1、HOT概述
PostgreSQL中,由于其多版本的特性,当我们进行数据更新时,实际上并不是直接修改元数据,而是通过新插入一行数据来进行间接的更新。而当表上存在索引时,由于新插入了数据,那么索引必然也需要同步进行更新,这在索引较多的情况下,对于更新的性能影响必然很大。
为了解决这一问题,pg从8.3版本开始就引入了HOT(Heap Only Tuple)机制。其原理大致为,当更新的不是索引字段时,我们通过将旧元组指向新元组,而原先的索引不变,仍然指向旧元组,但是我们可以通过旧元组作为间接去访问到新的元组,这样就不用再去更新索引了。
2、HOT实现技术细节
要使用HOT进行更新,需要满足两个前提:
- 新的元组和旧元组必须在同一个page中;
- 索引字段不能进行更新。
当我们进行HOT更新时,首先是分别设置旧元组的t_informask2标志位为HEAP_HOT_UPDATED和新元组为HEAP_ONLY_TUPLE。
更新如下图所示:
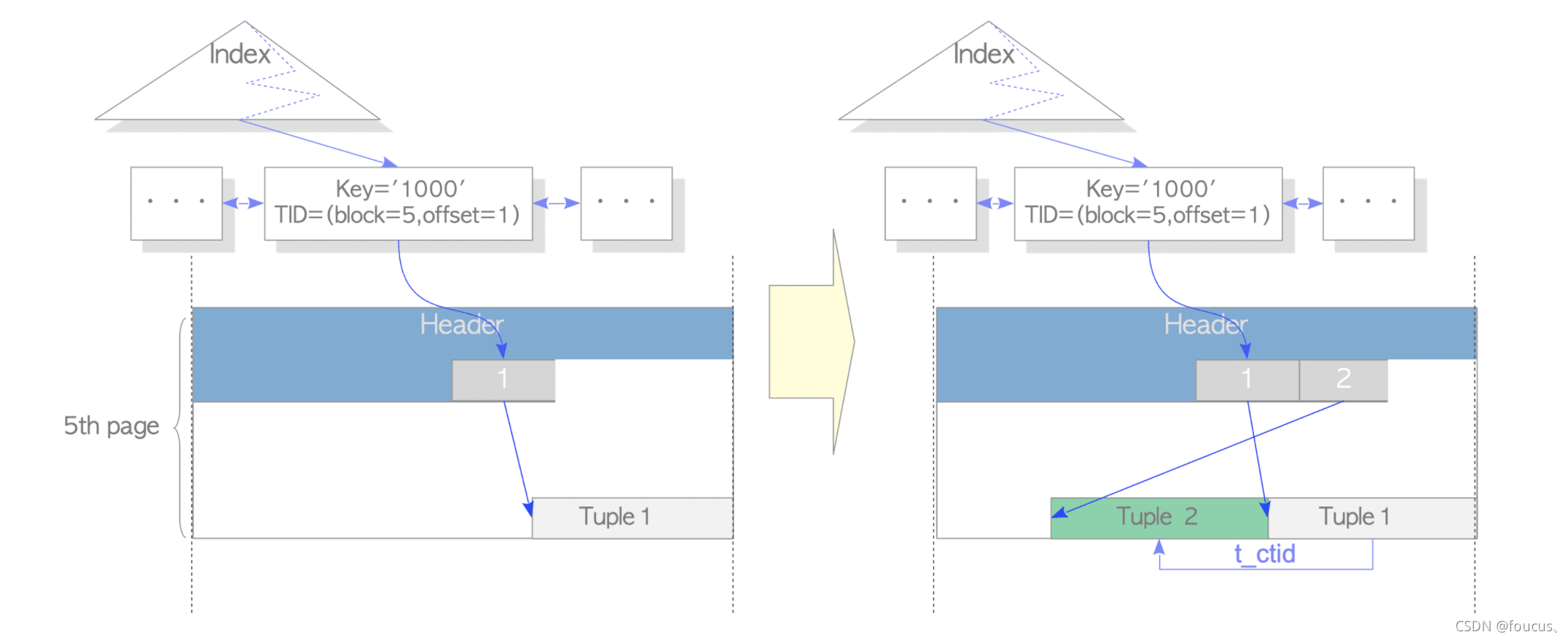
我们更新tuple1为tuple2,分别设置这两行元组的t_informask2标志位,然后tuple1的ctid指向tuple2,而tuple2指向自己。
但是这样存在一个明显的问题,我们都知道pg会定期进行vacuum清理那些死元组,那么我们这里如果通过tuple1去访问tuple2的话,tuple1这个死元组被清理了又该怎么办呢?
