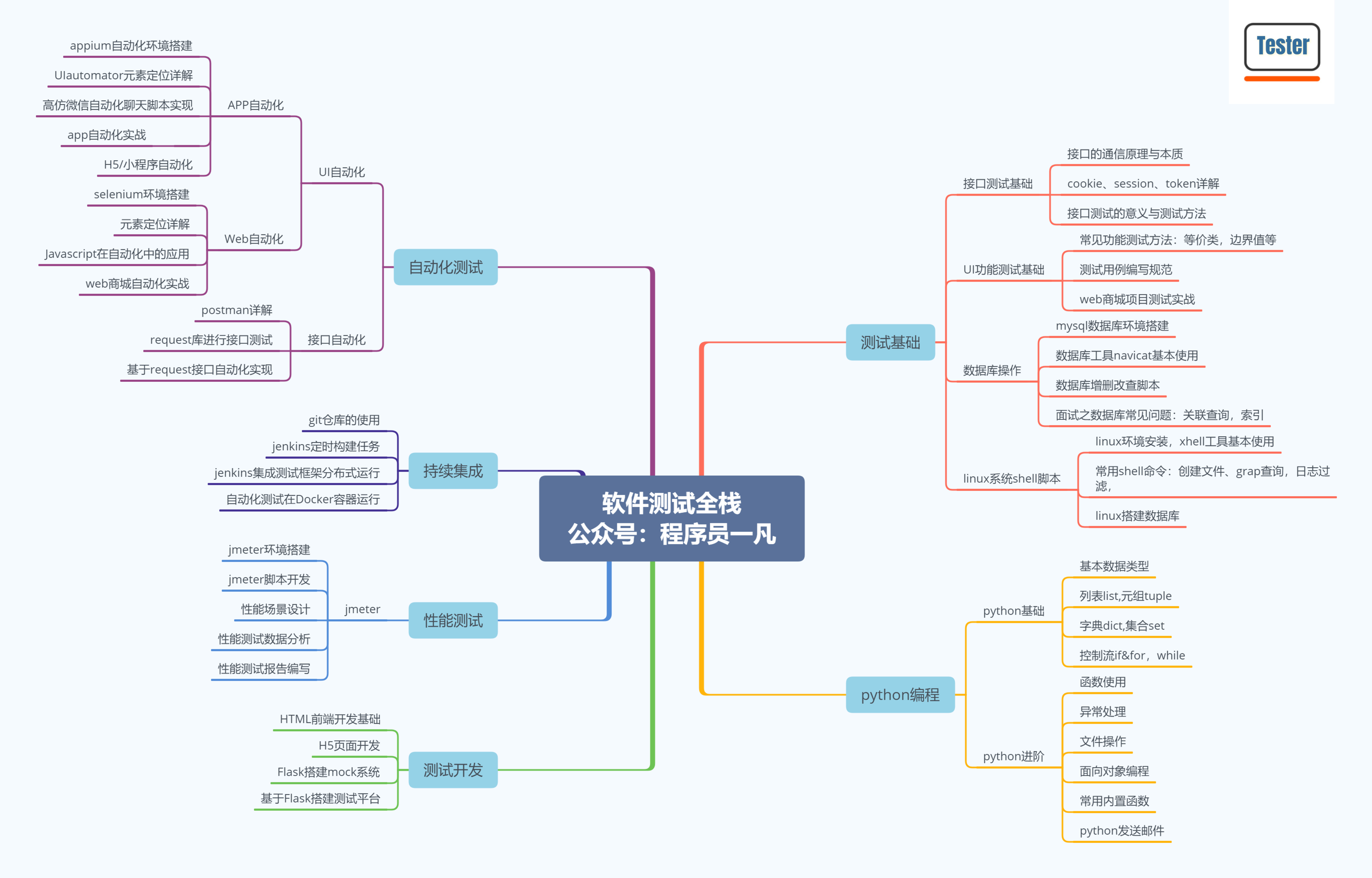
软件测试基础
软件测试的概念
通过一系列手段去证明软件是符合用户需求的,满足质量要求的。预期结果和实际结果的一个对比。
软件测试分类
按方法分:黑盒测试、白盒测试、灰盒测试
黑盒测试:把软件比作一个“黑匣子”,不考虑具体是内部是如何实现的,只考虑外部功能的运行,检查软件的输入和输出是否匹配。
白盒测试:检查软件的代码、函数和方法等内部结构。
灰盒测试:介于白盒和灰盒测试之间,既可以根据外部暴露出的功能进行检测,也可以参考内部的代码结构。
2.按方向分:功能测试、性能测试、安全测试
(1)功能测试:测试产品的功能,以确定是否满足设计需求。
(2)性能测试:分为客户端测试和服务器端测试(一般默认是服务器端测试)。
- 客户端性能测试:启动速度、消耗资源(CPU、内存、硬盘、流量、电量)
- 服务端性能测试(默认):压力测试、负载测试、并发测试
- 压力测试:获取系统正确运行的上限,检查软件在瞬间峰值的情况下是否能够正确运行。(通过多线程模拟)
- 负载测试:在峰值的持续压力下运行软件,看软件的承载极限达到什么程度。
- 并发测试:检查在并发条件下,会不会出现数据错乱的情况。(比如淘宝秒杀)
(3)安全测试:流量攻击、渗透、SQL注入、跨域攻击、爆破、劫持。
流量攻击:模拟大量用户访问服务器,不进行任何有效操作,无端消耗服务器资源。
渗透测试:发现软件系统中存在的漏洞,判断系统的安全性。
SQL注入:通过数据库的关键字进行异常操作,恶意执行不相干的SQL命令。
跨域攻击:诱导用户访问非法网站,利用会话信息模拟请求,盗取和篡改数据。(比如qq盗号)
暴力破解:写相应的脚本,用穷举法不断尝试破解对方的信息。
劫持:比如通过不安全的wifi连接,进行表单提交的操作,造成数据泄露。(还有网页广告弹窗等)
3.按阶段分:单元测试、集成测试、系统测试、验收测试
单元测试:最小模块的测试,可以是对代码、函数、方法进行白盒测试,一般由开发人员执行。
集成测试:主要是测试接口,所以也叫接口测试。(接口:模块与模块之间数据交换的通道。)
系统测试:对系统的功能、性能、安全、UI、稳定性、易用性、兼容性等进行测试。
