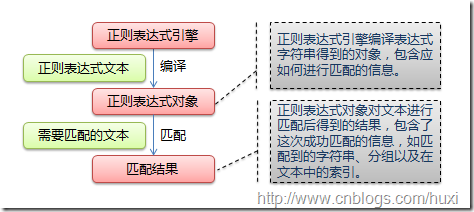
正则表达式是一个很强大的字符串处理工具,几乎任何关于字符串的操作都可以使用正则表达式来完成,作为一个爬虫工作者,每天和字符串打交道,正则表达式更是不可或缺的技能,正则表达式的在不同的语言中使用方式可能不一样,不过只要学会了任意一门语言的正则表达式用法,其他语言中大部分也只是换了个函数的名称而已,本质都是一样的。下面,我来介绍一下python中的正则表达式是怎么使用的。
首先,python中的正则表达式大致分为以下几部分:
- 元字符
- 模式
- 函数
- re 内置对象用法
- 分组用法
- 环视用法
所有关于正则表达式的操作都使用 python 标准库中的 re 模块。
一、元字符 (参见 python 模块 re 文档)
-
- . 匹配任意字符(不包括换行符)
- ^ 匹配开始位置,多行模式下匹配每一行的开始
- $ 匹配结束位置,多行模式下匹配每一行的结束
- * 匹配前一个元字符0到多次
- + 匹配前一个元字符1到多次
- ? 匹配前一个元字符0到1次
- {m,n} 匹配前一个元字符m到n次
- \\ 转义字符,跟在其后的字符将失去作为特殊元字符的含义,例如\\.只能匹配.,不能再匹配任意字符
- [] 字符集,一个字符的集合,可匹配其中任意一个字符
- | 逻辑表达式 或 ,比如 a|b 代表可匹配 a 或者 b
- (...) 分组,默认为捕获,即被分组的内容可以被单独取出,默认每个分组有个索引,从 1 开始,按照"("的顺序决定索引值
- (?iLmsux) 分组中可以设置模式,iLmsux之中的每个字符代表一个模式,用法参见 模式 I
- (?:...) 分组的不捕获模式,计算索引时会跳过这个分组
- (?P<name>...) 分组的命名模式,取此分组中的内容时可以使用索引也可以使用name
- (?P=name) 分组的引用模式,可在同一个正则表达式用引用前面命名过的正则
- (?#...) 注释,不影响正则表达式其它部分,用法参见 模式 I
- (?=...) 顺序肯定环视,表示所在位置右侧能够匹配括号内正则
- (?!...) 顺序否定环视,表示所在位置右侧不能匹配括号内正则
- (?<=...) 逆序肯定环视,表示所在位置左侧能够匹配括号内正则
- (?<!...) 逆序否定环视,表示所在位置左侧不能匹配括号内正则
- (?(id/name)yes|no) 若前面指定id或name的分区匹配成功则执行yes处的正则,否则执行no处的正则
- \number 匹配和前面索引为number的分组捕获到的内容一样的字符串
- \A 匹配字符串开始位置,忽略多行模式
- \Z 匹配字符串结束位置,忽略多行模式
- \b 匹配位于单词开始或结束位置的空字符串
- \B 匹配不位于单词开始或结束位置的空字符串
- \d 匹配一个数字, 相当于 [0-9]
- \D 匹配非数字,相当于 [^0-9]
- \s 匹配任意空白字符, 相当于 [ \t\n\r\f\v]
- \S 匹配非空白字符,相当于 [^ \t\n\r\f\v]
- \w 匹配数字、字母、下划线中任意一个字符, 相当于 [a-zA-Z0-9_]
- \W 匹配非数字、字母、下划线中的任意字符,相当于 [^a-zA-Z0-9_]
二、模式
-
- I IGNORECASE, 忽略大小写的匹配模式, 样例如下
s = 'hello World!' regex = re.compile("hello world!", re.I) print regex.match(s).group() #output> 'hello World!' #在正则表达式中指定模式以及注释 regex = re.compile("(?#注释)(?i)hello world!") print regex.match(s).group() #output> 'hello World!'