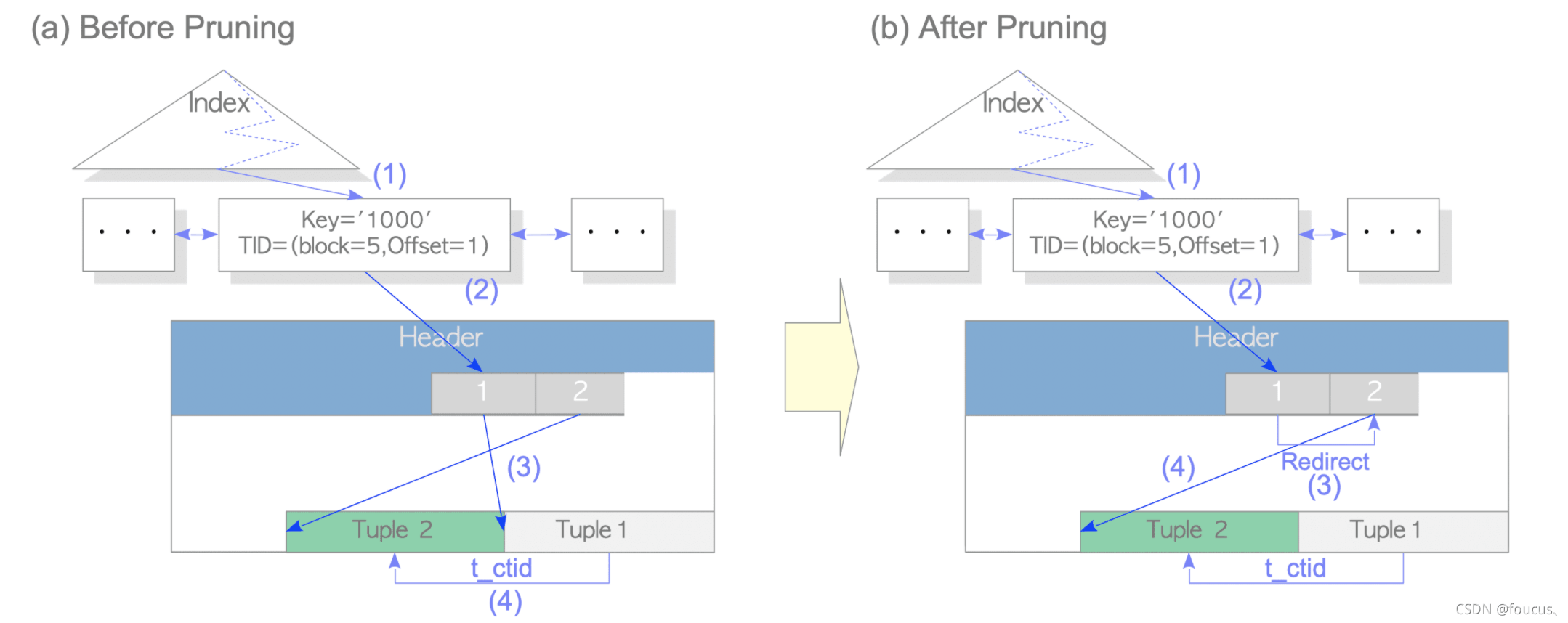
所以pg会在合适的时机进行行指针的重定向,将旧元组的行指针指向新元组的行指针,这一过程称为修剪。于是在修剪之后,我们通过HOT机制访问数据便成了这样:
1、通过索引元组找到旧元组的行指针1;
2、通过重定向的行指针1找到行指针2;
3、通过行指针2找到新元组tuple2。
这样即使旧元组tuple1被清理掉也没有影响了。
HOT对应的wal日志实现:
对于HOT的update操作,其wal日志中记录的信息主要是由xl_heap_update结构存储。
