七、pg_dump:
pg_dump是一个用于备份PostgreSQL数据库的工具。它甚至可以在数据库正在并发使用时进行完整一致的备份,而不会阻塞其它用户对数据库的访问。该工具生成的转储格式可以分为两种,脚本和归档文件。其中脚本格式是包含许多SQL命令的纯文本格式,这些SQL命令可以用于重建该数据库并将之恢复到生成此脚本时的状态,该操作需要使用psql来完成。至于归档格式,如果需要重建数据库就必须和pg_restore工具一起使用。在重建过程中,可以对恢复的对象进行选择,甚至可以在恢复之前对需要恢复的条目进行重新排序。该命令的使用方式如下:
pg_dump [option...] [dbname]
1. 命令行选项列表:
| 选项 | 说明 |
| -a(--data-only) | 只输出数据,不输出模式(数据对象的定义)。这个选项只是对纯文本格式有意义。对于归档格式,你可以在调用pg_restore时指定选项。 |
| -b(--blobs) | 在dump中包含大对象。 |
| -c(--clean) | 在输出创建数据库对象的SQL命令之前,先输出删除该数据库对象的SQL命令。这个选项只是对纯文本格式有意义。对于归档格式,你可以在调用 pg_restore时指定选项。 |
| -C(--create) | 先输出创建数据库的命令,之后再重新连接新创建的数据库。对于此种格式的脚本,在运行之前是和哪个数据库进行连接就不这么重要了。这个选项只是对纯文本格式有意义。对于归档格式,你可以在调用pg_restore时指定选项。 |
| -Eencoding | 以指定的字符集创建该dump文件。 |
| -ffile | 输出到指定文件,如果没有该选项,则输出到标准输出。 |
| -Fformat |
p(plain): 纯文本格式的SQL脚本文件(缺省)。c(custom): 输出适合于pg_restore的自定义归档格式。 这是最灵活的格式,它允许对装载的数据和对象定义进行重新排列。这个格式缺省的时候是压缩的。t(tar): 输出适合于pg_restore的tar归档文件。使用这个归档允许在恢复数据库时重新排序和/或把数据库对象排除在外。同i时也可能可以在恢复的时候限制对哪些数据进行恢复。 |
| -n schema | 只转储schema的内容。如果没有声明该选项,目标数据库中的所有非系统模式都会被转储。该选项也可以被多次指定,以指定不同pattern的模式。 |
| -Nschema | 不转储匹配schema的内容,其他规则和-n一致。 |
| -o(--oids) | 作为数据的一部分,为每个表都输出对象标识(OID)。 |
| -O(--no-owner) | 不输出设置对象所有权的SQL命令。 |
| -s(--schema-only) | 只输出对象定义(模式),不输出数据。 |
| -Susername | 指定关闭触发器时需要用到的超级用户名。它只有在使用--disable-triggers的时候才有关系。 |
| -ttable | 只输出表的数据。很可能在不同模式里面有多个同名表,如果这样,那么所有匹配的表都将被转储。通过多次指定该参数,可以一次转储多张表。这里还可以指定和psql一样的pattern,以便匹配更多的表。(关于pattern,基本的使用方式是可以将它视为unix的通配符,即*表示任意字符,?表示任意单个字符,.(dot)表示schema和object之间的分隔符,如a*.b*,表示以a开头的schema和以b开头的数据库对象。如果没有.(dot),将只是表示数据库对象。这里也可以使用基本的正则表达式,如[0-9]表示数字。) |
| -Ttable | 排除指定的表,其他规则和-t选项一致。 |
| -x(--no-privileges) | 不导出访问权限信息(grant/revoke命令)。 |
| -Z0..9 | 声明在那些支持压缩的格式中使用的压缩级别。 (目前只有自定义格式支持压缩) |
| --column-inserts | 导出数据用insert into table_name(columns_list) values(values_list)命令表示,这样的操作相对其它操作而言是比较慢的,但是在特殊情况下,如数据表字段的位置有可能发生变化或有新的字段插入到原有字段列表的中间等。由于columns_list被明确指定,因此在导入时不会出现数据被导入到错误字段的问题。 |
| --inserts | 导出的数据用insert命令表示,而不是copy命令。即便使用insert要比copy慢一些,但是对于今后导入到其他非PostgreSQL的数据库是比较有意义的。 |
| --no-tablespaces | 不输出设置表空间的命令,如果带有这个选项,所有的对象都将恢复到执行pg_restore时的缺省表空间中。 |
