楔子
所有的编程语言都致力于将重复的任务简单化,并为此提供各种各样的工具。在 Rust 中,泛型(generics)就是这样一种工具,它是具体类型或其它属性的抽象替代。在编写代码时,我们可以直接描述泛型的行为,以及与其它泛型产生的联系,而无须知晓它在编译和运行代码时采用的具体类型。
总结一下泛型就是,提高代码的复用能力,处理重复代码。泛型是具体类型或者其它属性的抽象代替,编写的泛型代码不是最终的代码,而是一些模板,里面有一些占位符,编译器在编译的时候会将占位符替换为具体的类型。
函数中的泛型
函数中定义泛型的时候,我们需要将泛型定义在函数的签名中:
// 这种定义方式是错误的,因为 T 不在作用域中
// 我们要将其放在签名里面
fn func(arg: T) -> T {
arg
}
// 这样做是正确的
fn func<T>(arg: T) -> T {
arg
}里面的 T 就是一个泛型,它可以代表任意的类型,然后在编译的时候会将其替换成具体的类型,这个过程叫做单态化。
另外这个 T 就是一个占位符,你换成别的也可以,只是我们一般写作 T。
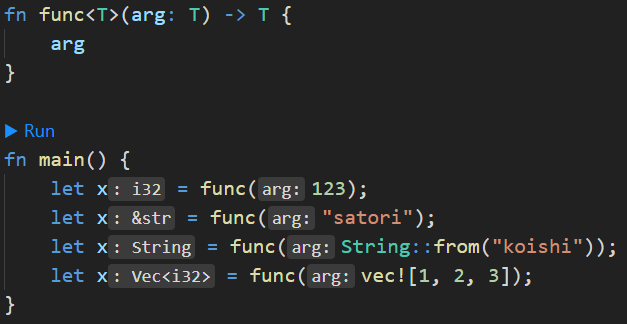
这里我们连续声明了多个变量 x,这在 Rust 里面是没有问题的,因为 Rust 有一个变量隐藏机制。然后再来看一下变量 x 的类型,虽然泛型 T 可以代表任意类型,但 Rust 在编译的时候会执行单态化,确定泛型的具体类型。
比如传一个 123,那么 T 就会被标记为 i32,因此返回的也是 i32,至于其它类型同理。还是那句话,T 只是一个占位符,至于它到底代表什么类型,取决于我们调用时传递的值是什么类型。
比如传递一个 &str,那么函数就会被 Rust 替换成如下:
fn func(arg: &str) -> &str {
arg
}以上过程被称为单态化,Rust 在编译期间会将泛型 T 替换成具体的类型。因此如果想使用泛型,那么函数签名中的泛型一定要出现在函数参数中,然后根据调用方传递的值的类型,来确定泛型。
总结一下:泛型一定要在函数的签名中,也就是在函数后面通过 <> 进行指定,否则的话泛型是无法使用的。此外,泛型还要出现在参数中,这是毫无疑问的,不然定义泛型干啥。
当然啦,泛型不止可以定义一个,定义任意个都是可以的。
// 如果有多个泛型,那么在 <> 里面通过逗号分隔
// 然后要保证函数签名 <> 里面声明的泛型,
// 都要在函数参数中出现,也就是要将定义的泛型全用上
fn func<A, B, C>(
arg1: A, arg2: B, arg3: C
) -> (C, A) {
(arg3, arg1)
}
fn main() {
// 函数 func 定义了三个泛型,然后返回的类型是 (C, A)
// 这里传递三个参数,显然当调用时,Rust 会确定泛型代表的类型
// A 是 i32,B 是 f64,C 是 &str
let x = func(123, 3.14, "你好");
// 泛型可以接收任何类型,那么当调用时
// A 是 Vec<i32>,B 是 [i32;2],C 是 (i32, i32)
let y = func(vec![1, 2], [1, 2], (3, 4));
}这里我们定义了三个泛型,然后返回的类型是 (C, A)。而 Rust 会根据参数的类型,来确定泛型,所以变量 x 是 (&str, i32) 类型,变量 y 是 ((i32, i32), Vec<i32>) 类型。

事实上 IDE 也已经推断出来了,总的来说泛型应该不难理解。
结构体中的泛型
如果一个结构体成员的类型不确定,那么也可以定义为泛型。
struct Point<T> {
x: T,
y: T
}和函数一样,泛型一定要写在 <> 当中作为签名出现,然后才可以使用,相当于告诉 Rust 都定义了哪些泛型。然后签名中的泛型,一定要全部使用,会根据函数调用时给参数传的值、或者实例化结构体时给成员传的值,来确定泛型代表哪一种类型。
如果签名中的泛型没有全部使用,那么 Rust 就无法执行单态化,于是报错。所以泛型一定要全部使用,再说了,不使用的话,定义它干嘛。
struct Point<T> {
x: T,
y: T
}
fn main() {
let p1 = Point{x: 11, y: 22};
let p2 = Point{x: 11.1, y: 22.2};
}T 只是一个占位符,具体什么类型要由我们传递的内容决定,可以是 i32,可以是 f64。但由于成员 x 和 y 的类型都是 T,所以它们的类型一定是一样的,要是 i32 则都是 i32,要是 f64 则都是 f64。
如果希望类型不同,那么只需要两个泛型即可。
struct Point<T, U> {
