前言
哈希结构是一个在计算机中非常常见的结构。哈希结构可以让我们在O(1)时间复杂度查找元素并且对其操作,并且增删改查性能并不会随着数据量的增多而改变。反而数据量的增大,会出现两个关键问题,一个是哈希冲突,另一个是rehash。而在Redis中,使用拉链法来解决哈希冲突,使用渐进式rehash来降低rehash的性能开销。
Redis中的Dict结构
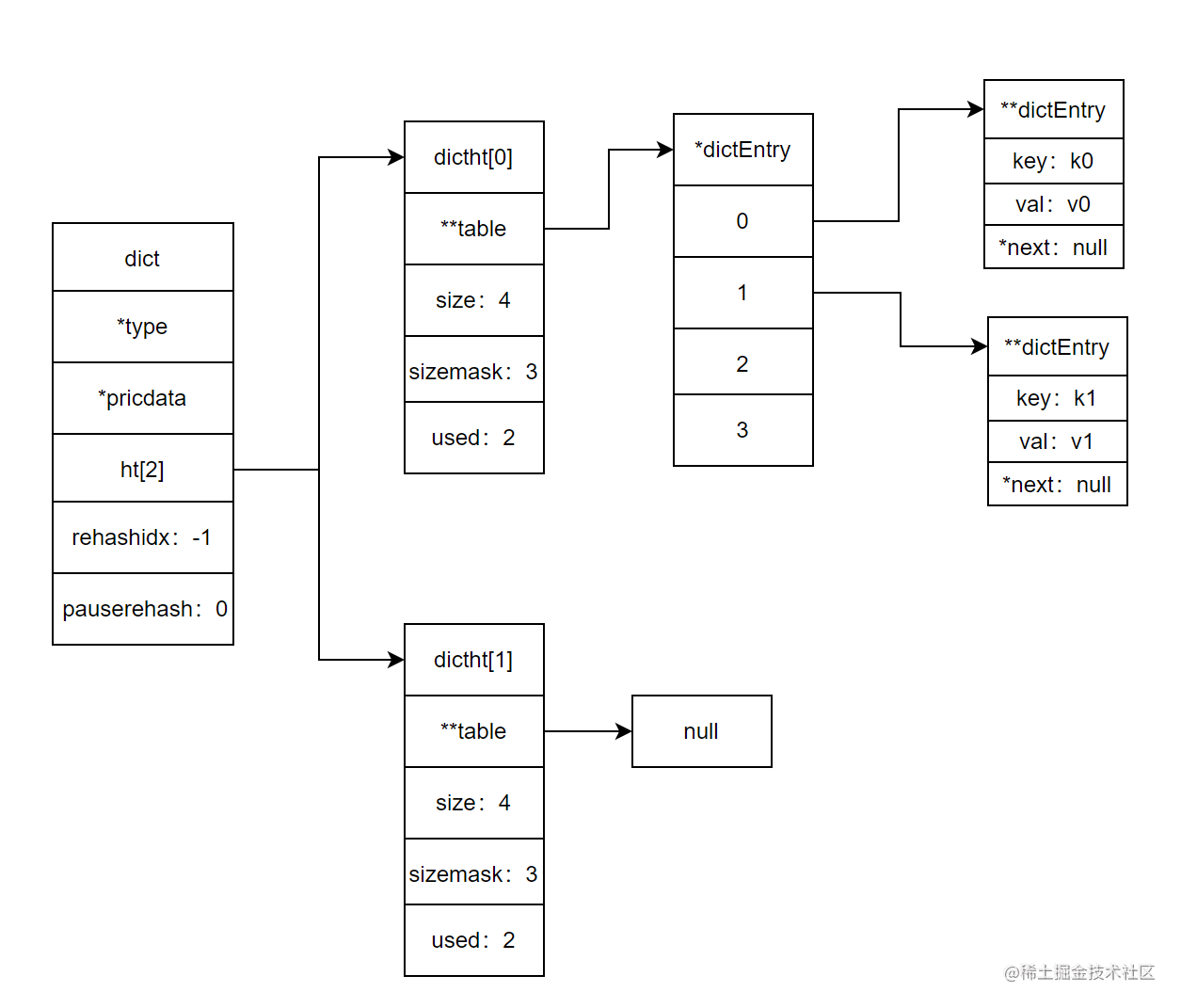
在Redis 6.2.4中,dict.h是这样定义的。
typedef struct dictEntry {
void *key;
//只能为其中任意的一个
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; //-1未进行rehash
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
} dict;它们的关系是这样的
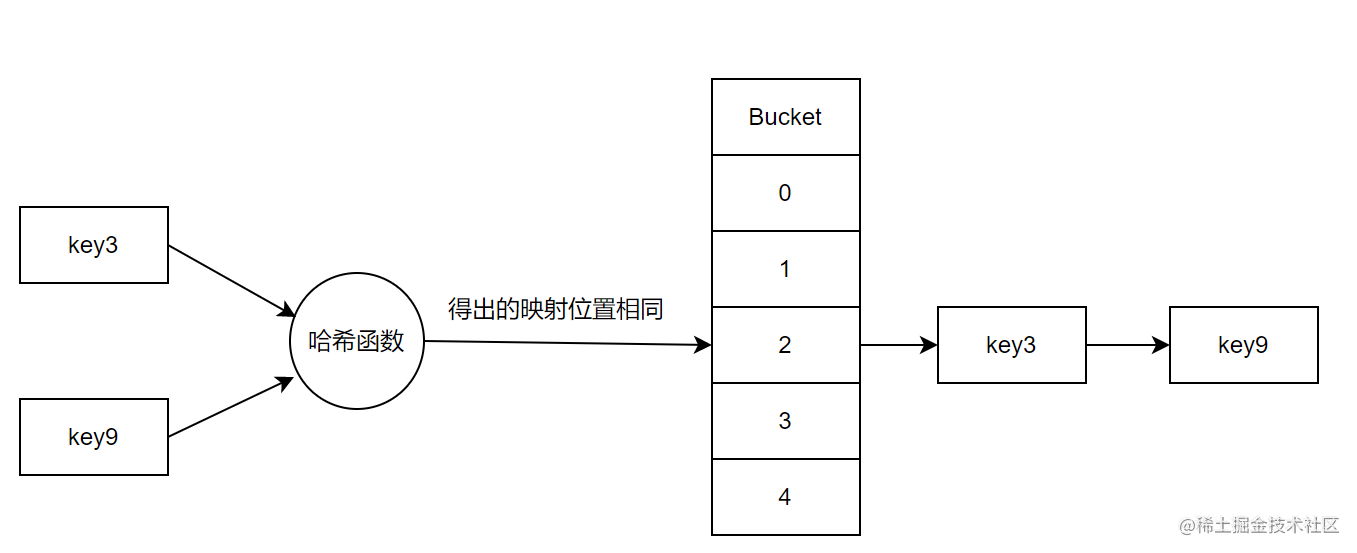
什么是哈希冲突
我们把存储数据的地方看成一个个桶(Bucket),当数据量超出桶容量或者Hash函数给出的桶号相同的时候,便会出现哈希冲突。解决办法就是,采用链表的方式,将同一个Bucket位置上的元素连接起来。这样也会有一个弊端,链表太长,开销又大了起来。所以必定不会无休止的链下去,一定要做rehash。
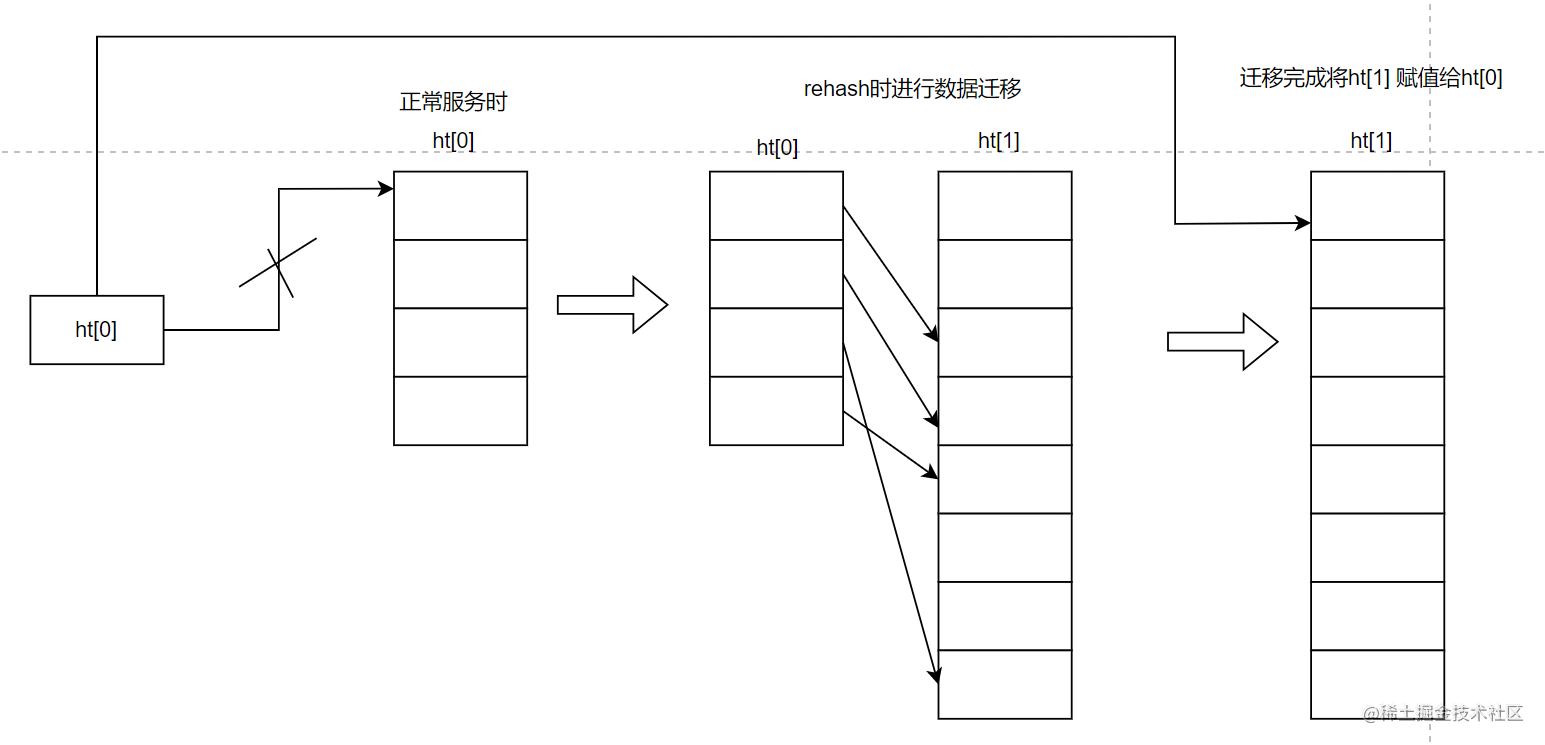
Redis的渐进式rehash
Hash 表在执行 rehash 时,由于 Hash 表空间扩大,原本映射到某一位置的键可能会被映射到一个新的位置上,因此,很多键就需要从原来的位置拷贝到新的位置。而在键拷贝时,由于 Redis 主线程无法执行其他请求,所以键拷贝会阻塞主线程,这样就会产生 rehash 开销。而为了降低 rehash 开销,Redis 就提出了渐进式 rehash 的方法。观察dict结构,它存储了两个相同的dictht, 在正常情况下,所有的数据都存储在ht[0]中。在进行rehash时,会先将数据迁移到ht[1]中,等到所有数据都迁移完成时,将ht[1] 赋值给ht[0],并且释放掉ht[0]空间。
rehash的触发条件
Redis 用来判断是否触发 rehash 的函数是**_dictExpandIfNeeded**。所以接下来我们就先看看,_dictExpandIfNeeded 函数中进行扩容的触发条件;
//如果Hash表为空,将Hash表扩为初始大小
if (d->ht[0].size == 0)
return dictExpand(d, DICT_HT_INITIAL_SIZE);
//如果Hash表承载的元素个数超过其当前大小,并且可以进行扩容,或者Hash表承载的元素个数已是当前大小的5倍
if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE(RDB快照) 或者 BGREWRITEAOF(AOF重写) 等后台进程;
- 哈希表的 LoadFactor > 5 ,表明当前的负载太严重了,需要立即进行扩容;(LoadFactor = used / size)
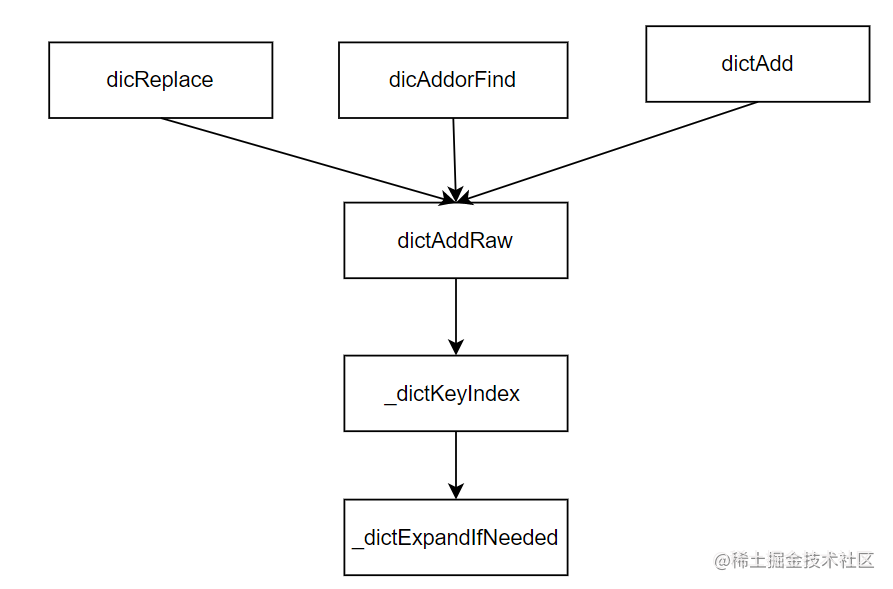
我们再来看下 Redis 会在哪些函数中,调用 _dictExpandIfNeeded 进行判断。通过在dict.c文件中查看 _dictExpandIfNeeded 的被调用关系,我们可以发现,_dictExpandIfNeeded 是被 _dictKeyIndex 函数调用的,而 _dictKeyIndex 函数又会被 dictAddRaw 函数调用,然后 dictAddRaw 会被以下三个函数调用。