- L LOCALE, 字符集本地化。这个功能是为了支持多语言版本的字符集使用环境的,比如在转义符\w,在英文环境下,它代表[a-zA-Z0-9_],即所以英文字符和数字。如果在一个法语环境下使用,缺省设置下,不能匹配"é" 或 "ç"。加上这L选项和就可以匹配了。不过这个对于中文环境似乎没有什么用,它仍然不能匹配中文字符。
- M MULTILINE,多行模式, 改变 ^ 和 $ 的行为
s = '''first line second line third line''' # ^ regex_start = re.compile("^\w+") print regex_start.findall(s) # output> ['first'] regex_start_m = re.compile("^\w+", re.M) print regex_start_m.findall(s) # output> ['first', 'second', 'third'] #$ regex_end = re.compile("\w+$") print regex_end.findall(s) # output> ['line'] regex_end_m = re.compile("\w+$", re.M) print regex_end_m.findall(s) # output> ['line', 'line', 'line'] - S DOTALL,此模式下 '.' 的匹配不受限制,可匹配任何字符,包括换行符
s = '''first line second line third line''' # regex = re.compile(".+") print regex.findall(s) # output> ['first line', 'second line', 'third line'] # re.S regex_dotall = re.compile(".+", re.S) print regex_dotall.findall(s) # output> ['first line\nsecond line\nthird line'] - X VERBOSE,冗余模式, 此模式忽略正则表达式中的空白和#号的注释,例如写一个匹配邮箱的正则表达式
email_regex = re.compile("[\w+\.]+@[a-zA-Z\d]+\.(com|cn)") email_regex = re.compile("""[\w+\.]+ # 匹配@符前的部分 @ # @符 [a-zA-Z\d]+ # 邮箱类别 \.(com|cn) # 邮箱后缀 """, re.X)
- I IGNORECASE, 忽略大小写的匹配模式, 样例如下
-
- U UNICODE,使用 \w, \W, \b, \B 这些元字符时将按照 UNICODE 定义的属性.
正则表达式的模式是可以同时使用多个的,在 python 里面使用按位或运算符 | 同时添加多个模式
如 re.compile('', re.I|re.M|re.S)
每个模式在 re 模块中其实就是不同的数字
print re.I
# output> 2
print re.L
# output> 4
print re.M
# output> 8
print re.S
# output> 16
print re.X
# output> 64
print re.U
# output> 32
三、函数 (参见 python 模块 re 文档)
python 的 re 模块提供了很多方便的函数使你可以使用正则表达式来操作字符串,每种函数都有它自己的特性和使用场景,熟悉之后对你的工作会有很大帮助
-
- compile(pattern, flags=0)
给定一个正则表达式 pattern,指定使用的模式 flags 默认为0 即不使用任何模式,然后会返回一个 SRE_Pattern (参见 第四小节 re 内置对象用法) 对象
regex = re.compile(".+")
print regex
# output> <_sre.SRE_Pattern object at 0x00000000026BB0B8>
这个对象可以调用其他函数来完成匹配,一般来说推荐使用 compile 函数预编译出一个正则模式之后再去使用,这样在后面的代码中可以很方便的复用它,当然大部分函数也可以不用 compile 直接使用,具体见 findall 函数
s = '''first line
second line
third line'''
#
regex = re.compile(".+")
# 调用 findall 函数
print regex.findall(s)
# output> ['first line', 'second line', 'third line']
# 调用 search 函数
print regex.search(s).group()
# output> first lin
-
- escape(pattern)
转义 如果你需要操作的文本中含有正则的元字符,你在写正则的时候需要将元字符加上反斜扛 \ 去匹配自身, 而当这样的字符很多时,写出来的正则表达式就看起来很乱而且写起来也挺麻烦的,这个时候你可以使用这个函数,用法如下
s = ".+\d123"
#
regex_str = re.escape(".+\d123")
# 查看转义后的字符
print regex_str
# output> \.\+\\d123
# 查看匹配到的结果
for g in re.findall(regex_str, s):
print g
# output> .+\d123
-
- findall(pattern, string, flags=0)
参数 pattern 为正则表达式, string 为待操作字符串, flags 为所用模式,函数作用为在待操作字符串中寻找所有匹配正则表达式的字串,返回一个列表,如果没有匹配到任何子串,返回一个空列表。
s = '''first line
second line
third line'''
# compile 预编译后使用 findall
regex = re.compile("\w+")
print regex.findall(s)