x: T,
y: U
}
fn main() {
// x 和 y 的类型可以相同,也可以不同
// 因为它们都可以接收任意类型
let p1 = Point{x: 11, y: 22};
let p2 = Point{x: 11.1, y: 22.2};
let p3 = Point{x: "11.1", y: String::from("satori")};
let p3 = Point{x: vec![1, 2, 3], y: (1, 2, 3)};
}还是那句话,泛型可以接收任意类型,想传啥都行,具体根据我们传递的值来确定。
枚举中的泛型
枚举也是支持泛型的,比如之前使用的 Option<T> 就是一种泛型,它的结构如下:
enum Option<T> {
Some(T),
None
}里面的 T 可以代表任意类型,然后我们再来自定义一个枚举。
// 签名中的泛型参数必须都要使用
// 比如函数签名的泛型,要全部体现在参数中
// 枚举和结构体签名的泛型,要全部体现在成员中
enum MyOption<A, B, C> {
// 这里 A、B、C 都是我们随便定义的,可以代指任意类型
// 具体是哪种类型,则看我们传递了什么
Some1(A),
Some2(B),
Some3(C),
}
fn main() {
// 泛型不影响效率,是因为 Rust 要进行单态化
// 所以泛型究竟代表哪一种类型要提前确定好
// 这里必须要显式指定 x 的类型。枚举和结构体不同
// 结构体每个成员都要赋值,所以 Rust 能够基于赋的值推断出所有的泛型
// 但枚举的话,每次只会用到里面的一个成员
// 如果还有其它泛型,那么 Rust 就无法推断了
// 比如这里只能推断出泛型 C 代表的类型,而 A 和 B 就无法推断了
// 因此每个泛型代表什么类型,需要我们手动指定好
let x: MyOption<i32, f64, u8> = MyOption::Some3(123);
match x {
MyOption::Some1(v) => println!("我是 i32"),
MyOption::Some2(v) => println!("我是 f64"),
MyOption::Some3(v) => println!("我是 u8"),
}
// 泛型可以代表任意类型,指定啥都是可以的
let y: MyOption<u8, i32, String> =
MyOption::Some3(String::from("xxx"));
match y {
MyOption::Some1(v) => println!("我是 u8"),
MyOption::Some2(v) => println!("我是 i32"),
MyOption::Some3(v) => println!("我是 String"),
}
/*
我是 u8
我是 String
*/
}如果觉得上面的例子不好理解的话,那么再举个简单的例子:
enum MyOption<T> {
MySome1(T),
MySome2(i32),
MySome3(T),
MyNone
}
fn main() {
// 这里我们没有指定 x 的类型
// 这是因为 MyOption 只有一个泛型
// 通过给 MySome1 传递的值,可以推断出 T 的类型
let x = MyOption::MySome1(123);
// 同样的道理,Rust 可以自动推断,得出 T 是 &str
let x = MyOption::MySome3("123");
// 但此处就无法自动推断了,因为赋值的是 MySome2 成员
// 此时 Rust 获取不到任何有关 T 的信息,无法执行推断
// 因此我们需要手动指定类型,但仔细观察一下声明
// 首先,如果没有泛型的话,那么直接 let x: MyOption = ... 即可
// 但里面有泛型,所以此时除了类型之外,还要连同泛型一起指定
// 也就是 MyOption<f64>
let x: MyOption<f64> = MyOption::MySome2(123);
// 当然泛型可以代表任意类型,此时的 T 则是一个 Vec<i32> 类型
let x: MyOption<Vec<i32>> = MyOption::MySome2(123);
}所以一定要注意:在声明变量的时候,如果 Rust 不能根据我们赋的值推断出泛型代表的类型,那么我们必须要手动声明类型,来告诉 Rust 泛型的相关信息,这样才可以执行单态化。
对于结构体也是同样的道理:
struct Girl1 {
field: i32,
}
struct Girl2<T> {
field: T,
}
