一:
正则在Perl、Py森、Ruby、Java等语言中文本的正则表达式几乎是一样的
以前常用到的在网上都有现成的例子拿来用,比如电话格式、邮箱格式之类的。
但是自然语言处理中往往会根据自己的需求来制定一个表达式,如果正则的知识掌握的比较片面,在编写自然语言处理程序时可能会觉得苦恼。
在《自然语言处理简明教程》里面有很系统的正则表达式教程,特意总结出来消化吸收。
二:
- 双斜线“//”
最简单的正则表达式就是这样的,由类似于/hello world /的正则来搜索语料库中包含子字符串“hello world”的任何字符串相匹配。/e/是可以匹配到字符串hello的。
- 中括号“[]”
[]会匹配其中的某一个字符。比如现在有嫌疑人,我们只知道他的名字可能是下面三种的某一种,分别是张伟、李伟或者黄伟。就可以使用/[张李黄]伟/来在人口数据库中匹配。
|
正则 |
匹配 |
模式例子 |
|
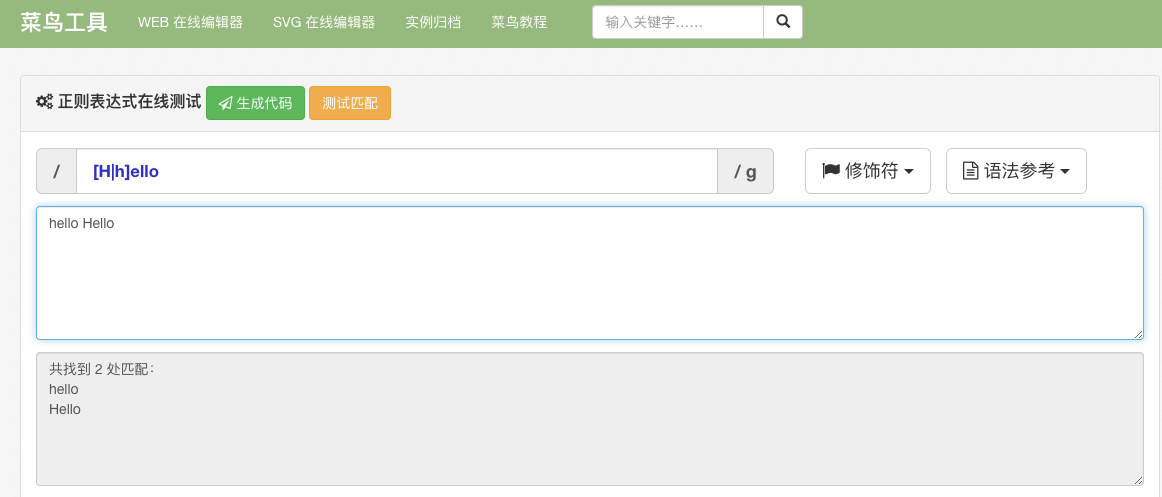
/[hH]/ello/
/[abc]/
/[1234567890]/ |
hello or Hello
‘a’或者’b’或者’c’
数字 |
“Hello!”
“happy~”
“1993年” |
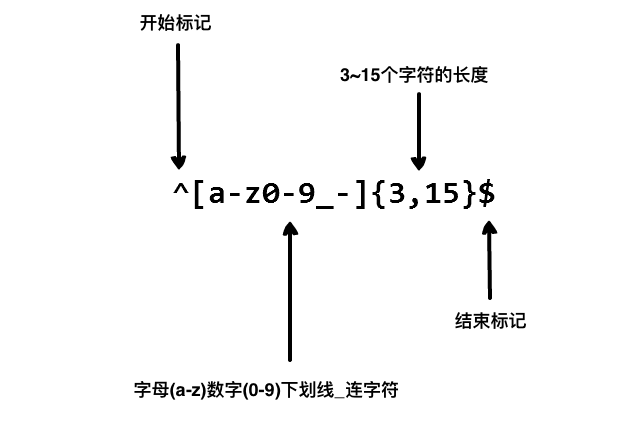
- {}表示限制长度。如:.{1}表示匹配一个任意字符
- 连字符“-”
用来划定范围,表示某一范围内的任何字符。比如上个例子里面的/[1234567890]/是不是感觉很不方便。如果表示为/[0-9]/就会显得精简的多。
|
正则 |
匹配 |
模式例子 |
|
/[A-Z]/
/[a-z]/
/[0-9]/ |
大写字母
小写字母
数字 |
“Hello!”
“happy~”
“1993年” |
- 脱字符“^”
如果在方括号之后有脱字符“^”,对应的模式就是否定的。
|
正则 |
匹配 |
模式例子 |
|
/[^A-Z]/
/[^aA]/
/[0-9]/ |
非大写字母
既不是a也不是A
数字 |
“Hello!”
