缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。常见的解决方案有:
- 互斥锁 - 逻辑过期 - key 永不过期 - 接口限流
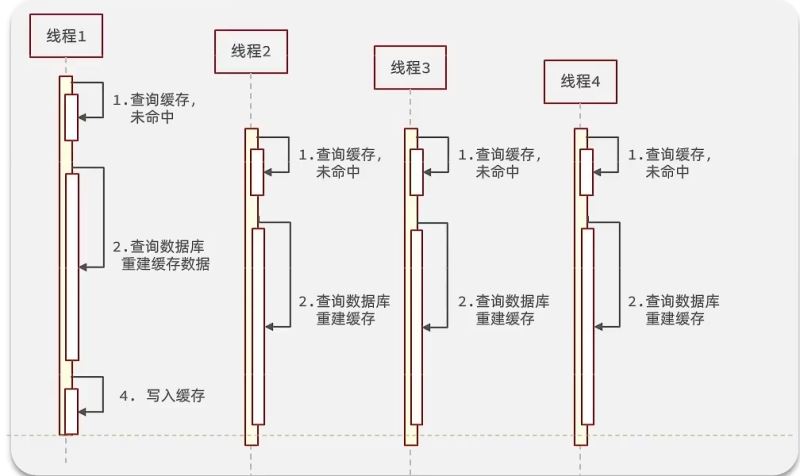
逻辑分析:假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力非常大。
解决方案一、使用锁来解决:
因为锁能实现互斥性。假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,我们可以采用 tryLock 方法 + double check 来解决这样的问题。假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。

解决方案二、逻辑过期方案
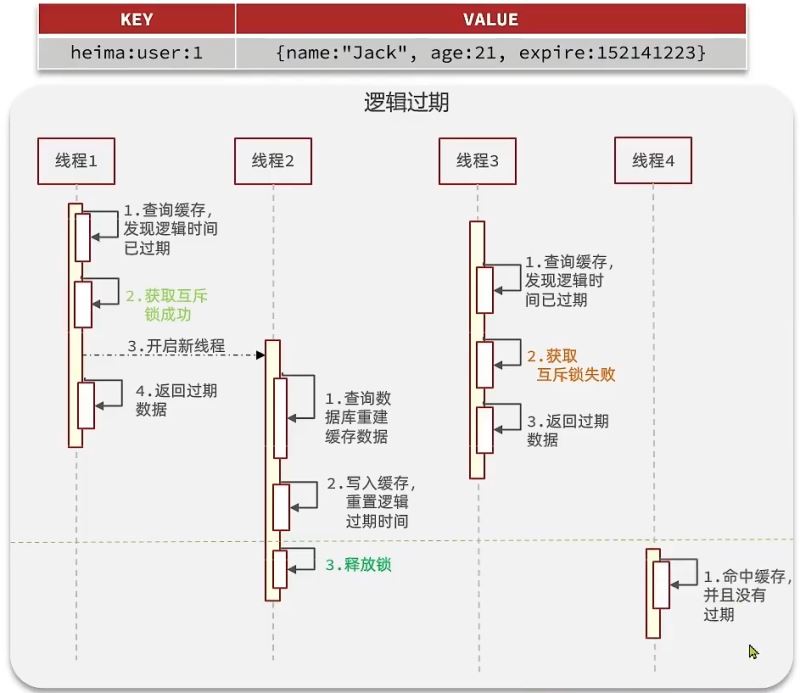
方案分析:我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们内存了吗,我们可以采用逻辑过期方案。我们把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个 线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回,假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
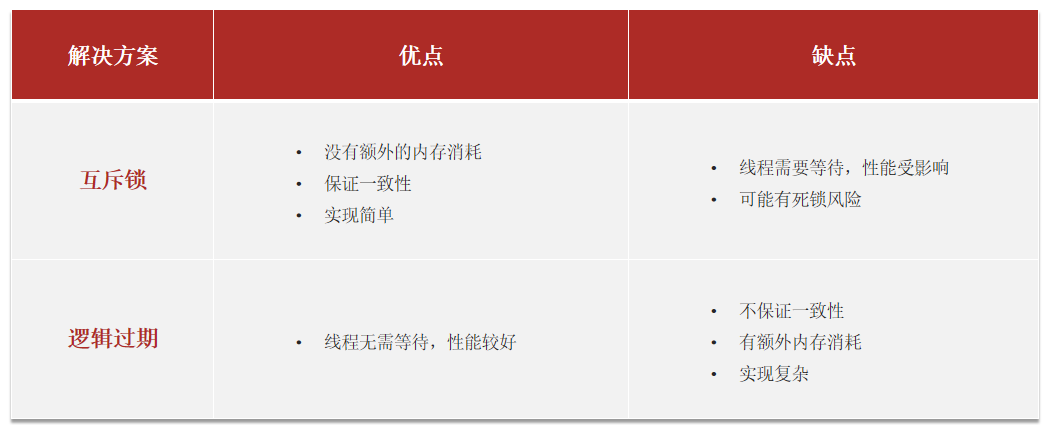
进行对比互斥锁方案由于保证了互斥性,所以数据一致,且实现简单,因为仅仅只需要加一把锁而已,也没其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行性能肯定受到影响逻辑过期方案: 线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回之前的数据,且实现起来麻烦。
解决方案三、永不过期 主动更新
解决方案四、接口限流
利用互斥锁解决缓存击穿问题
核心思路:相较于原来从缓存中查询不到数据后直接查询数据库而言,现在的方案是 进行查询之后,如果从缓存没有查询到数据,则进行互斥锁的获取,获取互斥锁后,判断是否获得到了锁,如果没有获得到,则休眠,过一会再进行尝试,直到获取到锁为止,才能进行查询如果获取到了锁的线程,再去进行查询,查询后将数据写入redis,再释放锁,返回数据,利用互斥锁就能保证只有一个线程去执行操作数据库的逻辑,防止缓存击穿。

操作锁的代码:核心思路就是利用 redis 的 setnx 方法来表示获取锁,该方法含义是redis中如果没有这个 key,则插入成功,返回1,在 stringRedisTemplate 中返回 true, 如果有这个 key 则插入失败,则返回0,在stringRedisTemplate 返回 false,我们可以通过 true,或者是 false,来表示是否有线程成功插入 key,成功插入的 key 的线程我们认为他就是获得到锁的线程。