# output> ['first', 'line', 'second', 'line', 'third', 'line']
# 不使用 compile 直接使用 findall
print re.findall("\w+", s)
# output> ['first', 'line', 'second', 'line', 'third', 'line']
-
- finditer(pattern, string, flags=0)
参数和作用与 findall 一样,不同之处在于 findall 返回一个列表, finditer 返回一个迭代器(参见 http://www.cnblogs.com/huxi/archive/2011/07/01/2095931.html ), 而且迭代器每次返回的值并不是字符串,而是一个 SRE_Match (参见 第四小节 re 内置对象用法) 对象,这个对象的具体用法见 match 函数。
s = '''first line
second line
third line'''
regex = re.compile("\w+")
print regex.finditer(s)
# output> <callable-iterator object at 0x0000000001DF3B38>
for i in regex.finditer(s):
print i
# output> <_sre.SRE_Match object at 0x0000000002B7A920>
# <_sre.SRE_Match object at 0x0000000002B7A8B8>
# <_sre.SRE_Match object at 0x0000000002B7A920>
# <_sre.SRE_Match object at 0x0000000002B7A8B8>
# <_sre.SRE_Match object at 0x0000000002B7A920>
# <_sre.SRE_Match object at 0x0000000002B7A8B8>
-
- match(pattern, string, flags=0)
使用指定正则去待操作字符串中寻找可以匹配的子串, 返回匹配上的第一个字串,并且不再继续找,需要注意的是 match 函数是从字符串开始处开始查找的,如果开始处不匹配,则不再继续寻找,返回值为 一个 SRE_Match (参见 第四小节 re 内置对象用法) 对象,找不到时返回 None
s = '''first line
second line
third line'''
# compile
regex = re.compile("\w+")
m = regex.match(s)
print m
# output> <_sre.SRE_Match object at 0x0000000002BCA8B8>
print m.group()
# output> first
# s 的开头是 "f", 但正则中限制了开始为 i 所以找不到
regex = re.compile("^i\w+")
print regex.match(s)
# output> None
-
- purge()
当你在程序中使用 re 模块,无论是先使用 compile 还是直接使用比如 findall 来使用正则表达式操作文本,re 模块都会将正则表达式先编译一下, 并且会将编译过后的正则表达式放到缓存中,这样下次使用同样的正则表达式的时候就不需要再次编译, 因为编译其实是很费时的,这样可以提升效率,而默认缓存的正则表达式的个数是 100, 当你需要频繁使用少量正则表达式的时候,缓存可以提升效率,而使用的正则表达式过多时,缓存带来的优势就不明显了 (参考 《python re.compile对性能的影响》http://blog.trytofix.com/article/detail/13/), 这个函数的作用是清除缓存中的正则表达式,可能在你需要优化占用内存的时候会用到。
-
- search(pattern, string, flags=0)
函数类似于 match,不同之处在于不限制正则表达式的开始匹配位置
s = '''first line
second line
third line'''
# 需要从开始处匹配 所以匹配不到
print re.match('i\w+', s)
# output> None
# 没有限制起始匹配位置
print re.search('i\w+', s)
# output> <_sre.SRE_Match object at 0x0000000002C6A920>
print re.search('i\w+', s).group()
# output> irst
-
- split(pattern, string, maxsplit=0, flags=0)
参数 maxsplit 指定切分次数, 函数使用给定正则表达式寻找切分字符串位置,返回包含切分后子串的列表,如果匹配不到,则返回包含原字符串的一个列表
s = '''first 111 line
second 222 line
third 333 line'''
# 按照数字切分
print re.split('\d+', s)
# output> ['first ', ' line\nsecond ', ' line\nthird ', ' line']
# \.+ 匹配不到 返回包含自身的列表
print re.split('\.+', s, 1)
# output> ['first 111 line\nsecond 222 line\nthird 333 line']
# maxsplit 参数
print re.split('\d+', s, 1)
# output> ['first ', ' line\nsecond 222 line\nthird 333 line']
-
- sub(pattern, repl, string, count=0, flags=0)
替换函数,将正则表达式 pattern 匹配到的字符串替换为 repl 指定的字符串, 参数 count 用于指定最大替换次数
s = "the sum of 7 and 9 is [7+9]."
