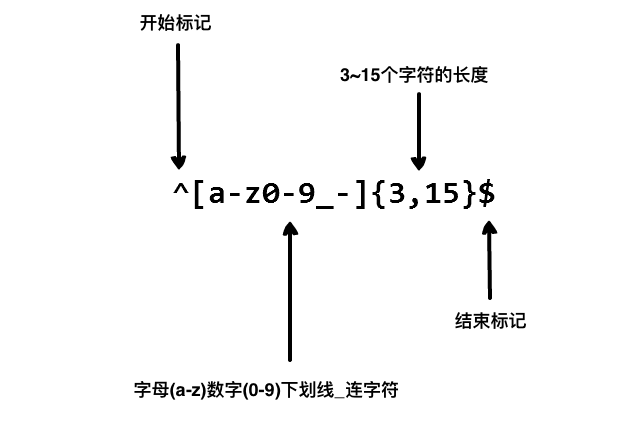
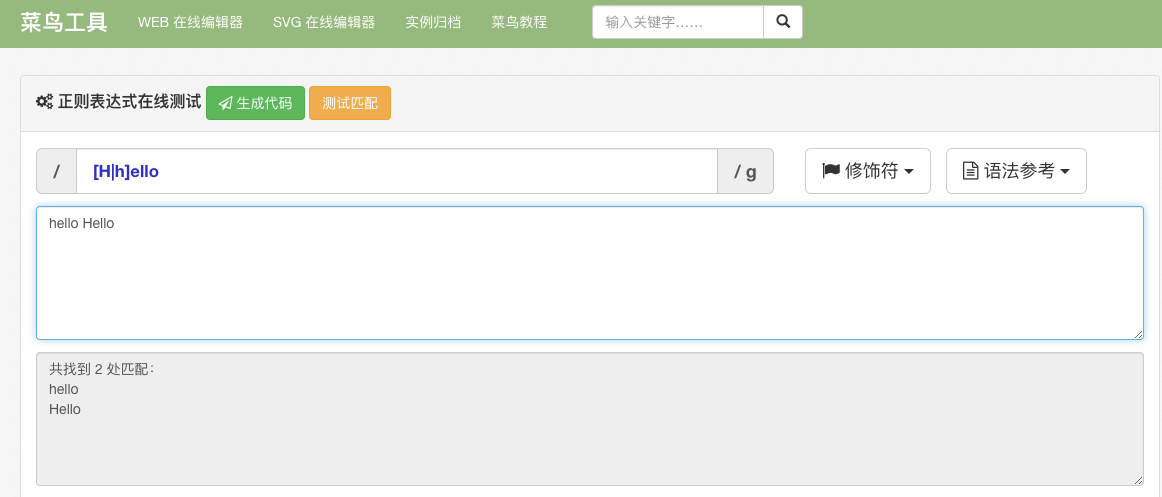
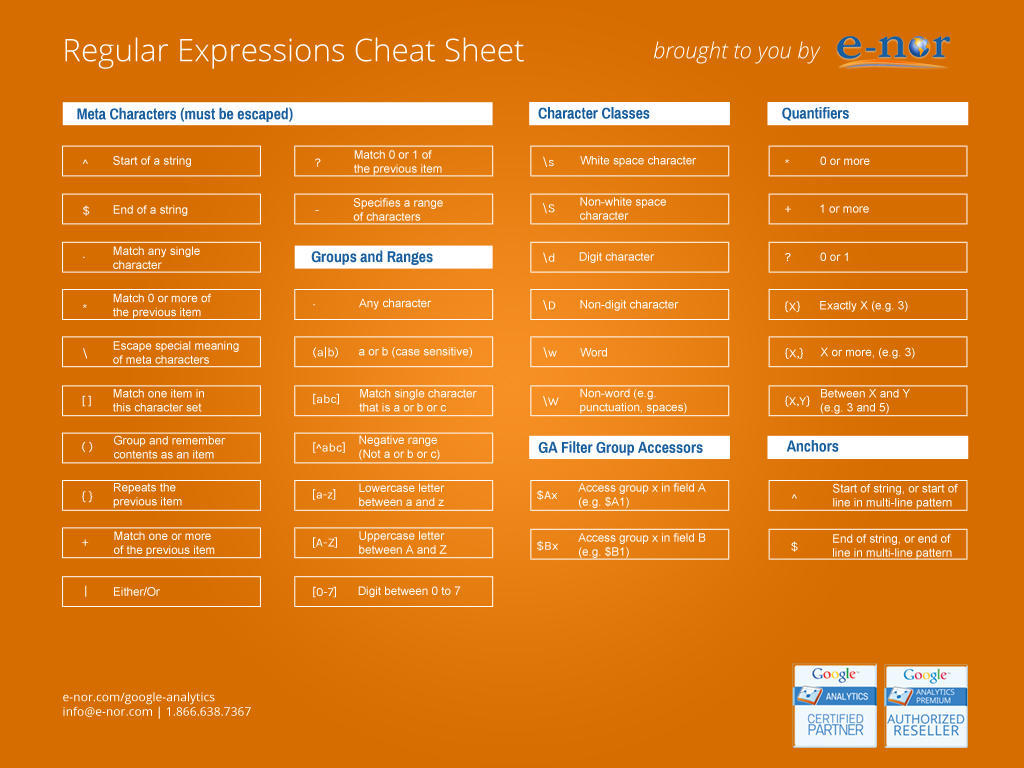
定义:
(维基百科)正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。
作用:
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎
. 任意单个字符(\n 除外)换行 na1.xls 正则 .a.\.xls
| 或操作符
[] 字符集合 na1.xls sa1.xls ca1.xls 正则;[ns]a[0-9]\.xls
[^] 对字符集合求非 z122对对对 正则:[^0-9]
- 定义一个区间[a-z] [0-9] z12322322的点点滴滴 正则:[0-9]
\ 对后面的字符转义 order1.xls 正则:.r.\.xls
^ 字符的开始位置
$ 字符的结束位置
总结:
.[]^$ 是所有语言都支持的正则表达式
2.数量元素
* 零次或多次 \d*\.\d ".0"、 "19.9"、 "219.9" 匹:.0 19.9 219.9
+ 一次或多次 "be+" "been" 中的 "bee", "bent" 中的 "be" 匹:"bee" "be"
? 零次或一次 "rai?n" "ran"、 "rain" 匹:"ran" "rain"
{n} 元素的n次 ",\d{3}" "1,043.6" 中的 ",043", "9,876,543,210" 中的 ",876"、 ",543" 和 ",210" 匹:连续 三个数字 043
{n,} 元素的至少n次 "\d{2,}" "166"、 "29"、 "1930"
{n,m} 至少n次,但不能多于m次 "\d{3,5}" "166", "17668", "193024" 中的 "19302"
*? *的懒惰版本 元素的零次或多次 次数尽可能少 \d*?\.\d ".0"、 "19.9"、 "219.9"
+? 元素的一次或多次 ,次数尽可能少 "be+?" "been" 中的 "be", "bent" 中的 "be"
?? 零次或一次,次数尽可能少 "rai??n" "ran"、 "rain" 匹:"ran" "rain"
{n,}? 至少n次,次数尽可能少 "\d{2,}?" "166"、 "29" 和 "1930"
{n,m}? 数据介于n和m次之间 次数尽可能少 "\d{3,5}?" "166", "17668", "193024" 中的 "193" 和 "024"
总结:
等价是等同于的意思,表示同样的功能,用不同符号来书写。
?,*,+,\d,\w 都是等价字符
?等价于匹配长度{0,1} 零次和一次
*等价于匹配长度{0,} 零次和多次
+等价于匹配长度{1,} 一次和多次
\d等价于[0-9]
\D等价于[^0-9]
\w等价于[A-Za-z_0-9]
\W等价于[^A-Za-z_0-9]。
3.位置元字符
\w 字母数字或下划线或汉子 \s 空白符 \d 匹配数字 \< 匹配单词的开头 \> 匹配单词的结束 \b 匹配单词的边界(开头和结尾)
4.反义字符
\W 匹配任意不是字母,数字,下划线,汉字的字符 \S 匹配任意不是空白符的字符。等价于 [^ \f\n\r\t\v] \D 匹配任意非数字的字符。等价于 [^0-9]。
5.大小写转换
\l 转小写 \u 转大写
6.回溯引用和向前查找(高级) 向前面查找基本支持,向后查找不一定支持 (具体根据不同的语言)
() 定义一个子表达式 也就是组
?= 向前查找 (不包含自己) .+(?=:) .+(:) http://www.forta.com/ 匹配: http http:
?<= 向后查找 (不包含自己,找不到什么都不返回) (?<=:).+ (:).+ 匹配: //www.forta.com/
?! 负向前查找 (?<=\$)\d+ I paid $30 fro 100 applaes, 找价钱 匹:30 找数量:\b(?<!\$)\d+\b
?<! 负向后查找 就是不以$开头
?() 条件 if then \d{5}(?(?=-)-\d{4}) 一般不用 太复杂,有的语言也不支持
?()| 条件 if then else
7.子表达式 (subexpression)
1.元字符和字符是正则表达式的基本构件
2.作用:对表达式进行分组和归类
3.目的:把一个表达式划分为一系列子表达式的目的,为了把那些子表达式当做一个独立元素来使用,用(和)括起来
4.注意:(和)是元字符,如果匹配本身,就需要转义\(和\)
5.例子:
Windos 2000; 正:( ){2,}
Windos  ;2000; 正:( [;;]){2,}
 ;2000; 正:\s( [;;]){2,}
ip:[192.168.1.142] 正:(\d{1,3}\.){3}\d{1,3} 或 (\d{1,3}\.){3}(\d{1,3}) 对速度有影响
(\d{1,3}\.)为子表达式,{3}把子表达式重复3次
用户的生日:1967-08-17 正:(19|20)\d{2}
8.子表达式嵌套
上面匹配IP不合法ip也能与之匹配,每个数字都不能大于255,上面的正则就能匹配到345、555等,这些ip是非法的。
正确IP:
(1)任何一个1位或2位数字
(2)任何一个以1开头的3位数字
(3)任何一个以2开头、第2位数字在0-4之间的3位数
(4)任何一个以25开头、第3位数字在0-5之间的3位数
(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))
9.子表达式另一个用途:回溯引用:前后一致匹配
1.<h1>fdefds</h1><h2>ddeded</h3><H4>ddd</h4> 正:<[hH]1>.*?</[hH]1> 结果:<[hH]1>.*?</[hH]1> 正:<[hH][1-6]>.*</[hH][1-6]> <h1>fdefds</h1><h2>ddeded</h3><H4>ddd</h4> 回溯引用正:<[hH]([1-6])>.*?</[hH][1-6]\1> \1只匹配与之相同的数字 2.在替换操作中的应用: Hello,ben@forta.com is my email address. 正则: \w+[\w\.]*@[\w\.]+\.\w+
替换正则;(\w+[\w\.]*@[\w\.]+\.\w+) <a href="mailto:$1">$1</a> 变为:Hello,<a href="ben@forta.com">ben@forta.com</a> is my email address.
10.正则表达式模式修饰符
(?i):匹配时不区分大小写。
(?s) 单行模式
(?m)表示更改^和$的含义,分别在任意一行的行首和行尾匹配,而不仅仅在每个字符串的开头和结尾匹配,(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结尾的位置)
(?E) 与m 相反,表示如果用这个修饰符,$将匹配绝对字符串的结尾,而不是换行符前面,默认就打开了这个模式
10.不同语言的正则
1).JavaScript 在string 和 RegExp对象的以下几个方法中实现
exec:用来搜索一个匹配的RegExp方法 match:用来匹配字符串的String方法 replace:用来完成替换操作的String方法 search:用来测试在某个给定字符串里是否存在一个匹配的String方法 split:用来把一个字符串拆分成多个子串的方法 test:用来测试在某个给定字符串里是否存在一个匹配的RegExp方法 g 激活全局搜索功能,i不区分大小写
http://www.runoob.com/js/js-regexp.html
2).C#
通过Regex类,命名空间:System.Text.RegularExpressions IsMatch()是否可以找到一个匹配 Match():一个单个匹配,成为一个Match对象 Matches():搜索所有的匹配,返回一个Match-Collection对象 Replace():在一个给定的字符串上进行替换 Split():拆分成字符串数组
http://www.runoob.com/csharp/csharp-regular-expressions.html
3).MySQL
在where子句中使用 :select * from table where REGEXP "pattern" 只提供了搜索功能,不支持使用正则表达式进行替换 要区分字母的大小写增加binary关键字 SELECT * FROM a1 WHERE name LIKE binary '%J%' #使用LIKE+通配符匹配大写J SELECT * FROM a1 WHERE name regexp binary 'j' #使用正则匹配小写j [[:<:]]匹配一个单词的开头 [[:>:]] 匹配单词的结尾
http://www.runoob.com/mysql/mysql-regexp.html
4).PHP
在4.2版本开始提供了PCRE组件,以前需要编译PHP pcre-regex软件才能启用正则支持 PCRE组件提供的一些函数: 1.preg_grep():进行搜索,结果为一个数组返回 2.preg_match():进行搜索,返回第一个匹配 3.preg_match_all():进行搜索,返回所有的匹配 4.preg_quote():输入一个模式,返回值是该模式的转义版本 5.preg_replace():搜索并替换 6.preg_replace_callback():搜索并替换,使用一个回调(callback)来完成实际替换动作 7.preg_split():把一个字符串分成子字符串
http://www.runoob.com/php/php-pcre.html
5).Java
从1.4版本开始,以前的JRE运行环境不支持正则表达式(java运行环境) 先引用包:import java.util.regex.*;导入正则表达式组件 import java.util.regex.Matcher类和以下这些方法实现 find():找一个给定模式的匹配 lookingAt():匹配字符串的开头 matches():匹配一个完整的字符串 replaceAll():对所有的匹配都进行替换 replaceFirst():只对第一个匹配进行替换
import java.util.regex.Pattern。提供了包装器方法 compile():把正则表达式编译成一个模式 flage():返回某给定模式的匹配标志 matches():匹配一个完整的字符串 pattern():把一个模式还原为一个正则表达式 split():把一个字符串拆分成一个子字符串
