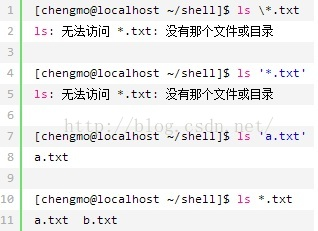
简介:
用一些特殊的符号来帮你去字符串中筛选出对应的符合条件的内容
正则表达式是一门独立的语言,所有的编程语言中都可以使用
^(13|14|15|18)[0-9]{9}$
正则表达式筛选数据比逻辑代码要来的方便的多
在python中如果你想要使用正则表达式的话需要导入内置的re模块
字符组的概念:
[0-9a-zA-Z]
特殊符号
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线
\d 匹配数字
^ 匹配字符串的开始
$ 匹配字符串的结尾
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[^...] 匹配除了字符组中字符的所有字符
量词 量词必须跟在正则表达式符号后面 不能单独出现
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
方式:
贪婪匹配
正则表达式默认都是贪婪匹配的
就是尽可能多的匹配内容
.*
非贪婪匹配
只需要在原有的正则表达式后面加一个问号就可以
将贪婪匹配变成非贪婪匹配
.*?
匹配身份证号码的正则表达式
"""
常见的正则表达式网络上都有现成的答案 你大可不必自己重复造轮子
^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$
/^1[3-9]\d{9}$/
"""
取消转义
方式1 在原来的斜杠前面再加一个斜杠
方式2 直接在最外层加一个字母小r
使用:
import re
res = 'asdFasVjo21T3kjAYokj213j1\nYkj3kjkGj 是多K_K久UU啊看oa'
# res1 = re.findall('[0123456789]',res)
# 简写
# res1 = re.findall('[0-9]',res)
# print(res1) # ['2', '1', '3', '2', '1', '3', '1', '3']
# 挨个比对是否满足正则表达式
# res1 = re.findall('[a-z]',res) # ['a', 's', 'd', 'a', 's', 'j', 'k', 'j', 'k', 'j', 'j', 'k', 'j', 'k', 'j', 'k', 'j']
# res1 = re.findall('[A-Z]',res) # ['F', 'V', 'T', 'A', 'Y', 'Y', 'G', 'K', 'K', 'U', 'U']
# res1 = re.findall('[0-9a-zA-Z]',res) # ['a', 's', 'd', 'F', 'a', 's', 'V', 'j', '2', '1', 'T', '3', 'k', 'j', 'A', 'Y', 'k', 'j', '2', '1', '3', 'j', '1', 'Y', 'k', 'j', '3', 'k', 'j', 'k', 'G', 'j', 'K', 'K', 'U', 'U']
# print(res1)
# res1 = re.findall('.',res)
# res1 = re.findall('^as',res)
# res1 = re.findall('o$',res)
# res1 = re.findall('[^a]',res)
#
# print(res1)
# res1 = re.findall('海.','海燕海娇海东')
# res1 = re.findall('^海.','海燕海娇海东') # ['海燕']
# res1 = re.findall('海.$','海燕海娇海东') # ['海东']
# res1 = re.findall('李.?','李杰和李莲英和李二棍子') # ['李杰', '李莲', '李二']
# res1 = re.findall('李.','李杰和李莲英和李二棍子') # ['李杰', '李莲', '李二']
# res1 = re.findall('李.*','李杰和李莲英和李二棍子') # ['李杰和李莲英和李二棍子']
# res1 = re.findall('李.+','李杰和李莲英和李二棍子') # ['李杰和李莲英和李二棍子']
# res1 = re.findall('李.{1,2}','李杰和李莲英和李二棍子') # ['李杰和', '李莲英', '李二棍']
# 贪婪匹配
# res1 = re.findall('李.*?','李杰和李莲英和李二棍子')
# print(res1)
# res1 = '<script>123</script>'
# # ret = re.findall('<.*>',res1) # 贪婪匹配只认准最后一个>才会结束 ['<script>123</script>']
# ret = re.findall('<.*?>',res1) # ['<script>', '</script>']
# print(ret)
# res1 = re.findall('[\d]','456bdha3')
# res1 = re.findall('[\d]+','456bdha3') # ['456', '3']
# res1 = re.findall(r'\d+\n','456bdha3') # ['456', '3']
# print(res1)
# 分组优先
import re
# 分组优先展示
# ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
# print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
# 取消分组优先展示
# ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
# print(ret)
# ret = re.search('a', 'eva egon yuan')
# if ret:
# print(ret.group()) # a
"""
search匹配到内容会返回一个对象 <_sre.SRE_Match object; span=(2, 3), match='a'>
只要获取到一个符合正则表达式的内容就会停止不再往后匹配了
如果没有匹配对应的数据那么会直接返回None
"""
# ret = re.match('a', 'eva egon yuan')
# print(ret)
# if ret:
# print(ret.group())
"""
match只会从头开始匹配内容
如果不符合直接返回None
如果开头匹配上了 跟search一样
"""
# search和match没有分组优先展示一说
# res1 = re.search('www.(baidu|oldboy).com', 'www.oldboy.com')
# print(res1.group(0)) # www.oldboy.com
# print(res1.group(1)) # oldboy
# 可以给正则表达式起别名 固定句式 ?P<别名>
# res1 = re.search('www.(?P<jason>baidu|oldboy).com', 'www.oldboy.com')
# print(res1.group()) # www.oldboy.com
# print(res1.group('jason')) # oldboy