private boolean tryLock(String key, String value, long time) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, value, time, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
private void unlock(String key) {
stringRedisTemplate.delete(key);
}操作锁要注意对 value 加入标识,在释放锁之前对其进行判断是不是自己的锁,防止误删!(还要保证判断语句和释放语句的原子性 可以用 lua 脚本)
核心代码:
public Shop queryWithMutex(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1、从redis中查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get("key");
// 2、判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 存在,直接返回
return JSONUtil.toBean(shopJson, Shop.class);
}
//判断命中的值是否是空值
if (shopJson != null) {
//返回一个错误信息
return null;
}
// 4.实现缓存重构
//4.1 获取互斥锁
String lockKey = "lock:shop:" + id;
long current_thread_id = Thread.currentThread().getId();
Shop shop = null;
try {
boolean isLock = tryLock(lockKey, current_thread_id, 10);
// 4.2 判断否获取成功
if(!isLock){
//4.3 失败,则休眠重试
Thread.sleep(50);
return queryWithMutex(id);
}
//4.4 成功,根据id查询数据库
shop = getById(id);
// 5.不存在,返回错误
if(shop == null){
//将空值写入redis
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
//返回错误信息
return null;
}
//6.写入redis
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES);
}catch (Exception e){
throw new RuntimeException(e);
}
finally {
//7.释放互斥锁
Object o = stringRedisTemplate.opsForValue().get(key);
