1、正则表达式的作用:匹配一个字符串中的一些内容。(字符串很重要,很久以前有次就把number类型的拿来匹配,就出现过问题啦)。
2、 声明和使用:
复制代码
/*
1.构造函数 var reg = new RegExp(/表达式/)
2.字面量 var reg = /表达式/ 推荐使用
eg: var reg = /abc/ 表示匹配含有abc 的字符串
常用方法:reg.test("要检测的字符串") 返回布尔值
*/
var reg = /abc/;
var result = reg.test('bc');
console.log(result); //false
复制代码
3、开始学习正则
1.简单类 只要含有正则中的内容即可
var reg1 = /abc/;
2.字符类:在正则中使用[]整体表示一位字符,字符串的某一个字符满足中括号中内容的其中一个即可
var reg2 = /[abc]/;
console.log(reg2.test("xyz"));//false
console.log(reg2.test("cdef"));//true 在cdef中含有[abc]中的一个c
3.反向类:在字符类中括号内部最开始写一个^,表示反向
var reg3 = /[^abc]/; // 字符串中含有除了abc以外的任意字符即可返回true
console.log(reg3.test("abc"));//false
console.log(reg3.test('cdef')); // true
4.范围类
复制代码
var reg4 = /[abcdefghigklmnopqrst]/;
var reg4 = /[a-t]/;//可以匹配到a到t之间的任意一个字符
console.log(reg4.test("uwy"));//false
console.log(reg4.test("guwy"));//true
//想要匹配所有的小写字母 //var reg = /[a-z]/;
//想要匹配所有的大写字母 var reg = /[A-Z]/;
//想要匹配所有的数字 var reg = /[0-9]/
复制代码
5.组合类
复制代码
var reg5 = /[0-9a-z]/;
console.log(reg5.test("AAAAAAAAAA"));//false
console.log(reg5.test("AAAAA0AAAAA"));//true
console.log(reg5.test("AAAAAaAAAAA"));//true
var reg = /[A-Z0-9a-z]/;
console.log(reg5.test("AAAAAAAAAA"));//true
console.log(reg5.test("012323"));//true
console.log(reg5.test("aaaaaa"));//true
复制代码
6.预定义类 意思就是正则提供了相应的api来简化写法
复制代码
var reg6 = /\d/;// /[0-9]/;
/*
. 匹配除换行符以外的任意字符
\w 单词字符(所有的字母数字和_) word
\W [^a-zA-Z0-9_] 非单词字符
\s 匹配任意的空白符 space
\S [^\f\r\n\t\v] 可见字符
\d 匹配数字 digit
\D [^0-9] 非数字字符
\b 匹配单词的开始或结束
*/
复制代码
7.字符转义:(常用的)
/*
如果使用元字符本身,需转义如. *
. * \
*/
8. 或者 | 括号 () 提升优先级,先计算
var reg8 = /abc|bcd/;
console.log(reg8.test("ab"));//false
console.log(reg8.test("abc"));//true
console.log(reg8.test("bcd"));//true
var reg8 = /a|b|c|d/;//如果使用单个字符,与后面的作用相同 [abcd]
9. ^ 匹配字符串的开始 $ 匹配字符串的结束
( ^ 在中括号外使用,写在正则最前面时,表示匹配开头,一个正则中只能使用一次)
var reg = /^abc/;
console.log(reg.test("abcdefg")); //true
console.log(reg.test("aabcdefg"));//false
($ 写在正则最后位置,表示以xxx结束)
var reg9 = /abc$/;
console.log(reg9.test("ddddabc"));//true
console.log(reg9.test("ddddaabbc"));//false
^和$同时使用 严格匹配-必须跟书写的正则内容完全相同
var reg = /^abc$/;
console.log(reg.test("abc"));//true
console.log(reg.test("abcabc"));//false
10.量词 //使用量词,表示数量
大括号中书写一个数值。表示出现的次数
var reg = /^a{3}$/;
console.log(reg.test("aa"));//false
console.log(reg.test("aaa"));//true
console.log(reg.test("aaaa"));//false