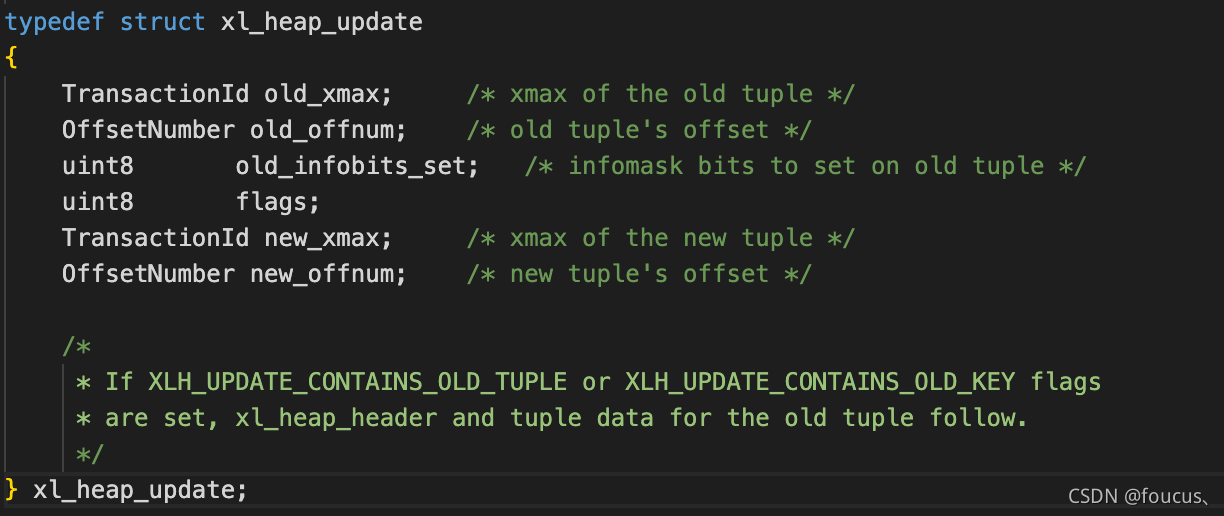
如果新的元组存储在 block_id 为 0 的块上,如果不是 XLOG_HEAP_HOT_UPDATE,那么旧的元组将会存储在 block_id 为 1 的块上。反之如果block_id 为 1 的块没有被使用,那么则认为是 XLOG_HEAP_HOT_UPDATE。
3、何时进行修剪
前面我们提到了,旧行的行指针会重定向到新行的行指针,这一过程称之为修剪。那么什么时候会发生修剪呢?
