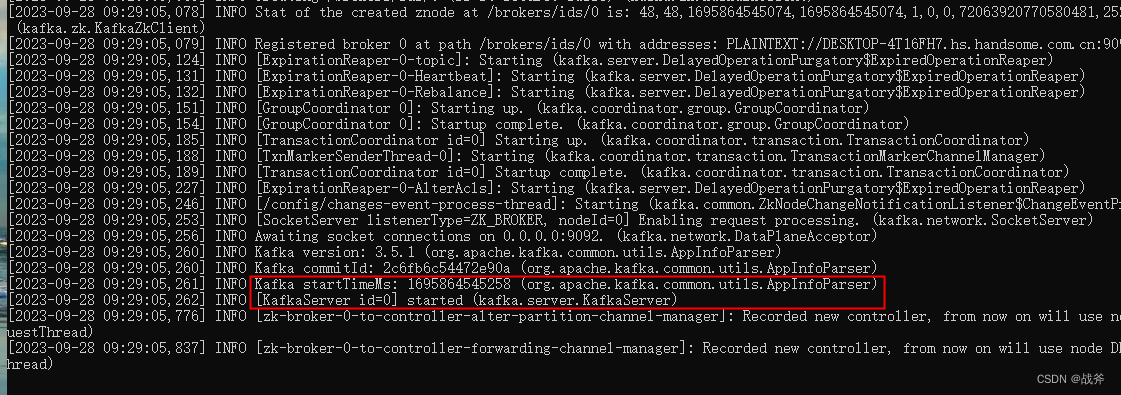
至此,说明kafka的启用就完成了。
四、可视化工具 EFAK(kafka-eagle)
同我们在前面讲解的ZK安装一样,kafka本身也没有提供可视化页面,但是市面上有很多开源的可视化工具,我们接下来就讲讲他们的安装及使用,我们选取其中的 EFAK来说, 请注意,在安装EFAK之前,你至少需要安装了JDK、kafka、mysql的环境后,再进行后续操作。
1. kafka开启JMX
JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架。JMX是一套标准的代理和服务,实际上,用户能够在任何Java应用程序中使用这些代理和服务实现管理。用人话说,就是对外暴露更多数据,方便某些监控之类的插件来使用
我们先要打开刚刚的kafka启动脚本 kafka-server-start.bat,如下:
在脚本中找到一个会执行到的位置,设置JMX的端口,并保存如下:
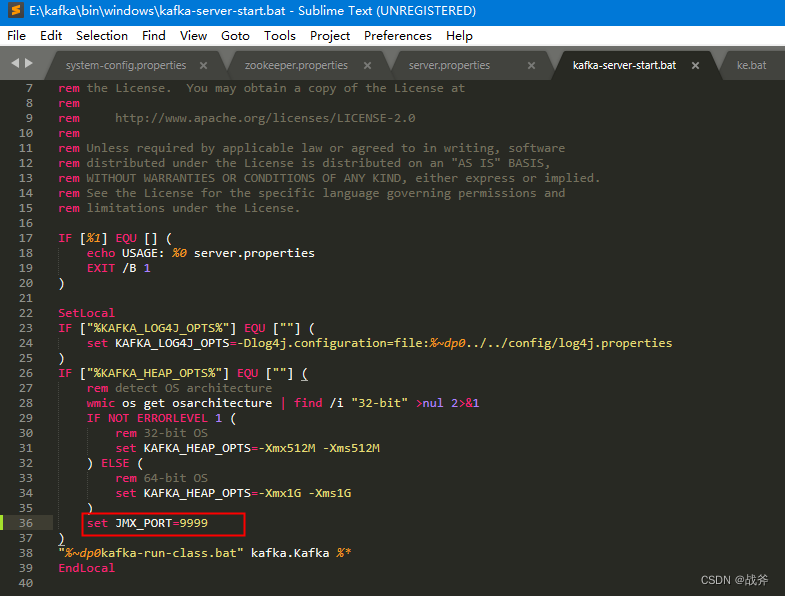
做完该步骤后,记得重启kafka
2. 下载及配置
我们打开它的官网:http://www.kafka-eagle.org/,如下:

直接下载其最新版,或者使用笔者上传的压缩包 http://xiazai.haodaima.com/202311/yuanma/efak-web_haodaima.rar
当我们将其解压缩后,需要注意到,如果使用其默认的启动脚本,我们还需要维护两个环境变量JAVA_HOME、KE_HOME,前者不必多说,后者为EFAK的安装根目录,在本例中为
E:\efak-web-3.0.1\efak-web-3.0.1
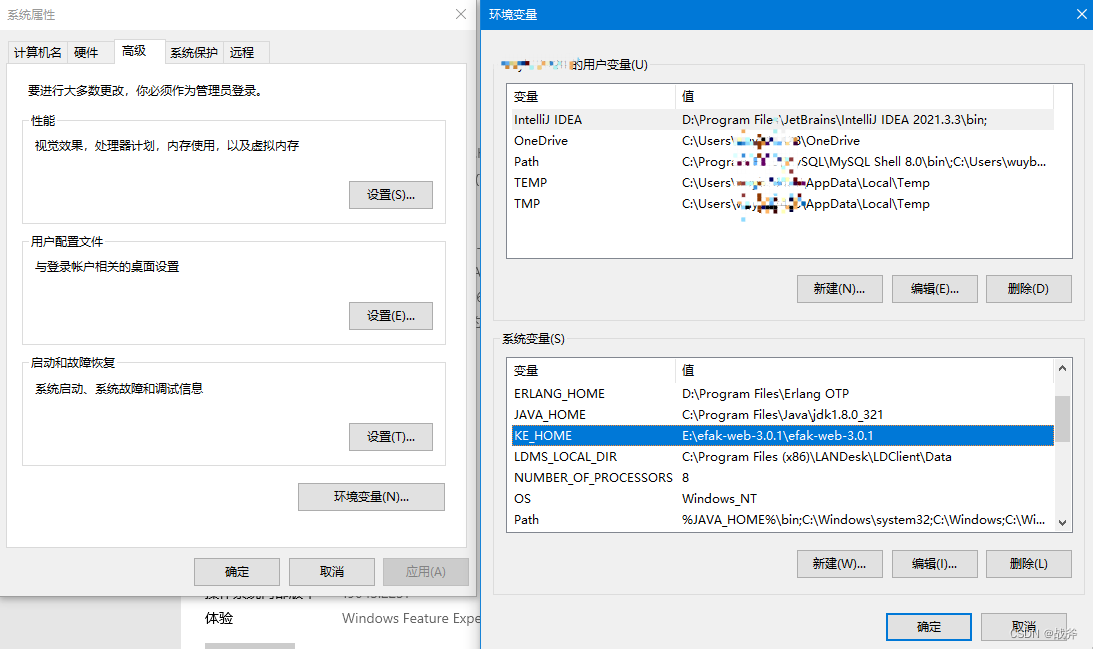