- dictAdd:用来往 Hash 表中添加一个键值对。
- dictReplace:用来往 Hash 表中添加一个键值对,或者键值对存在时,修改键值对。
- dictAddorFind:直接调用 dictAddRaw。
因此,当我们往 Redis 中写入新的键值对或是修改键值对时,Redis 都会判断下是否需要进行 rehash。
扩容扩多大?
在 Redis 中,rehash 对 Hash 表空间的扩容是通过调用 dictExpand 函数来完成的。dictExpand 函数的参数有两个,一个是要扩容的 Hash 表,另一个是要扩到的容量,下面的代码就展示了 dictExpand 函数的原型定义:
int dictExpand(dict *d, unsigned long size);
那么,对于一个 Hash 表来说,我们就可以根据前面提到的 _dictExpandIfNeeded 函数,来判断是否要对其进行扩容。而一旦判断要扩容,Redis 在执行 rehash 操作时,对 Hash 表扩容的思路也很简单,就是如果当前表的已用空间大小为 size,那么就将表扩容到 size2 的大小。
如下所示,当 _dictExpandIfNeeded 函数在判断了需要进行 rehash 后,就调用 dictExpand 进行扩容。这里你可以看到,rehash 的扩容大小是当前 ht[0]已使用大小的 2 倍。
dictExpand(d, d->ht[0].used*2);