匹配2-5个
var reg = /^a{2,5}$/;
console.log(reg.test("a"));//false
console.log(reg.test("aa"));//true
console.log(reg.test("aaaaaa"));//false
匹配至少3个
var reg = /^a{3,}$/;
console.log(reg.test("aa"));//false
console.log(reg.test("aaa"));//true
console.log(reg.test("aaaa"));//true
* 匹配0-多个 当字符串中某一个部分可选时,使用*
var reg = /^a*$/;
console.log(reg.test(""));//true
console.log(reg.test("a"));//true
console.log(reg.test("aaaa"));//true
+ 匹配1个到多个
var reg = /^a+$/;
console.log(reg.test(""));//false
console.log(reg.test("a"));//true
console.log(reg.test("aaaa"));//true
? 匹配0个或1个
var reg = /^a?$/;
console.log(reg.test(""));//true
console.log(reg.test("a"));//true
console.log(reg.test("aaaa"));//false
四、replace 和匹配模式
复制代码
var str = "abca";
//第一个参数可以使用字符串,同样可以使用正则表达式
console.log(str.replace("a", "z")); //zbca
// 匹配模式
// g - global 全局匹配
//i - ignoreCase 忽略大小写
console.log(str.replace(/a/ig, "z"));//zbcz
//trim是字符串方法
var str = " a a ";
console.log(str.trim());
var str = " a a ";
// \s 不可见字符
console.log(str.replace(/\s/g, ""));//替换掉所有的空格aa
console.log(str.replace(/^\s+|\s+$/g, ""));//替换掉两端的空格a a
// 自己的trim方法
function Trim(str) {
return str.replace(/^\s+|\s+$/g, "");
}
复制代码
五、正则提取 match
复制代码
//1. 字符串方法 match
var str = "aaa123hhh456hhh789aaa";
//提取出字符串中的数字
console.log(str.match(/\d{3}/)); //提取第一个匹配到的值["123", index: 3, input: "aaa123hhh456hhh789aaa"]
console.log(str.match(/\d{3}/g)); //提取所有的内容时,不会有index和input属性字 ["123", "456", "789"]
var str = "//小明:谢谢大神,我得邮箱是xiaoming@qq.com,哈哈小红:谢谢大神,我得邮箱是xiaohong@qq.com,哈哈李雷:
谢谢大神,我得邮箱是lilei@163.com,哈哈韩梅梅:谢谢大神,我得邮箱是hanmeimei@126.com,哈哈";
console.log(str.match(/\w+@\w+.\w+/g));
// 解析一下:@ 符号前面有一个或多个单词,后同理,. 点 “.”的转义 点后也是一个单词 g 全局匹配
//["xiaoming@qq.com", "xiaohong@qq.com", "lilei@163.com", "hanmeimei@126.com"]
复制代码
复制代码
// 2.exec 分组提取
//正则.exec(字符串);
//正则.exec(字符串);
var reg = /\w+@\w+\.\w+/g;
//通过同一个正则表达式多次处理一个字符串,可以多次提取出匹配到的内容以及起始位置索引值
//匹配不到时返回null
console.log(reg.exec(str));
var result;
while ((result = reg.exec(str)) != null) {
console.log("邮箱是:" + result + ",起始索引值为" + result.index);
}
var reg = /(\w+)@(\w+(?:\.\w+)+)/g;
//使用()可以在正则表达式中进行分组,从左往右,第一个( 表示组1
//如果不想提取出某个组的内容,可以在这个组开始的(贴着的后面加上 ?:
var result;
while ((result = reg.exec(str)) != null) {
console.log("邮箱是:" + result[0]+"用户名是:"
+result[1]+"域名是:"
+result[2]);
https://console.log(result);
}
/(?