http://www.runoob.com/java/java-regular-expressions.html
6).Perl脚本
各种语言正则表达式实现的鼻祖。很多语言都参考Perl的正则表达式 Perl正则表达式的三种形式,匹配m//、替换s//、转换tr// =~ 表示相匹配,!~ 表示不匹配 m/pattern/ 匹配给定的模式 s/pattern/pattern/ 执行一个替换操作 qr/pattern/ 返回一个Regex对象以后使用 split() 把字符串拆分成子字符串
http://www.runoob.com/perl/perl-syntax.html
7).SqlSrver
--如果存在则删除原有函数
IF OBJECT_ID(N'dbo.RegexReplace') IS NOT NULL
drop function dbo.RegexReplace
go
--开始创建正则替换函数
CREATE FUNCTION dbo.RegexReplace
(
@string VARCHAR(MAX), --被替换的字符串
@pattern VARCHAR(255), --替换模板
@replacestr VARCHAR(255), --替换后的字符串
@IgnoreCase INT = 0 --0区分大小写 1不区分大小写
)
RETURNS VARCHAR(8000)
as
begin
DECLARE @objRegex INT, @retstr VARCHAR(8000)
--创建对象
EXEC sp_OACreate 'VBScript.RegExp', @objRegex OUT
--设置属性
EXEC sp_OASetProperty @objRegex, 'Pattern', @pattern
EXEC sp_OASetProperty @objRegex, 'IgnoreCase', @IgnoreCase
EXEC sp_OASetProperty @objRegex, 'Global', 1
--执行
EXEC sp_OAMethod @objRegex, 'Replace', @retstr OUT, @string, @replacestr
--释放
EXECUTE sp_OADestroy @objRegex
RETURN @retstr
end
go
--保证正常运行的话,需要将Ole Automation Procedures选项置为1
EXEC sp_configure 'show advanced options', 1
RECONFIGURE WITH OVERRIDE
EXEC sp_configure 'Ole Automation Procedures', 1
RECONFIGURE WITH OVERRIDE
SELECT dbo.RegexReplace('John Smith', '([a-z]+)\s([a-z]+)', '$2,$1',1)
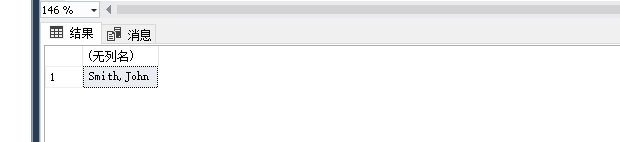
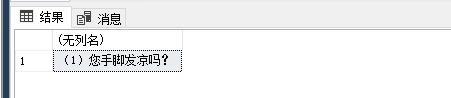
Select dbo.RegexReplace('<p><span style="font-size: 14px; line-height: 115%; font-family: 宋体;">(1)您手脚发凉吗?</span><br/></p>','\<[^<>]*\>','',1)
8).Nodejs正则函数 基本和js一样
1.Match :对字符串进行查找,以数组形式返回符合要求的字符串 stringObj.match(regExp) 2.test:布尔类型:匹配返回true,否则false regExp.test(str) 3.exec:使用指定的正则表达式模式去字符串中查找匹配项,以数组形式返回,为查找到返回null regExp.exec(stringObj) 4.search:返回第一个匹配的字符串所在的位置(偏移量),从0开始 stringObj.search(regExp) 5.split:返回分割后的数组 stringObj.split([separator[, limit]]) stringObj表示需要进行匹配的字符串,limit用来限制返回数组元素的个数 6.replace:返回替换之后的字符串.stringObj.replace(regExp, replaceText)
9).Python
import re 模块
1.re.search:搜索字符串,找到匹配的第一个字符串 2.re.match:从字符串开始匹配 3.re.split:使用正则表达式分割字符串 4.re.findall:返回匹配的字符串列表 5.re.finditer:返回一个迭代器迭代返回 6.re.sub 字符串替换 7.re.subn 返回值多了替换正则表达式的个数 8.re.MatchObject group 分组 group 从1往后的项
http://www.runoob.com/python/python-reg-expressions.html
代码:
import re
def re_demo():
txt='If you purchase more than 100 set,the price of product A is $9.90.'