而在 dictExpand 函数中,具体执行是由 _dictNextPower 函数完成的,以下代码显示的 Hash 表扩容的操作,就是从 Hash 表的初始大小(DICT_HT_INITIAL_SIZE),不停地乘以 2,直到达到目标大小。
static unsigned long _dictNextPower(unsigned long size)
{
//哈希表的初始大小
unsigned long i = DICT_HT_INITIAL_SIZE;
//如果要扩容的大小已经超过最大值,则返回最大值加1
if (size >= LONG_MAX) return LONG_MAX + 1LU;
//死循环直到找到不大于的最小值
while(1) {
//如果扩容大小大于等于最大值,就返回截至当前扩到的大小
if (i >= size)
return i;
//每一步扩容都在现有大小基础上乘以2
i *= 2;
}
}为什么叫渐进式
渐进式 rehash 的意思就是 Redis 并不会一次性把当前 Hash 表中的所有键,都拷贝到新位置,而是会分批拷贝,每次的键拷贝只拷贝 Hash 表中一个 bucket 中的哈希项。这样一来,每次键拷贝的时长有限,对主线程的影响也就有限了。
具体过程
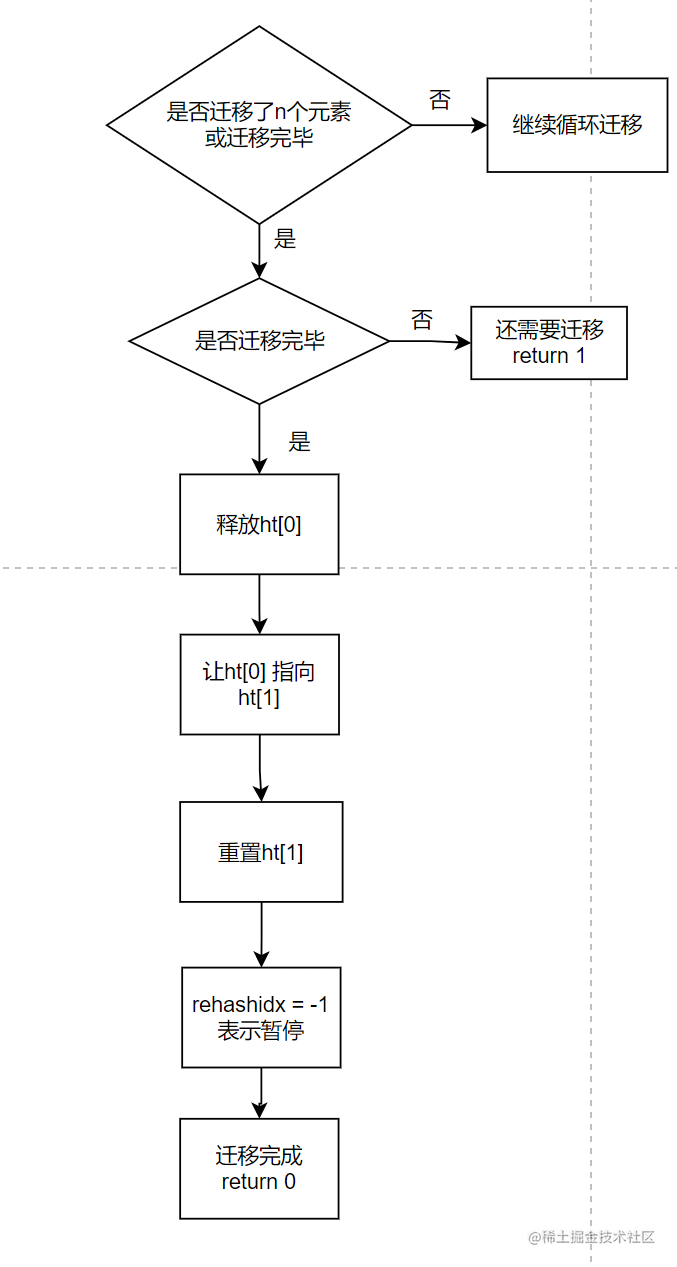
关键函数dictRehash部分代码
//入参:dict , 需要迁移的元素个数
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
//迁移元素,直到迁移完毕或者迁移完n个
while(n-- && d->ht[0].used != 0) {
//....这段代码在下面分析
}
/* Check if we already rehashed the whole table... */
//判断迁移是否完成
if (d->ht[0].used == 0) {