验收测试:软件发布之前进行的测试,这是测试的最后一个阶段,也叫交付测试,评估产品是否可以发布。
4.按对象分:web测试、app测试、小程序测试、车联网测试、物联网测试
测试方法与测试对象无关,测试流程基本都是通用的。
5.按状态分:动态测试、静态测试
动态测试:运行软件,判断软件运行结果与预期结果的差异,检查软件的正确性。(黑盒测试)
静态测试:不运行软件,检查软件代码、方法、函数、文档的正确性。(白盒测试)
6.其他:回归测试,冒烟测试、α测试、β测试
回归测试:检查开发有没有把bug修改好,重新测试一遍,以保持正确性。
冒烟测试:测试前的测试,检查开发是否进行自测,软件是否具有可测试性。
α测试:产品内测。
β测试:产品公测。
软件基本结构
软件 = 程序+数据+文档
基本结构:
B/S(浏览器/服务器),C/S(客户端/服务器)
主要区别:是否需要单独安装/更新客户端
前端
用户端(前台)
app:andriod(android、kotlin),ios(swift,object-c)
web:html,css,JavaScript
小程序
管理员端(后台)
主要是web
后端
#服务器上运行,断网无法使用,一般是linux环境
数据库
运行环境:java,php,python,.net,go
服务器软件:tomcat,apache,nginx,IIS
(c++一般用于桌面程序)
软件测试的方法
找到合适的测试数据
边界值
(左边界、右边界):<=6,先测<6,再测=6,所以要取边界值和边界值旁边的点,5和6。
等价类
有效等价类:比如0.01-200,0.01,200,0.02,199.99,100.05(保险起见还选了个中间值)
无效等价类:0,200.01
用户场景法
成功的场景:符合要求的金额和红包寄语(默认、0,25,1,25,12),发送红包成功
失败的场景:金额错误、寄语不符合要求(输入的值空,26)(空不等于空格)
了解概念
因果图
判定图
路径覆盖法
软件测试的模型
指的是研发模型(不仅仅是测试模型)
瀑布流
需求分析→软件设计→软件实现(编码)→软件测试→交付验收→实施维护
有完整上下结构,必须完成上一个步骤,才能开始下一个步骤。犯错成本高,容错率低,效 率低,维护成本高。
V字型