reg=re.search(r'(\d+).*\$(\d+\.?\d*)',txt)
print(reg.groups())
if __name__=='__main__':
re_demo()
match和search的区别:
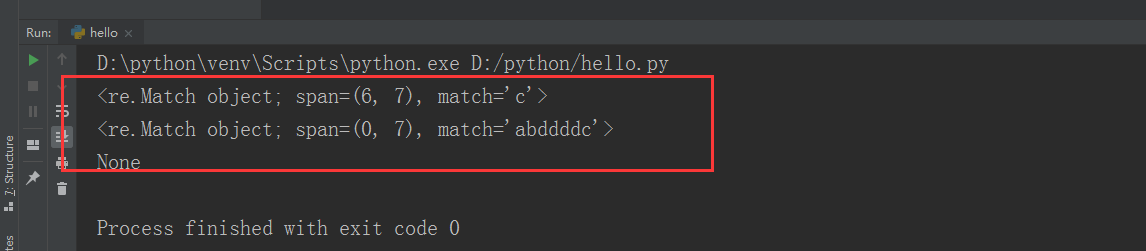
def re_method():
str='abddddcd'
print(re.search(r'c',str))
print(re.match(r'.*c',str))
print(re.match(r'c',str))
if __name__=='__main__':
re_method()
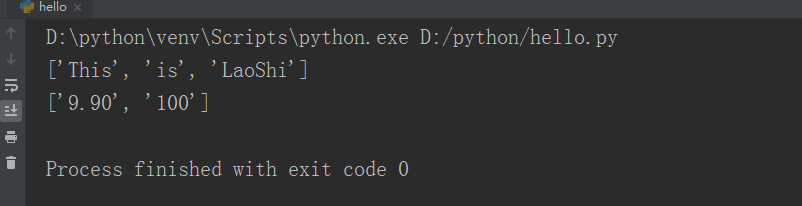
def re_method():
str='This is LaoShi'
print(re.split(r'\W',str))
if __name__=='__main__':
re_method()

def re_method():
str='This is LaoShi'
str1='The first price is $9.90 and the second price is$100'
print(re.findall(r'\w+',str))
print(re.findall(r'\d+\.?\d*',str1))
if __name__=='__main__':
re_method()
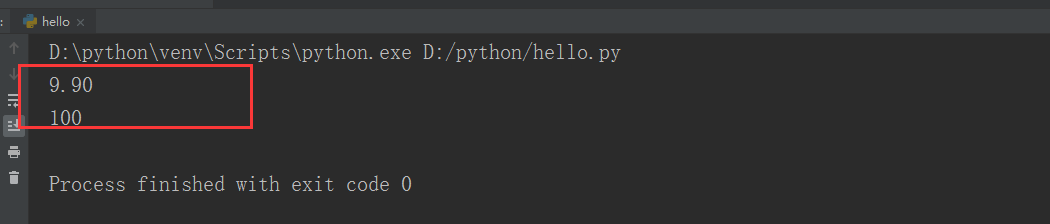
def re_method():
str='The first price is $9.90 and the second price is $100'
prices=re.finditer(r'\d+\.?\d*',str)
for price in prices:
print(price.group())
if __name__=='__main__':
re_method()
def re_method():
str='The first price is $9.90 and the second price is $100'
print(re.sub(r'\d+\.?\d*','<number>',str))
if __name__=='__main__':
re_method()

def re_method():
str='The first price is $9.90 and the second price is $100'
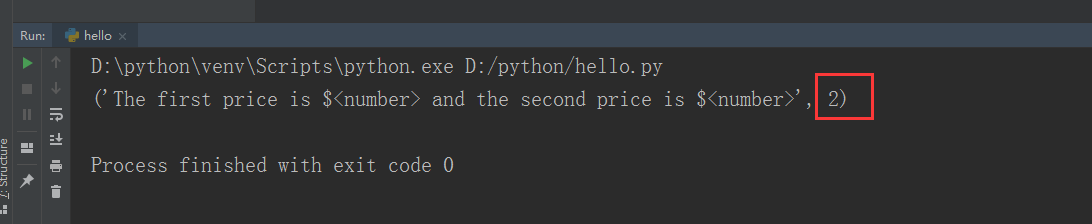
print(re.subn(r'\d+\.?\d*','<number>',str))
if __name__=='__main__':
re_method()
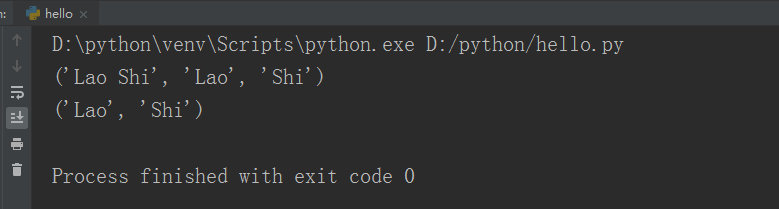
def re_method():
str='Lao Shi'
strs=re.match(r'(\w+)\s(\w+)',str)
print(strs.group(0,1,2))
print(strs.groups())
if __name__=='__main__':
re_method()
在js中的用法:
1.替换上下标
txtContent = txtContent.replace(/<span style="vertical-align: sub;">(.*?)<\/span>/g, "<sub>$1</sub>");
txtContent = txtContent.replace(/<span style="vertical-align: super;">(.*?)<\/span>/g, "<sup>$1</sup>");
2.去掉span
var regEx = new RegExp("<span style=(.|\\n)*?>((.|\\n)*?)</span>", "gi");
txtContent = txtContent.replace(regEx, "$2");
3.去掉p中style内容,保留p
var regEx = new RegExp("<p style=(.|\\n)*?>((.|\\n)*?)</p>", "gi");
txtContent = txtContent.replace(regEx, "<p>$2</p>");
4.去掉h中的内容保留h
var regEx = new RegExp("<(h\\d)\\s*([^>]|\\n)*?>((.|\\n)*?)</\\1>", "gi");
txtContent = txtContent.replace(regEx, "<$1>$3</$1>");
C#中的用法:
//判断英文
public static bool IsEnglishSentence(string str)
{
if (string.IsNullOrEmpty(str)) return false;
string[] foundParts = FindByRegex(str, "^\\s*[a-zA-Z\\d]");
return foundParts.Length != 0;
}
//判读中文
public static bool IsChineseSentence(string str)
{
if (string.IsNullOrEmpty(str)) return false;
string[] foundParts = FindByRegex(str, "\\s*[\u4e00-\u9fa5]");
return foundParts.Length != 0;
}
//查找正则表达式匹配的内容
public static string[] FindByRegex(string html, string strReg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg)) return null;
return FindByRegex(html, "$0", strReg);
}
//返回正则表达式返回的集合
public static string[] FindByRegex(string html, string groupName, string strReg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg)) return null;
int groupNum = -1;
if (groupName.StartsWith("$")) groupNum = int.Parse(groupName.Substring(1));
Regex regex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
List<string> result = new List<string>();
foreach (Match match in regex.Matches(html))
{
if (groupNum >= 0)
{
result.Add(match.Groups[groupNum].Value);
}
else
{
result.Add(match.Groups[groupName].Value);
}
}
return result.ToArray();
}
//根据p 拆分 true 去掉尾部的空行
public static string[] SplitToLinesByP(string html, bool skipLastEmptyLines = true)
{
if (string.IsNullOrEmpty(html)) return new string[] { html };
string[] contentParts;
if (html.StartsWith("<p>"))
{
contentParts = SplitByRegexNoFirtPart(html, "<p(\\s[^>]*?)?>");
}
else
{
contentParts = SplitByRegex(html, "<p(\\s[^>]*?)?>");
}
List<string> result = new List<string>();
for (int i = 0; i < contentParts.Length; i++)
{
result.Add(TrimEndP(contentParts[i]));
}
if (skipLastEmptyLines)
{
for (int i = contentParts.Length - 1; i >= 0; i--)
{
if (string.IsNullOrEmpty(result[i].Trim()))
{
result.RemoveAt(i);
}
else
{
break;
}
}
}
return result.ToArray();
}
//去除空p
public static string RemoveEmptyLinesByP(string html)
{
if (string.IsNullOrEmpty(html)) return html;
string[] lines = SplitToLinesByPAndRemoveEmptyLines(html);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < lines.Length; i++)
{
sb.Append("<p>");
sb.Append(lines[i]);
sb.Append("</p>");
}
return sb.ToString();
}
//去除数组中的空格
public static string[] SplitToLinesByPAndRemoveEmptyLines(string html)
{
if (string.IsNullOrEmpty(html)) return null;
string[] lines = SplitToLinesByP(html, true);
List<string> result = new List<string>();
for (int i = 0; i < lines.Length; i++)
{
if (TrimAllBlankAndNbsp(lines[i]).Length == 0 ||
TrimAllBlankAndNbsp(lines[i]) == "<p></p>") continue;
result.Add(lines[i]);
}
return result.ToArray();
}
//去除空格
public static string TrimAllBlankAndNbsp(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string strReg = "\\s|& | | |<br>)+";
Regex subRegex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
return subRegex.Replace(str, "");
}
//不返回第一部分内容
public static string[] SplitByRegexNoFirtPart(string html, string reg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(reg)) return new string[] { html };
string[] arr = SplitByRegex(html, reg);
return TrimFirstElementOfArray(arr);
}
//去掉数组中的第一个元素
public static string[] TrimFirstElementOfArray(string[] arr)
{
if (arr == null || arr.Length == 0) return new string[0];
string[] result = new string[arr.Length - 1];
for (int i = 1; i < arr.Length; i++) result[i - 1] = arr[i];
return result;
}
//根据正则表达式拆分成几部分,包含第一部分
public static string[] SplitByRegex(string html, string reg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(reg) || reg.Length == 0)
return new string[] { html };
Regex subRegex = new Regex(reg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
MatchCollection mc = subRegex.Matches(html);
if (mc.Count <= 0)
{
return new string[] { html };
}
List<int> positions = new List<int>();
for (int idx = 0; idx < mc.Count; idx++)
{
positions.Add(mc[idx].Index);
}
List<string> result = new List<string>();
result.Add(html.Substring(0, positions[0]));
for (int i = 0; i < positions.Count; i++)
{
int nextPos = 0;
if (i < positions.Count - 1) nextPos = positions[i + 1];
else nextPos = html.Length;
result.Add(html.Substring(positions[i], nextPos - positions[i]));
}