| --no-unlogged-table-data | 对于不计入日志(unlogged)的数据表,不会导出它的数据,至于是否导出其Schema信息,需要依赖其他的选项而定。 |
| -h(--host=host) | 指定PostgreSQL服务器的主机名。 |
| -p(--port=port) | 指定服务器的侦听端口,如不指定,则为缺省的5432。 |
| -U(--username=username) | 本次操作的登录用户名,如果-O选项没有指定,此数据库的Owner将为该登录用户。 |
| -w(--no-password) | 如果当前登录用户没有密码,可以指定该选项直接登录。 |
2. 应用示例:
# -h: PostgreSQL服务器的主机为192.168.149.137。
# -U: 登录用户为postgres。
# -t: 导出表名以test开头的数据表,如testtable。
# -a: 仅仅导出数据,不导出对象的schema信息。
# -f: 输出文件是当前目录下的my_dump.sql
# mydatabase是此次操作的目标数据库。
/> pg_dump -h 192.168.149.137 -U postgres -t test* -a -f ./my_dump.sql mydatabase
#-c: 先输出删除数据库对象的SQL命令,在输出创建数据库对象的SQL命令,这对于部署干净的初始系统或是搭建测试环境都非常方便。
/> pg_dump -h 192.168.220.136 -U postgres -c -f ./my_dump.sql mydatabase
#导出mydatabase数据库的信息。在通过psql命令导入时可以重新指定数据库,如:/> psql -d newdb -f my_dump.sql
/> pg_dump -h 192.168.220.136 -U postgres -f ./my_dump.sql mydatabase
#导出模式为my_schema和以test开头的数据库对象名,但是不包括my_schema.employee_log对象。
/> pg_dump -t 'my_schema.test*' -T my_schema.employee_log mydatabase > my_dump.sql
#导出east和west模式下的所有数据库对象。下面两个命令是等同的,只是后者使用了正则。
/> pg_dump -n 'east' -n 'west' mydatabase -f my_dump.sql
/> pg_dump -n '(east|west)' mydatabase -f my_dump.sql
八、pg_restore:
pg_restore用于恢复pg_dump导出的任何非纯文本格式的文件,它将数据库重建成保存它时的状态。对于归档格式的文件,pg_restore可以进行有选择的恢复,甚至也可以在恢复前重新排列数据的顺序。
pg_restore可以在两种模式下操作。如果指定数据库,归档将直接恢复到该数据库。否则,必须先手工创建数据库,之后再通过pg_restore恢复数据到该新建的数据库中。该命令的使用方式如下:
pg_restore [option...] [filename]
1. 命令行选项列表:
| 选项 | 说明 |
| filename | 指定要恢复的备份文件,如果没有声明,则使用标准输入。 |
| -a(--data-only) | 只恢复数据,而不恢复表模式(数据对象定义)。 |
| -c(--clean) | 创建数据库对象前先清理(删除)它们。 |
| -C(--create) | 在恢复数据库之前先创建它。(在使用该选项时,数据库名需要由-d选项指定,该选项只是执行最基本的CREATE DATABASE命令。需要说明的是,归档文件中所有的数据都将恢复到归档文件里指定的数据库中)。 |
| -ddbname | 与数据库dbname建立连接并且直接恢复数据到该数据库中。 |
| -e(--exit-on-error) |
如果在向数据库发送SQL命令的时候遇到错误,则退出。缺省是继续执行并且在恢复结束时显示一个错误计数。 |
| -Fformat | 指定备份文件的格式。由于pg_restore会自动判断格式,因此指定格式并不是必须的。如果指定,它可以是以下格式之一:t(tar): 使用该格式允许在恢复数据库时重新排序和/或把表模式信息排除出去,同时还可能在恢复时限制装载的数据。 c(custom):该格式是来自pg_dump的自定义格式。这是最灵活的格式,因为它允许重新对数据排序,也允许重载表模式信息,缺省情况下这个格式是压缩的。 |
| -I index | 只恢复指定的索引。 |
| -l(--list) | 列出备份中的内容,这个操作的输出可以作为-L选项的输入。注意,如果过滤选项-n或-t连同-l选项一起使用的话,他们也将限制列出的条目。 |
