沿途的风景美不胜收,真是让人流连忘返。人生就像一场旅行,不知道在下一站邂逅什么样的人,发生怎么样的故事!
1.Redis操作之Hash操作
redis支持五大数据类型,只支持第一层,也就说字典的value值,必须是字符串
如果value值想存字典,必须用json转换一下,转成字符串
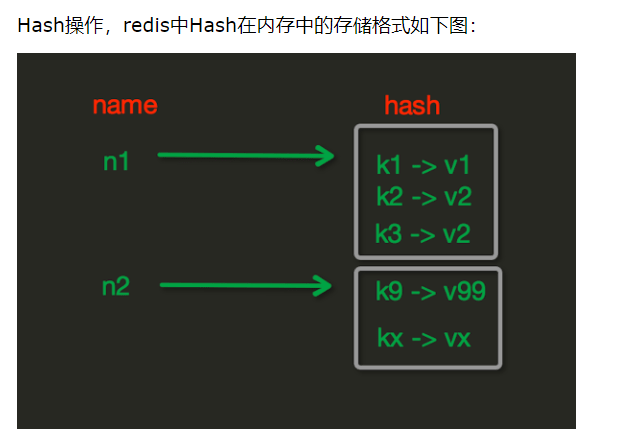
redis hash字典操作
reids:{
k1:'dafdadfasf',
m1:{
'key2':value2,
'key1':value1,
}
}
1.hset(name, key, value),插入值
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
# 设置值# conn.hset('m1','cao','曹蕊')
2.hmset(name, mapping),批量插入值
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
# 批量插入设置值# conn.hmset('m2', {'cao': 100, 'bai': 101})
3.hget(name,key),取值
# 在name对应的hash中获取根据key获取value
# 取值,根据大字典的key,再去查key
print(conn.hget('m2','cao'))
4.hmget(name, keys, *args) 批量取值
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
print(conn.hmget('m2','cao','bai'))print(conn.hmget('m2',['cao','bai']))
hlen(name)
# 获取name对应的hash中键值对的个数
# print(conn.hlen('m2'))
hkeys(name)
# 获取name对应的hash中所有的key的值
# print(conn.hkeys('m2'))
hvals(name)
# 获取name对应的hash中所有的value的值
# print(conn.hvals('m2'))
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
# print(conn.hexists('m2','cao'))
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
print(re.hdel('xxx','sex','name'))
# conn.hdel('m2','key1','key2')
# 这样可以# conn.hdel('m2',*['key1','key2'])# 这样不行# conn.hdel('m2',['key1','key2'])
hincrby用来统计一个东西的数量的频繁增加(name, key, amount=1)
hincrby应用场景:
统计文章阅读数:key是文章id,value是文章阅读数,有一个阅读者,数字加一,固定一个时间,将数据同步到数据库,一定要写日志,避免出错,还能查找到
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
conn.hincrby('m1','key3')
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hgetall(name)——慎用,一次性取出数据前需要先hlen看下长度
# 获取name对应hash的所有键值
print(re.hgetall('xxx').get(b'name'))
# 根据key把所有的值取出来
# print(conn.hgetall('m2'))
hscan_iter(name, match=None, count=None),增量迭代取值
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
应用场景: 比如我redis中字典有10000w条数据,全部都打印出来 hscan——指定游标,然后取多少值
for i in range(1000):
conn.hset('m2','key%s'%i,'value%s'%i)
指定每次取10条,直到取完
ret=conn.hscan_iter('m2',count=100)
不要用这种方式,一下全部取出,redis可能会被撑爆,或者先用len查看下长度再决定使用getall或者其他
ret=conn.hgetall('m2')
hscan(name, cursor=0, match=None, count=None)——指定游标,然后取多少数据
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
到此这篇关于redis中Hash字典操作的方法的文章就介绍到这了,更多相关redis Hash字典操作内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!