开发过程中的真实场景
A报文
开发过程中的真实场景
A报文
<?xml version="1.0" encoding="utf-8"?> <PACKET> <HEAD> <SERVICE_NAME>seeYou</SERVICE_NAME> </HEAD> <BODY> <CONTENT> <![CDATA[ <?xml version="1.0" encoding="utf-8"?> <PACKET> <![CDATA[ nice to meet you! ]]> </PACKET> ]]> </CONTENT> </BODY> </PACKET>
嵌套在A报文中的B报文
<?xml version="1.0" encoding="utf-8"?> <PACKET> <![CDATA[ nice to meet you! ]]> </PACKET>
场景
我得到A报文,后需要解析提取B报文转发给目标系统.
而现有解析代码PatternTool.java如下:
package kingtool; import java.util.regex.Matcher; import java.util.regex.Pattern; public class PatternTool { /** * 从regex表达式中提供对应的值 * @author King */ public static String parsePattern(String regex, String content ,int groupNum) { String ret = ""; String str = ""; String output =""; try { Pattern p = Pattern.compile(regex); Matcher m = p.matcher(content); if (m.find()) { for(int i = 0 ; i <= m.groupCount() ; i ++){ if(i == 0){ }else{ str = m.group(i); output = String.format("解析得正则表达式%s中group(%d)匹配的值\n",regex,i); System.out.println(output); System.out.println(str); } } ret = m.group(groupNum); System.out.println("返回第"+groupNum+"组匹配到的内容:\n"+ret); }else{ System.out.println("未解析到正则表达式"+regex+"匹配的的值\n"); } } catch (Exception e) { e.printStackTrace(); } return ret; } public static void main(String[] args) { String content = FileTool.readStringFromFile("D://c.txt", "GBK" ); //希望匹配<CONTENT>.*<![CDATA[.*]]>.*</CONTENT> String regex = "<CONTENT>(.*)<!\\[CDATA\\[(.*)\\]\\]>(.*)</CONTENT>"; String ret = parsePattern(regex,content,2); } }
解析后,打印结果如下(并非最终想要的B报文):
文件 D://c.txt存在与否?: true 读到的文件内容如下: <?xml version="1.0" encoding="utf-8"?><PACKET> <HEAD> <SERVICE_NAME>seeYou</SERVICE_NAME> </HEAD> <BODY> <CONTENT> <![CDATA[ <?xml version="1.0" encoding="utf-8"?> <PACKET> <![CDATA[ nice to meet you! ]]> </PACKET> ]]> </CONTENT> </BODY></PACKET> 解析得正则表达式<CONTENT>(.*)<!\[CDATA\[(.*)\]\]>(.*)</CONTENT>中group(1)匹配的值 <![CDATA[ <?xml version="1.0" encoding="utf-8"?> <PACKET> 解析得正则表达式<CONTENT>(.*)<!\[CDATA\[(.*)\]\]>(.*)</CONTENT>中group(2)匹配的值 nice to meet you! ]]> </PACKET> 解析得正则表达式<CONTENT>(.*)<!\[CDATA\[(.*)\]\]>(.*)</CONTENT>中group(3)匹配的值 返回第3组匹配到的内容:
现在来分析以上原因:
1.因为正则默认是贪婪的(全取模式,能吃多少是多少),所以第一个(.*)先取
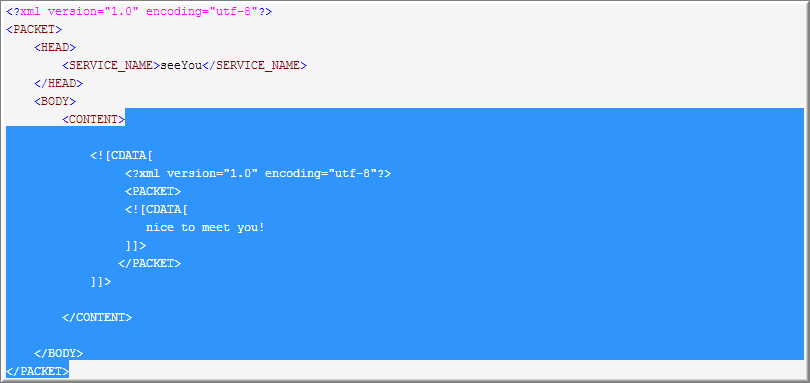
然后一点一点从尾部吐出来,直到匹配(<!\[CDATA\[(.*)\]\]>)就停止吐字符,至此 group(1) 匹配结束.