fn main() {
// 下面两个语句类似,只是第二次声明 g1 的时候多指定了类型
let g1 = Girl1 { field: 123 };
let g1: Girl1 = Girl1 { field: 123 };
// 下面两条语句也是类似的,第二次声明 g2 的时候多指定了类型
// 但此时的类型有些不一样,Girl2 的结尾多了一个 <i32>
// 原因很简单,因为 Girl2 里面有泛型
// 所以在显式指定类型的时候,还要将泛型代表的类型一块指定,否则报错
let g2 = Girl2 { field: 123 };
let g2: Girl2<i32> = Girl2 { field: 123 };
}然后还有一点比较重要,就是在声明的时候,只需在 <> 里面指定泛型即可,什么意思呢?举个例子:
struct Girl<E, T, W> {
field1: String,
field2: T,
field3: W,
field4: E,
field5: i32,
}
fn main() {
// 这里可以不指定类型,因为 Rust 可以推断出来
// 不过这里我们就显式指定。而虽然 Girl 有 5 个成员
// 但泛型的数量是三个,因此声明变量的时候也要指定三个
// 由于定义结构体的时候,泛型顺序是 E T W
// 所以这里的 f64 就是 E,u8 就是 T,Vec<i32> 就是 W
let g: Girl<f64, u8, Vec<i32>> = Girl {
field1: String::from("hello"),
field2: 123u8,
field3: vec![1, 2, 3],
field4: 3.14,
field5: 666,
};
}以上就是在枚举中使用泛型,并且针对泛型的用法稍微多啰嗦了一些。
方法中的泛型
我们也可以对方法实现泛型,举个例子:
struct Point<T, U> {
x: T,
y: U
}
// 针对 i32、f64 实现的方法
// 只有传递的 T、U 对应 i32、f64 才可以调用
impl Point<i32, f64> {
fn m1(&self) {
println!("我是 m1 方法")
}
}
fn main() {
let p1 = Point{x: 123, y: 3.14};
p1.m1(); // 我是 m1 方法
let p2 = Point{x: 3.14, y: 123};
//p2.m1();
//调用失败,因为 T 和 U 不是 i32、f64,而是 f64、i32
//所以 p2 无法调用 m1 方法
}可能有人好奇了,声明方法的时候不考虑泛型可不可以,也就是 impl Point {}。答案是不可以,如果结构体中有泛型,那么声明方法的时候必须指定。但这就产生了一个问题,那就是只有指定类型的结构体才能调用方法。
比如上述代码,只有当 x 和 y 分别为 i32、f64 时,才可以调用方法,如果我希望所有的结构体实例都可以调用呢?
struct Point<T, U> {
x: T,
y: U
}
// 针对 K、f64 实现的方法,由于 K 是一个泛型
// 所以它可以代表任何类型(泛型只是一个符号)
// 因此不管 T 最终是什么类型,i32 也好、&str 也罢
// K 都可以接收,只要 U 是 f64 即可
// 然后注意:如果声明方法时结构体后面指定了泛型
// 那么必须将使用的泛型在 impl 后面声明
impl <K> Point<K, f64> {
fn m1(&self) {
println!("我是 m1 方法")
}
}
// 此时 K 和 S 都是泛型,那么此时对结构体就没有要求了
// 因为不管 T 和 W 代表什么,K 和 S 都能表示,因为它们都是泛型
impl <K, S> Point<K, S> {
fn m2(&self) {
println!("我是 m2 方法")
}
}
// 这里我们没有使用泛型,所以也就无需在 impl 后面声明
// 但很明显,此时结构体实例如果想调用 m3 方法
// 那么必须满足 T 是 u8,W 是 f64
impl Point<u8, f64> {
fn m3(&self) {
println!("我是 m3 方法")
}
}
fn main() {
// 显然 p1 可以同时调用 m1 和 m2 方法,但 m3 不行
// 因为 m3 要求 T 是一个 u8,而当前是 &str
let p1 = Point{x: "hello", y: 3.14};
p1.m1(); // 我是 m1 方法
p1.m2(); // 我是 m2 方法
// 显然 p2 可以同时调用 m1、m2、m3