return result.ToArray();
}
//去掉结尾<p> 字符
public static string TrimEndP(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string strReg = "(<p>\\s*)+$";
Regex regex = new Regex(strReg);
return regex.Replace(str, "");
}
//去掉开始 </p> 字符
public static string TrimStartBackSlashTag(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string strReg = "^\\s*</([^>]+?)>";
Regex regex = new Regex(strReg);
while (true)
{
if (regex.Match(str).Success) str = regex.Replace(str, "");
else break;
}
return str;
}
//去除左边的空格
public static string TrimLeftAndRightBlankAndNbsp(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string strReg = "(\\s| | | |<br>)+";
strReg = "^" + strReg;
Regex subRegex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
return subRegex.Replace(str, "");
}
//去除右边的空格
public static string TrimRightBlankAndNbsp(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string strReg = "(\\s| | | |<br>)+";
strReg = strReg + "$";
Regex subRegex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
return subRegex.Replace(str, "");
}
//去掉不对称的p
public static string TrimUnnecessaryP(string str)
{
if (string.IsNullOrEmpty(str)) return str;
str = str.Trim();
int nP = FindHowmanyTimesInHtml("<p>", str);
int nSlashP = FindHowmanyTimesInHtml("</p>", str);
int nDiff = nSlashP - nP;
for (int i = 0; i < nDiff; i++)
{
str = RemoveFirstByRegex("</p>", str);
}
str = ReplaceNoContentPByEmpty(str);
return str;
}
//去掉<p></p>这种
public static string ReplaceNoContentPByEmpty(string str)
{
if (string.IsNullOrEmpty(str)) return str;
return str.Replace("<p></p>", "");
}
//根据正则返回匹配的条数
public static int FindHowmanyTimesInHtml(string html, string strReg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg)) return 0;
Regex regex = new Regex(strReg);
return regex.Matches(html).Count;
}
//移除第一个匹配到的字符
public static string RemoveFirstByRegex(string html, string strReg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg)) return null;
Regex regex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
int n = 0;
html = regex.Replace(html, match =>
{
n++;
if (n == 1) return "";
return match.Value;
});
return html;
}
//以空格拆分返回两部分
public static string[] SplitToTwoPartsBySpace(string str)
{
if (string.IsNullOrEmpty(str)) return null;
str = str.Replace(" ", " ").Replace(" ", " ").Replace(" ", " ");
str = str.Trim();
int idx = str.IndexOf(" ");
if (idx < 0) return new string[] { str, "" };
return new string[] { str.Substring(0, idx), str.Substring(idx + 1).Trim() };
}
//去掉h标签<h></h>
public static string TrimHLabel(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string reg = "(<h\\d>|</h\\d)";
return Regex.Replace(str, reg, "").Trim();
}
//去除以1.或1。
public static string TrimDigitalNum(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string reg = "(<p>|<br>\\n\\s*)\\d+[.。]";
return Regex.Replace(str, reg, "").Trim();
}
//去除 ①
public static string TrimCircledMun(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string reg = "^\\s*[①②③④⑤⑥⑦⑧⑨⑩]";
return Regex.Replace(str, reg, "").Trim();
}
//去掉题干前面例题字和括号里的题型
public static string TrimSubjectTypeFromstem(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string reg = "[^))]*[\u4E00-\u9FA5]+\\s*[\\)\\)]";
return Regex.Replace(str, reg, "").Trim();
}
//去掉 ;;
public static string RemoveSemicolon(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string reg = "[;;]";
return Regex.Replace(str, reg, "").Trim();
}
//去掉StringBuilder最后的 ,
public static StringBuilder TrimLastComma(StringBuilder sb)
{
if (sb == null) return sb;
if (sb.Length >= 1 && sb[sb.Length - 1] == ',')
sb.Remove(sb.Length - 1, 1);
return sb;
}
//中文字符转换成英文字符
public static string ReplaceChineseCompleteCharactorToEnglish(string str)
{
if (string.IsNullOrEmpty(str)) return str;
char[] chinese ={//全角
'0', '1', '2', '3', '4',
'5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'I', 'J',
'K', 'L', 'M', 'N', 'O',
'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y',
'Z', 'a', 'b', 'c', 'd',
'e', 'f', 'g', 'h', 'i',
'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's',
't', 'u', 'v', 'w', 'x',
'y', 'z',
'-', ' ', ':', '.', ',', '/', '%', '#', '!', '@',
'&', '(', ')', '<', '>', '"', ''', '?', '[', ']',
'{', '}', '\', '|', '+', '=', '_', '^', '¥', ' ̄', '`'
};
char[] english ={ // 半角
'0', '1', '2', '3', '4',
'5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'I', 'J',
'K', 'L', 'M', 'N', 'O',
'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y',
'Z', 'a', 'b', 'c', 'd',
'e', 'f', 'g', 'h', 'i',
'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's',
't', 'u', 'v', 'w', 'x',
'y', 'z',
'-', ' ', ':', '.', ',', '/', '%', '#', '!', '@',
'&', '(', ')', '<', '>', '"', '\'', '?', '[', ']',
'{', '}', '\\', '|', '+', '=', '_', '^', '$', '~', '`'
};
for (int i = 0; i < chinese.Length; i++)
{
str = str.Replace(chinese[i], english[i]);
}
return str;
}
//通过正则得到第二部分
public static string SplitByRegexGetSecondPart(string html, string subRegex)
{
if (string.IsNullOrEmpty(subRegex) || string.IsNullOrEmpty(html)) return html;
string[] parts = SplitByRegexToTwoParts(html, subRegex);
if (parts != null && parts.Length > 1) return parts[1];
return "";
}
//用正则拆分成两部分
public static string[] SplitByRegexToTwoParts(string html, string subRegex)
{
if (string.IsNullOrEmpty(subRegex) || string.IsNullOrEmpty(html)) return new string[] { html, html };
Regex reg = new Regex(subRegex, RegexOptions.Singleline | RegexOptions.IgnoreCase);
MatchCollection mc = reg.Matches(html);
if (mc.Count <= 0)
{
return new string[] { html, "" };
}
int pos = mc[0].Index;
return new string[] { html.Substring(0, pos), html.Substring(pos) };
}
//通过参数word进行拆分,返回后一部分 不包含word
public static string SplitByWordGetSecondPart(string html, string word)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(word)) return html;
int index = html.IndexOf(word);
if (index >= 0) return html.Substring(index);
return "";
}
//返回包含word 后一部分
public static string SplitByWordGetAfterPart(string html, string word)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(word)) return html;
int index = html.IndexOf(word);
if (index > 0) return html.Substring(index + word.Length);
return "";
}
//获得word之前的内容