一般来说,当我们执行select、update、insert、delete这些命令时均有可能触发修剪,其触发机制大致有两种情况:
- 上一次进行update时无法在本page找到足够的空间;
- 当前page上剩余空间小于fill-factor的值,最多小于10%

除此之外,当进行修剪时,还会选择合适的时机进行死元组的清理,这一操作称为碎片整理。碎片整理发生在当我们对元组进行检索时发现空闲空间少于10%时,和修剪不同的是,碎片整理不会发生在insert时,因为该操作并不会检索行。
相较于普通的vacuum操作,碎片清理并不涉及索引元组的清理,开销相对于常规的清理要小很多,是通过PageRepairFragmentation函数来实现的。
这也是为什么HOT要求新旧元组需要在同一个page中,虽然从理论上来说我们可以将行指针的链表指向不同page,但是这样我们便不能使用page-local的操作来进行碎片清理了。
4、HOT的不足
前面我们提到了HOT的前提条件之一就是:更新的列不能是索引列。需要注意,当更新的列是索引列时并不仅仅是会修改该列上的索引,整张表上所有的索引均会被修改。
例子:
创建测试表:
bill=# create table a(id int, c1 int, c2 int, c3 int); CREATE TABLE bill=# insert into a select generate_series(1,10), random()*100, random()*100, random()*100; INSERT 0 10 bill=# create index idx_a_1 on a (id); CREATE INDEX bill=# create index idx_a_2 on a (c1); CREATE INDEX bill=# create index idx_a_3 on a (c2); CREATE INDEX
观察索引页内容:
bill=# SELECT * FROM bt_page_items('idx_a_1',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+--------+---------+-------+------+-------------------------+------+--------+------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00 | f | (0,2) |
3 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00 | f | (0,3) |
4 | (0,4) | 16 | f | f | 04 00 00 00 00 00 00 00 | f | (0,4) |
5 | (0,5) | 16 | f | f | 05 00 00 00 00 00 00 00 | f | (0,5) |
6 | (0,6) | 16 | f | f | 06 00 00 00 00 00 00 00 | f | (0,6) |
7 | (0,7) | 16 | f | f | 07 00 00 00 00 00 00 00 | f | (0,7) |
8 | (0,8) | 16 | f | f | 08 00 00 00 00 00 00 00 | f | (0,8) |
9 | (0,9) | 16 | f | f | 09 00 00 00 00 00 00 00 | f | (0,9) |
10 | (0,10) | 16 | f | f | 0a 00 00 00 00 00 00 00 | f | (0,10) |
(10 rows)
bill=# SELECT * FROM bt_page_items('idx_a_2',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+-----------+---------+-------+------+-------------------------+------+--------+-------------------
1 | (0,5) | 16 | f | f | 00 00 00 00 00 00 00 00 | f | (0,5) |
2 | (0,4) | 16 | f | f | 05 00 00 00 00 00 00 00 | f | (0,4) |
3 | (0,8) | 16 | f | f | 0e 00 00 00 00 00 00 00 | f | (0,8) |
4 | (0,9) | 16 | f | f | 25 00 00 00 00 00 00 00 | f | (0,9) |
5 | (16,8194) | 32 | f | f | 30 00 00 00 00 00 00 00 | f | (0,1) | {"(0,1)","(0,3)"}
6 | (0,10) | 16 | f | f | 58 00 00 00 00 00 00 00 | f | (0,10) |
7 | (0,6) | 16 | f | f | 60 00 00 00 00 00 00 00 | f | (0,6) |
8 | (0,7) | 16 | f | f | 62 00 00 00 00 00 00 00 | f | (0,7) |
9 | (0,2) | 16 | f | f | 63 00 00 00 00 00 00 00 | f | (0,2) |
(9 rows)