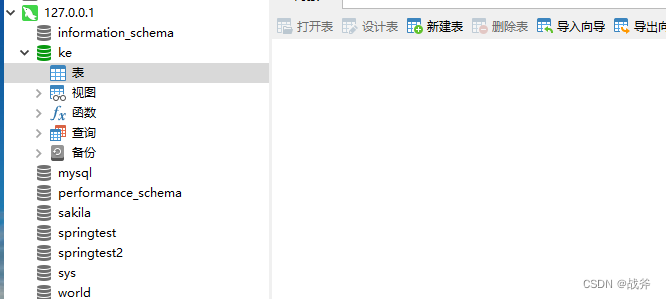
配置好环境变量后,我们还需要在数据库中选一个库,或者是新建一个库,笔者这边是按推荐建立了一个名为ke的库,如下:
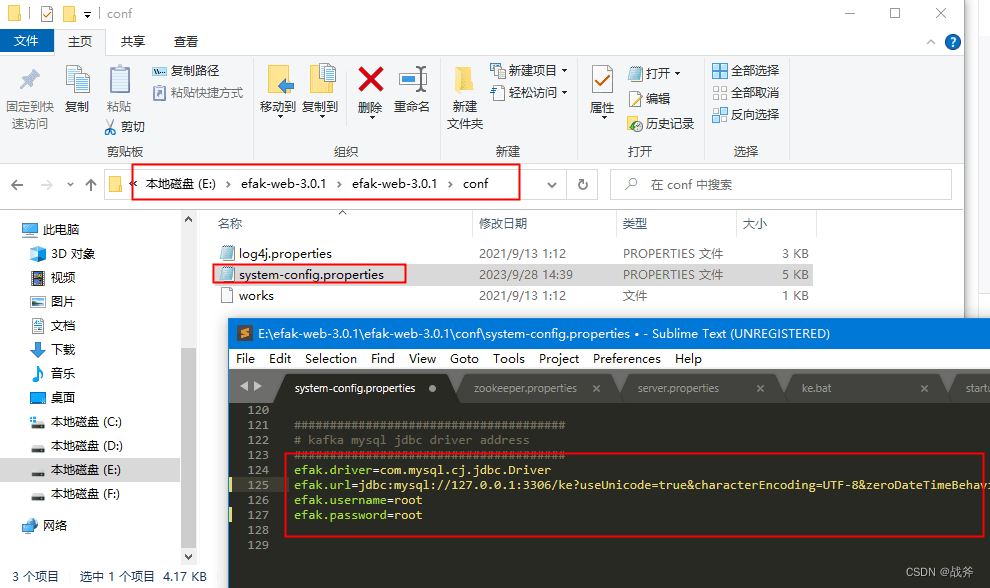
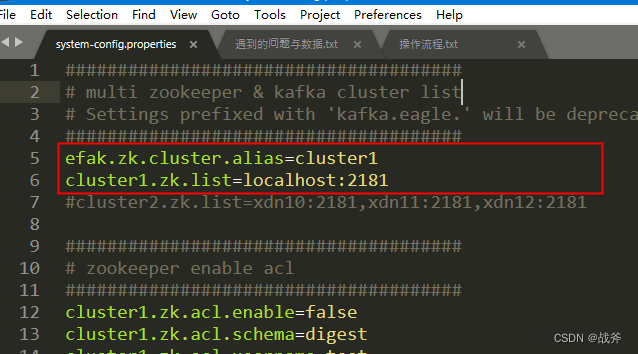
然后在system-config.properties配置文件中连接该库
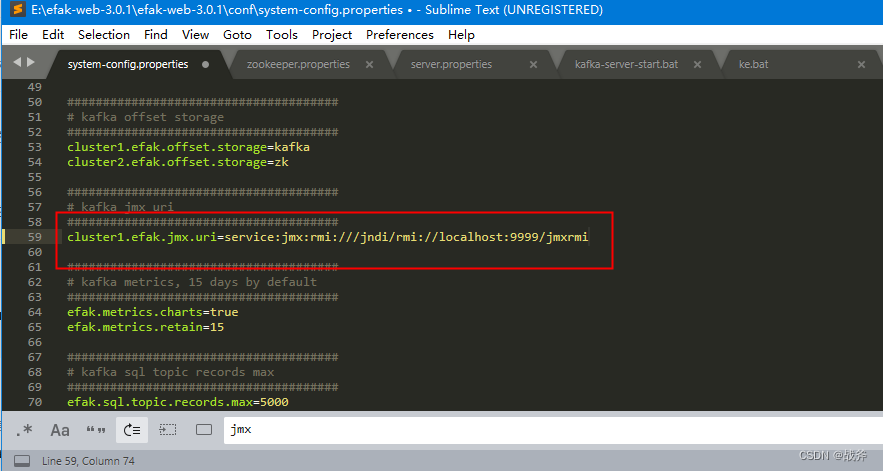
同时别忘记,在该配置文件中还要配置kafka的JMX的地址,不然是拿不到kafka的数据的
最后,修改一下ZK的配置,把我们上面启动的ZK的位置给他填上去,填完注意保存后再关闭
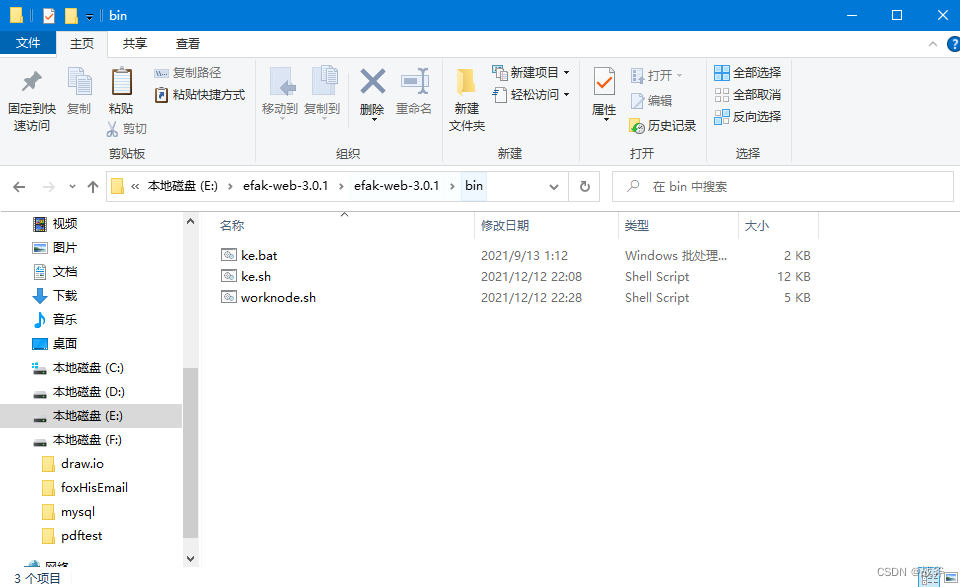