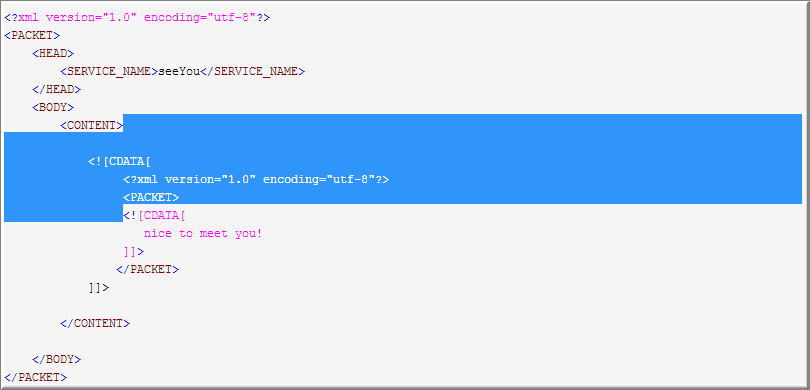
2. 现在来匹配第二个(.*),老规矩先全取
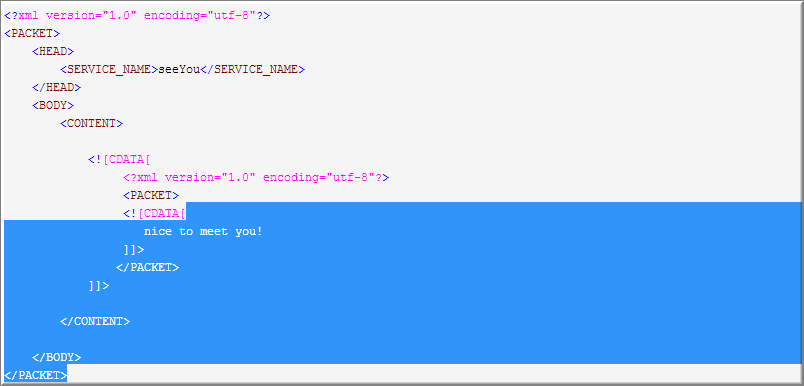
然后一个一个吐字符,直到遇到]]>
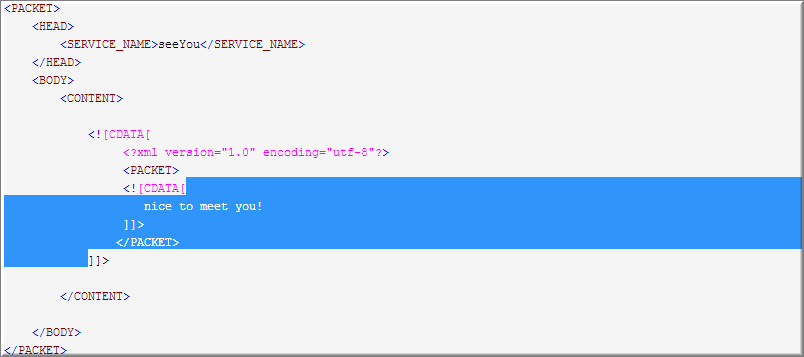
3. 最后来匹配第三个(.*),老规矩先全取
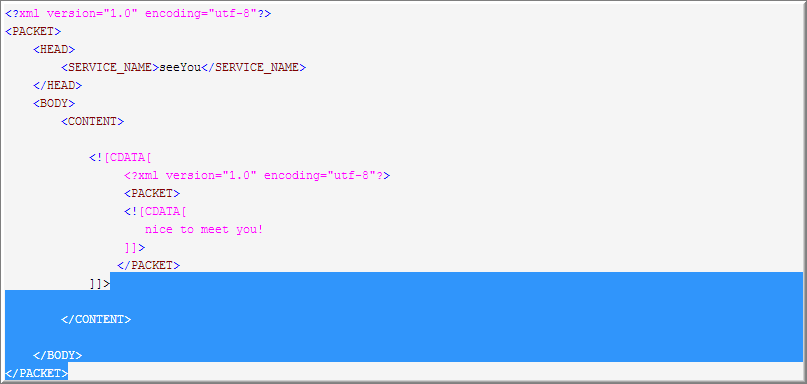
直到遇到</CONTENT>停下
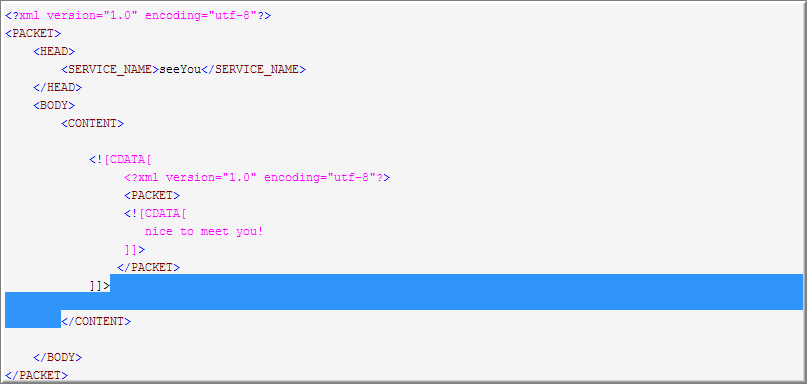
最终,这完全不是我们希望看到的匹配结果 nice to meet you! ]]> </PACKET>
解决方案: 加个?变成懒猫 lazy 模式即可
把PatternTool.java中main主函数的正则匹配式regex中的第一个括号中加一个?,变成懒猫 lazy 模式 ,即 (.*?)
public static void main(String[] args) { String content = FileTool.readStringFromFile("D://c.txt", "GBK" ); //希望匹配<CONTENT>.