测试和开发的工作一一对应。必须完成上一个步骤,才能开始下一个步骤,效率低。
W字型(用得最多)

每个阶段测试和开发都有事做。第一个V代表开发,第二个V代表测试。
分别有什么优势和劣质?
H型
螺旋形
敏捷性(流行趋势)
集中办公,需要高管理水平的人才
搭建测试环境
一般搭建在服务器上。
服务器操作系统的选择:
windows(收费,商业系统,不可选的图形化界面)
OSX(苹果,贵)
Linux(开源,免费,可不选图形化界面,节约成本):通过安装Linux系统或租云服务器获取
测试流程
需求分析阶段
(需求文档,场景原型,交互图,口述)
学习软件的功能、业务、流程
提取软件的功能点(画思维导图)
编写需求分析说明书
测试设计阶段
编写测试文档
测试计划:时间,人员,成本,申请资源、经费
测试策略:规定测试内容的深度和广度,测试内容的先后顺序
深度:是否做单元、集成、系统、验收测试
广度:系统测试的范围(功能、性能、安全、兼容性、易用性、稳定性)
测试方案:具体的测试内容,测试手段
测试用例:具体的测试步骤(excel表格)
测试用例的要素
编号(唯一),用例名称,前置条件,优先级,重要级,测试数据,测试步骤,预期结果,实际结果。
测试是无穷无尽的
测试评审:同行评审,小组评审,部门评审,项目评审,第三方评审,邮件评审
测试执行阶段
执行测试用例、提交bug(bug管理系统)、回归测试、跟踪管理bug,测试环境的搭建
和配置,申请资源
测试总结阶段
1.工作总结
2.bug统计分析
如禅道的报表功能,测试人员的提交bug数,开发人员的造成/修复bug数,不同软件模块的bug数,不同等级的bug数,解决bug的时间,每个版本的bug情况,bug的状态
3.软件质量评估
达到软件交付的标准:一二级bug全部关闭,三级bug关闭了80%以上,四级随缘
测试文档的编写
墨刀(画产品原型) 凹脑图
需求分析阶段:
需求分析说明书

除了功能点,还要列出限制条件,比如字符串长度,数字范围等。比如发红包功能,还要列出成功、失败场景。
测试计划:时间、人员、资源的分配,流程的管理。
测试方案:对每一项测试内容应该用到的测试方法、测试工具、测试开始/结束的标准进行描述。
测试策略:规定测试的范围,哪些阶段需要测试,测试的粒度(要测试多详细),测试顺序(哪些功能先测试),风险分析(最大程度的减少不相干因素的干扰)
以上三个文档经常合并,写进测试计划中。(多看模版)
测试用例:
5w1h

pdca(核心:不断优化)