# 基本用法 将目标替换为固定字符串
print re.sub('\[7\+9\]', '16', s)
# output> the sum of 7 and 9 is 16.
# 高级用法 1 使用前面匹配的到的内容 \1 代表 pattern 中捕获到的第一个分组的内容
print re.sub('\[(7)\+(9)\]', r'\2\1', s)
# output> the sum of 7 and 9 is 97.
# 高级用法 2 使用函数型 repl 参数, 处理匹配到的 SRE_Match 对象
def replacement(m):
p_str = m.group()
if p_str == '7':
return '77'
if p_str == '9':
return '99'
return ''
print re.sub('\d', replacement, s)
# output> the sum of 77 and 99 is [77+99].
# 高级用法 3 使用函数型 repl 参数, 处理匹配到的 SRE_Match 对象 增加作用域 自动计算
scope = {}
example_string_1 = "the sum of 7 and 9 is [7+9]."
example_string_2 = "[name = 'Mr.Gumby']Hello,[name]"
def replacement(m):
code = m.group(1)
st = ''
try:
st = str(eval(code, scope))
except SyntaxError:
exec code in scope
return st
# 解析: code='7+9'
# str(eval(code, scope))='16'
print re.sub('\[(.+?)\]', replacement, example_string_1)
# output> the sum of 7 and 9 is 16.
# 两次替换
# 解析1: code="name = 'Mr.Gumby'"
# eval(code)
# raise SyntaxError
# exec code in scope
# 在命名空间 scope 中将 "Mr.Gumby" 赋给了变量 name
# 解析2: code="name"
# eval(name) 返回变量 name 的值 Mr.Gumby
print re.sub('\[(.+?)\]', replacement, example_string_2)
# output> Hello,Mr.Gumby
-
- subn(pattern, repl, string, count=0, flags=0)
作用与函数 sub 一样, 唯一不同之处在于返回值为一个元组,第一个值为替换后的字符串,第二个值为发生替换的次数
-
- template(pattern, flags=0)
这个吧,咋一看和 compile 差不多,不过不支持 +、?、*、{} 等这样的元字符,只要是需要有重复功能的元字符,就不支持,查了查资料,貌似没人知道这个函数到底是干嘛的...