//释放ht[0]
zfree(d->ht[0].table);
//将ht[0] 指向 ht[1]
d->ht[0] = d->ht[1];
//让ht[1]重新指向null
_dictReset(&d->ht[1]);
//表示rehash暂停
d->rehashidx = -1;
//返回迁移完成
return 0;
}
//还需要继续迁移
/* More to rehash... */
return 1;
}那么,每次迁移几个元素呢?
这就要提到rehashidx了。rehashidx 变量表示的是当前 rehash 在对哪个 bucket 做数据迁移。比如,当 rehashidx 等于 0 时,表示对 ht[0]中的第一个 bucket 进行数据迁移;当 rehashidx 等于 1 时,表示对 ht[0]中的第二个 bucket 进行数据迁移,以此类推。
而 dictRehash 函数的主循环,首先会判断 rehashidx 指向的 bucket 是否为空,如果为空,那就将 rehashidx 的值加 1,检查下一个 bucket。
所以,渐进式 rehash 在执行时设置了一个变量 empty_visits,用来表示已经检查过的空 bucket,当检查了一定数量的空 bucket 后,这一轮的 rehash 就停止执行,转而继续处理外来请求,避免了对 Redis 性能的影响。下面的代码显示了这部分逻辑。
while(n-- && d->ht[0].used != 0) {
//如果当前要迁移的bucket中没有元素
while(d->ht[0].table[d->rehashidx] == NULL) {
//
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
...