public static string SplitByWordGetBeforePart(string html, string word)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(word)) return html;
int index = html.IndexOf(word);
if (index >= 0) return html.Substring(0, index);
return "";
}
//通过正则获取匹配之后的内容
public static string SplitByRegexGetAfterPart(string html, string reg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(reg)) return html;
Match match = Regex.Match(html, reg);
if (!match.Success) return "";
return html.Substring(match.Index + match.Value.Length);
}
//正则表达式之前的内容
public static string SplitByRegexGetBeforePart(string html, string reg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(reg)) return html;
Match match = Regex.Match(html, reg);
if (!match.Success) return "";
return html.Substring(0, match.Index);
}
//通过正则返回字典
public static Dictionary<string, string> GetKeyValuesByRegex(string html, string reg, string[] keys)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(reg)) return null;
Dictionary<string, string> dict = new Dictionary<string, string>();
Regex subRegex = new Regex(reg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
MatchCollection mc = subRegex.Matches(html);
if (mc.Count <= 0)
{
return null;
}
Match match = mc[0];
foreach (string key in keys)
{
if (match.Groups[key] != null) dict[key] = match.Groups[key].Value;
}
return dict;
}
//拼接集合
public static string ConcatJson(List<string> jsons, bool bAlreadyJson)
{
if (jsons.Count == 0) return null;
return ConcatJson(jsons.ToArray(), bAlreadyJson);
}
//拼接数组
public static string ConcatJson(string[] jsons, bool bAlreadyJson = true)
{
if (jsons == null) return null;
StringBuilder sb = new StringBuilder();
sb.Append("[");
for (int i = 0; i < jsons.Length; i++)
{
string value = jsons[i];
if (!bAlreadyJson)
{
if (value == null)
{
value = "null";
}
else
{
value = "\"" + ReplaceHtmlForJson(value) + "\"";
}
}
sb.Append(value);
if (i != jsons.Length - 1) sb.Append(",");
}
sb.Append("]");
return sb.ToString();
}
public static string ConcatJson(string[] keys, string[] values)
{
return ConcatJson(keys, values, null);
}
//拼接多个数组
public static string ConcatJson(string[] keys, string[] values, string[] isJsonAlreadyKeys)
{
if (keys == null || values == null || keys.Length == 0 || values.Length == 0) return "{}";
if (keys.Length != values.Length) throw new Exception("key and values 长度不用");
StringBuilder sb = new StringBuilder();
sb.Append("{");
for (int i = 0; i < keys.Length; i++)
{
string value = values[i];
if (value == null)
{
value = "null";
}
else
{
if (isJsonAlreadyKeys == null || isJsonAlreadyKeys != null && GetIndexOf(keys[i], isJsonAlreadyKeys) < 0)
{
value = "\"" + ReplaceHtmlForJson(value) + "\"";
}
}
sb.Append("\"" + keys[i] + "\":" + value);
if (i != keys.Length - 1) sb.Append(",");
}
sb.Append("}");
return sb.ToString();
}
//拼接字典的json
public static string ConcatJson(Dictionary<string, string> dict)
{
if (dict == null) return ConcatJson(null, null);
string[] keys = dict.Keys.ToArray();
string[] values = new string[dict.Keys.Count];
for (int i = 0; i < keys.Length; i++) values[i] = dict[keys[i]];
return ConcatJson(keys, values);
}
//根据key在数组中找
public static int GetIndexOf(string key, string[] array)
{
if (key == null) return -1;
if (array == null) return -1;
for (int i = 0; i < array.Length; i++)
{
if (key == array[i]) return i;
}
return -1;
}
//在数组中找
public static int GetIndexOf(string key, List<string> list)
{
return GetIndexOf(key, list.ToArray());
}
//根据传过来的正则解析出对应的文本,正则没有找到值,默认也算一个,包含第一个值
public static string[] SplitByManyRegex_AnyOrder(string html, string[] subRegexStrings,
bool resultChangeOrder = true)
{
if (string.IsNullOrEmpty(html) || subRegexStrings == null || subRegexStrings.Length == 0)
{
return new string[] { html };
}
string allReg = "(" + string.Join("|", subRegexStrings) + ")";
string[] result = SplitByRegex(html, allReg);
if (!resultChangeOrder) return result;
string[] ordered = new string[subRegexStrings.Length + 1];
ordered[0] = result[0];
for (int i = 1; i < result.Length; i++)
{
for (int k = 0; k < subRegexStrings.Length; k++)
{
if (Regex.Match(result[i], subRegexStrings[k]).Success)
{
ordered[k + 1] = result[i];
}
}
}
return ordered;
}
//不包含第一条 排序
public static string[] SplitByManyRegex_AnyOrder_NoFirst(string html, string[] subRegexStrings,
bool resultChangeOrder = true)
{
if (string.IsNullOrEmpty(html) || subRegexStrings == null || subRegexStrings.Length == 0)
{
return new string[] { html };
}
return TrimFirstElementOfArray(SplitByManyRegex_AnyOrder(html, subRegexStrings, resultChangeOrder));
}
//通过传一个数组正则,拆分返回找到数组的正则
public static string[] SplitByManyRegex(string html, string[] subRegexStrings)
{
if (string.IsNullOrEmpty(html) || subRegexStrings == null || subRegexStrings.Length == 0)
{
return new string[] { html };
}
string allRegexString = "^(?<mySubGroup0>.*?)";
for (int i = 0; i < subRegexStrings.Length; i++)
{
allRegexString += "(?<mySubGroup" + (i + 1) + ">" + subRegexStrings[i] + ".*?)";
}
allRegexString += "$";
Regex subRegex = new Regex(allRegexString, RegexOptions.Singleline | RegexOptions.IgnoreCase);
MatchCollection mc = subRegex.Matches(html);
if (mc.Count <= 0)
{
return new string[] { html };
}
List<int> positions = new List<int>();
for (int m = 0; m < subRegexStrings.Length + 1; m++)
{
positions.Add(mc[0].Groups["mySubGroup" + m].Index);
}
List<string> result = new List<string>();
//以^开始 mySubGroup0的位置就是0
for (int i = 0; i < positions.Count; i++)
{
int nextPos = 0;
if (i < positions.Count - 1) nextPos = positions[i + 1];
else nextPos = html.Length;
result.Add(html.Substring(positions[i], nextPos - positions[i]));
}
return result.ToArray();
}
//一个正则数组 不包含第一部分的
public static string[] SplitByManyRegexNoFirtPart(string html, string[] subRegexStrings)
{
if (string.IsNullOrEmpty(html) || subRegexStrings == null || subRegexStrings.Length == 0)
{
return new string[] { html };
}
string[] ary = SplitByManyRegex(html, subRegexStrings);
return TrimFirstElementOfArray(ary);
}
//传多少个正则就生成多少个数组
public static string[] SplitByManyRegex_MayLess(string html, string[] subRegexStrings)
{
if (string.IsNullOrEmpty(html) || subRegexStrings == null || subRegexStrings.Length == 0)
{
return new string[] { html };
}
string allRegexString = "^(?<mySubGroup0>.*?)"; ;
//组装成 (A(B(C?)?)?)