四、re 内置对象用法
-
- SRE_Pattern 这个对象是一个编译后的正则表达式,编译后不仅能够复用和提升效率,同时也能够获得一些其他的关于正则表达式的信息
- SRE_Pattern 这个对象是一个编译后的正则表达式,编译后不仅能够复用和提升效率,同时也能够获得一些其他的关于正则表达式的信息
属性:
- flags 编译时指定的模式
- groupindex 以正则表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
- groups 正则表达式中分组的数量
- pattern 编译时用的正则表达式
s = 'Hello, Mr.Gumby : 2016/10/26' p = re.compile('''(?: # 构造一个不捕获分组 用于使用 | (?P<name>\w+\.\w+) # 匹配 Mr.Gumby | # 或 (?P<no>\s+\.\w+) # 一个匹配不到的命名分组 ) .*? # 匹配 : (\d+) # 匹配 2016 ''', re.X) # print p.flags # output> 64 print p.groupindex # output> {'name': 1, 'no': 2} print p.groups # output> 3 print p.pattern # output> (?: # 构造一个不捕获分组 用于使用 | # (?P<name>\w+\.\w+) # 匹配 Mr.Gumby # | # 或 # (?P<no>\s+\.\w+) # 一个匹配不到的命名分组 # ) # .*? # 匹配 : # (\d+) # 匹配 2016
函数:可使用 findall、finditer、match、search、split、sub、subn 等函数
-
- SRE_Match 这个对象会保存本次匹配的结果,包含很多关于匹配过程以及匹配结果的信息
属性:
- endpos 本次搜索结束位置索引
- lastgroup 本次搜索匹配到的最后一个分组的别名
- lastindex 本次搜索匹配到的最后一个分组的索引
- pos 本次搜索开始位置索引
- re 本次搜索使用的 SRE_Pattern 对象
- regs 列表,元素为元组,包含本次搜索匹配到的所有分组的起止位置
- string 本次搜索操作的字符串
s = 'Hello, Mr.Gumby : 2016/10/26'
m = re.search(', (?P<name>\w+\.\w+).*?(\d+)', s)
# 本次搜索的结束位置索引
print m.endpos
# output> 28
# 本次搜索匹配到的最后一个分组的别名
# 本次匹配最后一个分组没有别名
print m.lastgroup
# output> None
# 本次搜索匹配到的最后一个分组的索引
print m.lastindex
# output> 2
# 本次搜索开始位置索引
print m.pos
# output> 0
# 本次搜索使用的 SRE_Pattern 对象
print m.re
# output> <_sre.SRE_Pattern object at 0x000000000277E158>
# 列表,元素为元组,包含本次搜索匹配到的所有分组的起止位置 第一个元组为正则表达式匹配范围
print m.regs
# output> ((7, 22), (7, 15), (18, 22))
# 本次搜索操作的字符串
print m.string
# output> Hello, Mr.Gumby : 2016/10/26
函数:
- end([group=0]) 返回指定分组的结束位置,默认返回正则表达式所匹配到的最后一个字符的索引
- expand(template) 根据模版返回相应的字符串,类似与 sub 函数里面的 repl, 可使用 \1 或者 \g<name> 来选择分组
- group([group1, ...]) 根据提供的索引或名字返回响应分组的内容,默认返回 start() 到 end() 之间的字符串, 提供多个参数将返回一个元组
- groupdict([default=None]) 返回 返回一个包含所有匹配到的命名分组的字典,没有命名的分组不包含在内,key 为组名, value 为匹配到的内容,参数 default 为没有参与本次匹配的命名分组提供默认值
- groups([default=None]) 以元组形式返回每一个分组匹配到的字符串,包括没有参与匹配的分组,其值为 default
- span([group]) 返回指定分组的起止位置组成的元组,默认返回由 start() 和 end() 组成的元组
- start([group]) 返回指定分组的开始位置,默认返回正则表达式所匹配到的第一个字符的索引
s = 'Hello, Mr.Gumby : 2016/10/26' m = re.search('''(?: # 构造一个不捕获分组 用于使用 | (?P<name>\w+\.\w+) # 匹配 Mr.Gumby | # 或 (?P<no>\s+\.\w+) # 一个匹配不到的命名分组 ) .