//(?:exp) 匹配exp,不捕获匹配的文本,也不给此分组分配组号
零宽断言 (?=exp) 匹配exp前面的位置
(?<=exp) 匹配exp后面的位置
(?!exp) 匹配后面跟的不是exp的位置
(?<!exp) 匹配前面不是exp的位置
注释 (?#comment) 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读
复制代码
以下是收集于网络中的常用正则表达式:
一、校验数字的表达式
1 数字:[1]$
2 n位的数字:^\d{n}$
3 至少n位的数字:^\d{n,}$
4 m-n位的数字:^\d{m,n}$
5 零和非零开头的数字:^(0|[1-9][0-9])$
6 非零开头的最多带两位小数的数字:^([1-9][0-9])+(.[0-9]{1,2})?$
7 带1-2位小数的正数或负数:^(-)?\d+(.\d{1,2})?$
8 正数、负数、和小数:^(-|+)?\d+(.\d+)?$
9 有两位小数的正实数:[2]+(.[0-9]{2})?$
10 有1~3位小数的正实数:[3]+(.[0-9]{1,3})?$
11 非零的正整数:[4]\d$ 或 ^([1-9][0-9]){1,3}$ 或 ^+?[1-9][0-9]$
12 非零的负整数:^-[1-9][]0-9"$ 或 ^-[1-9]\d$
13 非负整数:^\d+$ 或 [5]\d|0$
14 非正整数:^-[1-9]\d|0$ 或 ^((-\d+)|(0+))$
15 非负浮点数:^\d+(.\d+)?$ 或 [6]\d.\d|0.\d[1-9]\d|0?.0+|0$
16 非正浮点数:^((-\d+(.\d+)?)|(0+(.0+)?))$ 或 ^(-([1-9]\d.\d|0.\d[1-9]\d))|0?.0+|0$
17 正浮点数:[7]\d.\d|0.\d[1-9]\d$ 或 ^(([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9]))$
18 负浮点数:^-([1-9]\d.\d|0.\d[1-9]\d)$ 或 ^(-(([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9])))$
19 浮点数:^(-?\d+)(.\d+)?$ 或 ^-?([1-9]\d.\d|0.\d[1-9]\d|0?.0+|0)$
二、校验字符的表达式
1 汉字:[8]{0,}$
2 英文和数字:[9]+$ 或 [10]{4,40}$
3 长度为3-20的所有字符:^.{3,20}$
4 由26个英文字母组成的字符串:[11]+$
5 由26个大写英文字母组成的字符串:[12]+$
6 由26个小写英文字母组成的字符串:[13]+$
7 由数字和26个英文字母组成的字符串:[14]+$
8 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9 中文、英文、数字包括下划线:[15]+$
10 中文、英文、数字但不包括下划线等符号:[16]+$ 或 [17]{2,20}$
11 可以输入含有%&',;=?$"等字符:[%&',;=?$\x22]+
12 禁止输入含有的字符:[^\x22]+
三、特殊需求表达式
1 Email地址:^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)$
2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3 InternetURL:[a-zA-z]+://[^\s] 或 ^http://([\w-]+.)+[\w-]+(/[\w-./?%&=])?$
4 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^((\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7 身份证号(15位、18位数字):^\d{15}|\d{18}$
8 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
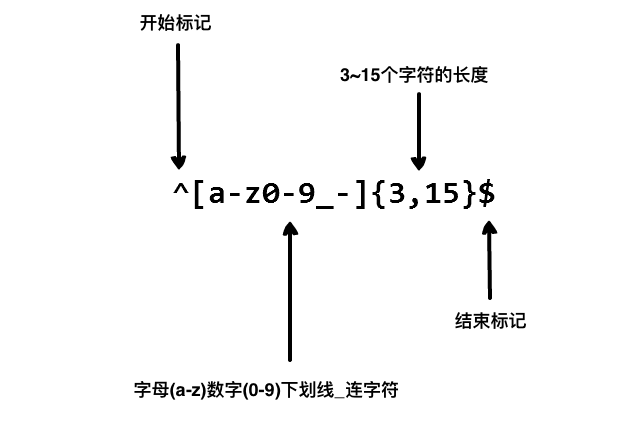
9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):[18][a-zA-Z0-9_]{4,15}$
10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):[19]\w{5,17}$
11 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.\d)(?=.[a-z])(?=.[A-Z]).{8,10}$
12 日期格式:^\d{4}-\d{1,2}-\d{1,2}
13 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
14 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
15 钱的输入格式:
16 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":[20][0-9]$
17 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9])$
18 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9])$
19 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:[21]+(.[0-9]+)?$
20 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:[22]+(.[0-9]{2})?$
21 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:[23]+(.[0-9]{1,2})?$
22 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:[24]{1,3}(,[0-9]{3})(.[0-9]{1,2})?$
23 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3}))(.[0-9]{1,2})?$
24 备注:这就是最终结果了,别忘了"+"可以用""替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
25 xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\.[x|X][m|M][l|L]$
26 中文字符的正则表达式:[\u4e00-\u9fa5]
27 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
28 空白行的正则表达式:\n\s\r (可以用来删除空白行)
29 HTML标记的正则表达式:<(\S?)[^>]>.?</\1>|<.? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
30 首尾空白字符的正则表达式:\s*|\s*$或(\s)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
33 IP地址:\d+.\d+.\d+.\d+ (提取IP地址时有用)
34 IP地址:((??:25[0-5]|2[0-4]\d|[01]?\d?\d)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d?\d))
1 . 校验密码强度
密码的强度必须是包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.\d)(?=.[a-z])(?=.*[A-Z]).{8,10}$
2. 校验中文
字符串仅能是中文。
[25]{0,}$
3. 由数字、26个英文字母或下划线组成的字符串
^\w+$
4. 校验E-Mail 地址
同密码一样,下面是E-mail地址合规性的正则检查语句。
[\w!#$%&'+/=?^_{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_~-]+)@(?:\w?\.)+\w?
