前言
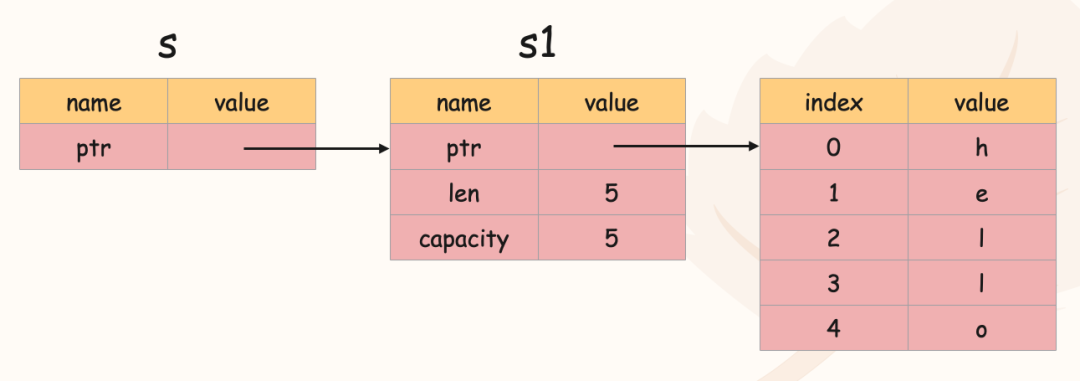
Rust 中有两种字符串,String 和 &str,其中 String 可动态分配、修改,内部实现可以理解为 Vec<u8>,而 &str 是一个类型为 &[u8] 的切片。这两种字符串都只能保存合法的 UTF-8 字符。
而对于非肉眼可辨识的 UTF-8 字符,则可以考虑使用如下类型:
- 文件路径有专用的 Path 和 PathBuf 类可用。
- 使用 Vec<u8> 和 &[u8]
- 使用 OSString 和 &OSStr 和操作系统交互
- 使用 CString 和 &CStr 和 C 库交互
上面的第二种方法,就是常用的处理非 UTF-8 字节流的方式,也就是使用 Vec<u8> 和 &[u8] ,其中我们也可以使用字面值来处理这两种类型的数据,我们称之为字节字符串字面值(byte string literals),其类型为 &[u8]。
字符串字面值(String literals)
先来看一下字符串字面值。
和其他语言一样,用双引号括起来就是一个字符串,不过 Rust 的一个特点是字符串可以跨行,即中间有回车也不会引起编译或运行错误,在输出的时候也会带着里面的换行符。
同样,字符串字面值里面支持转义,比如想在里面使用双引号,该转义也会对换行符进行转义,比如下面这样,在换行符前面使用 \ ,则该转义符、换行符以及下一行开头的所有空格都将会被忽略:
let a = "foobar"; let b = "foo\ bar"; assert_eq!(a,b);
字符串字面值除了支持常见的 \ 对字节(字符)进行转义,还支持对 Unicode 进行转义:
- \xHH: + 2位的十六进制7位宽度字节码,这相当于等值的 ASCII 字符。
- \u{xxxx}:24位长的16进制,表示等值的 Unicode 字符。
- \n/\r/\t 表示 U+000A (LF), U+000D (CR) 和 U+0009 (HT)
- \\ 用来对 \ 本身进行转义
- \0 表示 Unicode U+0000 (NUL)
Raw 类型的字符串字面值表示进行转义,也就是说字面值写的是什么内容,字符串的值就是什么。这种类型的字面值使用 r 以及若干 # 开头进行定义,结尾需要相等数量的 #。
如下所示:
"foo"; r"foo"; // foo "\"foo\""; r#""foo""#; // "foo" "foo #\"# bar"; r##"foo #"# bar"##; // foo #"# bar "\x52"; "R"; r"R"; // R "\\x52"; r"\x52"; // \x52
如果字符串中有双引号怎么办?因为 raw string 里不能使用转义,所以 \" 是肯定不行的。Rust 实际支持使用 r# 的方式来指定字符串边界。这个 # 就是转义的另一种实现方式,比如字符串里面有 4 个 #,那么该字符串可以用 r#####"abc####def"##### 来包围起来,也就是比里面的 # 多即可。
Byte string literals
Byte string 字面值使用 b"..." 以及衍生语法定义,其类型为 &[u8],这个和 &str 是完全不一样的类型,所以有些在 &str 上能用的方法,在 &[u8] 上是用不了的。
比如:
// &[u8; 5]: [119, 111, 114, 108, 100]!
let world = b"world";
println!("Hello, {}!", world);
编译会报错,因为 &[u8] 没有实现 std::fmt::Display:
29 | println!("Hello, {}!", world);
| ^^^^^ `[u8; 5]` cannot be formatted with the default formatter
|= help: the trait `std::fmt::Display` is not implemented for `[u8; 5]`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
Byte string 字面值也支持转义,但是需要注意它只支持字节转义,不支持 Unicode 转义。
// 支持字符转义,输出:Hello, Rust!
let escaped = b"\x52\x75\x73\x74 as bytes";
// 不支持 Unicode 转义,编译错误:
// = help: unicode escape sequences cannot be used as a byte or in a byte string
let escaped = b"\u{211D} is not allowed";// Raw byte strings work just like raw strings
let raw_bytestring = br"\u{211D} is not escaped here";
println!("{:?}", raw_bytestring);
// Converting a byte array to `str` can fail
if let Ok(my_str) = str::from_utf8(raw_bytestring) {
println!("And the same as text: '{}'", my_str);
}字节字符串也支持 raw 定义,和标准字符串类型类似,使用 r 前缀定义 raw byte string 字面值变量。
例如下面的例子中普通的字节字符串需要转义,raw 字节字符串就不需要使用 \ 进行转义了。
b"foo"; br"foo"; // foo b"\"foo\""; br#""foo""#; // "foo" b"foo #\"# bar"; br##"foo #"# bar"##; // foo #"# bar b"\x52"; b"R"; br"R"; // R b"\\x52"; br"\x52"; // \x52
总结
下面是刚才介绍的这几种字符串字面值定义的一个总结,列出了不同的定义方式和其含义。
符合 意义
“…” 字符串字面值
r"…“, r#”…“#, r##”…“##, etc. Raw 字符串字面值,禁止转义
b"…“ 字节字符串字面值,类型为 &[u8]
br"…“, br#”…“#, br##”…“##, etc. Raw 字节字符串字面值
‘…’ 字符字面值
b'…‘ ASCII字节字面值
参考资料
到此这篇关于Rust字符串字面值的文章就介绍到这了,更多相关Rust字符串字面值内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!