测试文档:通过测试方法提取功能点,根据场景发提取测试点,根据季等价类、边界值设计测试数据,编写文档。
(mooc网浪晋:如何学好测试用例) 萌芽群里有测试用例模版。
系统测试用例

接口测试用例

测试应用
app测试(B/S),web测试(C/S)
app测试除了常见的测试之外,还有app专项测试:安装/卸载/修复/更新,消息推送,弱网(2G/3G/4G/5G/WIFI)测试,场景交互(来电话了,正在听音乐,摄像头,录音,前后台切换),权限测试(权限关闭和打开是否会影响功能的使用,需要时是否还能还会弹出权限提醒),离线测试。
SVN的使用
svn类似网盘,存放公司文件,输入账号密码可共享。
安装svn--右键文件夹--svn检出--填入版本库url--确定--输入账号密码
创建新文档 -- 右键--svn-- 加入--右键--提交--确定
*每个步骤之前最后先右键更新,以免出现不必要的错误。
bug的管理
在测试用例文档中填写测试结果,提交bug
bug六要素
编号、bug标题、优先级、严重级别、重现步骤、附件(bug截图、错误日志或者视频,提供佐证),
bug管理工具
禅道、BUGFree、ALM(QC)、JIRA、Bugzilla、TAPD、excle、testlink
bug的管理流程都是一样的,选择其中一个就可以了
优先级
和时间有关,使用的功能是否紧急。
一二三级bug都解决了,系统测试结束,可以进入系统交付阶段。
严重级别
致命的(影响核心流程、程序崩溃、程序闪退,和钱有关的)
严重的(主要功能障碍,比如个人资料无法修改)
普通的(可有可无的功能故障、不符合用户习惯的方式)
轻微的(建议)
bug的管理流程
主流程:
1.测试人员提交bug,指派给对应的开发
2.开发确认是否是bug,如果是则修改,不是转回测试人员
3.开发修改完成后,测试进行回归测试。回归测试通过,关闭bug;没通过,回到第一步。
bug状态(生命周期)
新建new,已确认(激活)open,已解决,关闭closed,重新打开(激活)reopen,延迟(是bug,但不着急修改),拒绝(开发认为不是bug),重复bug。
版本迭代
版本号、版本迭代(大版本.小版本.迭代版本 初始1.0.1)
增量测试(只测试有变化的功能),全量测试(测试软件的所有功能)
软件做大之后,不可能每次都进行全量测试,比较老的功能,可以开发自动化测试,这样的话只做增量测试就可以了。
cmmi
了解一下五个等级(近两年不是很流行了,传统的还有保留)
一般会从第三级开始认证,前两级没什么用

搭建linux测试环境
linux系统:centOS(企业用最多的),Ubuntu,debian,kali,redhot,优麒麟,深度
搭建云服务器
腾讯云购买云服务器 -- 进入控制台(记住主ip地址) -- 操作里面的“更多”,修改密码(勾选同意强制关机) -- 刷新界面,状态显示“运行中”,即重启成功
登录(记住端口号)-- 出现linux终端即成功,关闭
连接Xshell
(linux的远程操控软件)
商业版有30天评估期,如果是自己用,下载家庭和学校版就可以了,是免费的:
文件 -- 新建 --名称随意,主机为主IP地址(公),端口号同云服务器 -- 连接 --接受并保存 --输入账号密码(同云服务器) -- 连接成功
linux常见命令
程序的操作
1.启动程序:直接输入程序名(如 vi)
2.关闭程序 (杀死进程):kill -9 进程号(pid)
如果没写-9,默认是-15,即正常终止当前进程。
-9表示进程将被内核杀死;这个信号不容忽视。 9表示不可捕获或可忽略的KILL信号。
查看进程号:ps -ef 查看所有运行中的进程
ps -ef |grep 程序名 ,查看指定程序的进程号
3.安装:不同软件安装方法不同,wget -i -c 以rmp结尾的安装包地址
文件的操作
1.新建文件:touch 文件名
2.新建文件夹 :mkdir 文件夹名
3.复制粘贴:cp 1.txt 文件夹路径
. 当前文件夹
,,上级文件夹
~回到桌面(用户文件夹)
/根目录
4.剪切/移动文件:mv 文件夹名 目标文件夹路径
5.重命名:mv 文件 重命名文件名
6.打开文件夹: cd 文件夹名
cd 文件夹/文件名 从根目录开始找
cd ./文件夹/文件名 从当前目录开始找
7.列出当前文件夹中的文件:
ls(查看文件名列表)
ll(查看文件详情列表)
8.删除:
rm 文件名(删除文件,会跳出确认提示)
rm -r 文件夹(删除文件夹,会跳出确认提示)
rm -f (强制删除文件,不跳出提示)
rm -rf(强制删除文件夹,不跳出提示)
rm -rf /* (格式化根目录)
linux上文件的读写
linux文件编辑器:vi、vim
读文件
1.cat 文件名
直接输出文件内容,一次性读
2.more 文件名
分页读,有显示进度条,“ctrl+C”退出
3.tail
读取动态文件内容。(比如实时变化更新的日志文件)
tail -f 文件名(一直动态读取最新内容)
tail -q 文件名 (读取时不显示处理信息)
tail -n 数字 文件名(读取最新几行的信息,数字几就是最新几行)
tail -c 文件名 (读取时显示字节数)
写文件
1.编辑已有文件
vi 文件名 -- 按“i” 进入编辑模式(出现--INSERT--字样) -- 输入内容 --按“ESC”退出编辑模式 -- 在底端输入“:wq”保存并退出。
:wq (保存并退出)
:q(退出)
:q!(不保存,强制退出)
2.新建可编辑文件
直接输入“vi”进入编辑器 -- 按“i”进入编辑模式 --输入内容 -- 按“ESC”退出编辑模式 --在底端输入“:wq 新建文件名”新建文件,保存并退出。
读写的应用
文件的读写一般用来配置环境变量。linux中配置环境变量的文件是在根目录/etc/profile中设置。
windows中搭建tomcat,java
java安装
1.下载jdk,最好安装在默认路径,不要更改,安装在其他盘容易出问题。
2.配置环境变量:bin目录路径添加到path中,jre路径里面的bin目录也添加到path中。
3.cmd输入”java -version“和”javac -version“,出现版本号即安装成功。
tomcat安装
1.双击下一步安装。
2.浏览器输入127.0.0.1:8080/出现首页即安装成功。
linux中搭建tomcat,java
安装filezilla
(windows和linux之间的文件传输软件)
填入主机,用户名,密码。端口号(同云服务器)--快速连接云服务器
直接把windows上的文件拖入linux对应的文件夹即可。
下载jdk和tomcat,拖入Linux。(一般软件都是安装在usr文件夹中)
安装java
(tomcat是用java写的,所以要运行tomcat,必须要安装Java)
官网下载最新的jdk文件
tar -zxvf 需要解压的jdk文件 -- cd usr/ -- mkdir java -- mv 解压后的文件夹 /usr/java
cd /etc --vi profile -- 在done下空白处,按“i”键进入编辑模式 --写入Java环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin

