一、介绍
官方文档:中文2 3版本
下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy
一、介绍
官方文档:中文2.3版本
下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的。
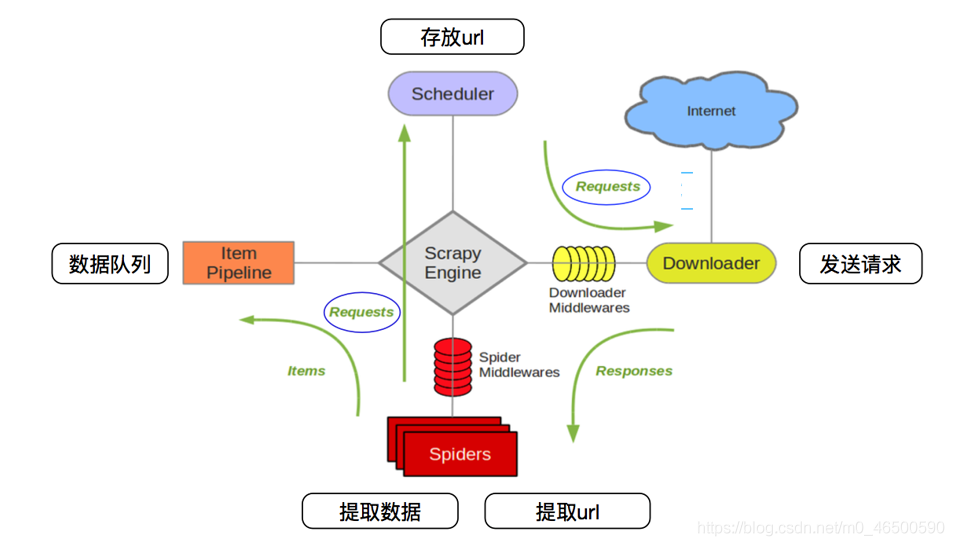
二、基本使用
2.1 环境安装
1.linux和mac操作系统:
pip install scrapy
2.windows系统:
- 先安装wheel:
pip install wheel - 下载twisted:下载地址
- 安装twisted:
pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd64.whl(记得带后缀) pip install pywin32pip install scrapy
3.Anaconda(推荐)
在我一开始学python使用的就是python3.8,在安装各种库的时候,总会有各种报错,真的有点让人奔溃。Anaconda在安装过程中就会安装一些常用的库,其次,当我们想要安装其他库时也很方便。当然大家也可以选择安装其他的一些软件,
2.2 scrapy使用流程
这里默认大家已经安装好scrapy库,大家要记得要在命令行里输入以下命令啊。(我使用的anaconda的命令行)
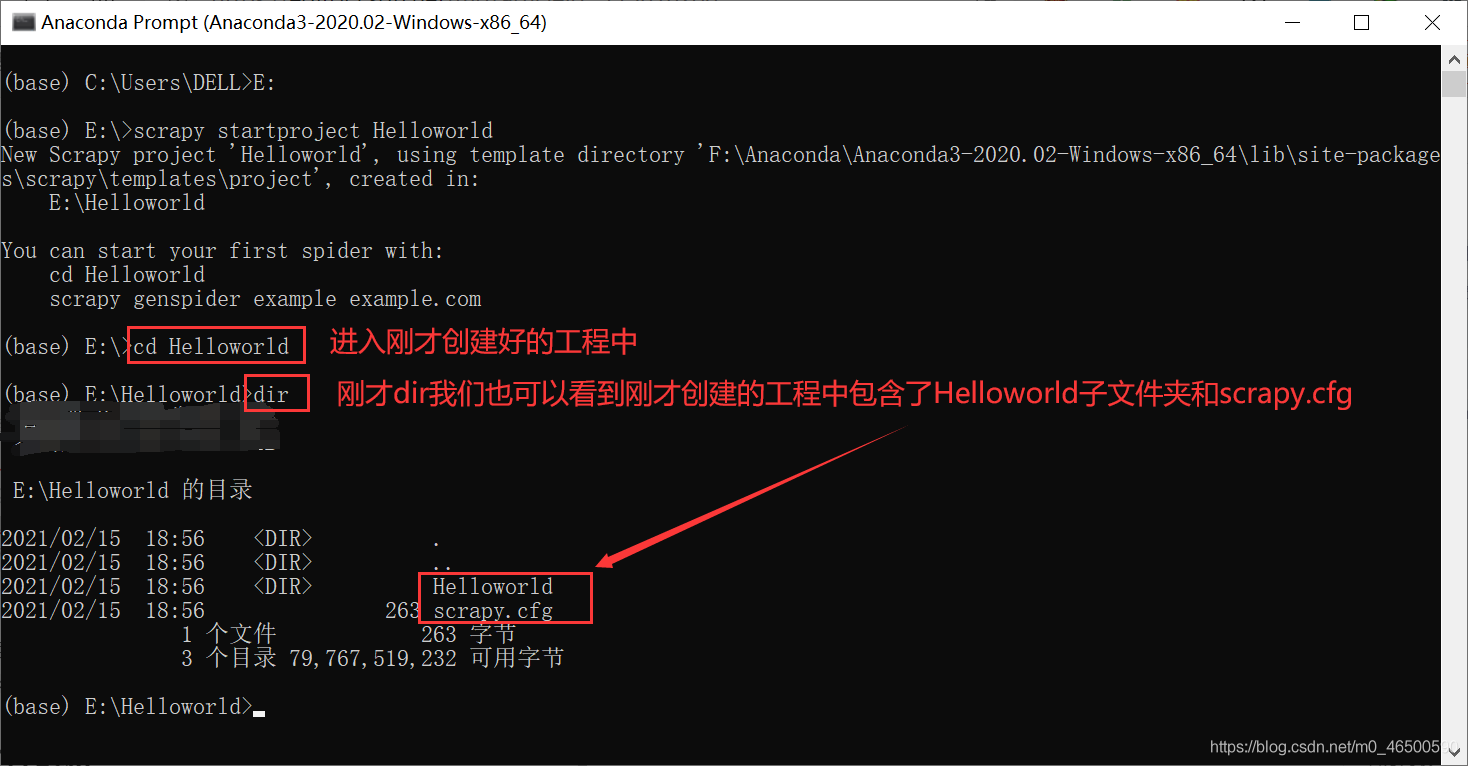
创建工程
scrapy startproject projectName
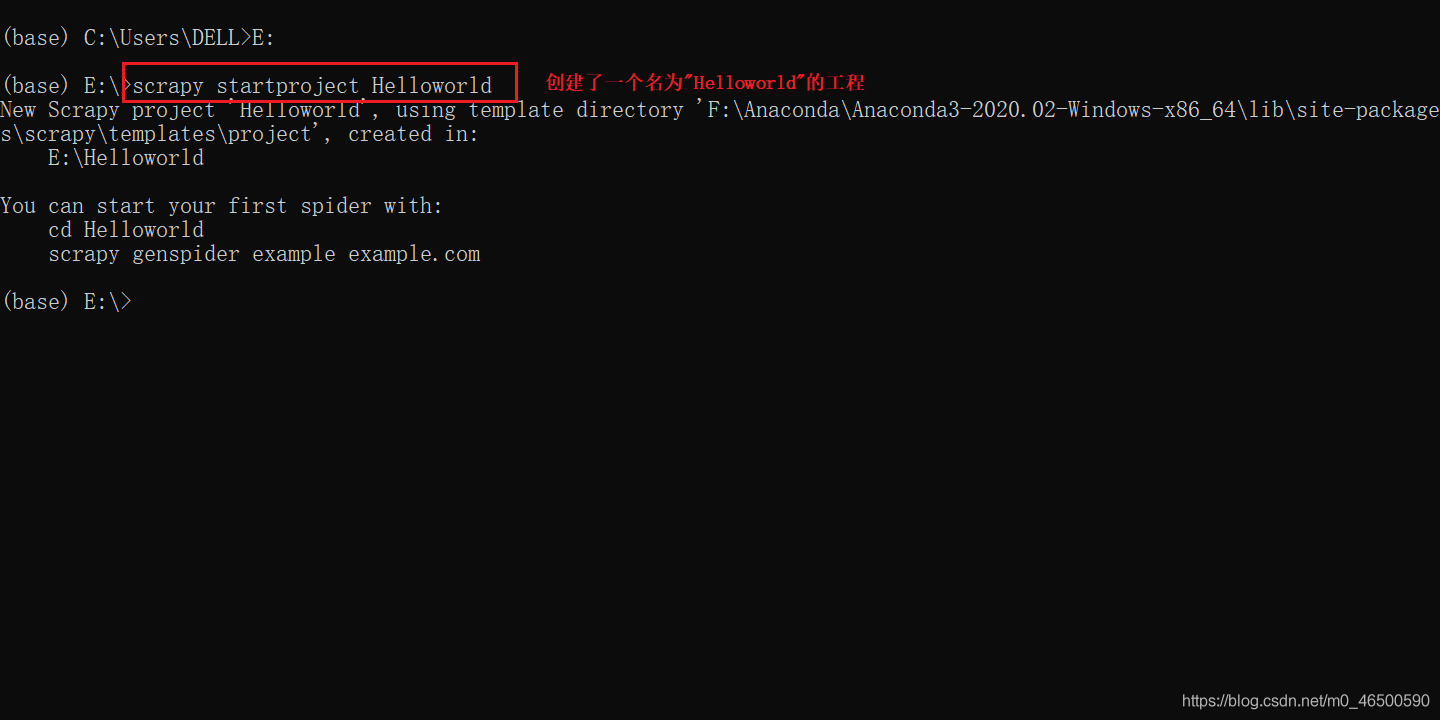
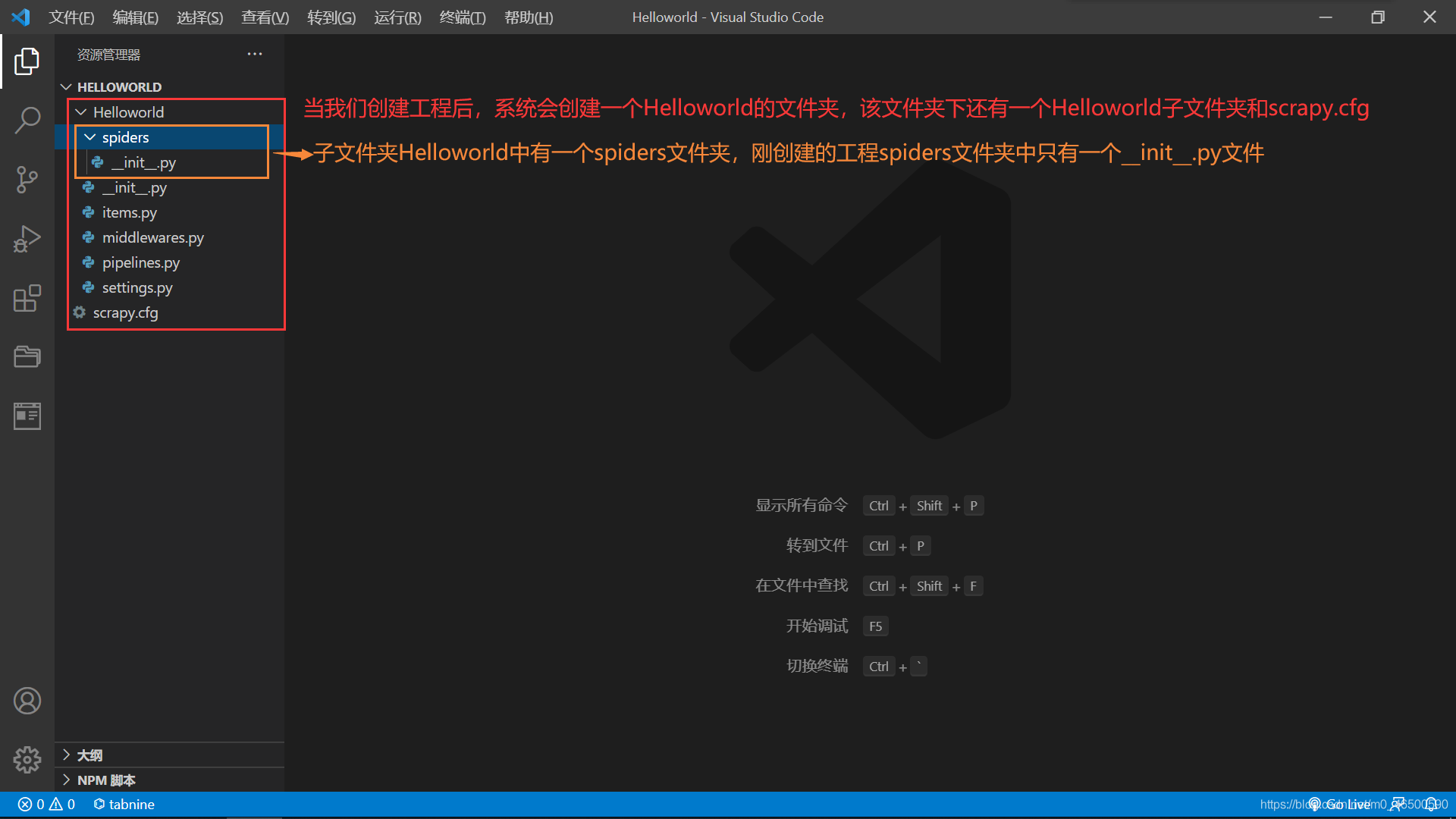
进入工程目录:这里一定要进入到刚才创建好的目录中
cd projectName
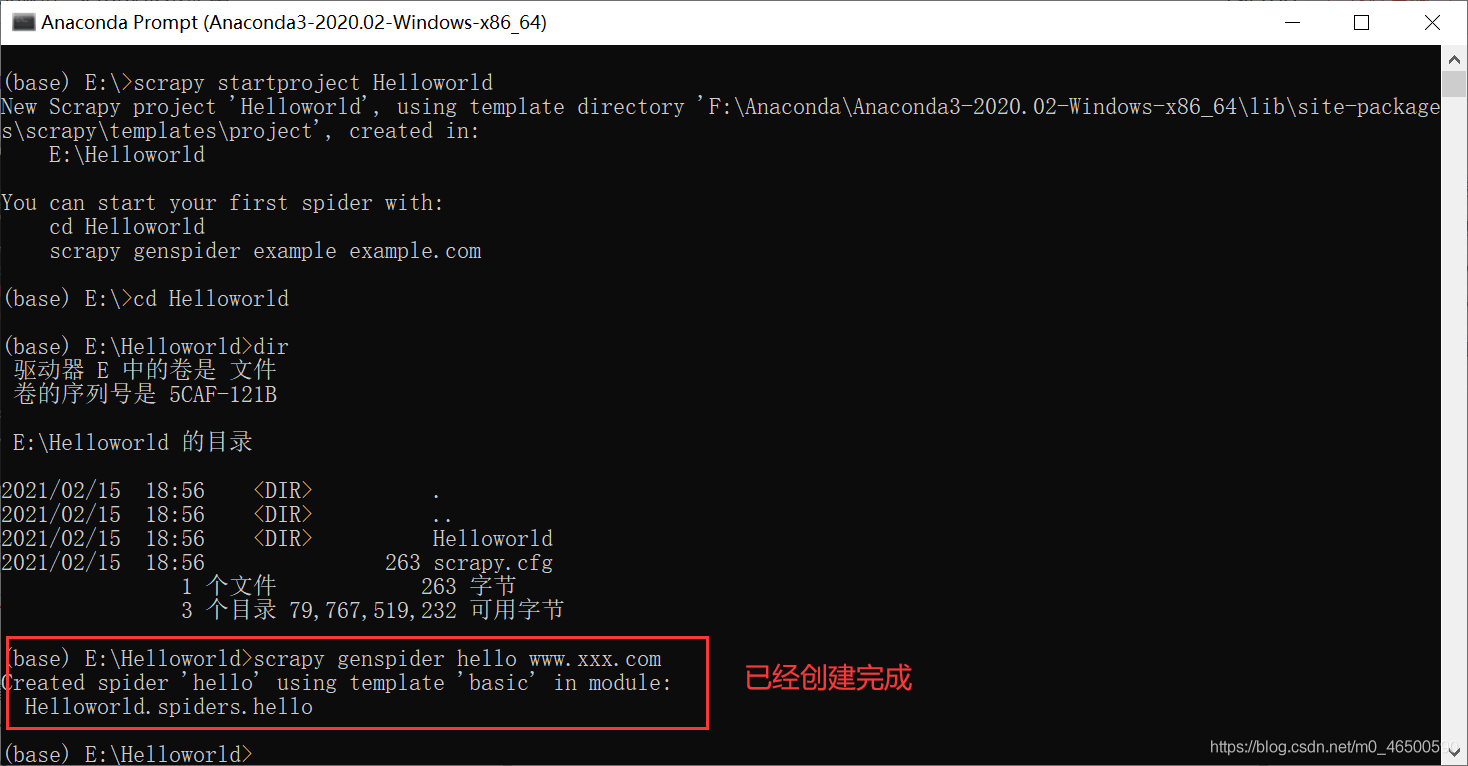
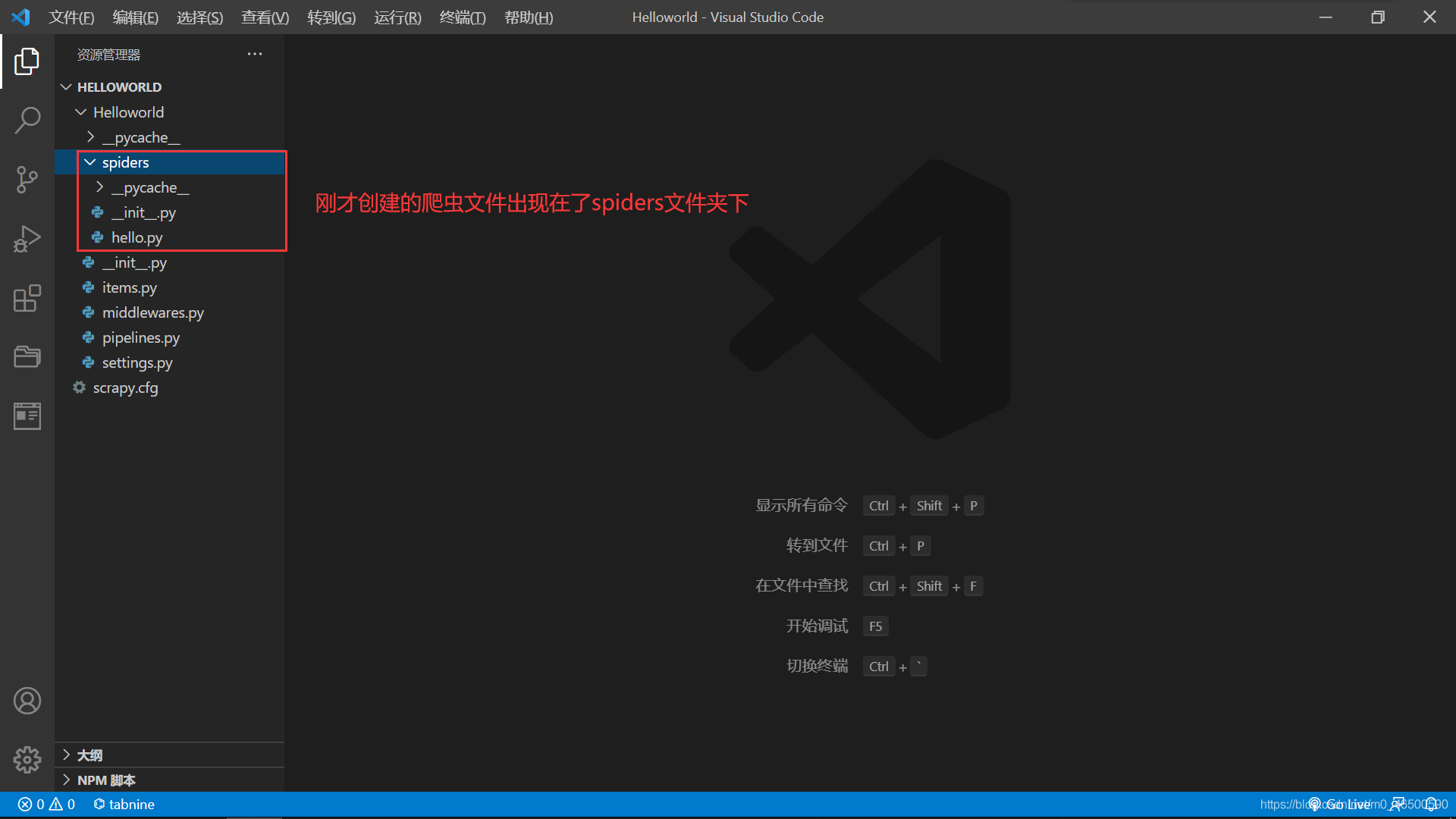
创建爬虫文件:创建的爬虫文件会出现在之前创建好的spiders文件夹下
scrapy genspider spiderName www.xxx.com
编写相关代码
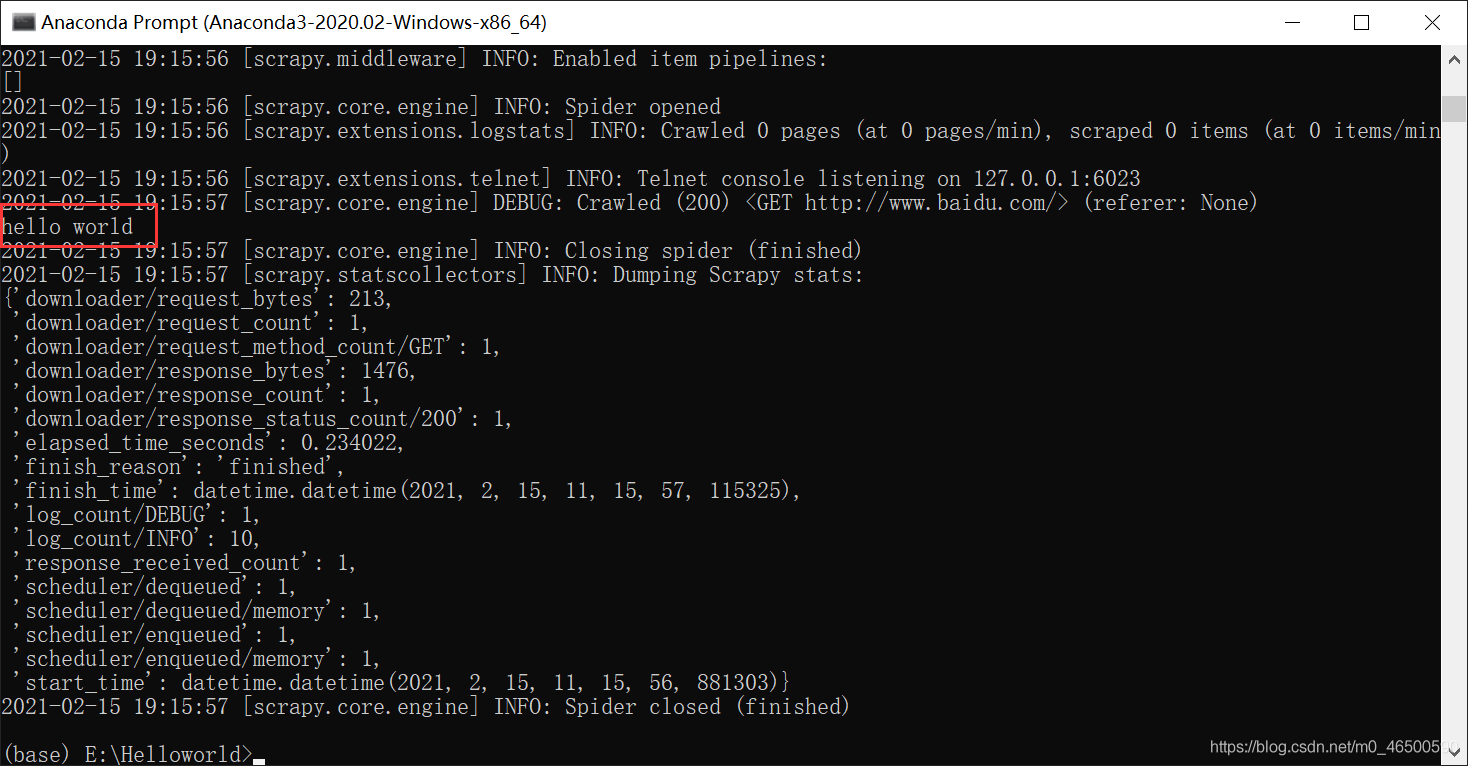
执行爬虫文件
scrapy crawl spiderName
2.3 文件解析
import scrapy
class HelloSpider(scrapy.Spider):
name = 'hello' # 爬虫名称
# 允许的域名:限定start_urls列表当中哪些url可以进行请求的发送
# 通常情况下我们不会使用
# allowed_domains = ['www.baidu.com']
# 起始的url列表:scrapy会自动对start_urls列表中的每一个url发起请求
# 我们可以手动添加我们需要访问的url
start_urls = ['https://www.baidu.com/','https://www.csdn.net/']
def parse(self, response): # 当scrapy自动向start_urls中的每一个url发起请求后,会将响应对象保存在response对象中
# 代码一般是在parse方法中写
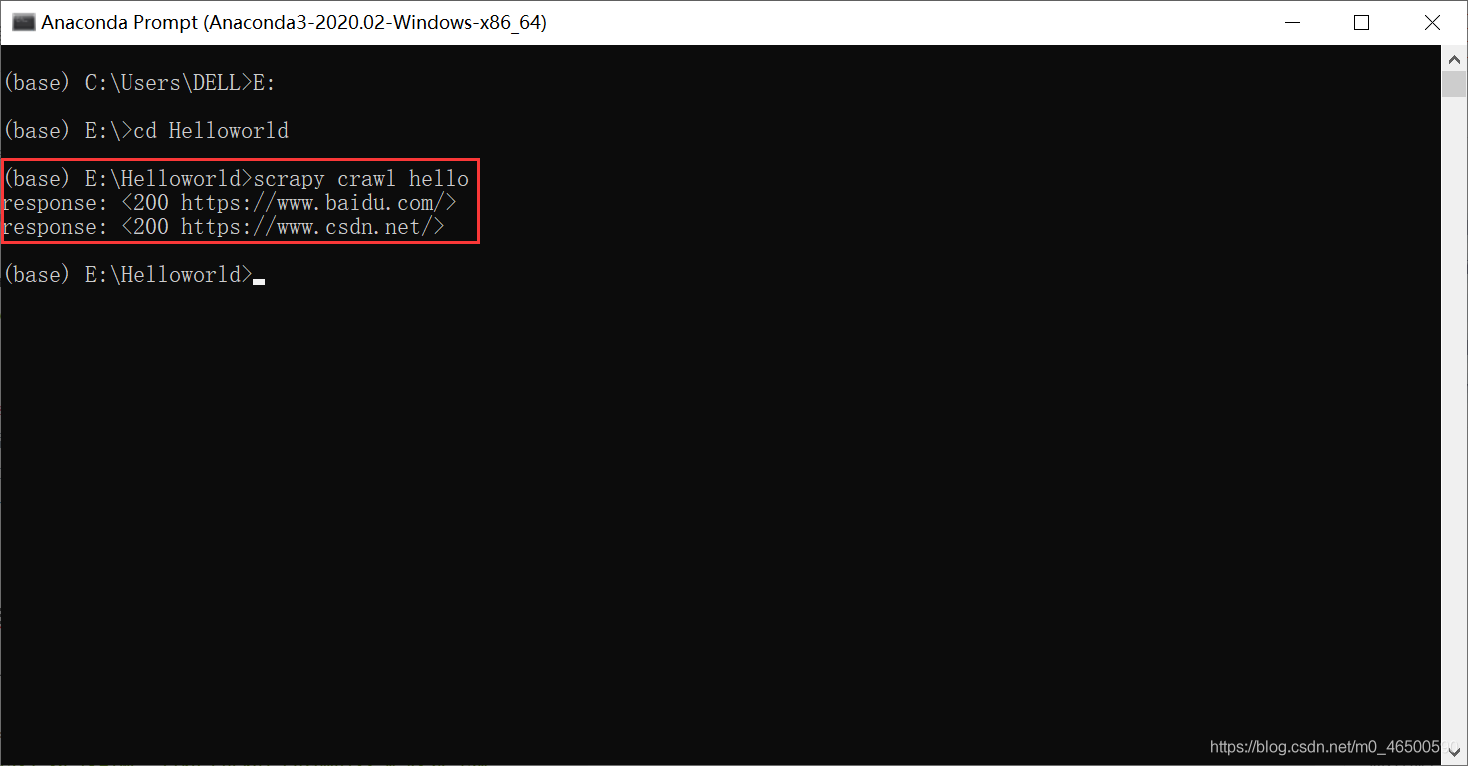
print("response:",response)
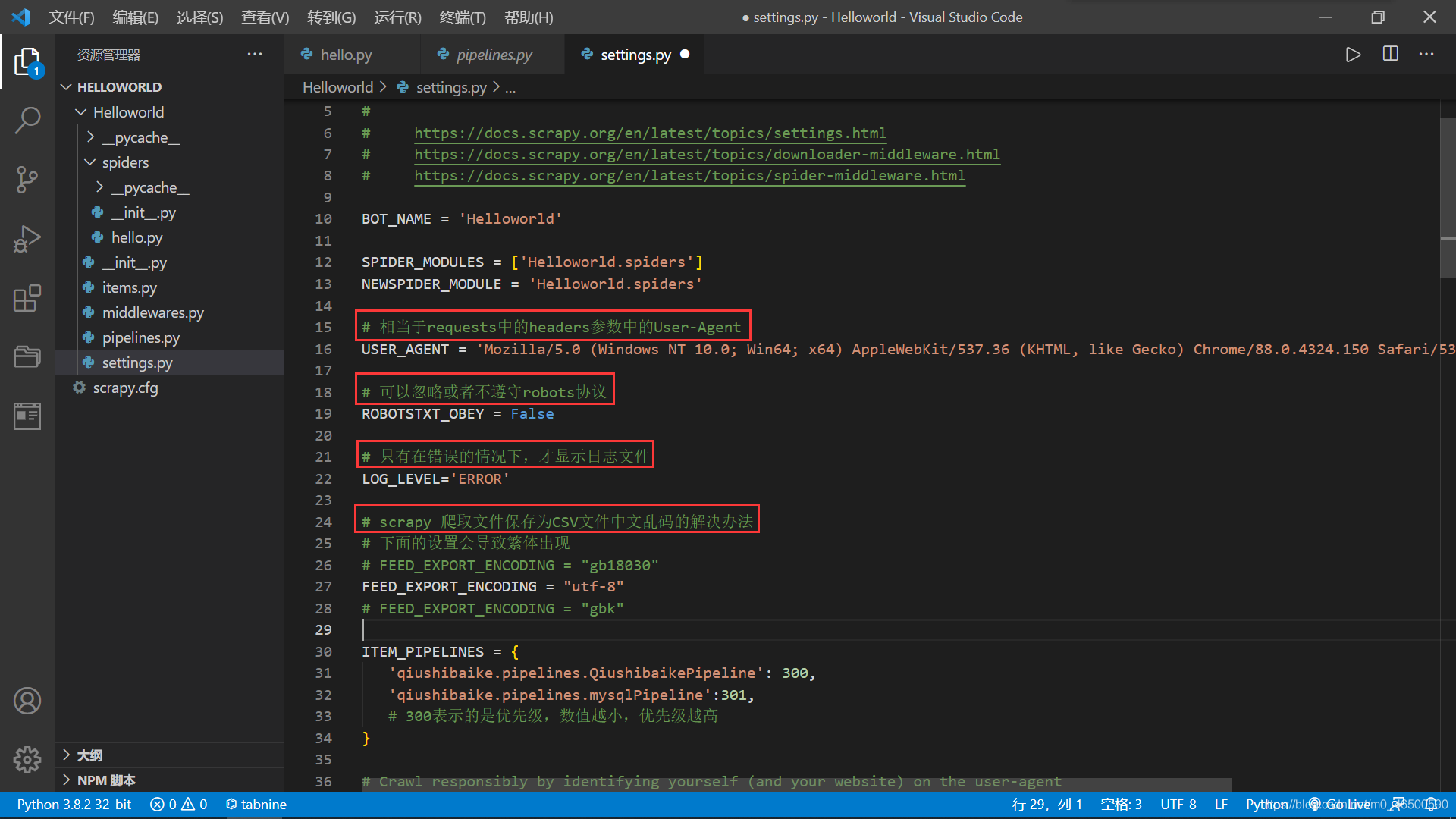
2.4 settings.py一些常见的设置
相当于requests中的headers参数中的User-Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.68'
可以忽略或者不遵守robots协议
ROBOTSTXT_OBEY = False
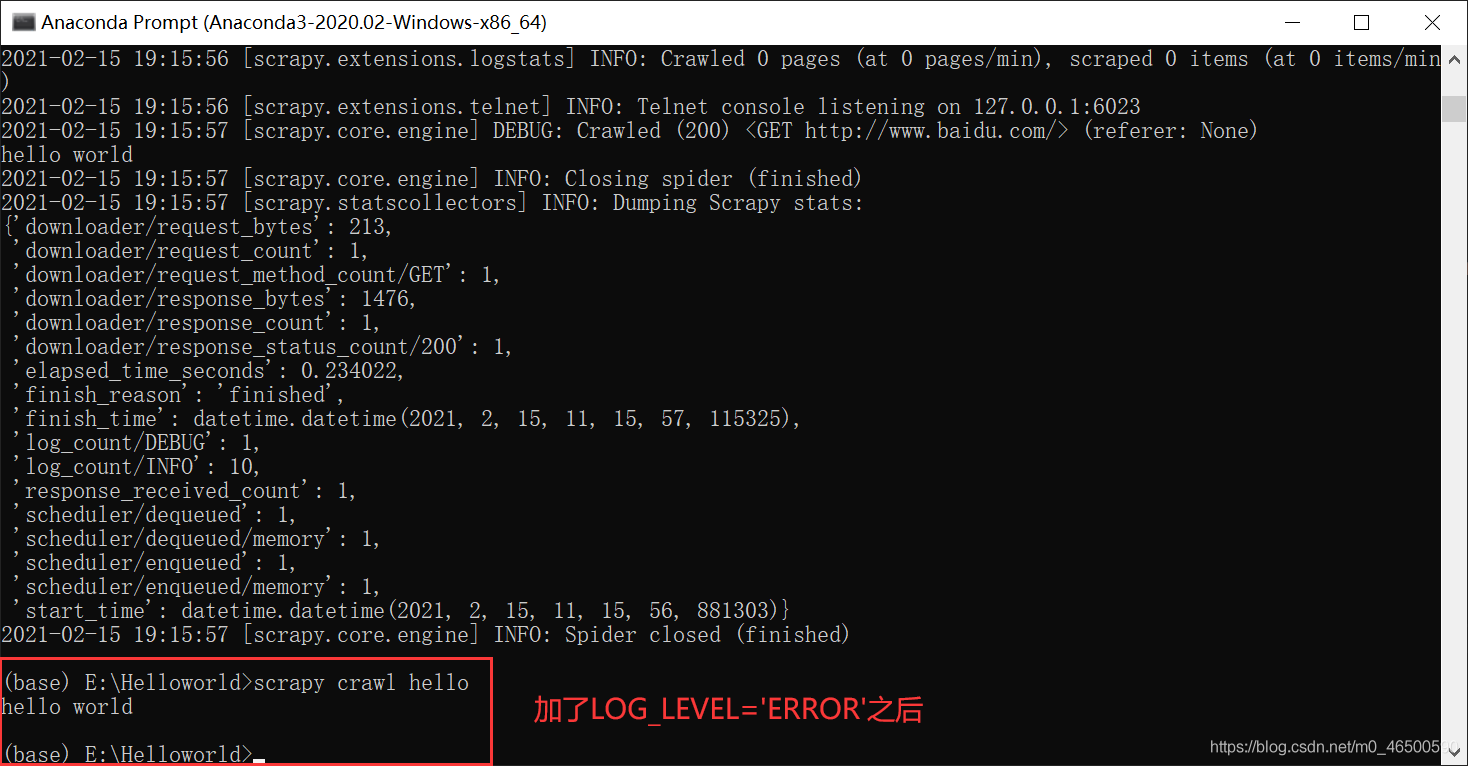
只有程序出现错误的情况下,才显示日志文件,程序正常执行时只会输出我们想要的结果
LOG_LEVEL='ERROR' == scrapy crawl spiderName --nolog //二者是等价的,当然还是推荐使用前者
未加LOG_LEVEL='ERROR'
加LOG_LEVEL='ERROR'之后
scrapy 爬取文件保存为CSV文件中文乱码的解决办法
//下面的设置可能会导致繁体出现,可以逐个试一下 FEED_EXPORT_ENCODING = "gb18030" FEED_EXPORT_ENCODING = "utf-8" FEED_EXPORT_ENCODING = "gbk"
三、实例
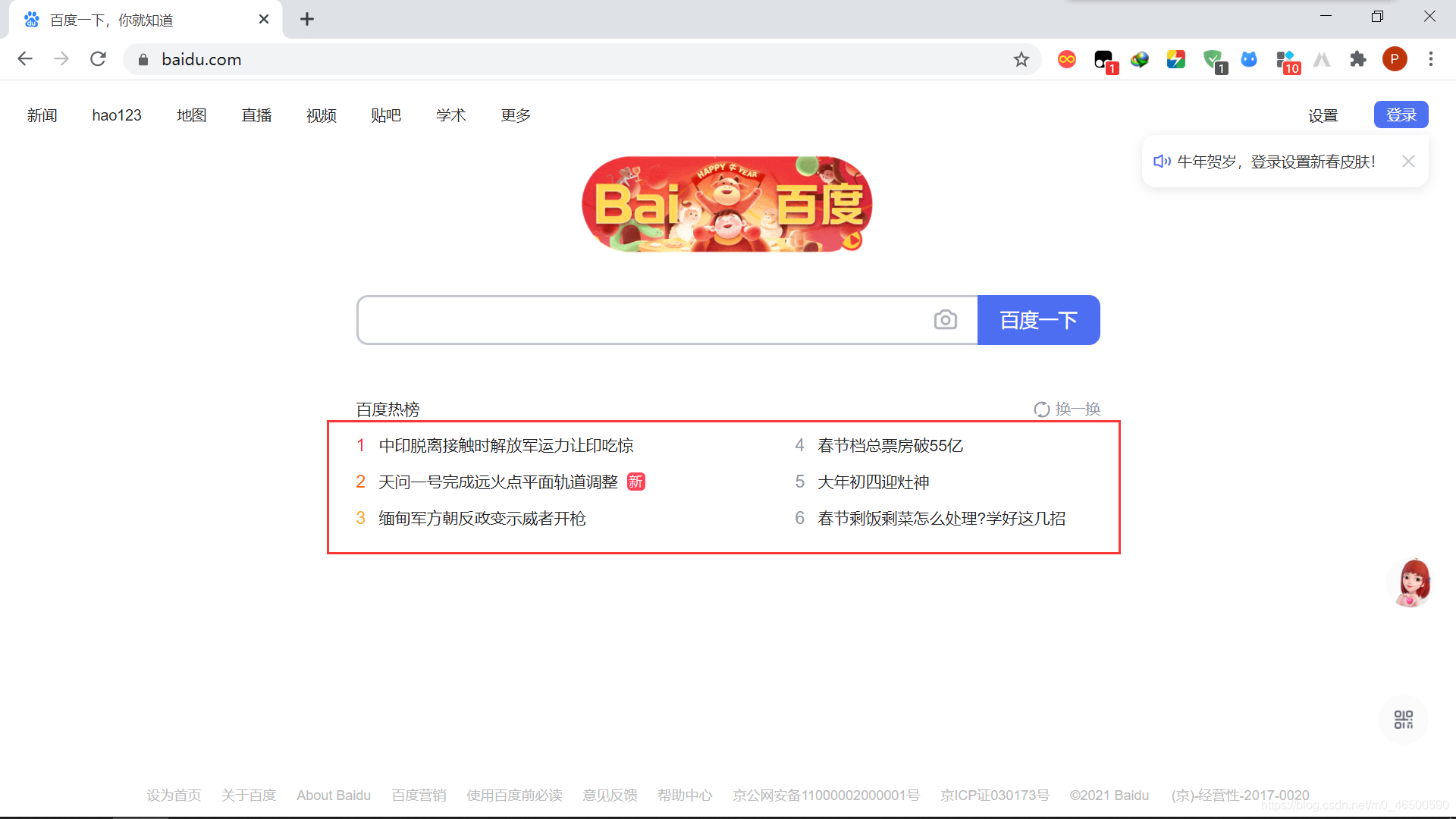
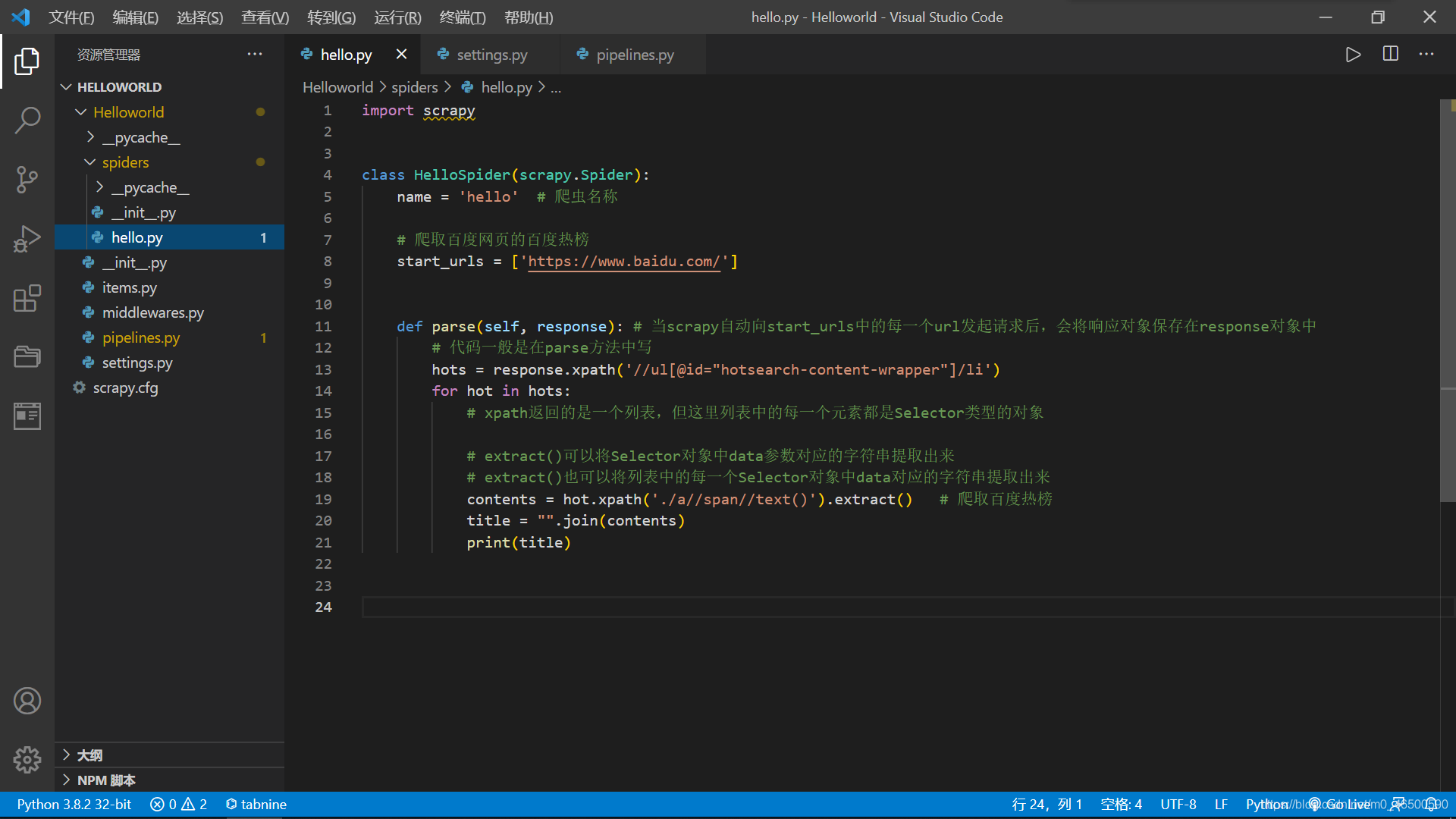
3.1 实例要求
目的:爬取百度网页的百度热榜
3.2 实例代码
实例代码
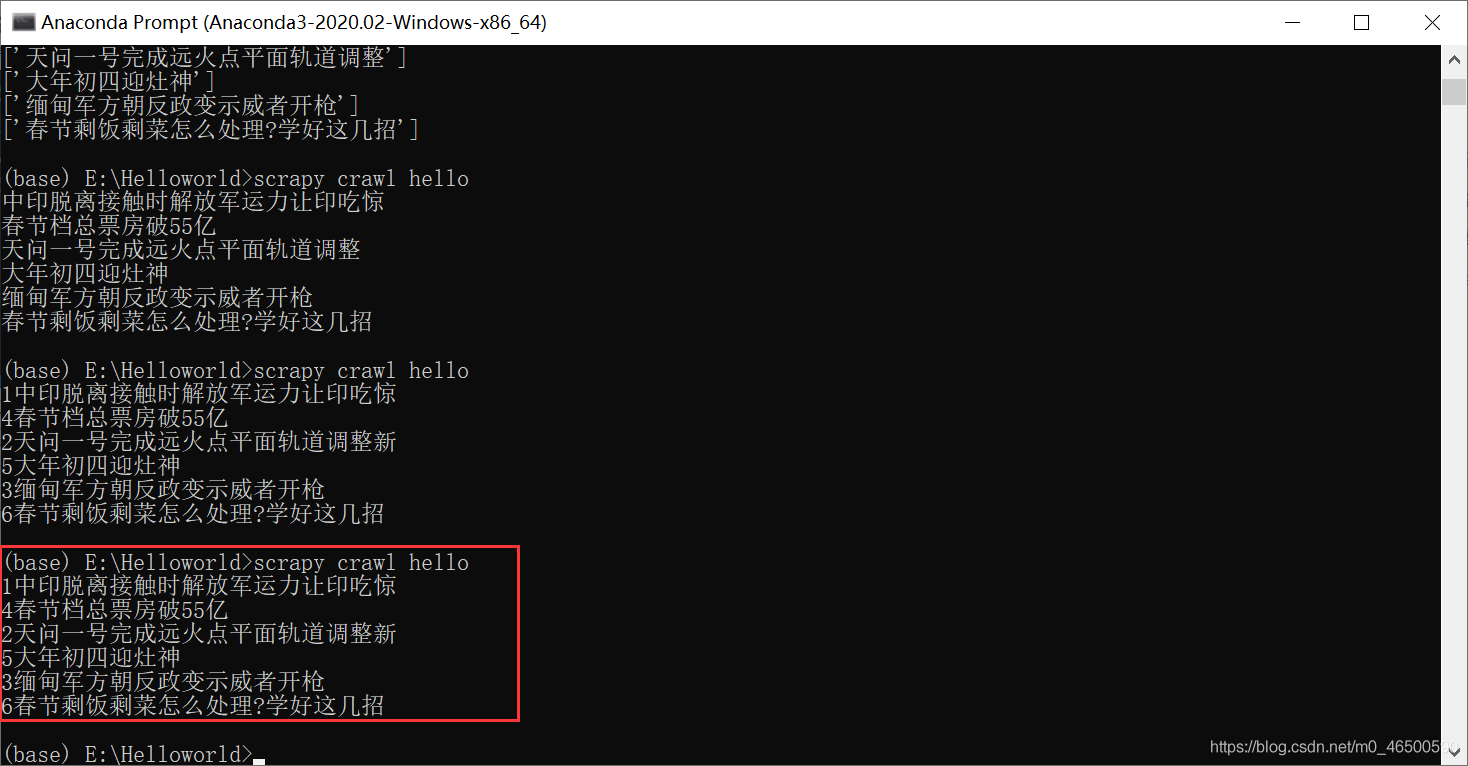
3.3 输出结果
结果
到此这篇关于python爬虫scrapy基本使用超详细教程的文章就介绍到这了,更多相关python爬虫scrapy使用内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!