*<![CDATA[.*]]>.*</CONTENT> String regex = "<CONTENT>(.*?)<!\\[CDATA\\[(.*)\\]\\]>(.*)</CONTENT>"; String ret = parsePattern(regex,content,2); }
解析后,打印结果如下(是最终想要的B报文):
文件 D://c.txt存在与否?: true 读到的文件内容如下: <?xml version="1.0" encoding="utf-8"?><PACKET> <HEAD> <SERVICE_NAME>seeYou</SERVICE_NAME> </HEAD> <BODY> <CONTENT> <![CDATA[ <?xml version="1.0" encoding="utf-8"?> <PACKET> <![CDATA[ nice to meet you! ]]> </PACKET> ]]> </CONTENT> </BODY></PACKET> 解析得正则表达式<CONTENT>(.*?)<!\[CDATA\[(.*)\]\]>(.*)</CONTENT>中group(1)匹配的值 解析得正则表达式<CONTENT>(.*?)<!\[CDATA\[(.*)\]\]>(.*)</CONTENT>中group(2)匹配的值 <?xml version="1.0" encoding="utf-8"?> <PACKET> <![CDATA[ nice to meet you! ]]> </PACKET> 解析得正则表达式<CONTENT>(.*?)<!\[CDATA\[(.*)\]\]>(.*)</CONTENT>中group(3)匹配的值 返回第2组匹配到的内容: <?xml version="1.0" encoding="utf-8"?> <PACKET> <![CDATA[ nice to meet you! ]]> </PACKET>
现在来分析以上原因:
1.因为加了?后,正则变成了懒猫 lazy 模式(特别地懒,能不吃就不吃),所以第一个(.*?)先取
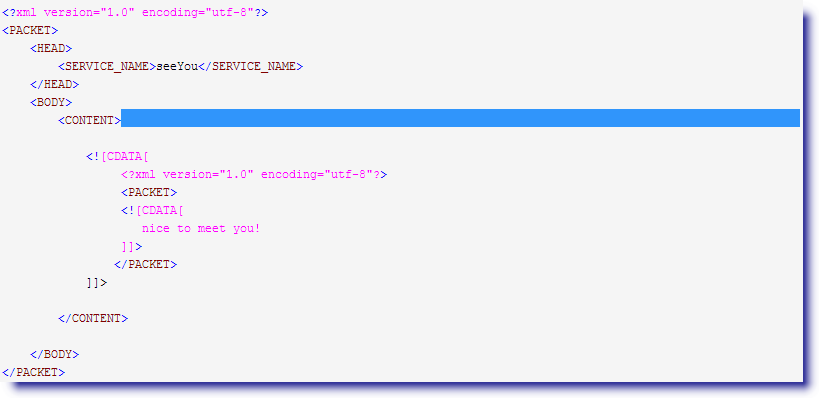