-- 按“ESC”退出编辑模式 -- 输入“:wq”保存退出 -- source profile(使文件生效,没报错即生效)-- java -version 查看Java版本 -- javac version 查看版本(有版本号即安装成功)
安装tomcat
tar -zxvf 需要解压的tomcat文件 --cd usr/ -- mkdir tomcat -- mv 解压后的文件 /usr/tomcat --cd /usr/tomcat/ -- cd 解压文件夹 -- cd bin/ -- vi setclasspath.sh配置java环境变量 -- 在第一个if前面写,写上Java的位置

-- 按“ESC”退出编辑模式 -- 输入“:wq”保存退出 -- ./startup.sh启动tomcat --在windows浏览器输入主IP地址:8080(如果能打开tomcat主界面即安装成功)
安装过程中可以随时用“ll”命令,查看是否创建相应文件夹和文件。
放入自己的网站
进入/usr/tomcat/apache解压后的文件 -- 找到webapps文件夹(放网站的文件夹)-- 用filezilla放入网站的文件即可。 -- 回到/bin文件夹(可用pwd查看当前路径)-- ./shutdown.sh 关闭tomcat --./shutup.sh重启tomcat -- 在windows浏览器输入主IP地址:8080/放入的网站文件夹名(如果能打开网站即访问成功)
数据库MySQL入门
作用:存储数据
数据库:Oracle(性能好,但是贵),MySQL(性能合适,免费,节约成本,用得最多),SQL server,sqlite,mangodb
mysql的安装
官网-社区版(无可视化,不占用资源,命令行操作)
解压安装包 -- 配置环境变量(系统变量path里加入安装目录和bin目录)-- 打开cmd命令行(管理员身份运行)-- cd进入安装目录 -- 输入mysqld -install安装成功 -- 输入"mysqld --initialize-insecure"初始化(回车无反应即成功 )--输入"net start mysql"启动
检查是否安装成功:普通模式打开cmd --输入mysql -u root -p(出现mysql>)即成功
navicat可视化工具
官网下载 -- 连接mysql -- 创建数据库 -- 创建表 -- 设计表
修改密码:
用户--双击root@localhost--直接修改
*主机填%,所有电脑都可以访问;填localhost,只有本机可以访问
mysql基础命令
1.连接数据库
mysql -u root -p(初始化账号密码为空)
完整:mysql-h localhost(主机名或ip地址)-port 3306 -u -root -p
2.show databases;显示数据库
3.use 数据库名;进入相应数据库
4.show tables;显示表
5.create database 数据库名;创建数据库
6.drop database 数据库名;删除数据库
7.create table 表名(
字段名 类型(大小) not null,
字段名2 类型(大小),
……);新建表
8.drop table 表名;删除表
9.修改表:
alter table 表名 drop 字段名;删除字段
alter table 表名 add 字段名 类型(长度);增加字段
alter table 表名 change 旧字段名 新字段名 类型(长度);修改字段名
alter table 表名 modify 字段名 修改类型(修改长度);修改字段属性
10.desc 表名;查看表结构
11.运行sql文件:source xxx.sql
表的四大操作
1.增:insert into 表名(字段1,2……) values(字段值1,2……);
2.删:delete from 表名 where 条件;
3.改:update 表名 set 字段 字段=字段值 where 条件;
4.查:点击筛选/查询 select 字段/* from 表名 where 条件;
多表联查(前提是具有表关系):
内关联:(inner) join on(两张表的交集)
连接两张表:select */具体需要的字段 from 表1 join 表2 on 表关系(表1.字段=表2.字段)where 条件;
三张表:继续join 表3 on 表关系;
外关联:
左关联left join on(两张表的交集加上左表)
右关联right join on(两张表的交集加上右表)
常用命令及应用
模糊查询:where 字段 like '刘%';姓刘('%三%';名字带三。'%刘',以刘结尾。)
排序:order by 字段(从小到大)+desc(从大到小)
限制条数:
limit 5:从第一行开始显示5条,即limit 0,5
limit 5,5;葱第五行开始显示5条
字段重命名:select id as '编号',name as '姓名' from 表 where 条件;(as可省略)
表重命名:select 字段1,2…… from 表 as 重命名的表名1(如s) join 表2 as 重命名表2(如q) on s.字段=g.字段;
聚合函数:
最大/小值:select min/max(字段)from 表;
求和:select sum(字段)from 表;
select 字段1+字段2+…… as '表头名' from 表;
平均数:select avg(字段) from 表;
计数:select count(*) from 表;
分组:group by 字段名(按组拆分表,再计算);配合聚合函数使用
网络知识
接口测试
#接口测试工具:postman,Jmeter
接口测试文档必要信息
1.接口名称,接口地址url,
2.接口类型:
post 修改数据库数据,像服务器发送数据
get 从数据库读取数据
put,patch,delete,copy,head,options,link,unlink,purge,lock,unlock,propfind,view
3.接口参数:form-data,ram(text,json,xml),x-www-form-urlencoded,none,binary
4.请求头:headers
5.返回的数据
6.状态码
7.缓存(解决无状态连接的问题):
session:存在服务器中,更安全
cookies:存在本地
*session存在于服务器中的账号密码,cookie相当于银行卡,token相当于银行卡密码。
网络知识
网络协议
1.tcp 速度慢,数据安全可靠(http不加密,https加密)
可靠原因:三次握手
2.udp 速度快,发送的数据不可靠
3.socket 一般用于客户端
协议缺陷:无状态连接,每次请求都是独立的,记不住上次的请求,所以要引入缓存。
ip
公网ip:运行商提供
局域网ip:
windows查看ip:进入cmd--输入ipconfig--看ipv4
linux查看ip:进入cmd--输入ifconfig --看inet
本机ip:localhost或127.0.0.1
查看特定网站的ip:进入cmd--输ping -www.baidu.com查看百度的ip
端口号
22:访问Linux服务器的默认端口
3306:访问mysql的默认端口
8080:访问tomcat的默认端口
域名
ip的别称,好记,花钱买。
bug的定位
集成测试(接口测试):后端bug
系统测试:
1.看有没有操作接口
2.没有即前端的bug
3.有的话看状态码:
200一般是前端的bug,不过也有可能是代码没问题,功能写错了
4*,一般是前端bug
500 后端服务器bug
抓包工具
1.fiddle 免费,可抓web和app
2.network 浏览器自带(F12),抓web,选择XHR是看接口数据。
3.Charles 收费,可抓web和app
抓HTTPS的包
安装证书。
fiddle--tools--option--https--钩上前两个选项--弹窗都点yes。(没出现弹窗点actions)
对app进行抓包
fiddler是通过代理的形式进行抓包的一个抓包工具,默认的代理端口为8888。
1.要抓取手机app的数据包,要对fiddler进行设置,打开fiddler后,选择"Tools"项,在点击"Options",进入到设置界面。
2.在"Options"界面,选择"Connections"项,检查"Allow remote computers to connect"是否勾选。
3.在配置手机代理设置前,需要知道电脑的IP地址,可以通过cmd中输入"ipconfig"查看。
4.进入到手机的wlan配置界面,点开已经连上的wlan,进入到该wlan的设置界面。
5.在wlan设置界面找到"代理设置"项,点击进入到代理设置界面,填入电脑ip和端口
号。
6.运行手机上的APP,然后观察fiddler,就可以发现抓取到了运行该APP的响应数据。