| -L list-file | 仅恢复在list-file中列出的条目,恢复的顺序为各个条目在该文件中出现的顺序,你也可以手工编辑该文件,并重新排列这些条目的位置,之后再进行恢复操作,其中以分号(;)开头的行为注释行,注释行不会被导入。 |
| -n namespace | 仅恢复指定模式(Schema)的数据库对象。该选项可以和-t选项联合使用,以恢复指定的数据对象。 |
| -O(--no-owner) | 不输出设置对象所有权的SQL命令。 |
| -Pfunction-name(argtype [, ...]) |
只恢复指定的命名函数。该名称应该和转储的内容列表中的完全一致。 |
| -s(--schema-only) | 只恢复表结构(数据定义)。不恢复数据,序列值将重置。 |
| -Susername | 指定关闭触发器时需要用到的超级用户名。它只有在使用--disable-triggers的时候才有关系。 |
| -t table | 只恢复指定表的Schema和/或数据,该选项也可以连同-n选项指定模式。 |
| -x(--no-privileges) | 不恢复访问权限信息(grant/revoke命令)。 |
| -1(--single-transaction) | 在一个单一事物中执行恢复命令。这个选项隐含包括了--exit-on-error选项。 |
| --no-tablespaces | 不输出设置表空间的命令,如果带有这个选项,所有的对象都将恢复到执行pg_restore时的缺省表空间中。 |
| --no-data-for-failed-tables | 缺省情况下,即使创建表失败了,如该表已经存在,数据加载的操作也不会停止,这样的结果就是很容易导致大量的重复数据被插入到该表中。如果带有该选项,那么一旦出现针对该表的任何错误,对该数据表的加载将被忽略。 |
| --role=rolename | 以指定的角色名执行restore的操作。通常而言,如果连接角色没有足够的权限用于本次恢复操作,那么就可以利用该选项在建立连接之后再切换到有足够权限的角色。 |
| -h(--host=host) | 指定PostgreSQL服务器的主机名。 |
| -p(--port=port) | 指定服务器的侦听端口,如不指定,则为缺省的5432。 |
| -U(--username=username) | 本次操作的登录用户名,如果-O选项没有指定,此数据库的Owner将为该登录用户。 |
| -w(--no-password) | 如果当前登录用户没有密码,可以指定该选项直接登录。 |
2. 应用示例:
#先通过createdb命令,以myuser用户的身份登录,创建带恢复的数据newdb
/> createdb -U myuser newdb
#用pg_restore命令的-l选项导出my_dump.dat备份文件中导出数据库对象的明细列表。
/> pg_restore -l my_dump.dat > db.list
/> cat db.list
2; 145344 TABLE species postgres
4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
8; 145416 TABLE ss_old postgres
10; 145433 TABLE map_resolutions postgres
#将以上列表文件中的内容修改为以下形式。
#主要的修改是注释掉编号为2、4和8的三个数据库对象,同时编号10的对象放到该文件的头部,这样在基于该列表
#文件导入时,2、4和8等三个对象将不会被导入,在恢复的过程中将先导入编号为10的对象的数据,再导入对象6的数据。
/> cat new_db.list
10; 145433 TABLE map_resolutions postgres
;2; 145344 TABLE species postgres
;4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
;8; 145416 TABLE ss_old postgres
#恢复时指定的数据库是newdb,导入哪些数据库对象和导入顺序将会按照new_db.list文件中提示的规则导入。
/> pg_restore -d newdb -L new_db.list my_dump.dat
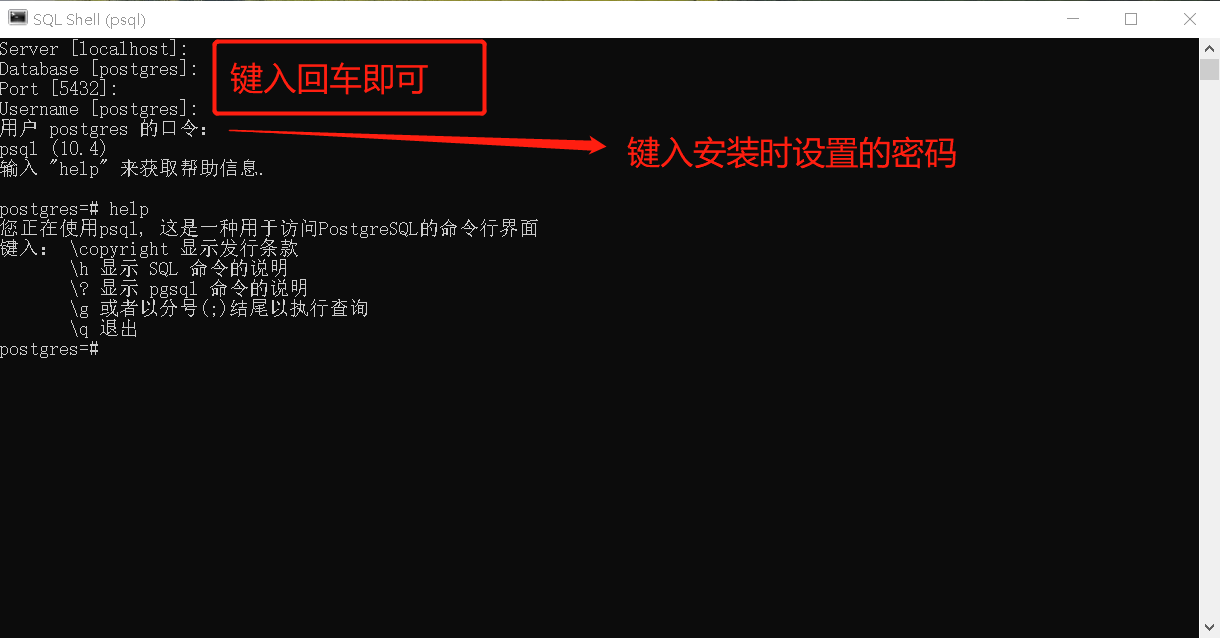
九、psql:
PostgreSQL的交互终端,等同于Oracle中的sqlplus。
1. 常用命令行选项列表:
| 选项 | 说明 |
| -c command | 指定psql执行一条SQL命令command(用双引号括起),执行后退出。 |
| -d dbname | 待连接的数据库名称。 |
| -E | 回显由\d和其他反斜杠命令生成的实际查询。 |