for (int i = 0; i < subRegexStrings.Length; i++)
{
allRegexString += "((?mySubGroup)" + (i + 1) + ">" + subRegexStrings[i] + ".*?)";
}
for (int i = subRegexStrings.Length-1; i >=0; i--)
{
allRegexString += "?";
}
allRegexString += "$";
Regex subRegex = new Regex(allRegexString, RegexOptions.Singleline | RegexOptions.IgnoreCase);
MatchCollection mc = subRegex.Matches(html);
if (mc.Count <= 0)
{
return new string[] { html };
}
List<int> positions = new List<int>();
for (int m = 0; m < subRegexStrings.Length+1; m++)
{
if (mc[0].Groups["mySubGroup" + m].Success)
{
positions.Add(mc[0].Groups["mySubGroup" + m].Index);
}
}
List<string> result = new List<string>();
for (int i = 0; i < positions.Count; i++)
{
int nextPos = 0;
if (i < positions.Count - 1) nextPos = positions[i + 1];
else nextPos = html.Length;
result.Add(html.Substring(positions[i], nextPos - positions[i]));
}
return result.ToArray();
}
//根据正则表达式分成三部分
public static string[] SplitByRegexToThreeParts(string html, string subRegexString)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(subRegexString))
return new string[] { html, "", "" };
Match match = Regex.Match(html, subRegexString, RegexOptions.IgnoreCase);
if (match == null || !match.Success) return new string[] { html, "", "" };
string firstPart = html.Substring(0, match.Index);
string middlePart = html.Substring(match.Index, match.Length);
string thirdPar = html.Substring(match.Index + match.Length);
return new string[] { firstPart, middlePart, thirdPar };
}
//html转成json格式
public static string ReplaceHtmlForJson(string str)
{
if (string.IsNullOrEmpty(str)) return str;
str = TrimStartAndEndUglyP(str);
return str.Replace("\\", "\\\\")
.Replace("\n", "\\n").Replace("\r", "\\r")
.Replace("\"", "\\\"");
}
//拆分单个正则,返回匹配的正则表达式(分隔符)之间的部分,不要匹配项
public static string[] SplitByRegex_ReturnPartsWithoutSeperators(string html, string subRegexString)
{
if(string.IsNullOrEmpty(html)||string.IsNullOrEmpty(subRegexString))
return new string[] { html };
string[] parts = SplitByRegex_ReturnSeperatorAndParts(html, subRegexString);
List<string> result = new List<string>();
for (int i = 0; i < parts.Length; i+=2)
{
result.Add(TrimStartAndEndUglyP(parts[i]));
}
return result.ToArray();
}
//拆分正则数组,返回匹配的正则表达式(分隔符)之间的部分,不要匹配项
public static string[] SplitByRegex_ReturnPartsWithoutSeperators(string html, string[] subRegexStrings)
{
if (string.IsNullOrEmpty(html) || subRegexStrings == null) return new string[] { html };
return SplitByRegex_ReturnPartsWithoutSeperators(html, string.Join("|", subRegexStrings));
}
//拆分单个正则,返回匹配的正则表达式(分隔符)以及之间的部分
public static string[] SplitByRegex_ReturnSeperatorAndParts(string html, string subRegexString)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(subRegexString))
return new string[] { html };
Regex subRegex = new Regex(subRegexString, RegexOptions.Singleline | RegexOptions.IgnoreCase);
MatchCollection mc = subRegex.Matches(html);
if (mc.Count <= 0)
{
return new string[] { html };
}
List<int> positions = new List<int>();
for (int m = 0; m < mc.Count; m++)
{
positions.Add(mc[m].Index); //每个匹配的首位置
positions.Add(mc[m].Index + mc[m].Length); //每个匹配的尾位置
}
List<string> result = new List<string>();
result.Add(html.Substring(0, positions[0]));
for (int i = 0; i < positions.Count; i++)
{
int nextPos = 0;
if (i < positions.Count - 1) nextPos = positions[i + 1];
else nextPos = html.Length;
result.Add(html.Substring(positions[i], nextPos - positions[i]));
}
return result.ToArray();
}
//获取两个正则表达式之间的内容
public static string FindContentBetweenTwoRegex(string html, string reg1, string reg2)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(reg1) || string.IsNullOrEmpty(reg2))
return html;
string reg = string.Format("({0})(?<myinnercontent>.*?)({1})", reg1, reg2);
return FindFirstByRegex(html, "myinnercontent", reg);
}
//根据正则取到第一部分内容
public static string FindFirstByRegex(string html,string groupName,string strReg)
{
if (string.IsNullOrEmpty(html)||string.IsNullOrEmpty(strReg)) return html;
string[] words = FindByRegex(html, groupName, strReg);
if (words == null || words.Length == 0) return null;
return words[0];
}
public static string FindFirstByRegex(string html, string strReg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg))
return html;
return FindFirstByRegex(html, "$0", strReg);
}
//查找【】 中的内容 如:【标题:*****】
public static string FindInChineseSingleFishTail(string html, string key)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(key)) return html;
string reg = "【" + key + "[:|:]\\s*(?<content>[^】]*?)】";
return FindFirstByRegex(html, "content", reg);
}
//查找【key】....【/key】 中的内容
public static string FindInChineseKeyPairFishTail(string html, string key)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(key)) return html;
string reg = "【" + key + "】(?<content>.*?)【/" + key + "】";
return TrimStartAndEndUglyP(FindFirstByRegex(html, "content", reg));
}
//找到【】里面的内容
public static string FindContentFishTail(string html)
{
if (string.IsNullOrEmpty(html)) return html;
string reg = "【(?<content>.*?)】";
return TrimStartAndEndUglyP(FindFirstByRegex(html, "content", reg));
