R语言dplyr包的数据整理、分析函数用法文章连载NO.01
在日常数据处理过程中难免会遇到些难处理的,选取更适合的函数分割、筛选、合并等实在是大快人心!
利用dplyr包中的函数更高效的数据清洗、数据分析,及为后续数据建模创造环境;本篇涉及到的函数为filter、filter_all()、filter_if()、filter_at()、mutate、group_by、select、summarise。
1、数据筛选函数:
#可使用filter()函数筛选/查找特定条件的行或者样本
#filter(.data=,condition_1,condition_2)#将返回相匹配的数据
#同时可以多条件匹配multiple condition,当采用多条件匹配时可直接condition1,condition2或者condition1&condition2
#其他逻辑表达还有:==,>,>=等,&,|,!,xor(),is.na,between,near
#filter延展的相关函数filter_all()、filter_if()、filter_at()
#以iris数据集为例:
filter(.data=iris,Sepal.Length>3,Sepal.Width<3.5) filter(.data=iris,Sepal.Length>3,Species=="virginica")
输出情况: 输出情况:


#要使用filter_all()、filter_if()、filter_at()需要先去掉Species列(非数值型列)
iris_data<-iris%>% select(-Species)
#筛选所有属性小于6的行
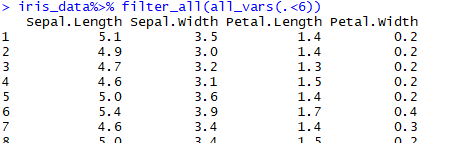
iris_data%>% filter_all(all_vars(.<6))
部分输出情况:
#筛选任意一个属性大于3的行
iris_data%>% filter_all(any_vars(.>3))
#筛选以sep开头的属性任一大于3的行
iris_data%>% filter_at(vars(starts_with("Sep")), any_vars(. >3))
#R中自带数据集mtcars,筛选任意一个属性大于150的行
filter_all(mtcars, any_vars(. > 150))
#筛选以d开头的属性任一可被2整除的行
filter_at(mtcars, vars(starts_with("d")), any_vars((. %% 2) == 0))
2、数据分组、汇总函数group_by、summarise
其他延展函数 group_by_all、group_by_if、group_by_at(将在后续文章中解析)
group_by函数按照某个变量分组,对于数据集本身并不会发生什么变化,只有在与mutate(), arrange() 和 summarise() 函数结合应用的时候会体现出它的优越性,将会对这些 tbl 类数据执行分组操作 (R语言泛型函数的优越性).
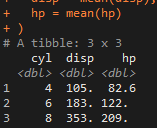
mtcars_cyl <- mtcars %>% group_by(cyl) mtcars_cyl %>% summarise( disp = mean(disp), hp = mean(hp) )
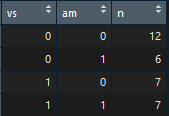
mtcars_vs_am <- mtcars %>% group_by(vs, am) mtcars_vs <- mtcars_vs_am %>% summarise(n = n())
3、新增列函数mutate,在数据集的基础上新增列,不对原数据作更改
可用的相关参数、逻辑:
• +, - 等等
• log()
• lead(), lag()
• dense_rank(), min_rank(), percent_rank(), row_number(), cume_dist(), ntile()
• cumsum(), cummean(), cummin(), cummax(), cumany(), cumall()
• na_if(), coalesce()
• if_else(), recode(), case_when()
相关延展函数:transmute、mutate_all、mutate_if、mutate_at(后期文章分享)
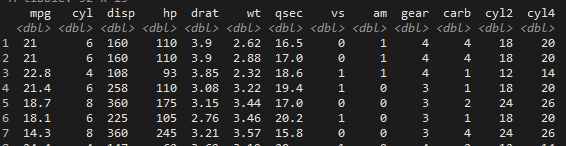
mtcars %>% as_tibble() %>% mutate( cyl2 = cyl*3, cyl4 = cyl2+2 )
到此这篇关于R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解的文章就介绍到这了,更多相关R语言dplyr包数据处理函数内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!