1 什么是一致性?
一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的。
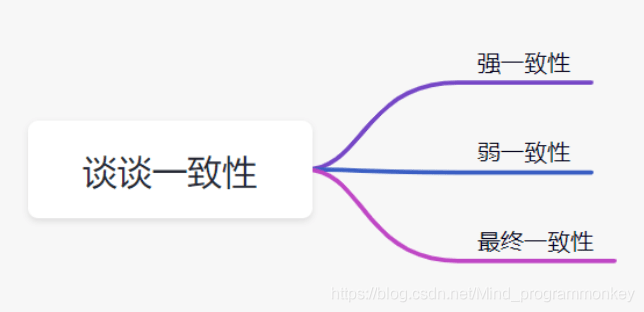
强一致性: 这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验性好,但实现起来往往对系统的性能影响大;
弱一致性: 这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态;
最终一致性: 最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型;
2 三个经典的缓存模式
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。一般我们是如何使用缓存呢?有三种经典的缓存使用模式:
- Cache-Aside Pattern;
- Read-Through / Write-Through
- Write-behind
(1) Cache-Aside
Cache-Aside Pattern, 即旁路缓存模式。它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。
a. Cache-Aside读流程
Cache-Aside Pattern的读请求流程如下:
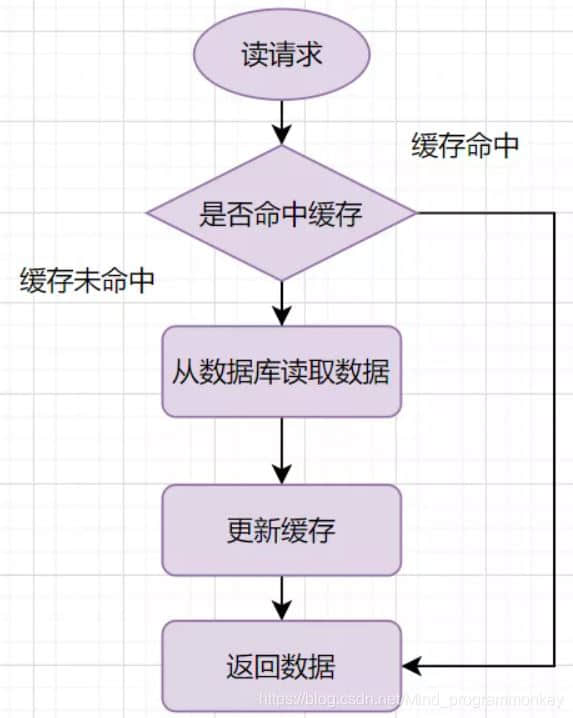
读的时候,先读缓存,缓存命中的话,直接返回数据;缓存没有命中的话,就去读数据库,从数据库中取出数据,放入缓存后,同时返回响应; b.Cache-Aside写流程
Cache-Aside Pattern的写请求流程如下:
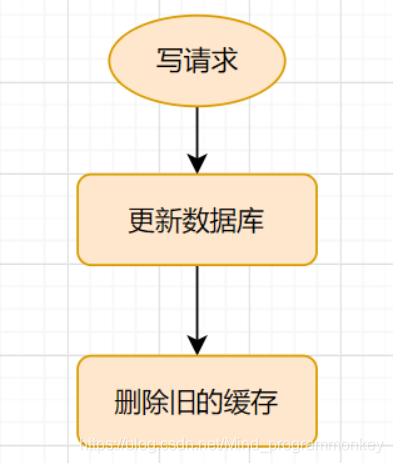
更新得到时候,先更新数据库,然后再删除缓存。
当这个数据在下一次需要的时候,使用Cache-Aside模式将会在获取数据的时候,同时从数据仓库中获取数据,并且写到Cache之中。
(2) Read-Through/Write-Through(读写穿透)
Read/Write - Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过抽象缓存层完成的。
a.Read-Through
Read-Through读的简要流程如下:
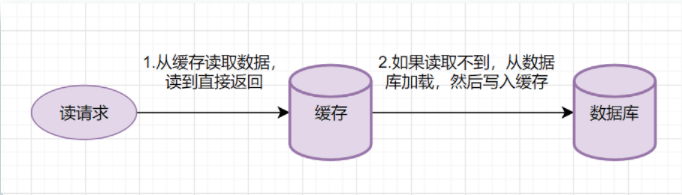
从缓存中读取数据,读到直接返回;
如果读取不到的话,从数据库中加载,写入缓存后,再返回响应;
这个简要流程是不是跟Cache-Aside很像呢?其实Read-Through就是多了一层Cache-Provider而已,流程如下:

Read-Through 实际上只是在Cache-Aside之上进行了一层封装,它会让程序代码变得更加简洁,同时也减少数据源上的负载。
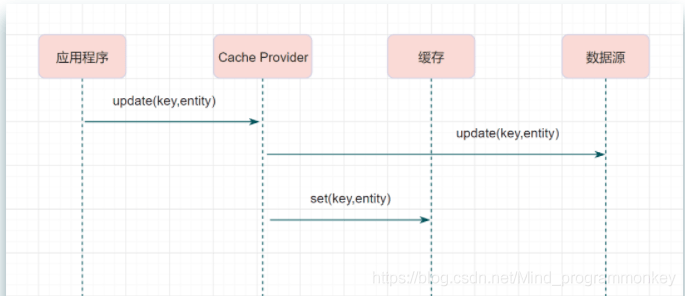
b.Write-Through
Write-Through模式下,当发生写请求时,也是由缓存抽象层完成数据源和缓存数据的更新,流程如下:
(3) Write-behind(异步缓存写入)
Write-behind跟Read-Through/Write-Through有很多相似的地方,都是由Cache Provider来负责缓存和数据库的读写。它们又有个很大的不同:Read/Write-Through是同步更新缓存和数据的,Write-Behind则是只更新缓存,不直接更新数据库,通过批量异步的方式来更新数据库。

这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。
但是它适合频繁写的场景,MySQL的Innodb Buffer Pool机制就是用到这种模式。
3 操作缓存的时候,到底是删除缓存呢,还是更新缓存?