最后进入EFAK的bin目录,运行其 ke.bat 文件进行启动
3. 启动故障及解决
在这一步笔者的电脑出现了几个问题,我们一一来说:
① 错误信息 C:\Program’ is not recognized as an internal or external command
该故障如下图:

经查验,发现是启动脚本中存在
%JAVA_HOME%\bin\jar -xvf %KE_HOME%\kms\webapps\ke.war
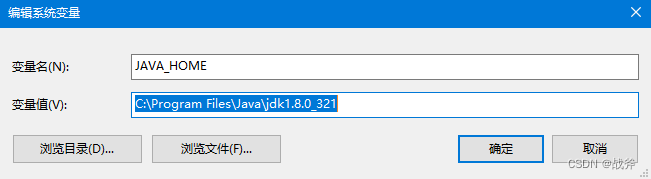
这样的语句,因为笔者的JAVA_HOME设置路径,目录Program Files存在空格,导致执行命令时出现异常,
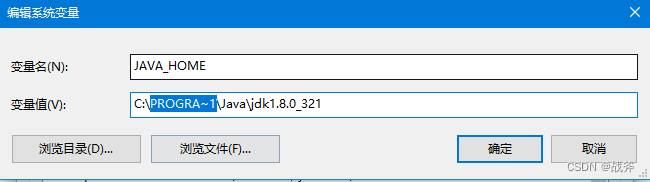
所以可以把JAVA_HOME的路径中的Program Files为改为PROGRA~1,即如下:
② tomcat 启动乱码
运行命令实际上是执行一个war包,并启动一个tomcat,并弹出一个新的命令行窗口,我们在tomcat 的窗口中看见大量的乱码,如下:
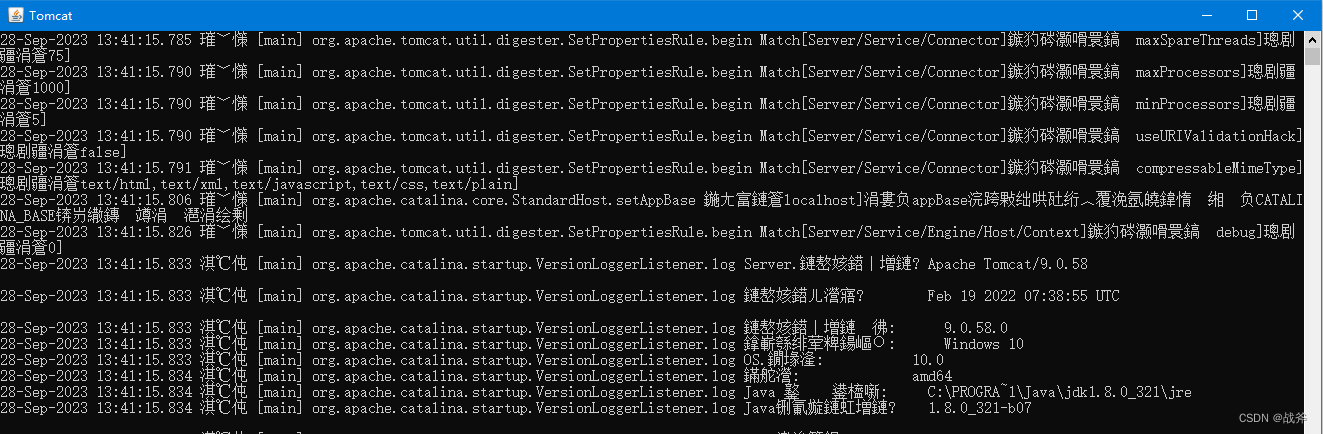
这主要是其内置的日志输出中文,编码为UTF-8,而命令行的编码格式默认为GBK导致的,这个问题有很多方式解决,笔者提供三种思路:
方案一:Tomcat启动时会检查本地语言环境,因为笔者电脑是中文环境,才会输出中文日志。实际上在生产中部署于linux环境时,基本都是英文环境,所以我们可以把运行参数中的语言环境设置为英文即可。
我们打开 catalina 的脚本
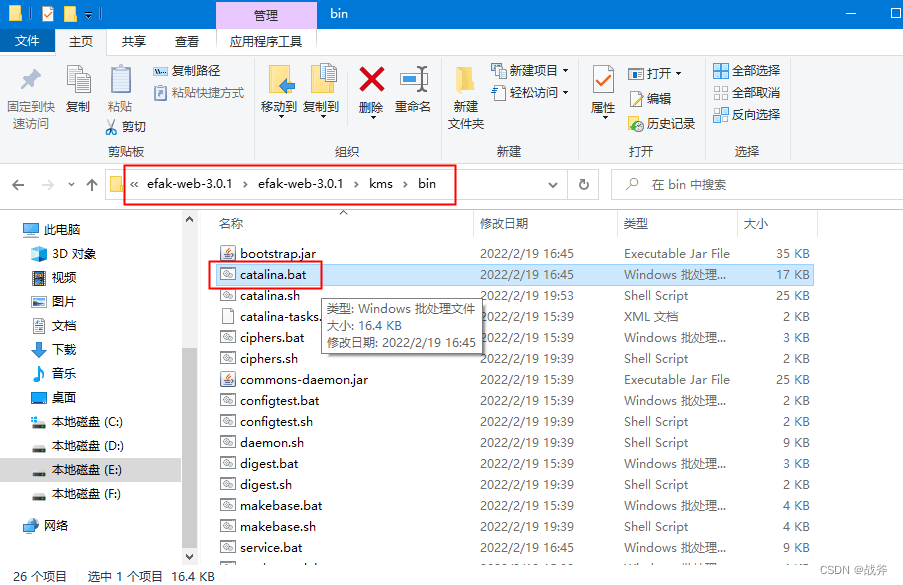
在日志输出的设置上,指定英文输出,如下图,即加上
-Duser.language=en -Duser.region=US
