简介
Parquet是一种高效的列式存储格式,广泛用于大数据系统中的数据仓库和数据管理工具中,旨在提高数据分析的性能和效率,能够更好地支持数据压缩和列式查询,同
简介
Parquet是一种高效的列式存储格式,广泛用于大数据系统中的数据仓库和数据管理工具中,旨在提高数据分析的性能和效率,能够更好地支持数据压缩和列式查询,同时兼顾读写速度和数据大小
初衷
为了让 Hadoop 生态系统中的任何项目都能利用压缩、高效的列式数据表示的优势
技术与原理
基于列存储和压缩技术,每一列的数据通过一系列压缩算法进行压缩,然后存储到文件系统中,这种方式能够避免存储冗余数据,并且能够使查询只涉及到所需的列,从而大大提高查询效率
相关术语
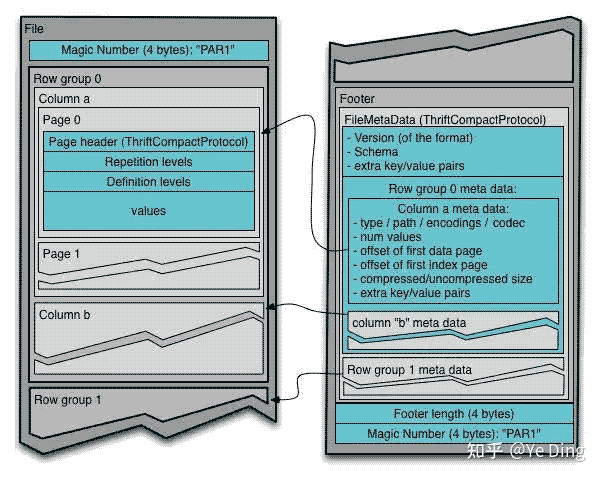
Block(hdfs Block):hdfs中的数据块File:hdfs文件,包含文件的元数据,不需要包含实际的数据Row group/行组:将数据水平划分为Row groupColumn chunk:特定列的数据块,它们位于特定的行组中,并保证在文件中是连续的Page:列块被分为页,页面在概念上是一个不可分割的单元(就压缩和编码而言),列块中可以有多种交错的页面类型,Page为了让数据读取的粒度足够小,便于单条数据或小批量数据的查询
从层次结构上看,文件由一个或多个行组组成,行组的每列恰好包含一个列块,列块包含一页或多页
结构图如下
文件格式如下
4-byte magic number "PAR1" <Column 1 Chunk 1 + Column Metadata> <Column 2 Chunk 1 + Column Metadata> ... <Column N Chunk 1 + Column Metadata> <Column 1 Chunk 2 + Column Metadata> <Column 2 Chunk 2 + Column Metadata> ... <Column N Chunk 2 + Column Metadata> ... <Column 1 Chunk M + Column Metadata> <Column 2 Chunk M + Column Metadata> ... <Column N Chunk M + Column Metadata> File Metadata 4-byte length in bytes of file metadata 4-byte magic number "PAR1"
Header
Header的内容很少,只有4个字节,本质是一个magic number,用来指示文件类型
PAR1:普通的Parquet文件
PARE: 加密过的Parquet文件
File Body
实际存储数据,包含Column Chunk和Column Metadata
Footer
- 包含了诸如
schema,Block的offset和size,Column Chunk的offset和size等所有重要的元数据 - 承担了整个文件入口的职责,读取
Parquet文件的第一步就是读取Footer信息,转换成元数据之后,再根据这些元数据跳转到对应的block和column,读取真正所要的数据
Index
Index是Parquet文件的索引块,主要为了支持谓词下推(Predicate Pushdown)功能
谓词下推是一种优化查询性能的技术,简单地来说就是把查询条件发给存储层,让存储层可以做初步的过滤,把肯定不满足查询条件的数据排除掉,从而减少数据的读取和传输量
Parquet索引类型
Max-Min:Max-Min索引是对每个Page都记录它所含数据的最大值和最小值,这样某个Page是否不满足查询条件就可以通过这个Page的max和min值来判断BloomFilter索引: 针对value比较稀疏,max-min范围比较大的列,用Max-Min索引的效果就不太好,BloomFilter可以克服这一点,同时也可以用于单条数据的查询
rust读写Parquet文件
依赖项目
https://github.com/apache/arrow-r
修改Cargo.toml如下
[dependencies] parquet = "46.0.0" parquet_derive = "46.0.0"
修改main.rs
use std::convert::TryFrom;
use std::{fs, path::Path};
use parquet::file::reader::SerializedFileReader;
use parquet::file::writer::SerializedFileWriter;
use parquet::record::RecordWriter;
use parquet_derive::ParquetRecordWriter;
const PARQUET_FILEPATH: &str = "./target/sample.parquet";
#[derive(ParquetRecordWriter)]
struct ACompleteRecord<'a> {
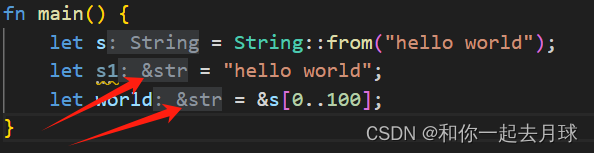
pub a_bool: bool,
pub a_str: &'a str,
}
fn write() {
let path = Path::new(PARQUET_FILEPATH);
let file = fs::File::create(path).unwrap();
let samples = vec![
ACompleteRecord {
a_bool: true,
a_str: "I'm true",
},
ACompleteRecord {
a_bool: false,
a_str: "I'm false",
},
];
let schema = samples.as_slice().schema().unwrap();
let mut writer = SerializedFileWriter::new(file, schema, Default::default()).unwrap();
let mut row_group = writer.next_row_group().unwrap();
samples
.as_slice()
.write_to_row_group(&mut row_group)
.unwrap();
row_group.close().unwrap();
writer.close().unwrap();
}
fn read() {
let rows = [PARQUET_FILEPATH]
.iter()
.map(|p| SerializedFileReader::try_from(*p).unwrap())
.flat_map(|r| r.into_iter());
for row in rows {
println!("{}", row.unwrap());
}
}
fn main() {
write();
read();
}运行
$ cargo run
Compiling temp v0.1.0 (/home/gong/rust-work/temp)
Finished dev [unoptimized + debuginfo] target(s) in 2.26s
Running `target/debug/temp`
{a_bool: true, a_str: "I'm true"}
{a_bool: false, a_str: "I'm false"}查看parquet文件
$ cat target/sample.parquet
PAR1,X%a_bool44<X22I'm true I'm false,I'm true I'm false
5a_str��&�&�I'm true I'm false I'm falsI'm tru4�V<H
rust_schema%a_bool
%a_str%L,&<%a_bool44<X��"&�
5a_str��&�&�I'm true I'm false��@��(parquet-rs version 46.0.0�PAR1%阅读参考
以上就是Apache Arrow Parquet存储与使用的详细内容,更多关于Apache Arrow Parquet存储的资料请关注好代码网其它相关文章!