7.进入到"Tools"—>Options——>https项,选择"...from remote clients only",这样就只显示抓到的手机上的数据包。
python基础
python安装
1.双击安装(记得勾选add python to path)
2.cmd里输入”pip list“,出现版本号;再输入”python“,出现python版本号,和”>>>“,即成功。
vscode安装
1.双击安装,不要下载user版。
2.自带的插件商店里输入chinese,安装汉化包。
3.按住”ctrl+shift+p“,搜索”config“,选择语言配置,出现”language:zh-ch“即中文。
vscode配置python环境:
1.插件商店输入”python“安装python包。
2.点击左边的爬虫图标,点击”没有配置“后面的设置,选择第一个python file,出现的文件关掉就行。看到终端右上角出现python,点一下旁边的加号,点击”选择默认shell“,选择”cmd“。
3.设置里搜索“python path”,添加python的安装路径,出现文件setting.json 和"python.pythonPath": "D:\\python\\python38\\python.exe"即可。*这样不同的项目就可以用不同的python。
python基础知识
python的数据类型:int,str,float,bool,NoneType,tuple,list,dict
python注释:单行注释#,多行注释""" """
插入数据:
a.append(),在末尾追加数据
insert(下标,数据) 在指定下标处插入数据
删除数据:
a.pop(下标或"字典的key"),取出指定数据进行操作,并在原序列中删除这个数据
del a[下标或"字典的key"] 直接删除数据,没法对删除的数据操作
获取数据:
a.get("key"),当key不存在时,返回none。
a["key"],当key不存在时,报错。
判断条件:<,>,==,!=,in,not in, is, not is
判断的连接词:and,or,not and,not or
异常捕获:
try
……
except Exception as e:
return "错误信息,{}".format(e)
既可以显示自定义的错误信息,还可以显示系统的报错信息e
python的第三方包
常见第三方包:selenium,requests,pymysql,xlrd,xlwt
常见命令:
pip -v ;查看pip的版本
pip list ;查看所以安装的第三方包及版本
pip install 包名; 安装第三方包
pip uninstall;卸载第三方包
pip install -r xxx.txt;批量安装txt文件中写入的安装包
pip install 包名 -i 下载源地址;切换下载地址,默认的下载地址是国外的官网,下载速度慢
pymysql的用法
下载安装:pip install pymysql
import pymysql
连接数据库:
db=pymysql.connect(host="ip地址",user="用户名",password="密码",db="数据库名")
获取光标(游标):
cursor=db.cursor()
执行sql语句:
cursor.execute("sql查询语句")
获取结果(返回值):
res=cursor.fetchall()
打印结果:
print(res)
关闭数据库:
db.close()
*如果输入的是sql修改语句,后面就不是获取结果,而是提交修改db.commit()
requests库的使用
下载安装:pip install requests
失败的话,直接用镜像安装:
pip install requests -i http://pypi.douban.com/simple --trusted-host=pypi.douban.com
import requests
访问get接口类型
1.获取接口地址
url="接口地址?参数=参数值&参数2=参数值2"
headers={请求头} (如果headers已存在,可以用headers.update(参数)追加新的参数)
2.访问接口(发送请求)
res = requests.get(url, headers=headers)
3.打印返回结果
print(res.text)
res.text 以文本(字符串)格式返回结果
res.json 以json(字典)格式返回结果
res.cookies 获取cookie的值
访问post接口类型
requests.post(参数)
参数:url,method(get,post……),headers,data(普通类型数据),json(json字典类型数据),cookies,file
返回信息:返回的数据,cookies,code,time,size,headers
requests库模拟登录
在postman里,传入token即可登录成功。
使用requests库,仅仅传入url,headers,data=token不成功,无法登录。
原因:
因为postman里会自动补全session的值,而requests方法不会。
解决办法:
1.手工添加
session={
"用户1":{"token":"geagaeg"}
"用户2":{"token":"fnaohfioahio"}
}
session在cookies里,使用res.cookies获取cookie的值,添加参数cookies=cookies
2.自动添加
开头增加一条语句 requests = requests.Session
方法,类,包的封装
方法封装
适用于步骤相同,只有输入数据不同的情况。
def 方法名(参数):
"""
在调用这个方法的时候,鼠标移动到方法名上,会显示这个注释
"""
return
类
包>模块>类>方法>变量
多次输入相同数据,进行不同操作的情况,解决方法:
1.方法一:配置文件config.py
info = 多次输入的信息
然后from config import info
直接引用变量info即可。
*如果info={"user":"123"}是字典,引用变量**info,加上**可让"user":"123"变成"user"="123"
2.方法二:定义类
class 类名(*首字母大写):
"""
注释
"""
def __init__(self){
self.参数=值
}
def 方法1(self,参数){
}
a=类名(参数)#类的实例化
再调用里面的方法。
类的继承和重写(多态)
class 类名a(类名b):
def……
#a继承了b的所有方法
创建包
新建文件夹--新建文件__init__.py,再放入其他py文件,就成为一个包了,可用import导入使用。
Python读取excel文件
1.读取普通文件
with open("文件名.py","模式")as f:
res.read(行数) #行数可省略,即全部读取
模式:r(可读模式),w(可写模式),a(追加模式)
读取:res.read()
写入:res.write("写入内容")
2.读取excel
pip install xlrd (安装xlrd)
1.打开excel文件
excel = xlrd.open_workbook("xxx.xlsx")
2.选取对应的sheet表
table = excel.sheet_by_name("sheet名")
3.获取表格行和列的数据
行数 = table.ncols
列数 = table.nrows
4.按坐标获取单个特定表格的数据
value = table.cell_value(0,0)
5.读取整个表格的数据
for i in range(行数):
for j in range(列数):
value = table.cell_value(i,j)
print(value,end=" ")
6.以数组形式,按行储存表格
tabledata = []
for i in range(列数):
tabledata.append(table.row_values(i))
*可以结合xlrd和requests,自动读取xlrd的内容,进行批量自动测试
报错问题
卸载Python时报错:No Python installation was detected
打开C:\Users\Administrator\AppData\Local\Programs;
删除Python文件夹;
打开控制面板>> 删除程序,找到Python,右键点击更改;
点击Repair (Uninstall的上一个选项);
然后右键点击卸载Uninstall。
VScode:Linter pylint is not installed.
pip install pylint *注意要在c盘下运行
pip更新失败