*? # 匹配 : (\d+) # 匹配 2016 ''', s, re.X) # 返回指定分组的结束位置,默认返回正则表达式所匹配到的最后一个字符的索引 print m.end() # output> 22 # 根据模版返回相应的字符串,类似与 sub 函数里面的 repl, 可使用 \1 或者 \g<name> 来选择分组 print m.expand("my name is \\1") # output> my name is Mr.Gumby # 根据提供的索引或名字返回响应分组的内容,默认返回 start() 到 end() 之间的字符串, 提供多个参数将返回一个元组 print m.group() # output> Mr.Gumby : 2016 print m.group(1,2) # output> ('Mr.Gumby', None) # 返回 返回一个包含所有匹配到的命名分组的字典,没有命名的分组不包含在内,key 为组名, value 为匹配到的内容,参数 default 为没有参与本次匹配的命名分组提供默认值 print m.groupdict('default_string') # output> {'name': 'Mr.Gumby', 'no': 'default_string'} # 以元组形式返回每一个分组匹配到的字符串,包括没有参与匹配的分组,其值为 default print m.groups('default_string') # output> ('Mr.Gumby', 'default_string', '2016') # 返回指定分组的起止未知组成的元组,默认返回由 start() 和 end() 组成的元组 print m.span(3) # output> (18, 22) # 返回指定分组的开始位置,默认返回正则表达式所匹配到的第一个字符的索引 print m.start(3) # output> 18
五、分组用法
python 的正则表达式中用小括号 "(" 表示分组,按照每个分组中前半部分出现的顺序 "(" 判定分组的索引,索引从 1 开始,每个分组在访问的时候可以使用索引,也可以使用别名
s = 'Hello, Mr.Gumby : 2016/10/26' p = re.compile("(?P<name>\w+\.\w+).*?(\d+)(?#comment)") m = p.search(s) # 使用别名访问 print m.group('name') # output> Mr.Gumby # 使用分组访问 print m.group(2) # output> 2016
有时候可能只是为了把正则表达式分组,而不需要捕获其中的内容,这时候可以使用非捕获分组
s = 'Hello, Mr.Gumby : 2016/10/26' p = re.compile(""" (?: # 非捕获分组标志 用于使用 | (?P<name>\w+\.\w+) | (\d+/) ) """, re.X) m = p.search(s) # 使用非捕获分组 # 此分组将不计入 SRE_Pattern 的 分组计数 print p.groups # output> 2 # 不计入 SRE_Match 的分组 print m.groups() # output> ('Mr.Gumby', None)
如果你在写正则的时候需要在正则里面重复书写某个表达式,那么你可以使用正则的引用分组功能,需要注意的是引用的不是前面分组的 正则表达式 而是捕获到的 内容,并且引用的分组不算在分组总数中.
s = 'Hello, Mr.Gumby : 2016/2016/26' p = re.compile(""" (?: # 非捕获分组标志 用于使用 | (?P<name>\w+\.\w+) | (\d+/) ) .*?(?P<number>\d+)/(?P=number)/ """, re.X) m = p.search(s) # 使用引用分组 # 此分组将不计入 SRE_Pattern 的 分组计数 print p.groups # output> 3 # 不计入 SRE_Match 的分组 print m.groups() # output> ('Mr.Gumby', None, '2016') # 查看匹配到的字符串 print m.group() # output> Mr.Gumby : 2016/2016/
六、环视用法
环视还有其他的名字,例如 界定、断言、预搜索等,叫法不一。
环视是一种特殊的正则语法,它匹配的不是字符串,而是 位置,其实就是使用正则来说明这个位置的左右应该是什么或者应该不是什么,然后去寻找这个位置。
环视的语法有四种,见第一小节元字符,基本用法如下。
s = 'Hello, Mr.Gumby : 2016/10/26 Hello,r.Gumby : 2016/10/26' # 不加环视限定 print re.compile("(?P<name>\w+\.\w+)").findall(s) # output> ['Mr.Gumby', 'r.Gumby'] # 环视表达式所在位置 左边为 "Hello, " print re.compile("(?<=Hello, )(?P<name>\w+\.\w+)").findall(s) # output> ['Mr.Gumby'] # 环视表达式所在位置 左边不为 "," print re.compile("(?<!,)(?P<name>\w+\.\w+)").findall(s) # output> ['Mr.Gumby'] # 环视表达式所在位置 右边为 "M" print re.compile("(?=M)(?P<name>\w+\.\w+)").findall(s) # output> ['Mr.Gumby'] # 环视表达式所在位置 右边不为 r print re.compile("(?!r)(?P<name>\w+\.\w+)").findall(s) # output> ['Mr.Gumby']
高级一些的例子参见《正则基础之——环视(Lookaround)》(http://www.cnblogs.com/kernel0815/p/3375249.html)
参考文章:
《Python正则表达式指南》(http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html)
《Python 正则式学习笔记 》(http://blog.csdn.net/whycadi/article/details/2011046)