}
public const string DigitalPointReg = "(<p>|<br>|\\n)\\s*\\d+[.]";
public const string ParenthesesNumReg = "(<p>|<br>|\\n)\\s*(([((])\\d+[))]|[⑴⑵⑶⑷⑸⑹⑺⑻⑼⑽⑾⑿⒀⒁⒂⒃⒄⒅⒆⒇])";
public const string CircledNumReg = "(<p>|<br>|\\n)\\s*[①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳]";
//去掉⑴⑵⑶⑷⑸⑹
public static string RemoveParenthesesNumReg(string html)
{
if (string.IsNullOrEmpty(html)) return html;
string parenthesesNumReg = "\\s*[⑴⑵⑶⑷⑸⑹⑺⑻⑼⑽⑾⑿⒀⒁⒂⒃⒄⒅⒆⒇]";
return RemoveByRegex(html, parenthesesNumReg);
}
public static string[] SplitByDigitalPoint(string html)
{
if (string.IsNullOrEmpty(html)) return null;
return SplitByRegex(html, DigitalPointReg);
}
public static string[] SplitByDigtalPointNoFirst(string html)
{
if (string.IsNullOrEmpty(html)) return null;
return SplitByRegexNoFirtPart(html, DigitalPointReg);
}
public static string[] SplitByParenthesesNum(string html)
{
if (string.IsNullOrEmpty(html)) return null;
return SplitByRegex(html, ParenthesesNumReg);
}
public static string[] SplitByCircledNum(string html)
{
if (string.IsNullOrEmpty(html)) return null;
return SplitByRegex(html, CircledNumReg);
}
public const string CircledNumString= "①②③④⑤⑥⑦⑧⑨⑩⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳";
public static int FindCircledNum(string html)
{
if (string.IsNullOrEmpty(html)) return 0;
Match match = Regex.Match(html, "[" + CircledNumString + "]");
if (!match.Success) return 0;
string num = match.Value;
return CircledNumString.IndexOf(num) + 1;//返回数字
}
public static string RemoveCircledNum(string html)
{
if (string.IsNullOrEmpty(html)) return html;
return ReplaceByRegex("[" + CircledNumString + "]", html, "");
}
public static string ReplaceByRegex(string html, string strReg, string target)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg)) return html;
return ReplaceByRegex(html, strReg, m => target);
}
//替换正则表达式匹配的内容
public static string ReplaceByRegex(string html, string strReg, MatchEvaluator function)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg)) return null;
Regex regex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
html = regex.Replace(html, function);
return html;
}
//去掉正则表达式匹配的内容
public static string RemoveByRegex(string html, string strReg)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(strReg)) return html;
Regex regex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
html = regex.Replace(html, match => "");
return html;
}
//眼花【缭】乱 这样的,拆成多个汉字,
public static char[] GetChineseCharactorsAndGetFishTailPosition(string html, out int index)
{
index = -1;
if (string.IsNullOrEmpty(html)) return null;
//找到位置,index
html = html.Trim();
index = html.IndexOf("【"); //【内是正确答案
html = RemoveFishTail(html);
return html.ToArray();
}
//去掉【】
public static string RemoveFishTail(string html)
{
if (string.IsNullOrEmpty(html)) return html;
return html.Replace("【", "").Replace("】", "").Trim();
}
//找到后面的数据 +1 在 合并
public static string GetReplaceNumAdd(string str)
{
if (string.IsNullOrEmpty(str)) return str;
string strReg = "(?<str>\\s*\\w+)(?<num>\\s*\\d+)";
return ReplaceByRegex(strReg, str, match =>
{
string strStr = match.Groups["str"].Value;
string num = match.Groups["num"].Value;
int.TryParse(num, out int number);
if (number == 0) return str;
return strStr + number++;
});
}
//从Html中找到标记
public static string[] FindTagsInHtml(string tag, string html)
{
if (string.IsNullOrWhiteSpace(html) || string.IsNullOrEmpty(tag)) return null;
string strReg = "<" + tag + "[^>]*?>";
Regex regex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
List<string> list = new List<string>();
foreach (Match match in regex.Matches(html))
{
list.Add(match.Value);
}
return list.ToArray();
}
//从元素中找到属性
public static string FindAttributeInHtml(string attr, string html)
{
if (string.IsNullOrEmpty(html) || string.IsNullOrEmpty(attr)) return null;
string strReg = attr + "\\s*=\\s*(['\"])(?<val>.*?)(\\1)";
Regex regex = new Regex(strReg, RegexOptions.Singleline | RegexOptions.IgnoreCase);
Match match = regex.Match(html);
if (match == null || !match.Success) return null;
return match.Groups["val"].Value;
}
//替换数学公式中特殊符号
public static string ReplaceMathematicalFormula(string html)
{
if (string.IsNullOrEmpty(html)) return html;
var mathSymbols = "Ï∉Î∈Í⊆ð∁Æ∅Ü⊊Ý⊋´×△Δ﹣-³≥";
for (int i = 0; i < mathSymbols.Length; i+=2)
{
var c1 = mathSymbols[i];
var c2 = mathSymbols[i + 1];
html = html.Replace(c1, c2);
}
return html;
}
//规范化html格式
public static string NormalizeHtmlFormat(string html)
{
if (string.IsNullOrEmpty(html)) return html;
html = new Regex("(<br>)+").Replace(html, "<br>");
//将多个空格换成一个 题干中() 不去
html = new Regex("( | | | )+").Replace(html, " ");
html = ReplaceByRegex(html, "[((](?<content>.*?)[))]", match =>
{
string value = match.Value;
string content = match.Groups["content"].Value;
if (Regex.IsMatch(content, "^(\\s| | | | )*?")) return "( )";
return value;
});
html = new Regex("<b(\\s[^>]*?)?>(.*?)</b>").Replace(html, "$2"); //$2表示<b></b>中的内容 去掉<b></b>
return html = new Regex("<i(\\s[^>]*?)?>(.*?)</i>").Replace(html, "$2");//去掉<i></i>
}