5. 校验身份证号码
下面是身份证号码的正则校验。15 或 18位。
15位:
[26]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$
18位:
[27]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$
6. 校验日期
“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。
^(??!0000)[0-9]{4}-(??:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7. 校验金额
金额校验,精确到2位小数。
[28]+(.[0-9]{2})?$
8. 校验手机号
下面是国内 13、15、18开头的手机号正则表达式。(可根据目前国内收集号扩展前两位开头号码)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
9. 判断IE的版本
IE目前还没被完全取代,很多页面还是需要做版本兼容,下面是IE版本检查的表达式。
^.MSIE 5-8?(?!.Trident\/[5-9]\.0).*$
10. 校验IP-v4地址
IP4 正则语句。
\b(??:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b
11. 校验IP-v6地址
IP6 正则语句。
(([0-9a-fA-F]{1,4}{7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}{1,7}([0-9a-fA-F]{1,4}{1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}{1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}{1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}{1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}{1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}(:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}{0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}{1,4}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12. 检查URL的前缀
应用开发中很多时候需要区分请求是HTTPS还是HTTP,通过下面的表达式可以取出一个url的前缀然后再逻辑判断。
if (!s.match(/[29]+:\/\//))
{
s = 'http://' + s;
}
13. 提取URL链接
下面的这个表达式可以筛选出一段文本中的URL。
^(f|ht){1}(tp|tps):\/\/([\w-]+\.)+[\w-]+(\/[\w- ./?%&=]*)?
14. 文件路径及扩展名校验
验证windows下文件路径和扩展名(下面的例子中为.txt文件)
([a-zA-Z]\\\)\\([\\]+\\)[^\/:?"<>|]+\.txt(l)?$
15. 提取Color Hex Codes
有时需要抽取网页中的颜色代码,可以使用下面的表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16. 提取网页图片
假若你想提取网页中所有图片信息,可以利用下面的表达式。
\< [img][^\\>][src] *= [\"\']{0,1}([^\"\'\ >])
17. 提取页面超链接
提取html中的超链接。
(<a\s(?!.\brel=)[^>])(href="https?:\/\/)((?!(??:www\.)?'.implode('|(?:www\.)?', $follow_list).'))["]+)"((?!.*\brel=)[>])(?:[^>]*)>
18. 查找CSS属性
通过下面的表达式,可以搜索到相匹配的CSS属性。
^\s[a-zA-Z\-]+\s[:]{1}\s[a-zA-Z0-9\s.#]+[;]{1}
19. 抽取注释
如果你需要移除HMTL中的注释,可以使用如下的表达式。
- 匹配HTML标签
通过下面的表达式可以匹配出HTML中的标签属性。
<\/?\w+((\s+\w+(\s=\s(?:".?"|'.?'|[\^'">\s]+))?)+\s|\s)\/?>
0-9 ↩︎
0-9 ↩︎
0-9 ↩︎
1-9 ↩︎
1-9 ↩︎
1-9 ↩︎
1-9 ↩︎
\u4e00-\u9fa5 ↩︎
A-Za-z0-9 ↩︎
A-Za-z0-9 ↩︎
A-Za-z ↩︎
A-Z ↩︎
a-z ↩︎
A-Za-z0-9 ↩︎
\u4E00-\u9FA5A-Za-z0-9_ ↩︎
\u4E00-\u9FA5A-Za-z0-9 ↩︎
\u4E00-\u9FA5A-Za-z0-9 ↩︎
a-zA-Z ↩︎
a-zA-Z ↩︎
1-9 ↩︎
0-9 ↩︎
0-9 ↩︎
0-9 ↩︎
0-9 ↩︎
\u4e00-\u9fa5 ↩︎
1-9 ↩︎
1-9 ↩︎
0-9 ↩︎
a-zA-Z ↩︎