说明
文本格式: /pattern/flags
正则表达式构造函数: new RegExp("pattern"[,"flags"]);
参数说明:
pattern -- 一个正则表达式文本
flags -- 如果存在,将是以下值:
g: 全局匹配
i: 忽略大小写
gi: 以上组合
[注意] 文本格式的参数不用引号,而在用构造函数时的参数需要引号。如:/ab+c/i new RegExp("ab+c","i")是实现一样的功能。在构造函数中,一些特殊字符需要进行转意(在特殊字符前加"/")。如:re = new RegExp("//w+")
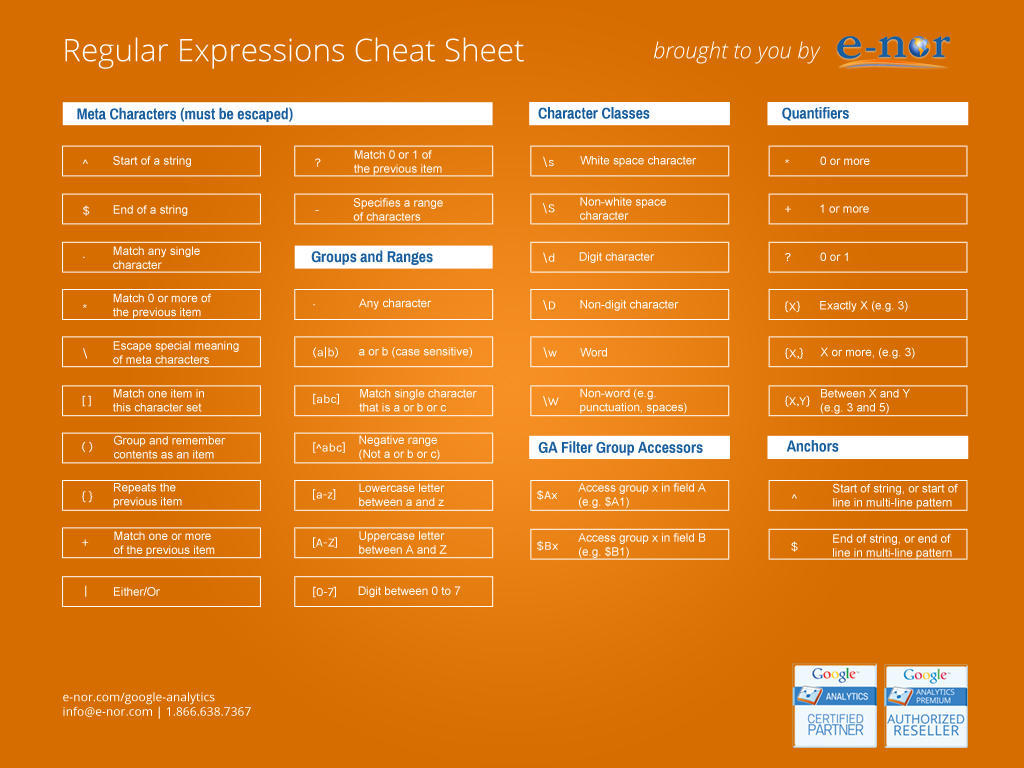
正则表达式中的特殊字符
字符 含意
/ 做为转意,即通常在"/"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后//b/,转意为匹配一个单词的边界。
-或-
对正则表达式功能字符的还原,如"*"匹配它前面元字符0次或多次,/a*/将匹配a,aa,aaa,加了"/"后,/a/*/将只匹配"a*"。
^ 匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a"
$ 匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A"
* 匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa
+ 匹配前面元字符1次或多次,/ba*/将匹配ba,baa,baaa
? 匹配前面元字符0次或1次,/ba*/将匹配b,ba
(x) 匹配x保存x在名为$1...$9的变量中
x|y 匹配x或y
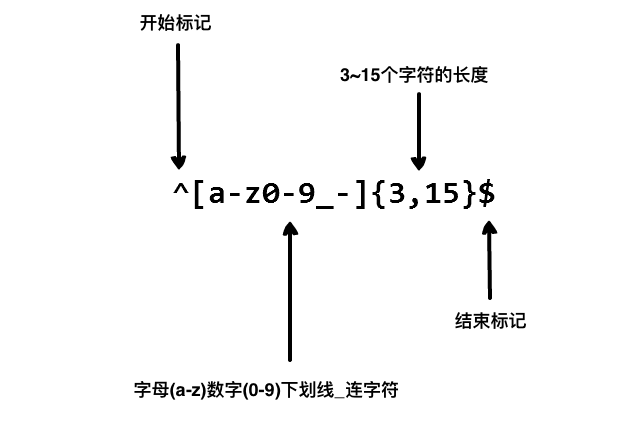
{n} 精确匹配n次
{n,} 匹配n次以上
{n,m} 匹配n-m次
[xyz] 字符集(character set),匹配这个集合中的任一一个字符(或元字符)
[^xyz] 不匹配这个集合中的任何一个字符
[/b] 匹配一个退格符
/b 匹配一个单词的边界
/B 匹配一个单词的非边界
/cX 这儿,X是一个控制符,//cM/匹配Ctrl-M
/d 匹配一个字数字符,//d/ = /[0-9]/
/D 匹配一个非字数字符,//D/ = /[^0-9]/
/n 匹配一个换行符
/r 匹配一个回车符
/s 匹配一个空白字符,包括/n,/r,/f,/t,/v等
/S 匹配一个非空白字符,等于/[^/n/f/r/t/v]/
/t 匹配一个制表符
/v 匹配一个重直制表符
/w 匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[/w]匹配"$5.98"中的5,等于[a-zA-Z0-9]
/W 匹配一个不可以组成单词的字符,如[/W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。
附:
perl中 s/[^[:alnum:]]//g s的意思是替换
---------------------------------------------
常用正则表达式
"^/d+$" //非负整数(正整数 + 0) "^[0-9]*[1-9][0-9]*$" //正整数
"^((-/d+)|(0+))$" //非正整数(负整数 + 0)
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?/d+$" //整数
"^/d+(/./d+)?$" //非负浮点数(正浮点数 + 0)
"^(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数
"^((-/d+(/./d+)?)|(0+(/.0+)?))$" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+/.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*/.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数
"^(-?/d+)(/./d+)?$" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^/w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[/w-]+(/.[/w-]+)*@[/w-]+(/.[/w-]+)+$" //email地址
"^[a-zA-z]+://(/w+(-/w+)*)(/.(/w+(-/w+)*))*(/?/S*)?$" //url
使用范例
1.替换
string targetUrl = "/dir/regex.html&tt=wer";