“happy~”
“1993年” |
- 问号“?”
比如我们在语料库中搜索诗人“李白”或者“李太白”,此时方括号就无法帮助我们,因为[]只能表示xx或者XX,但是不能表示有xx或者没xx。此时可以用“?”来表示前一个字符有或者无。
|
正则 |
匹配 |
|
/李太?白/
/times?/ |
“李白”或者“李太白”
time或者times |
- “Kleene*”
当正则表达式用来表示重复的字符时,比如在下载文件时,出现了下面的下载进度:
99.9%
99.99%
99.999%
99.9999%
……
此时我们可以用/9*/来表示重复了“0或者若干次”的字符“9”,因此想表示出现了一次或者多次的“9”,需要用/99*/。
因此/99\.99*%/可以用来表示上述进度条。(此处的“.”需要转译,因为我们不想让他表示为通配符)
稍微复杂点:
/[10]*/可以用来表示一个二进制串,比如“1010100001110001”
- “Kleene+”
但是我用/99*/来表示重复了“0或者若干次”的字符“9”时总觉得多写了一个“9”很不爽,这时有没有办法帮我们省掉多打一个“9”的时间呢?
/9+/就可以了~
因此使用/[10]+/来搜索语料中的二进制字符串看起来更顺手
- 通配符“.”
哎那个马什么民,帮我把袜子洗一下。
这样说话是很不礼貌的,但是当我们确实忘了别人名字时怎么办呢?
正则表达式同样可以解决这个问题。
正则里面有一个点号,通配符(/./)可以表示任何字符。
/马.民/可以在你的班级花名册里面搜索到所有叫“马X民”的人。
|
正则 |
匹配 |
模式例子 |
|
/[beg.n]/
|
beg和n中包含一个字符的字符串 |
begin,beg‘n,begun |
当/./和/*/或者/+/碰到时,什么神奇的事情会发生呢?
比如我们想知道有一天 马X民对黄伟做了什么事情,怎么写正则来在班级日志里面缩小搜索范围呢?
/马.民.+黄伟/就可以表示在一个长字符串里面,符合马X民bulabula黄伟的句子。
- 锚号“^”和“$”
顾名思义,锚号是用来把正则“锚”在字符串的特定位置的。最普通的锚号是“^”和“$”,当“^”用作锚号的时候,表示一行的开始。比如/^The/就表示单词The必须出现在一句话的开头。相反“$”表示一行的结尾。
回到上面的例子,比如我们想在班级日志里面找到“马兴民xxx黄伟。”这样的句子,就可以使用锚号来定位。/^马兴民.+黄伟。$/
- 词界“\b”“\B”
\b表示词界,\B表示非词界。
首先,在计算机语言里面,什么是一个词呢。从技术上说,词被定义为数字、下划线、或者字母的任何序列。
比如我们在搜索单词“a”的时候,如果仅仅用/a/,同样会匹配到类似于“happy”这样的单词,但是如果用/\ba\b/的话,就会只找到单词a。比如“I am a handsome man.”
它仅仅会匹配到单词“a”而非“am”。
- 析取符“|”
析取符表示或者。
前面有个小伙子很眼熟,我记得他的名字叫马兴民或者黄伟。现在我打开在线班级花名册,输入正则/黄伟|马兴民/,一下就找到了两个人的信息和照片,一看哦都不是。
析取符就是用来表示或者,/a|b/表示a或者b。
在英文语料中,有时候会出现名词的复数形式比如cat和cats,这种形式我们很容易表达。但是有些复数比如family的复数families该如何表达呢。