}而如果 rehashidx 指向的 bucket 有数据可以迁移,那么 Redis 就会把这个 bucket 中的哈希项依次取出来,并根据 ht[1]的表空间大小,重新计算哈希项在 ht[1]中的 bucket 位置,然后把这个哈希项赋值到 ht[1]对应 bucket 中。
这样,每做完一个哈希项的迁移,ht[0]和 ht[1]用来表示承载哈希项多少的变量 used,就会分别减一和加一。当然,如果当前 rehashidx 指向的 bucket 中数据都迁移完了,rehashidx 就会递增加 1,指向下一个 bucket。下面的代码显示了这一迁移过程。
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}还有一个问题,n的大小是多少?从下面这个函数可以看到,是1。每次仅仅迁移一个元素,之后变去执行主要操作。
static void _dictRehashStep(dict *d) {
if (d->pauserehash == 0) dictRehash(d,1);
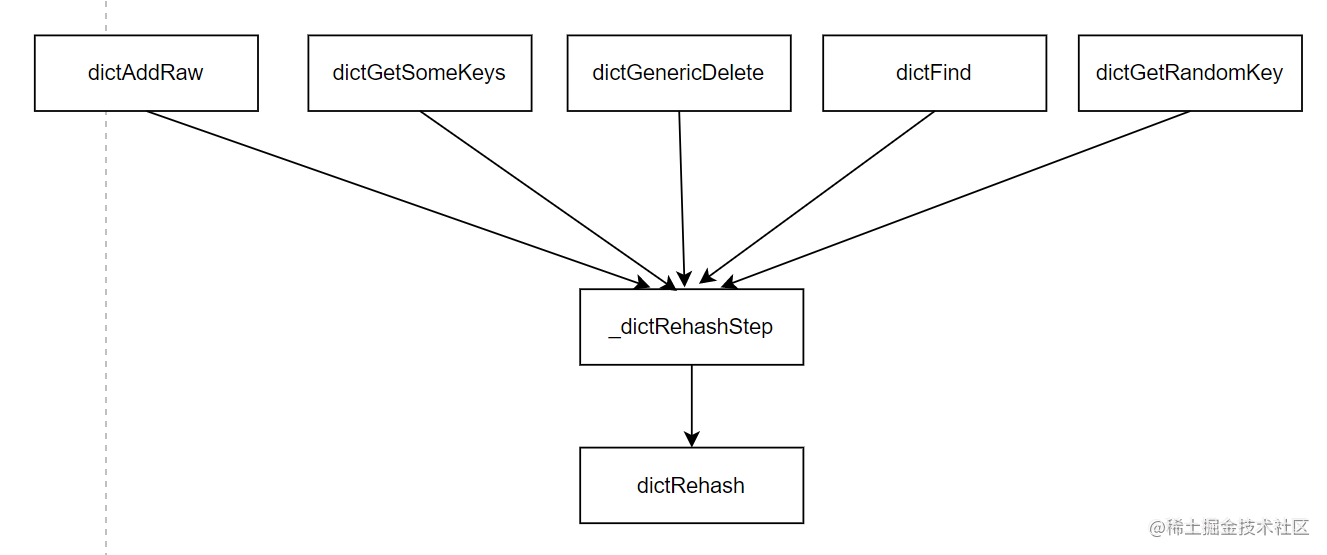
}看看有哪些函数调用了_dictRehashStep,Ctrl+F找一下。它们发现分别是:dictAddRaw,dictGenericDelete,dictFind,dictGetRandomKey,dictGetSomeKeys。其中,dictAddRaw 和 dictGenericDelete 函数,分别对应了往 Redis 中增加和删除键值对,而后三个函数则对应了在 Redis 中进行查询操作。调用关系如下图。
总结
什么是渐进式rehash?为什么要设计两个ht?
Redis核心命令执行是单线程的,所以一次性迁移全部数据开销很大并且会阻塞服务。在需要rehash的时候,不会立即将全部数据进行迁移,而是通过辅助表来慢慢进行迁移,每次迁移1个元素,进行正常服务的时候,在ht[1]中进行添加操作,其他操作在ht[0]和ht[1]中一起进行。
rehashidx有什么用?
为-1的时候表示没有rehash,为0的时候表示要迁移ht[0]中0号元素到ht[1]中,后续依次类推
rehash触发条件?
扩容或者收缩
dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- 当LoadFactor小于0.1时,Dict收缩
- 扩容大小为第一个大于等于used + 1的2^n
- 收缩大小为第一个大于等于used 的2^n
- dict采用渐进式rehash,每次访问Dict时执行一次rehash
到此这篇关于Redis中哈希结构(Dict)的实现的文章就介绍到这了,更多相关Redis 哈希结构 内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!