| -f filename | 使用filename文件中的数据作为命令输入源,而不是交互式读入查询。在处理完文件后,psql结束并退出。 |
| -h hostname | 声明正在运行服务器的主机名 |
| -l | 列出所有可用的数据库,然后退出。 |
| -L filename | 除了正常的输出源之外,把所有查询记录输出到文件filename。 |
| -o filename | 将所有查询重定向输出到文件filename。 |
| -p port | 指定PostgreSQL服务器的监听端口。 |
| -q --quiet | 让psql安静地执行所处理的任务。缺省时psql将输出打印欢迎和许多其他信息。 |
| -t --tuples-only | 关闭打印列名称和结果行计数脚注等信息。 |
| -U username | 以用户username代替缺省用户与数据库建立连接。 |
2. 应用示例:
#先通过createdb命令,以myuser用户的身份登录,创建带恢复的数据newdb
/> createdb -U myuser newdb
#用pg_restore命令的-l选项导出my_dump.dat备份文件中导出数据库对象的明细列表。
/> pg_restore -l my_dump.dat > db.list
/> cat db.list
2; 145344 TABLE species postgres
4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
8; 145416 TABLE ss_old postgres
10; 145433 TABLE map_resolutions postgres
#将以上列表文件中的内容修改为以下形式。
#主要的修改是注释掉编号为2、4和8的三个数据库对象,同时编号10的对象放到该文件的头部,这样在基于该列表
#文件导入时,2、4和8等三个对象将不会被导入,在恢复的过程中将先导入编号为10的对象的数据,再导入对象6的数据。
/> cat new_db.list
10; 145433 TABLE map_resolutions postgres
;2; 145344 TABLE species postgres
;4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
;8; 145416 TABLE ss_old postgres
#恢复时指定的数据库是newdb,导入哪些数据库对象和导入顺序将会按照new_db.list文件中提示的规则导入。
/> pg_restore -d newdb -L new_db.list my_dump.dat
3. 内置命令列表:
psql内置命令的格式为反斜杠后面紧跟一个命令动词,之后是任意参数。参数与命令动词以及其他参数之间可以用空白符隔开,如果参数里面包含空白符,该参数必须用单引号括起,如果参数内包含单引号,则需要用反斜杠进行转义,此外单引号内的参数还支持类似C语言printf函数所支持的转义关键字,如\t、\n等。
| 命令 | 说明 |
| \a | 如果目前的表输出格式是不对齐的,切换成对齐的。如果是对齐的,则切换成不对齐。 |
| \cd [directory] | 把当前工作目录切换到directory。没有参数则切换到当前用户的主目录。 |
| \C [title] | 为查询结果添加表头(title),如果没有参数则取消当前的表头。 |
| \c[dbname[username] ] | 连接新的数据库,同时断开当前连接。如果dbname参数为-,表示仍然连接当前数据库。如果忽略username,则表示继续使用当前的用户名。 |
| \copy | 其参数类似于SQL copy,功能则几乎等同于SQL copy,一个重要的差别是该内置命令可以将表的内容导出到本地,或者是从本地导入到数据库指定的表,而SQL copy则是将表中的数据导出到服务器的某个文件,或者是从服务器的文件导入到数据表。由此可见,SQL copy的效率要优于该内置命令。 |
| \d [pattern] | 显示和pattern匹配的数据库对象,如表、视图、索引或者序列。显示所有列,它们的类型,表空间(如果不是缺省的)和任何特殊属性。 |
| \db [pattern] | 列出所有可用的表空间。如果声明了pattern, 那么只显示那些匹配模式的表空间。 |
| \db+ [pattern] | 和上一个命令相比,还会新增显示每个表空间的权限信息。 |
| \df [pattern] | 列出所有可用函数,以及它们的参数和返回的数据类型。如果声明了pattern,那么只显示匹配(正则表达式)的函数。 |
| \df+ [pattern] | 和上一个命令相比,还会新增显示每个函数的附加信息,包括语言和描述。 |