bill=# SELECT * FROM bt_page_items('idx_a_3',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+--------+---------+-------+------+-------------------------+------+--------+------
1 | (0,6) | 16 | f | f | 03 00 00 00 00 00 00 00 | f | (0,6) |
2 | (0,3) | 16 | f | f | 12 00 00 00 00 00 00 00 | f | (0,3) |
3 | (0,5) | 16 | f | f | 15 00 00 00 00 00 00 00 | f | (0,5) |
4 | (0,9) | 16 | f | f | 1a 00 00 00 00 00 00 00 | f | (0,9) |
5 | (0,4) | 16 | f | f | 33 00 00 00 00 00 00 00 | f | (0,4) |
6 | (0,7) | 16 | f | f | 3d 00 00 00 00 00 00 00 | f | (0,7) |
7 | (0,10) | 16 | f | f | 4e 00 00 00 00 00 00 00 | f | (0,10) |
8 | (0,1) | 16 | f | f | 4f 00 00 00 00 00 00 00 | f | (0,1) |
9 | (0,2) | 16 | f | f | 5c 00 00 00 00 00 00 00 | f | (0,2) |
10 | (0,8) | 16 | f | f | 5d 00 00 00 00 00 00 00 | f | (0,8) |
(10 rows)更新索引列c2:
bill=# update a set c2=c2+1 where id=1 returning ctid,*; ctid | id | c1 | c2 | c3 --------+----+----+----+---- (0,11) | 1 | 19 | 66 | 86 (1 row) UPDATE 1
再观察索引内容:
可以看到3个索引的索引页均发生了变化。
bill=# SELECT * FROM bt_page_items('idx_a_1',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+--------+---------+-------+------+-------------------------+------+--------+------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (0,11) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,11) |
3 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00 | f | (0,2) |
4 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00 | f | (0,3) |
5 | (0,4) | 16 | f | f | 04 00 00 00 00 00 00 00 | f | (0,4) |
6 | (0,5) | 16 | f | f | 05 00 00 00 00 00 00 00 | f | (0,5) |
7 | (0,6) | 16 | f | f | 06 00 00 00 00 00 00 00 | f | (0,6) |
8 | (0,7) | 16 | f | f | 07 00 00 00 00 00 00 00 | f | (0,7) |
9 | (0,8) | 16 | f | f | 08 00 00 00 00 00 00 00 | f | (0,8) |
10 | (0,9) | 16 | f | f | 09 00 00 00 00 00 00 00 | f | (0,9) |
11 | (0,10) | 16 | f | f | 0a 00 00 00 00 00 00 00 | f | (0,10) |
(11 rows)
bill=# SELECT * FROM bt_page_items('idx_a_2',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+--------+---------+-------+------+-------------------------+------+--------+------
1 | (0,6) | 16 | f | f | 04 00 00 00 00 00 00 00 | f | (0,6) |
2 | (0,9) | 16 | f | f | 0b 00 00 00 00 00 00 00 | f | (0,9) |
3 | (0,1) | 16 | f | f | 13 00 00 00 00 00 00 00 | f | (0,1) |
4 | (0,11) | 16 | f | f | 13 00 00 00 00 00 00 00 | f | (0,11) |
5 | (0,2) | 16 | f | f | 19 00 00 00 00 00 00 00 | f | (0,2) |
6 | (0,5) | 16 | f | f | 1d 00 00 00 00 00 00 00 | f | (0,5) |
7 | (0,8) | 16 | f | f | 1e 00 00 00 00 00 00 00 | f | (0,8) |