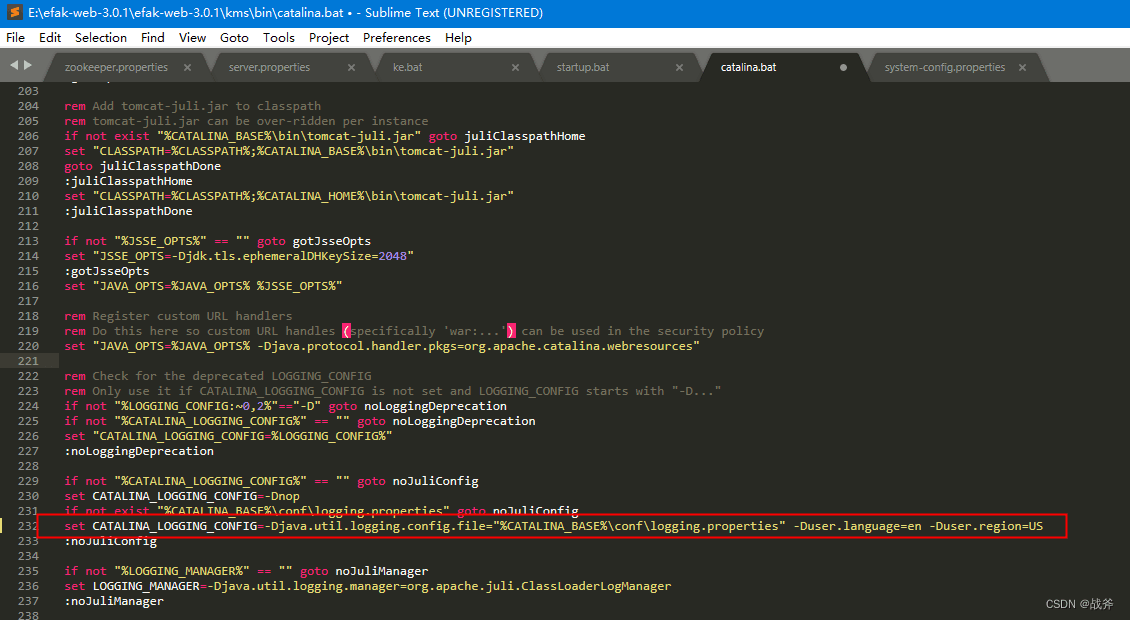
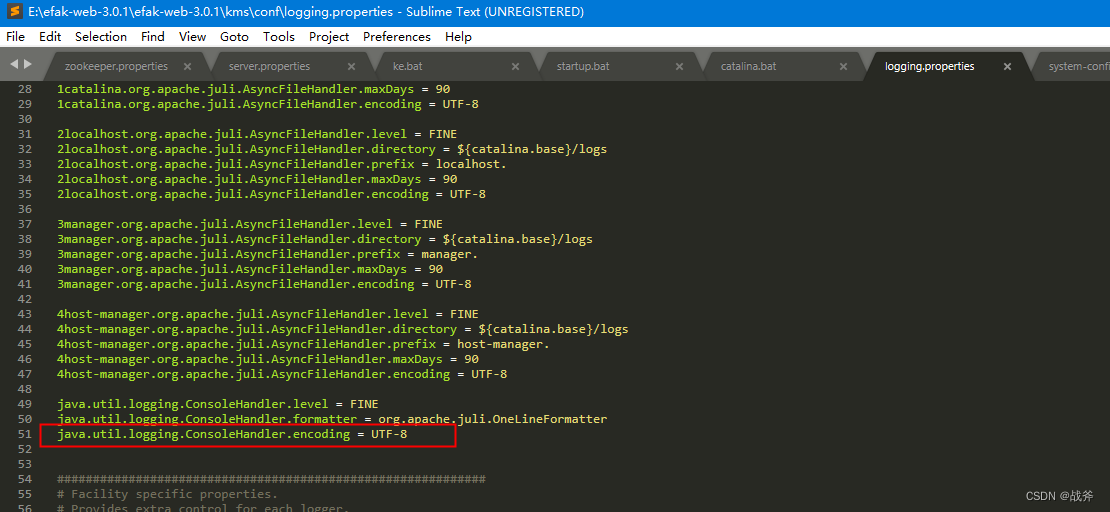
方案二:既然其日志输出编码格式为GBK,那我们就修改tmacat输出日志的编码成GBK,该方案需修改tomcat的日志配置文件,如下:
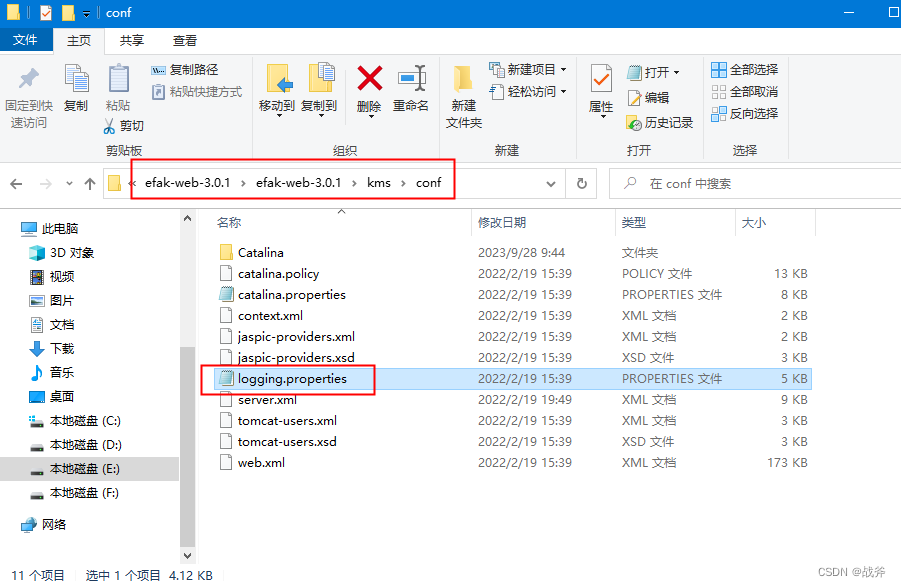
将其控制台输出的编码格式改为GBK
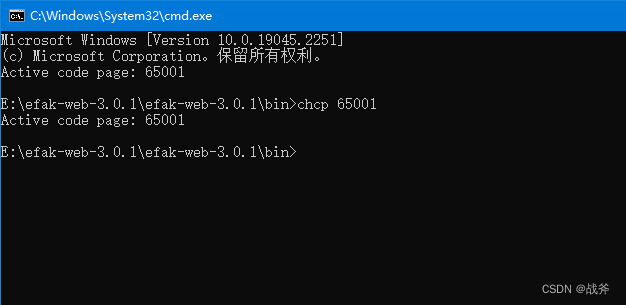
方案三:修改我们控制台的编码,此方案我们可以设置命令提示行的属性来完成,操作如下:
我们先打开命令行,输入 chcp 65001
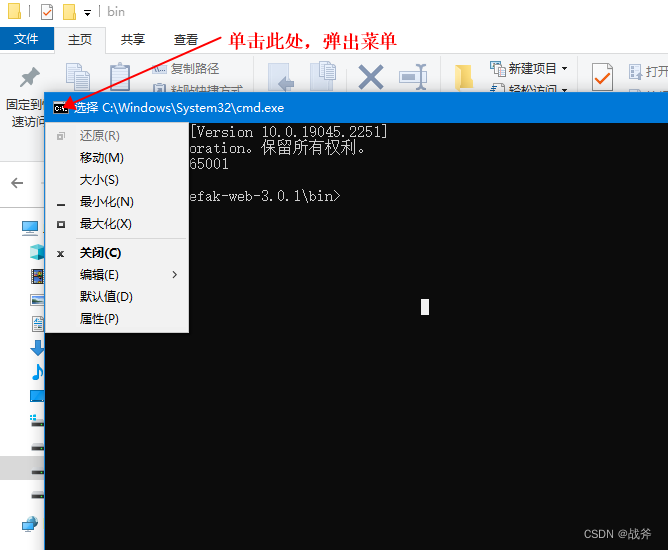
然后单击菜单可以看到菜单
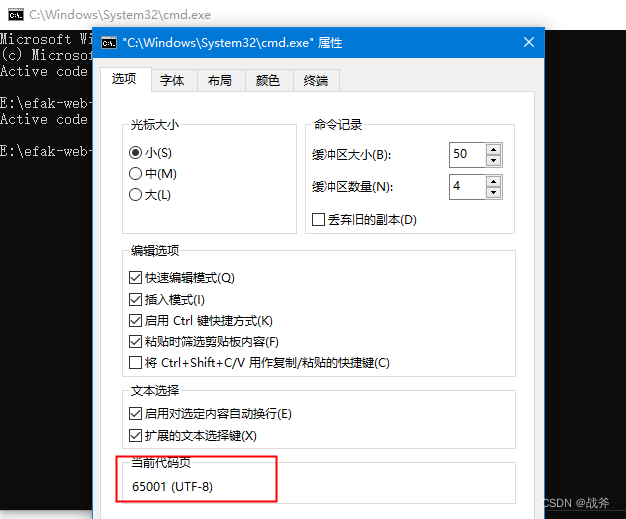