if(o != null && (String)o.equals(current_thread_id)){
unlock(lockKey);
}
}
return shop;
}利用逻辑过期解决缓存击穿问题
缓存穿透
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有以下几种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
- id 格式校验
缓存空对象
思路分析:
当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库。因为数据库能够承载的并发不如 redis 这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到 redis 中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了。
布隆过滤
我们可以将数据库的数据,所对应的id写入到一个list集合中,当用户过来访问的时候,我们直接去判断list中是否包含当前的要查询的数据,如果说用户要查询的id数据并不在list集合中,则直接返回,如果list中包含对应查询的id数据,则说明不是一次缓存穿透数据,则直接放行。
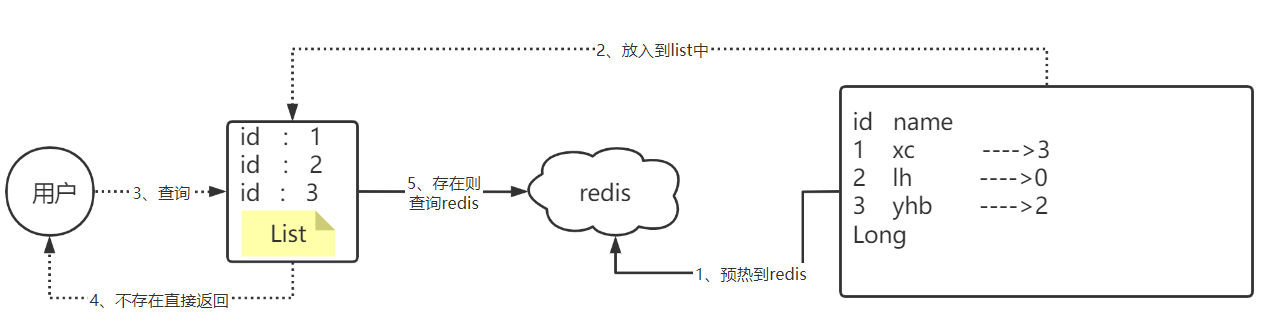
现在的问题是这个主键其实并没有那么短,而是很长的一个 主键哪怕你单独去提取这个主键,但是在11年左右,淘宝的商品总量就已经超过10亿个所以如果采用以上方案,这个list也会很大,所以我们可以使用bitmap来减少list的存储空间我们可以把list数据抽象成一个非常大的bitmap,我们不再使用list,而是将db中的id数据利用哈希思想,比如:id % bitmap.size = 算出当前这个id对应应该落在bitmap的哪个索引上,然后将这个值从0变成1,然后当用户来查询数据时,此时已经没有了list,让用户用他查询的id去用相同的哈希算法, 算出来当前这个id应当落在bitmap的哪一位,然后判断这一位是0,还是1,如果是0则表明这一位上的数据一定不存在, 采用这种方式来处理,需要重点考虑一个事情,就是误差率,所谓的误差率就是指当发生哈希冲突的时候,产生的误差。
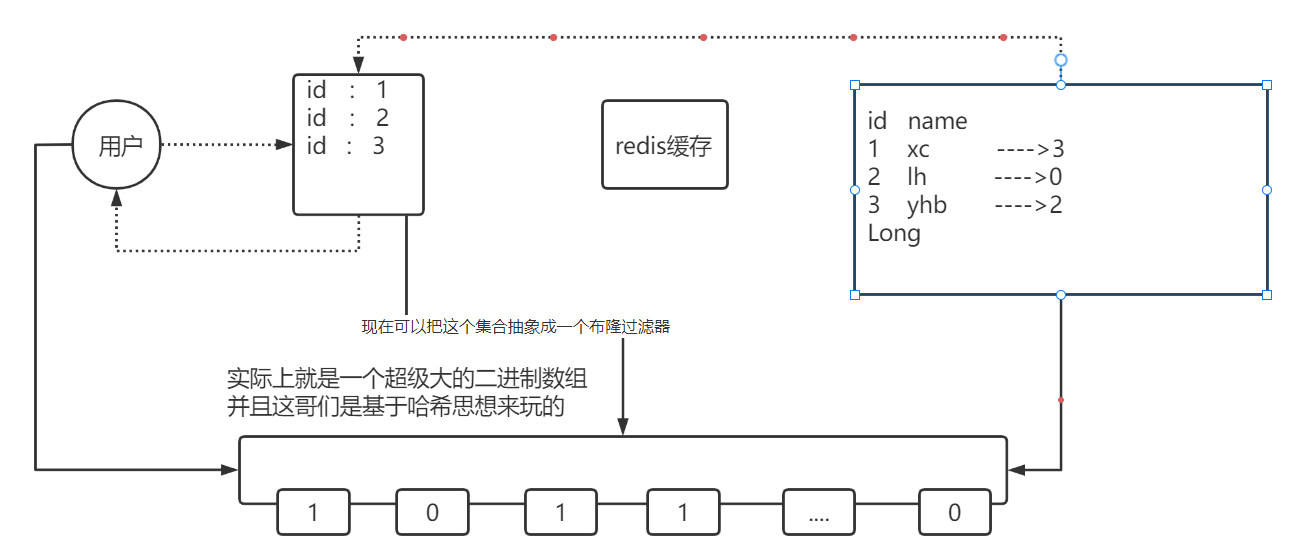
id 格式校验
将客户端传来的 id 做校验比如:
if(id < 1 || id > Integer.MIN_VALUE){
return null;
}具体校验根据业务来。
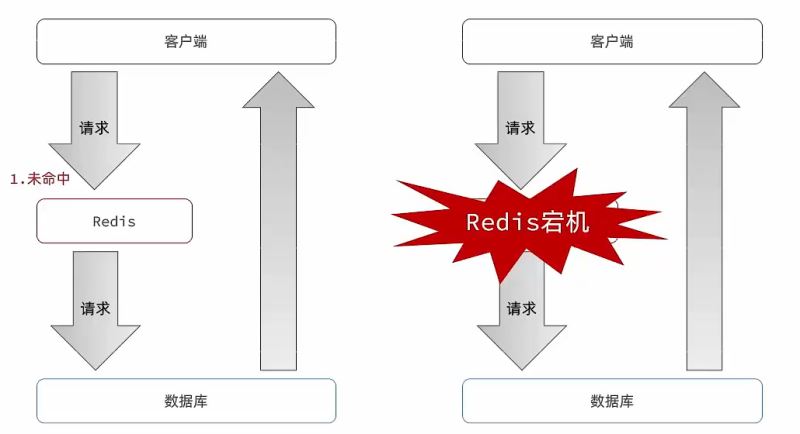
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
以上就是Redis解决缓存雪崩、穿透和击穿的问题(Redis使用必看)的详细内容,更多关于Redis解决缓存雪崩、穿透和击穿的资料请关注好代码网其它相关文章!