然后一点一点吃字符进来,直到匹配(<!\[CDATA\[(.*)\]\]>)就停止吃字符,至此 group(1) 匹配结束.
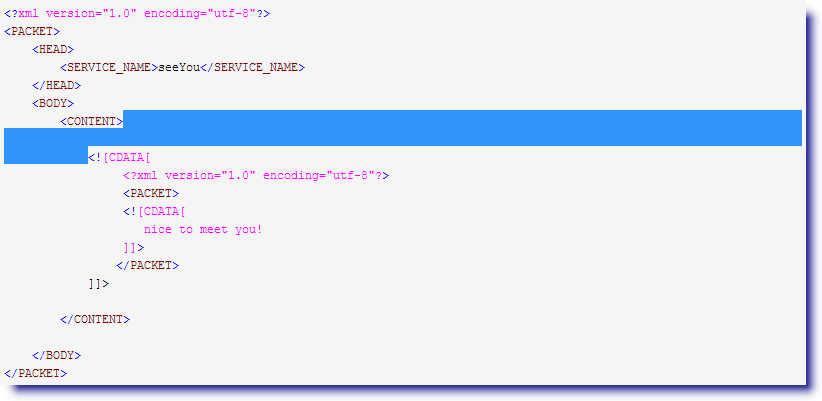
2. 现在来匹配第二个(.*),老规矩先全取
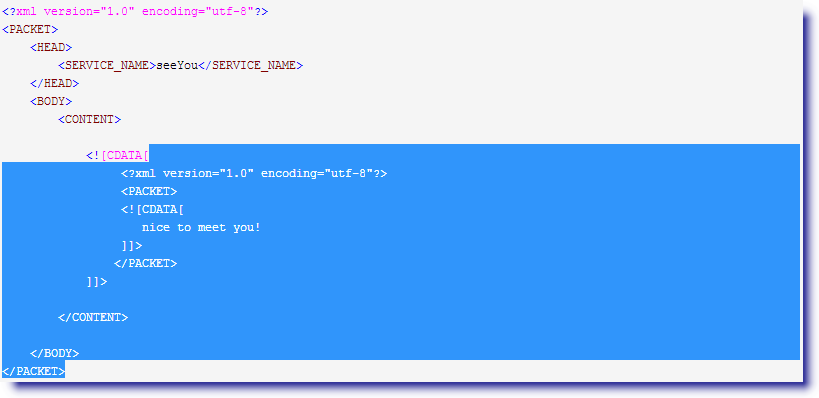
然后一个一个吐字符,直到遇到]]>
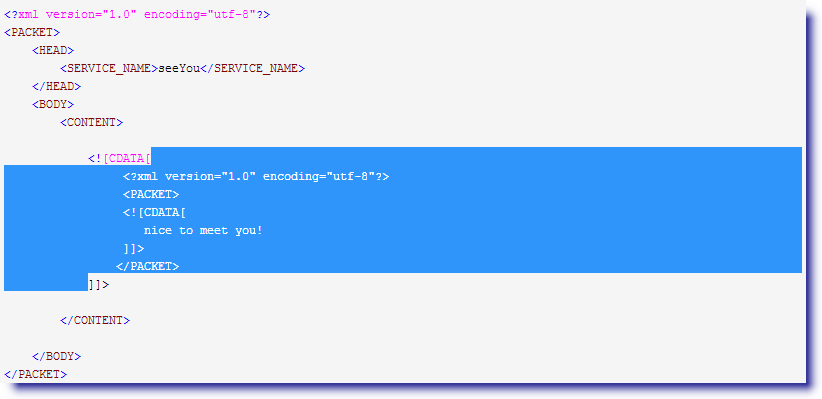
3. 最后来匹配第三个(.*),老规矩先全取
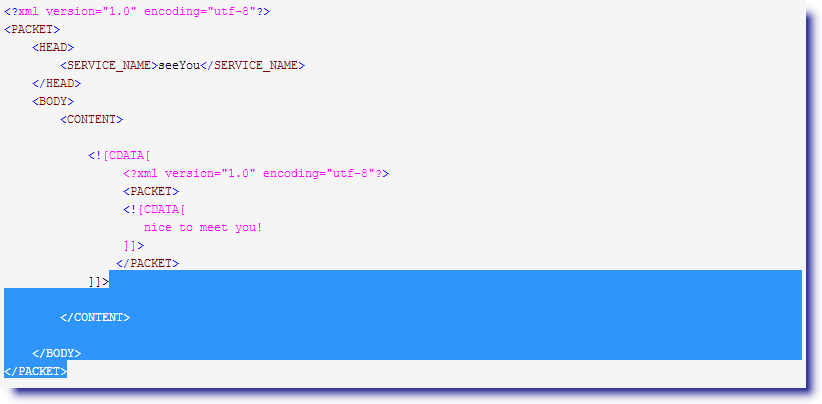
直到遇到</CONTENT>停下
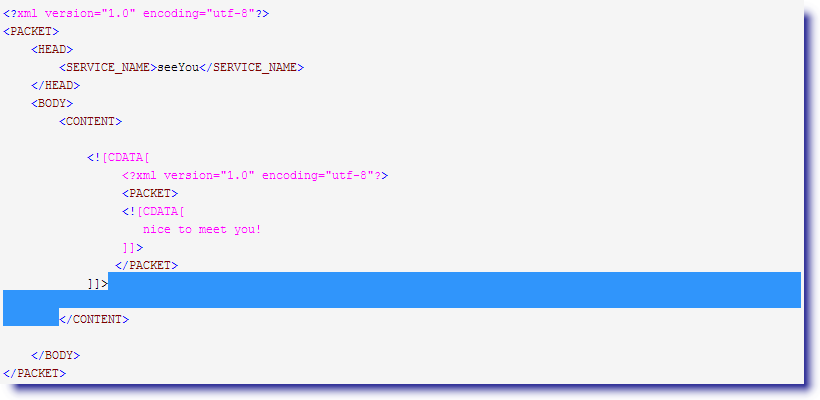
最终,这就是我们希望看到的匹配结果 :
<?xml version="1.0" encoding="utf-8"?>
<PACKET>
<![CDATA[
nice to meet you!
]]>
</PACKET>
|
总结:
正则默认贪婪 greedy 模式 : 能取多少是多少
加了?后变成懒猫 lazy 模式 : 能不取就尽量不取
感觉空虚寂寞,只是因为你无所关注,无处付出。