点击属性可观察到它的编码格式
但是这样的设置仅仅是针对当前窗口的,当我们启动tomcat时,它会打开另一个命令窗口,我们可以设法让其不会打开其他窗口,而继续在本窗口输出。我们可以打开启动tomcat 的脚本
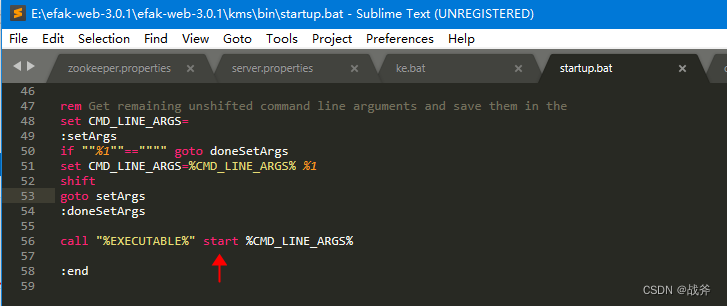
将其执行参数从 start 改为 run ,这样就不会再弹其他窗口了
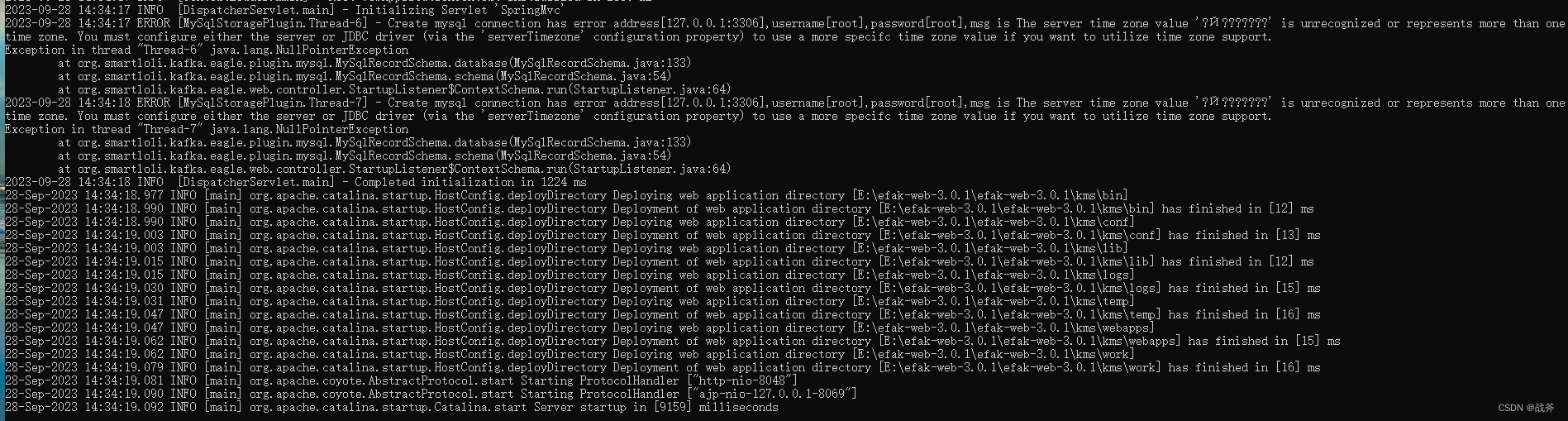
③ mysql 时区值异常
如下图,在启动过程中,连接mysql时在获取时区信息时出现异常,这个其实在高版本mysql上很多人都遇到过,如下图:
我们只需要在mysql 时把时区设置一下就可以,以root 用户设置时区
set global time_zone='+8:00';
④ 表缺失
由于EFAK对数据库的控制不够精细,所以可能会出现建表故障,导致启动后没有建表成功,此时还需要手动建表,其建表脚本我已经上传,可自行点击: 建表脚本下载

3. 启动与登录
在解决完上述各项问题后,我们成功启动了 kafka-eagle。此时可以打开http://127.0.0.1:8048/,看到如下页面:
输入默认的用户名:admin 及密码 123456 即可进入管理页面
总结
在本篇技术博文中,我们详细地教你如何安装kafka,还有它的可视化工具 kafka-eagle,中间也列举了一些异常以及它的处理方式,真正做到了手把手教学。那么安装教学就告一段落。在后面的学习中,我们将讲解他们的使用及运行原理,希望同学们能喜欢
到此这篇关于安装kafka与可视化工具kafka-eagle的文章就介绍到这了,更多相关kafka可视化工具内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!