首先famil串已经是固定的了,这时我们只需要尾串跟上y或者ies即可,此时我们使用圆括号运算符(),将一个模式括起来,使得它就像一个单独的字符。因此如果我们想找到语料中的family和families时,需要用/famil(y|ies)/,析取符仅仅运用于后缀y或者ies。
三:
- 通用字符集的替换
|
正则 |
扩充表达式 |
匹配 |
|
\d \D \w \W \s \S |
[0-9] [^0-9] [a-zA-Z0-9] [^\w] [_\r\t\n\f] [^\s] |
数字字符 非数字字符 数字字母下划线 相反 表格,换行等空白区域 非空白区域 |
-
计数符
|
正则 |
匹配 |
|
* + ? {n} {n,m} {n,} |
零或多 一或多 零或一 出现n次 n到m次 至少n次 |
- ? 贪婪模式与非贪婪模式
比如在HTML中有许多标签<div>part1</div><div>part2</div><div>part3</div><div>part4</div>
使用<div>.*</div>匹配到的是:<div>part1</div><div>part2</div><div>part3</div><div>part4</div>,此时为贪婪模式。
使用<div>.*?</div>匹配到的是:<div>part1</div>
- (?<=exp) (?=exp)零宽断言
(?<=exp) 表示匹配exp之后的,(?=exp)表示匹配exp之前的。
比如上面标签例子:<div>part1</div><div>part2</div><div>part3</div><div>part4</div>
如果我们仅仅想拿到标签里面的内容,就可以使用零宽断言:
(?<=<div>).*(?=</div>)此时匹配到:part1</div><div>part2</div><div>part3</div><div>part4
结合上面的零宽断言:
(?<=<div>).*?(?=</div>)此时匹配到:part1 part2 part3 part4
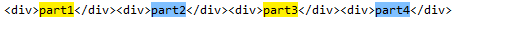
- 一个开发思路的例子
当我们想在语料中查找英语冠词the的时候,随手写下正则/the/。
但是随后发现有些地方是不完善的,比如当the出现在开头的时候,就是The,因此我们把正则改成/[tT]he/。
此时这个正则还是不完善的,因为它会找到诸如There,other这样的单词,因此我们给它加上了词界/\b[tT]he\b/。
问题又来了,假如我们不想把下划线和数字作为词界,我们还希望能够找到形如 _the,the99这样的词。此时我们需要给the的两段加上限制:不能为字母。于是正则变成了/[^a-zA-Z][tT]he[^a-zA-Z]/。
万事大吉了吗?这时候我们发现,当the出现在开头的时候,正则找不到它,因为我们规定了the的开头必须有一个非英文字符,因此我们需要修改开头为,the出现在开头或者开头有一个非英文字符。即/(^"[^a-zA-Z])[tT]he[^a-zA-Z]/。
终于到这里,一个符合要求的简单的定冠词the被搜索了出来。
平时书写正则的时候也要注意,提升准确率,提升覆盖率。
- 第二个例子
- 附上一个正则符号表
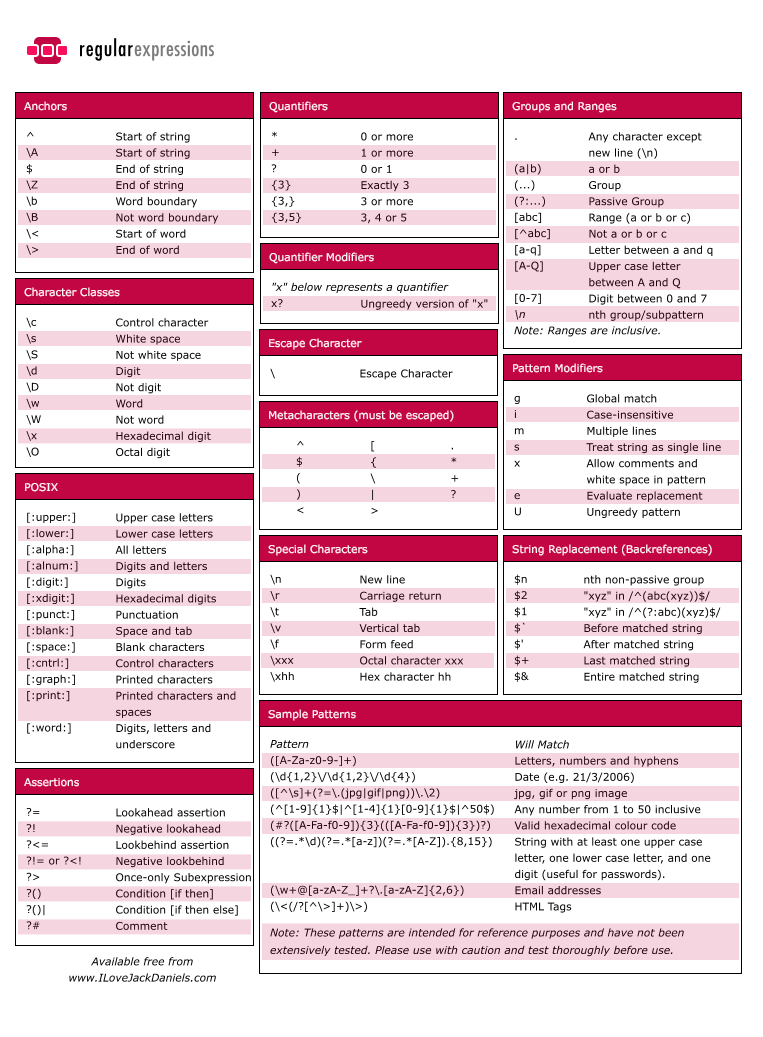
图片出处: