条件查询-模糊匹配
PostgreSQL和SQL Server的模糊匹配like是不一样的,PostgreSQL的like是区分大小写的,SQL Server不区分。
测试如下:
//构造数据SQL create table t_user ( id integer PRIMARY KEY, name varchar(50) not null, code varchar(10) ); insert into t_user values(1,'Zhangsan','77771'); insert into t_user values(2,'Lisi',null);
将如下SQL分别在PostgreSQL和SQL Server中执行:
select * from t_user where name like '%zhang%';
PostgreSQL结果:
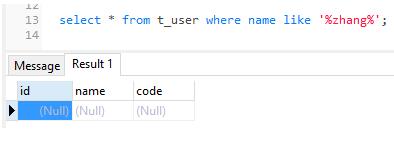
SQL Server结果:

如果想让PostgreSQL的like也不区分大小写的话,可以使用ilike
select * from t_user where name ilike '%zhang%';
或者使用lower或者upper都转换成小写或者大写再模糊匹配,这种方式的SQL两种数据库都兼容。
select * from t_user where upper(name) like upper('%zhang%');
select * from t_user where lower(name) like lower('%zhang%');
条件查询-弱类型匹配
PostgreSQL在做条件查询的时候是强类型校验的,但是SQL Server是弱类型。
将如下SQL分别在PostgreSQL和SQL Server中执行:
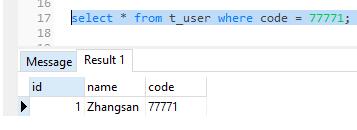
select * from t_user where code = 77771;
code是一个varchar类型的数据。
PostgreSQL结果:

SQL Server结果:
条件查询-末尾空白
SQL Server的查询如果末尾有空白的话,SQL Server会忽略但是PostgreSQL不会。
将如下SQL分别在PostgreSQL和SQL Server中执行:
select * from t_user where code = '77771 ';
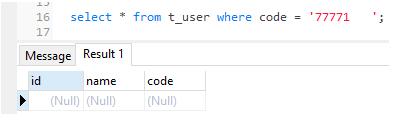
PostgreSQL结果:
SQL Server结果:
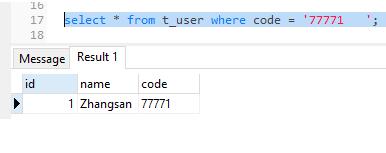
SQL Server是能查出数据的,但是PostgreSQL查不出来。
order by
1.PostgreSQL和SQL Server的默认order by行为是不一致的。
2.order by的字段如果是null,PostgreSQL会将其放在前面,SQL Server则将其放在后面。
将如下SQL分别在PostgreSQL和SQL Server中执行:
select * from t_user order by code desc;
PostgreSQL:

SQL Server:

可以看出,查出来的数据的顺序是不同的。
某些情况下如果要求数据顺序在两个数据库中要一致的话,可以在PostgreSQL的查询SQL中增加nulls last来让null数据滞后。
select * from t_user order by code desc nulls last;
也可以使用case when来统一SQL:
ORDER BY (case when xxx is null then '' else xxx end) DESC;
字符串拼接
SQL Server使用" + “号来拼接字符串,并且在2012版本之前不支持concat函数。
PostgreSQL使用” || "来拼接字符串,同时支持concat函数。
查询表是否存在
//SQL Server select count(name) from sys.tables where type='u' and name='t_user'; //PostgreSQL select count(table_name) from information_schema.tables where table_name='t_user';
补充:SqlServer与Postgresql数据库字段类型对照表
如下所示:
sqlserver to postgresql type // "bigint", "bigint" // "binary", "bytea" // "bit", "boolean" // "char", "char" // "datetime", "timestamp" // "decimal", "numeric" // "float", "double precision" // "image", "bytea" // "int", "integer" // "money", "numeric(19,4)" // "nchar", "varchar" // "ntext", "text" // "numeric", "numeric" // "nvarchar", "varchar" // "real", "real" // "smalldatetime", "timestamp" // "smallint", "smallint" // "smallmoney", "numeric(10,4)" // "text", "text" // "timestamp", "bigint" // "tinyint", "smallint" // "uniqueidentifier", "uniqueidentifier" // "varbinary", "bytea" // "varchar", "varchar"
以上为个人经验,希望能给大家一个参考,也希望大家多多支持好代码网。如有错误或未考虑完全的地方,望不吝赐教。