8 | (0,4) | 16 | f | f | 21 00 00 00 00 00 00 00 | f | (0,4) |
9 | (0,3) | 16 | f | f | 28 00 00 00 00 00 00 00 | f | (0,3) |
10 | (0,10) | 16 | f | f | 3a 00 00 00 00 00 00 00 | f | (0,10) |
11 | (0,7) | 16 | f | f | 4d 00 00 00 00 00 00 00 | f | (0,7) |
(11 rows)
bill=# SELECT * FROM bt_page_items('idx_a_3',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+--------+---------+-------+------+-------------------------+------+--------+------
1 | (0,2) | 16 | f | f | 17 00 00 00 00 00 00 00 | f | (0,2) |
2 | (0,7) | 16 | f | f | 18 00 00 00 00 00 00 00 | f | (0,7) |
3 | (0,5) | 16 | f | f | 33 00 00 00 00 00 00 00 | f | (0,5) |
4 | (0,6) | 16 | f | f | 37 00 00 00 00 00 00 00 | f | (0,6) |
5 | (0,4) | 16 | f | f | 38 00 00 00 00 00 00 00 | f | (0,4) |
6 | (0,1) | 16 | f | f | 41 00 00 00 00 00 00 00 | f | (0,1) |
7 | (0,11) | 16 | f | f | 42 00 00 00 00 00 00 00 | f | (0,11) |
8 | (0,9) | 16 | f | f | 4d 00 00 00 00 00 00 00 | f | (0,9) |
9 | (0,8) | 16 | f | f | 58 00 00 00 00 00 00 00 | f | (0,8) |
10 | (0,3) | 16 | f | f | 62 00 00 00 00 00 00 00 | f | (0,3) |
11 | (0,10) | 16 | f | f | 63 00 00 00 00 00 00 00 | f | (0,10) |
(11 rows)这也意味着当我们无法使用HOT更新时,每更新一条数据都会更新所有的索引,那么这个对性能的影响可想而知。而我们简单想想其实并没有这个必要,因为对于没有被更新的索引列而言,只是ctid发生了变化,其索引列指向的值并没有变化。那么有没有办法让我们更新索引列时只修改该索引列的索引呢?PHOT应运而生。
5、PHOT概述
PHOT(Partial Heap Only Tuples),正如我们前面所说,PHOT是为了解决HOT更新索引列时会修改索引列的弊端。目前,PG中还不支持该功能,不过社区中已经有相关的讨论了,预计可能会在PG15中和大家见面。
PHOT的设计思路主要是:通过在t_infomask2标志位新加入两种类型HEAP_HOT_UPDATED 和HEAP_ONLY_TUPLE用来表示PHOT更新,类似于HOT。当我们对索引列进行修改时,通过一个PHOT的bitmap位图来记录哪些索引列被更新了,然后,当我们对索引列修改时,只需要修改这个bitmap位图中的列即可。
#define HEAP_HOT_UPDATED 0x4000 /* tuple was HOT-updated */ #define HEAP_ONLY_TUPLE 0x8000 /* this is heap-only tuple */
6、PHOT实例
我们通过下面的例子来看看PHOT和HOT的不同之处。
构建环境:
CREATE TABLE test (a INT, b INT, c INT); CREATE INDEX ON test (a); CREATE INDEX ON test (b); CREATE INDEX ON test (c); INSERT INTO test VALUES (0, 0, 0); UPDATE test SET a = 1, b = 1; UPDATE test SET b = 2, c = 2; UPDATE test SET a = 2; UPDATE test SET a = 3, c = 3;
不使用PHOT:
可以看到,不使用PHOT的情况下,每次更新都会产生新的索引元组。
在这些更新之后,有 15 个索引元组、5 个行指针和 5 个堆元组。
test_a_idx 0 1 1 2 3 test_b_idx 0 1 2 2 2 test_c_idx 0 0 2 2 3 lp 1 2 3 4 5 heap (0,0,0) (1,1,0) (1,2,2) (2,2,2) (3,2,3)
PHOT:
在使用PHOT后,通过增加了一个bitmap位图来记录被更新的列。当执行完上述更新后,有 10 个索引元组、5 个行指针、5 个堆元组和 4 个位图。
test_a_idx 0 1 2 3 test_b_idx 0 1 2 test_c_idx 0 2 3 lp 1 2 3 4 5 heap (0,0,0) (1,1,0) (1,2,2) (2,2,2) (3,2,3) bitmap xx- -xx x-- x-x
而前面的例子我们使用PHOT更新又是什么结果呢?