日常开发中,我们一般使用的就是Cache-Aside模式。但这里我们注意到Cache-Aside在写入请求的时候,为什么是删除缓存而不是更新缓存呢?
我们在操作缓存的时候,到底应该删除缓存还是更新缓存呢?这里通过一个例子来说明一下:
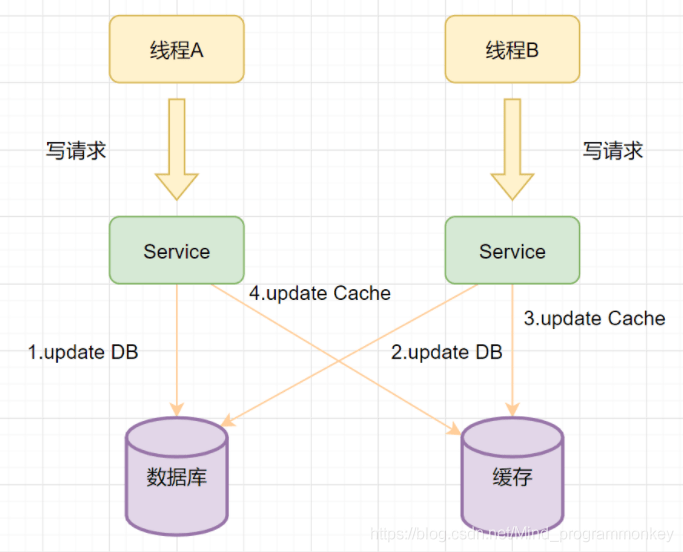
线程A先发起一个写操作,第一步先更新数据库;线程B先发起一个写操作,第二步后更新数据库;但是由于网络等原因,线程B先更新了缓存;线程A更新缓存;
此外, 更新缓存相对于删除缓存,还有两点劣势:
如果你写入的缓存值,是经过复杂计算才得到的话,更新缓存频率高的话,就浪费性能了;在写数据库场景多、读数据场景少的情况下,数据很多时候还没被读取到,又被更新了,这也浪费了性能呢。 4 双写的情况下,先操作数据库还是先操作缓存呢?
Cache-Aside缓存模式中,有些小伙伴还是会有疑问,在写请求过来的时候,为什么是先操作数据库呢?为什么不先操作缓存呢?