使用强制更新命令:“python -m pip install -U --force-reinstall pip”
unittest自动化框架搭建
自动化测试框架:unittest(自带),pytest(第三方)
unittest的使用
1.定义类
class 类名(类名必须以Test开头)(unittest.TestCase)#固定继承这个类
2.写入方法或测试用例
def test_01_方法名(self,参数)
#方法名加01是为了控制顺序,否则将按首字母的顺序排序
3.判断结果
用断言判断结果
self.断言方法(参数)


4.运行代码
if __name__ = "__main__":
unittest.main(参数)
其中一个参数叫verbosity,代表结果的详细程度,=1是默认,=2更加详细。
5.显示结果
.代表成功
F代表失败
同时运行多个测试用例文件
实际中不常用
1.新建文件run.py
2.import unittest
3.倒入测试文件中的类
from 文件名 import 类名
4.将测试用例装入测试套件
suite = unittest.TestSuite #实例化测试套件
tests = [测试类名("类里的方法"),测试类名……]
suite.addTests(tests)
5.运行
runner = unittest.TextTestRunner(verbosity=2,参数可省略))
runners.run(suite)
实际运用
把测试用例文件放进同一个文件夹
*tests = unittest.defaultTestLoad.discover(".",pattern="test_*.py")
#"."代表当前文件夹,"test_"代表以test_开头的文件
完整代码:
suite = unittest.TestSuite()
tests = unittest.defaultTestLoader.discover(".",pattern = "test_*.py")
suite.addTests(tests)
with open("xx.txt","w") as f:
runner = unittest.TextTestRunner(stream=f #写入文件,verbosity=2)
runner.run(suite)
生成测试报告
下载文件 HTMLTestRunner.py,放入测试文件夹
import unittest
from HTMLTestRunner import HTMLTestRunner
import time
nowtime = time.strftime("%y-%m-%d_%H_%M_%S")
suite = unittest.TestSuite()
tests = unittest.defaultTestLoader.discover("测试文件夹",pattern="test_*.py")
suite.addTests(tests)
with open("测试报告().html".format(nowtime),"wb") as f:
runner = HTMLTestRunner(stream=f,verbosity=2,title="测试报告",description="描述")
runner.run(suite)
组织代码:
把文件分类,归档到文件夹,只留一个run.py
设置测试的前置条件:
def setUp(self): #用例执行前运行
获取self.token和self.requests = requests.Session() #模拟登陆功能
def tearDown(self): #用例执行后运行
缺点:有多少测试用例,就执行多少次。比如用例1.2.3的的前置条件都是a,结束都是b,这样写运行的顺序是a1ba2ba3b,每次都要运行一次前置条件。
改进:加入装饰器
@classmethod
def setUp(cls):
@classmethod
def tearDown(cls):(一般用于数据清理)
Db.commit(delete from 表 where 用户id="测试员1";)
#这样不会积累测试数据,测试完就删除清空。
*setUphetearDown方法里的初始变量都用cls.变量名,在测试用例里引用的时候,还是写self.变量名
selenium入门
接口自动化测试(requests),UI自动化测试(web#selenium,app#appnium)
配置selenium环境
1.安装
管理员模式cmd--pip3 install selenium
2.下载浏览器驱动(比如谷歌)
1.确定浏览器版本(只看最高位就行)
2.搜"chromedriver 淘宝"进入driver mirror网站,下载对应版本驱动
3.新建脚本文件夹(文件夹名不能是selenium)
4.新建py脚本,用于写自动化测试脚本
5.解压驱动,和脚本文件一起放入脚本文件夹
模拟百度搜索:
1.导入selenium
import selenium或者from selenium import webdriver
2.实例化浏览器,获得实例化句柄
driver = selenium.webdriver.Chrome(executable_path = '驱动文件夹路径(相对于当前脚本文件路径)')
3.打开网页
driver.get("网址")
driver.maximize_window() #全屏运行浏览器
4.在搜索框输入文本
用开发者工具,定位搜索框元素的id或其他name之类的。
e = driver.find_element_by_id("输入框id")
e.send_keys("搜索内容")
5.点击搜索
审查搜索按钮的id
button = driver.find_element_by_id("搜索按钮id")
button.click()
6.关闭浏览器
driver.quit()
7.检查搜索结果
因为网页内容是变化的,但是网页title不变,所以可以用title做判断。
driver.title 获取网页标题
assert driver.title = "title名"。#用断言判断
判断没有成功:因为代码运行比网页加载快,这时应该在开头设置一下等待时间。
设置等待
1.静态等待
time.sleep(秒数a) #等待a秒
2.等待网页加载
driver.implicitly_wait(10) #等待网页加载,10秒内加载完,就立刻运行下面的代码,超过10秒,也立刻运行。
3.动态查找元素
1.导入webdriverwait
from selenium webdriver.support.ui import WebDriverWait
2.直接在查找元素的时候等待
i.以元组的形式存储要查找的元素
变量名1 = ("id","id号")
变量名2 = ("name","name号")
变量名 = ("xpath","xpath路径")
……
ii.操作元素
webDriverWait(driver,10).until(lambda s: s.find_element(*变量1)).send_key("搜索内容")
#变量名前面加个*号,即解压元组,*("1","2")== "1","2"
#driver为浏览器驱动对象,10为超时时间,超时会报超时

优化


八大定位元素方式
1.id
driver.find_element_by_id("id")
2.xpath
找到搜索框元素,右键copy --> xpath
driver.find_element_by_xpath("'xpath'") #xpath语句用单引号
3.name
driver.find_element_by_name("name") #driver.current_url获取当前网页地址
4.classname
driver.find_element_by_name("name")
5.css selector
driver.find_element_by_css_selector("XXXX") #找到搜索框元素,右键copy --> selector
6.link_text
driver.find_element_by_link_text("链接名")。
只适用于a标签链接,比如<a>123</a>,就填123
7.部分link_text
driver.find_element_by_partial_link_text("hao")
比如<a>hao123</a>,只写hao就可以找到
8.tag标签
driver.find_element_bt_tag("tag标签")
<a><body>等标签
切换网页作用域
1.iframe
判断是否有iframe框架,网页右键空白处,出现"是否加载框架",或者代码里直接搜iframe。
driver.switch_to_frame
2.新窗口_blank
driver.switch_to_window(driver.window_handles[-1])
#driver.window_handles[-1]为所有窗口的句柄
3.alert提示窗口
driver.switch_to_alert().accept() #点击确定
driver.switch_to_alert().dismiss() #点击取消
appium基础入门
appium环境设置
jdk配置
一、背景
JDK已经更新到12了,但是由于很多工具仍然未及时更新,故推荐最稳定的JDK版本1.8.x;
JDK需要配置通常情况下,JDK配置分为三项:
JAVA_HOME:某些软件仍然需要
CLASSPATH:某些Java WEB项目部署需要
PATH:都需要(O(∩_∩)O哈哈~)
二、安装
链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-
要注册oracle账户才能下载

这里选择自己操作系统对应的版本,如果是32位的操作系统,就选择32位的;如果是64位的就选择64。
三、配置
1. 解压
解压到 C:\Program Files (x86)\Java\
2. 配置
右键计算机 > 属性 > 高级系统设置 > 环境变量 > 系统变量 进行设置

右键计算机选择属性
在系统变量里面进行设置

环境变量设置
新建JAVA_HOME: C:\Program Files (x86)\Java\jdk1.8.0_171

新建CLASSPATH:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;