// 另外这里的 x 可以直接写成 123,无需在结尾加上 u8
// 因为 Rust 看到我们调用了 m3 方法,会自动推断为 u8
let p2 = Point{x: 123u8, y: 3.14};
p2.m1(); // 我是 m1 方法
p2.m2(); // 我是 m2 方法
p2.m3(); // 我是 m3 方法
// 显然 p3 只能调用 m2 方法,因为 m2 对 T 和 W 没有要求
// 但是像 m3 就不能调用,因为它是为 <u8, f64> 实现的方法
// 只有当 T、W 为 u8、f64 时才可以调用
// 显然此时是不满足的,因为都是 &str,至于 m1 方法也是同理
// 所以 p3 只能调用 m2,这个方法是为 <K, S> 实现的
// 而 K 和 S 也是泛型,可以代表任意类型,因此没问题
let p3 = Point{x: "3.14", y: "123"};
p3.m2(); // 我是 m2 方法
}然后注意:我们上面的泛型本质上针对的还是结构体,而我们定义方法的时候也可以指定泛型,其语法和在函数中定义泛型是一样的。
#[derive(Debug)]
struct Point<T, U> {
x: T,
y: U,
}
// 使用 impl 时 Point 后面的泛型名称可以任意
// 比如我们之前起名为 K 和 S,但这样容易乱,因为字母太多了
// 所以建议:使用 impl 时的泛型和定义结构体时的泛型保持一致即可
impl<T, U> Point<T, U> {
// 方法类似于函数,它是一个独立的个体,可以有自己独立的泛型
// 然后返回值,因为 Point 里面是泛型,可以代表任意类型
// 那么自然也可以是其它的泛型
fn m1<V, W>(self, a: V, b: W) -> Point<U, W> {
// 所以返回值的成员 x 的类型是 U,那么它应该来自于 self.y
// 成员 y 的类型是 W,它来自于参数 b
Point { x: self.y, y: b }
}
}
fn main() {
// T 是 i32,U 是 f64
let p1 = Point { x: 123, y: 3.14 };
// V 是 &str,W 是 (i32, i32, i32)
println!("{:?}", p1.m1("xx", (1, 2, 3)))
// Point { x: 3.14, y: (1, 2, 3) }
}以上就是 Rust 的泛型,当然在工作中我们不会声明的这么复杂,这里只是为了更好掌握泛型的语法。
然后注意一下方法里面的 self,不是说方法的第一个参数应该是引用吗?理论上是这样的,但此处不行,而且如果写成 &self 是会报错的,会告诉我们没有实现 Copy 这个 trait。
之所以会有这个现象,是因为我们在返回值当中将 self.y 赋值给了成员 x。那么问题来了,如果方法的第一个参数是引用,就意味着结构体在调用完方法之后还能继续用,那么结构体内部所有成员的值都必须有效,否则结构体就没法用了。这个动态数组相似,如果动态数组是有效的,那么内部的所有元素必须都是有效的,否则就可能访问非法的内存。
因此在构建返回值、将 self.y 赋值给成员 x 的时候,就必须将 self.y 拷贝一份,并且还要满足拷贝完之后数据是各自独立的,互不影响。如果 self.y 的数据全部在栈上(可 Copy 的),那么这是没问题的;如果涉及到堆,那么只能转移 self.y 的所有权,因为 Rust 默认不会拷贝堆数据,但如果转移所有权,那么方法调用完之后结构体就不能用了,这与我们将第一个参数声明为引用的目的相矛盾。
所以 Rust 要求 self.y 必须是可 Copy 的,也就是数据必须都在栈上,这样才能满足在不拷贝堆数据的前提下,让 self.y 赋值之后依旧保持有效。但问题是,self.y 的类型是 U,而 U 代表啥类型 Rust 又不知道,所以 Rust 认为 U 不是可 Copy 的,或者说没有实现 Copy 这个 trait,于是报错。
因此第一个参数必须声明为 self,此时泛型是否实现 Copy 就不重要了,没实现的话会直接转移所有权。因为该结构体实例在调用完方法之后会被销毁,不再被使用,那么此时可以转移内部成员的所有权。正所谓人都没了,还要这所有权有啥用,不如在销毁之前将成员值的所有权交给别人。
最后说一下泛型代码的性能,使用泛型的代码和使用具体类型的速度是一样的,因此这就要求 Rust 在编译的时候能够推断出泛型的具体类型,所以类型要明确。
到此这篇关于深入了解Rust中泛型的使用的文章就介绍到这了,更多相关Rust泛型内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!