| \distvS [pattern] | 这不是一个单独命令名称:字母 i、s、t、v、S 分别代表索引(index)、序列(sequence)、表(table)、视图(view)和系统表(system table)。你可以以任意顺序声明部分或者所有这些字母获得这些对象的一个列表。 |
| \dn [pattern] | 列出所有可用模式。如果声明了pattern,那么只列出匹配模式的模式名。 |
| \dn+ [pattern] | 和上一个命令相比,还会新增显示每个对象的权限和注释。 |
| \dp [pattern] | 生成一列可用的表和它们相关的权限。如果声明了pattern, 那么只列出名字可以匹配模式的表。 |
| \dT [pattern] | 列出所有数据类型或只显示那些匹配pattern的。 |
| \du [pattern] | 列出所有已配置用户或者只列出那些匹配pattern的用户。 |
| \echotext [ ... ] | 向标准输出打印参数,用一个空格分隔并且最后跟着一个新行。如:\echo `date` |
| \g[{filename ||command}] | 把当前的查询结果缓冲区的内容发送给服务器并且把查询的输出存储到可选的filename或者把输出定向到一个独立的在执行 command的Unix shell。 |
| \ifilename | 从文件filename中读取并把其内容当作从键盘输入的那样执行查询。 |
| \l | 列出服务器上所有数据库的名字和它们的所有者以及字符集编码。 |
| \o[{filename ||command}] | 把后面的查询结果保存到文件filename里或者把后面的查询结果定向到一个独立的shell command。 |
| \p | 打印当前查询缓冲区到标准输出。 |
| \q | 退出psql程序。 |
| \r | 重置(清空)查询缓冲区。 |
| \s [filename] | 将命令行历史打印出或是存放到filename。如果省略filename,历史将输出到标准输出。 |
| \t | 切换是否输出列/字段名的信息头和行记数脚注。 |
| \w{filename ||command} | 将当前查询缓冲区输出到文件filename或者定向到Unix命令command。 |
| \z [pattern] | 生成一个带有访问权限列表的数据库中所有表,视图和序列的列表。如果给出任何pattern,则被当成一个规则表达式,只显示匹配的表,视图和序列。 |
| \! [command] | 返回到一个独立的Unix shell或者执行Unix命令command。参数不会被进一步解释,shell将看到全部参数。 |
4. 内置命令应用示例:
在psql中,大部分的内置命令都比较易于理解,因此这里只是给出几个我个人认为相对容易混淆的命令。
# \c: 其中横线(-)表示仍然连接当前数据库,myuser是新的用户名。
postgres=# \c - myuser
Password for user myuser:
postgres=> SELECT user;
current_user
--------------
myuser
(1 row)
# 执行任意SQL语句。
postgres=# SELECT * FROM testtable WHERE i = 2;
i
---
2
(1 row)
# \g 命令会将上一个SQL命令的结果输出到指定文件。
postgres=# \g my_file_for_command_g
postgres=# \! cat my_file_for_command_g
i
---
2
(1 row)
# \g 命令会将上一个SQL命令的结果从管道输出到指定的Shell命令,如cat。
postgres=# \g | cat
i
---
2
(1 row)
# \p 打印上一个SQL命令。
postgres=# \p
SELECT * FROM testtable WHERE i = 2;
# \w 将上一个SQL命令输出到指定的文件。
postgres=# \w my_file_for_option_w
postgres=# \! cat my_file_for_option_w
SELECT * FROM testtable WHERE i = 2;
# \o 和\g相反,该命令会将后面psql命令的输出结果输出到指定的文件,直到遇到下一个独立的\o,
# 此后的命令结果将不再输出到该文件。
postgres=# \o my_file_for_option_o
postgres=# SELECT * FROM testtable WHERE i = 1;
# 终止后面的命令结果也输出到my_file_for_option_o文件中。
postgres=# \o
postgres=# \! cat my_file_for_option_o
i
---
1
(1 row)