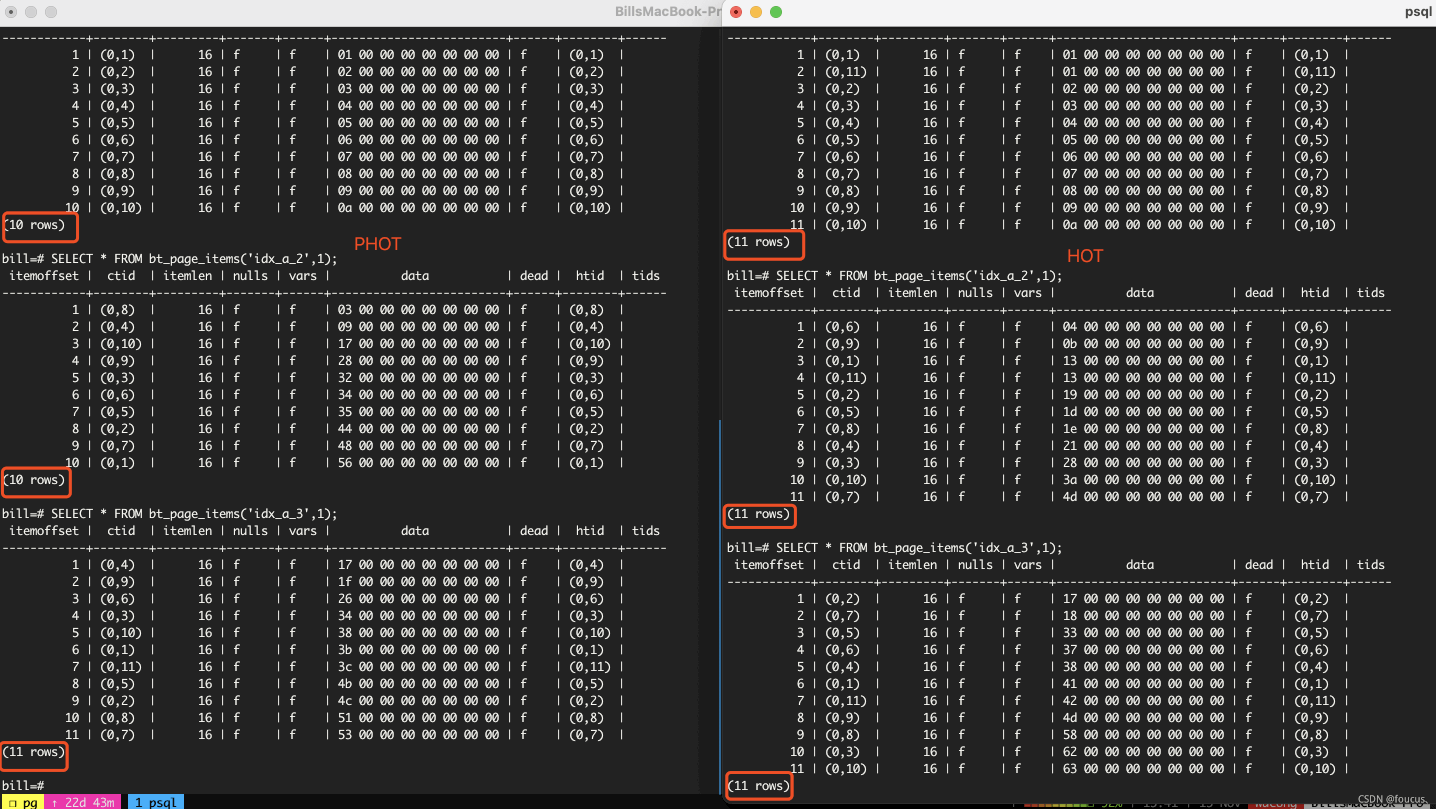
可以看到下图中,左边是使用PHOT进行更新的,只是被更新的索引列发生了变化,而右边非PHOT进行更新则是所有的索引列均发生变化。
性能测试:
通过简单的pgbench测试,TPS 提高了约 34%,其中每个表都有 5 个额外的文本列和每列上的索引。有了额外的索引和列,理论上 TPS 的提升应该会更高。对于没有表修改的短期 pgbench 运行,使用 PHOT 观察到 TPS 增加了约 2%,表明常规 pgbench 运行没有受到显着影响。
总结
PostgreSQL使用HOT机制来避免因为其多版本特性导致的每次更新数据均需要修改索引的情况。而当前的HOT机制,对于索引列的更新仍然存在比较明显的性能问题,因为所有的索引均需要发生修改,不过预计在PG15中,将会加入更为强大的PHOT功能,更新索引列再也不会影响其它索引了。
参考链接:
到此这篇关于PostgreSQL HOT与PHOT有哪些区别的文章就介绍到这了,更多相关PostgreSQL HOT与PHOT内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!