PATH环境添加:;%JAVA_HOME%\BIN;%JAVA_HOME%\JRE\BIN;

CLASSPATH如果存在,就直接添加
4. 验证
输入:java -version
输入:javac -version
如图显示后,即可正常

安卓sdk配置
Android Debug Bridge,我们一般简称为adb,主要存放在sdk安装目录下的platform-tools文件夹中,它是一个非常强大的命令行工具,通过这个工具用来连接电脑和Android设备(手机、电脑、电视、平板、电视盒子等)。
安装
1. 下载安装包:
链接: https://pan.baidu.com/s/1ar6OPXCRohYXFAa83wmoxQ
提取码: 54zh
2. 解压文件包到固定位置:D:\android-sdk-windows

3. 新建a环境变量;将b c环境变量添加到path环境下
* a. 添加环境变量:
变量名:ANDROID_HOME
变量值:D:\android-sdk-windows
* b. 在path目录最后面添加:%ANDROID_HOME%\tools;%ANDROID_HOME%\platform-tools;

4. 打开命令提示符:win键+R,并输入“cmd”
5. 在cmd输入命令验证添加环境变量是否成功:adb version

查看adb环境是否配置成功
准备安卓模拟器
1. 下载并安装雷电模拟器:http://www.ldmnq.com/
2. 安装完成后,我们需要查看雷电模拟器是否连接adb,在cmd中输入命令:adb devices

查看模拟器是否安装成功
常用命令
4.1 adb kill-server和adb start-server
关闭adb server和开启adb server。
有时候ADB Server会出现异常故障,我们组需要使用上述命令重启ADB Server。

4.2 adb devices
查看当前PC端连接有多少设备,通常使用此命令判断设备是否连接上电脑。(出现emulator-5554基本上就表示连上了)

4.3 adb logcat
获取设备运行日志。通过该命令捕获安卓APP崩溃时的异常信息,帮助问题定位。

然后找到并打开日志,分析其中异常信息。

4.4 adb install
栗子:adb install xxx.apk
作用:给安卓设备安装xxx软件。运行命令后,有些手机手动确认允许电脑安装软件。

4.5 adb pull
栗子:adb pull /sdcard/123.txt C://abc
作用:将设备文件/sdcard/文件夹下的123.txt文件复制到电脑的C盘adb文件夹下。
4.6 adb push
栗子:adb push C://123.txt /sdcard/
作用:将电脑C盘目录下的123.txt文件复制到设备/sdcard/下。
4.7 adb shell
进入安卓设备的shell终端。安卓是给予Linux开发的,每一个安卓设备都自带shell终端。

我们可以使用shell终端来进行各项操作,比如查看文件目录:ls

或者可以查看安卓手机运行状态:top

还可以查看手机剩余运行内容:free -m

还可以查看手机剩余存储空间:df

扩展阅读:ADB命令大全:https://blog.csdn.net/MzTestor/article/details/79310900
appium-desktop安装
安装appium的安卓客户端
- pip3 install Appium-Python-Client -i https://pypi.tuna.tsinghua.edu.cn/simple
安装安卓模拟器
- 下载并安装雷电模拟器:http://www.ldmnq.com/
- 打开雷电模拟器
安装被测APP
传送门:链接: https://pan.baidu.com/s/1Yexgofqhb7w3F1U9RTBW_w 提取码: fv7s
连接安卓设备
使用的是手机:打开安卓手机的USB调试,用数据线连接手机和电脑
使用的是模拟器:直接去执行adb devices
在windows命令提示符中输入:adb devices,能看到手机连上电脑既可

编写appium的python代码
在VSCode中新建Python文件,并且输入对应代码运行查看效果
根据自己的手机来修改代码中对应的参数
# 1.导入appium的webdriver
from appium import webdriver
def get_driver():
"""
获取设备driver
"""
desired_caps = {}
desired_caps['platformName'] = 'Android'
# 打开什么平台的app,固定的 > 启动安卓平台
desired_caps['platformVersion'] = '5.1.1'
# 安卓系统的版本号:adb shell getprop ro.build.version.release
desired_caps['deviceName'] = 'vivo x6plus d'
# 手机/模拟器的型号:adb shell getprop ro.product.model
desired_caps['appPackage'] = 'io.appium.android.apis'
# app的名字:
# 需要先打开被测软件,u0背后就是包名。“/”后面,
#tXX前面就是activity启动页面的名字,包括前面那个小数点。
#有时获取不到,或者打开有广告,清除一下缓存。
#安卓8.1之前:adb shell dumpsys activity | findstr "mFocusedActivity"
# 安卓8.1之后:adb shell dumpsys activity | findstr "mResume"
desired_caps['appActivity'] = '.ApiDemos' # 同上↑
desired_caps['unicodeKeyboard'] = True # 为了支持中文
desired_caps['resetKeyboard'] = True # 设置成appium自带的键盘
# 去打开app,并且返回当前app的操作对象。接口4723看打开appium的时候显示的是哪个接口就填哪个。
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
return driver
def test():
"""
查找单个元素,appium-inspector元素定位器,点击appium里的放大镜就可以出现。
在desired CApabilities里加入字典desired_caps的各个元素, 点save as保存-点击start运行--列出了不同的元素,直接点击使用里面的id,xpath等。
"""
# 获取driver
driver = get_driver()
# 通过id获取元素:最准确,*安卓里的id值不唯一,id不是id值,resource-id才是id值。
app = driver.find_element_by_id("android:id/text1")
app.click()
# 返回键
driver.back()
# 通过text获取元素。直接用元素的名字就行。
Animation = driver.find_element_by_android_uiautomator('new UiSelector().text("Animation")')