targetUrl = new Regex("^/dir/(.+).html&(.+)", RegexOptions.IgnoreCase).Replace(targetUrl, "/dir.aspx?ID=$1&$2", 1);
//targetUrl = "/dir.aspx?ID=regex&tt=wer"
//$0 == "/dir/regex.html&tt=wer";
2.匹配其中Match的Group0是整个匹配字符串:
Group0='One car'
Capture0='One car', Position=2
另外一种匹配用法是使用Regex.Maches,大体跟上面相同,变化如下
MatchCollection m = r.Matches(text);
for (int idx=0; idx<m.Count; idx++)
{
Console.WriteLine("Match"+ (idx));
for (int i = 0; i <=m[idx].Groups.Count; i++)
Code...{
string text = "1 One car; 2 red car; 3 blue car";
string pat = @"(w+)s+(car)";
// Compile the regular expression.
Regex r = new Regex(pat, RegexOptions.IgnoreCase);
// Match the regular expression pattern against a text string.
Match m = r.Match(text);
int matchCount = 0;
while (m.Success)
...{
Console.WriteLine("Match"+ (++matchCount));
for (int i = 1; i <m.Groups.Count; i++)
...{
Group g = m.Groups[i];//捕获组可以在单个匹配中捕获零个、一个或更多的字符串
Console.WriteLine("Group"+i+"='" + g + "'");
CaptureCollection cc = g.Captures;
for (int j = 0; j < cc.Count; j++)
...{
Capture c = cc[j];
System.Console.WriteLine("Capture"+j+"='" + c + "', Position="+c.Index);
}
}
m = m.NextMatch();
}
}
Result...{/**//*
Group1='One'
Capture0='One', Position=2
Group2='car'
Capture0='car', Position=6
Match2
Group1='red'
Capture0='red', Position=13
Group2='car'
Capture0='car', Position=17
Match3
Group1='blue'
Capture0='blue', Position=24
Group2='car'
Capture0='car', Position=29
*/}3. 删除HTML元素 public static string StripHtmlXmlTags (string content) ...{
return Regex.Replace(content, "<[^>]+>", "", RegexOptions.IgnoreCase | RegexOptions.Compiled);
}4. 删除多余空格(仅空格)
searchTerms = Regex.Replace(searchTerms, " {1,}", " ", RegexOptions.IgnoreCase | RegexOptions.Compiled | RegexOptions.Multiline);
5. Trim
String.prototype.trim = function () {
return this.replace(/^/s*/, "").replace(//s*$/, "");}6. private static var pattern:RegExp = /=([^/s^/>]+)/g;public static function CoverImg4Html(img:String):String{ var res:String = decodeURI(img); res = res.replace(pattern, "='$1'"); var pos:int = res.indexOf("img"); res = "<img vspace='0' hspace='0'" + res.substring(pos + 3); return res;}
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/anghlq/archive/2006/09/20/1253119.aspx