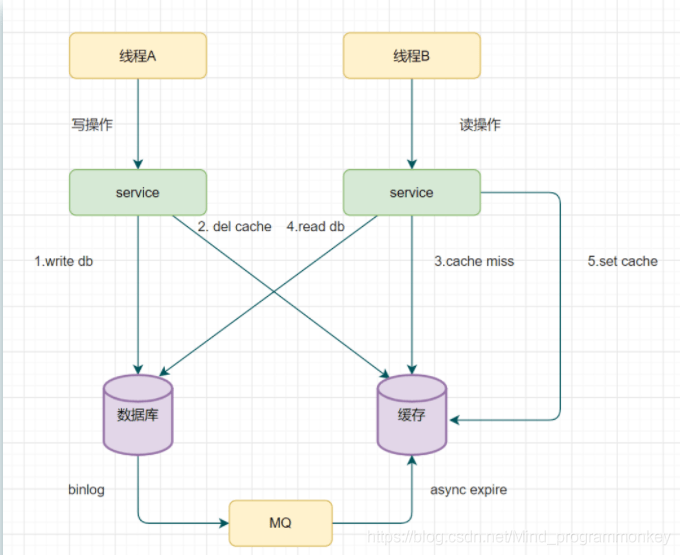
例子:假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。
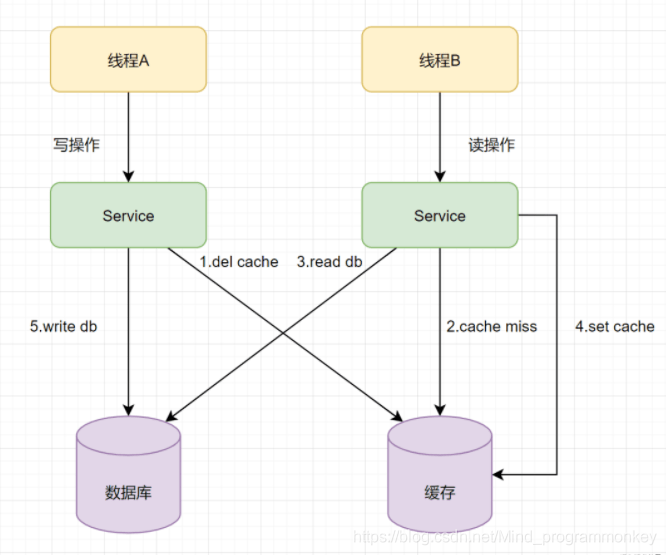
线程A发起一个写操作,第一步del cache;此时线程B发起一个读操作,cache miss;线程B继续读DB,读出来一个老数据,此时线程B把老数据设置入cache;线程A写入DB更新数据;
这里就存在这样的一个问题了:缓存和数据库的数据不一致了。缓存保存的是老数据,数据库保存的是新数据。 因此,Cache-Aside缓存模式,选择了先操作数据库而不是先操作缓存。
但可能这时候有小伙伴会思考:先操作数据库再操作缓存,不一样也会导致不一致嘛?它俩又不是原子性操作的。这个是会的。但是这种方式,一般会因为删除缓存失败等原因,才会导致脏数据,这个概率就很低。
那么针对这种删除缓存失败的情况,如何保证一致性呢?
数据库和缓存数据保持强一致,可以嘛?
实际上,没办法做到数据库和缓存的绝对的一致性。
加锁可以嘛?并发写期间加锁,任何读操作不写入缓存?缓存以及数据库封装CAS乐观锁,更新缓存时通过lua脚本?分布式事务,3PC?TCC?
其实,这是由CAP理论 决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP 。个人觉得,追求绝对一致性的业务场景,不适合引入缓存。
CAP理论,指的是在一个分布式戏中,Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性)。三者不可兼得
5 几种方案保证数据库与缓存的一致性 (1) 缓存延时双删
有些小伙伴可能会说,并不一定要先操作数据库呀,采用缓存延时双删策略,就可以保证数据的一致性拉。那么什么是延时双删呢?

先删除缓存;再更新数据库;再休眠一会(比如1秒),再次删除缓存;
那么这个休眠一会,一般多久呢?都是1秒?
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据;
这种方案还算可以,只有休眠那一会(比如就那1秒),可能有脏数据,一般业务也会接受的。但是如果第二次删除缓存失败呢?缓存和数据库的数据还是可能不一致,对吧?给Key设置一个自然的expire过期时间,让它自动过期怎样?那业务要接受过期时间内,数据的不一致咯?还是有其他更佳方案呢?
(2) 删除缓存重试机制
不管是延时双删还是Cache-Aside的先操作数据库再删除缓存, 都可能会存在第二步的删除缓存失败,导致的数据不一致问题。可以使用这个方案优化:删除失败就多删除几次呀,保证删除缓存成功就可以了呀~ 所以可以引入删除缓存重试机制。
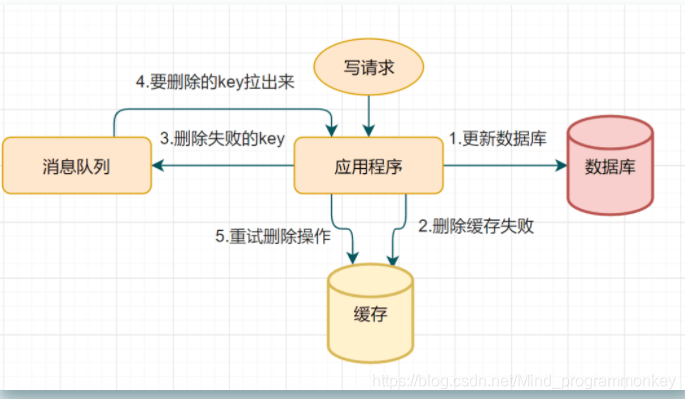
写请求更新数据库;缓存因为某些原因,删除失败;把删除失败的key放到消息队列;消费消息队列的消息,获取要删除的key;重试删除缓存操作; (3) 读取binlog异步删除缓存
重试删除缓存机制还可以,但是会造成好多业务代码入侵。其实,还可以这样优化:通过数据库的binlog来异步淘汰key。
以上就是Redis与MySQL双写一致性如何保证呢的详细内容,更多关于Redis与MySQL双写一致性的资料请关注其它相关文章!