有的时候PG给出的执行计划由于很多原因并不是最优的,需要手动指定执行路径时我们可以加载pg_hint_plan这个插件。
1 安装插件
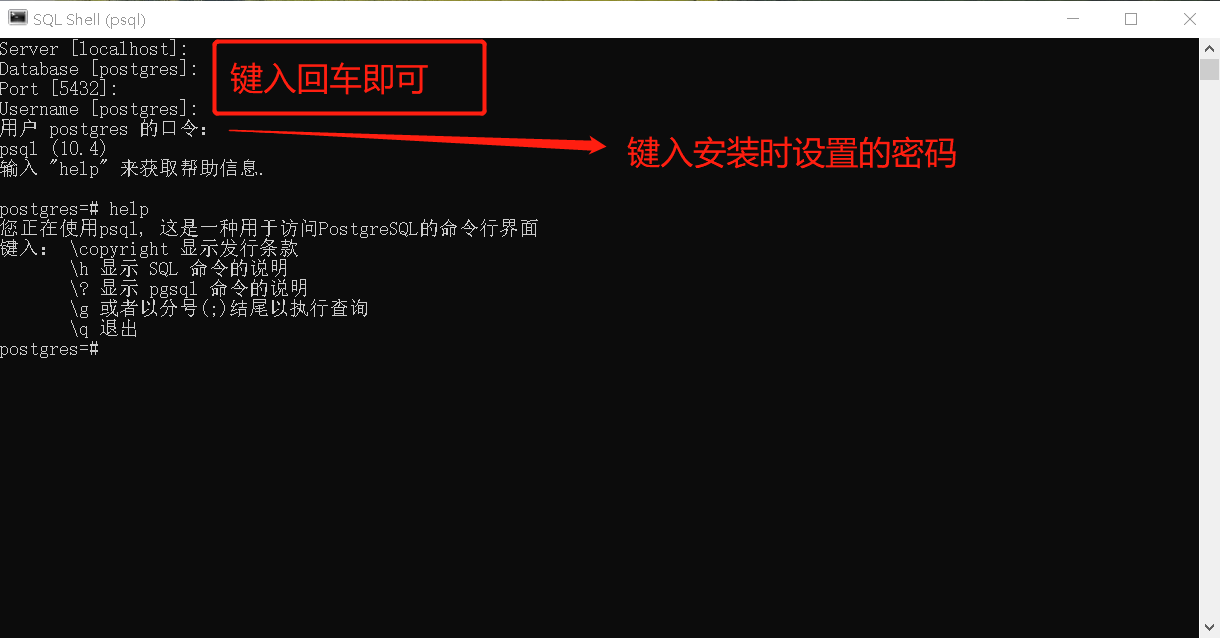
预先安装Postgres
有的时候PG给出的执行计划由于很多原因并不是最优的,需要手动指定执行路径时我们可以加载pg_hint_plan这个插件。
1 安装插件
预先安装Postgresql10.7
cd postgresql-10.7/contrib/ wget https://github.com/ossc-db/pg_hint_plan/archive/REL10_1_3_3.tar.gz tar xzvf pg_hint_plan-REL10_1_3_3.tar.gz cd pg_hint_plan-REL10_1_3_3 make make install
检查文件
cd $PGHOME ls lib/pg_hint_plan.so lib/pg_hint_plan.so ls share/extension/ pg_hint_plan--1.3.0--1.3.1.sql pg_hint_plan--1.3.2--1.3.3.sql pg_hint_plan.control plpgsql.control pg_hint_plan--1.3.1--1.3.2.sql pg_hint_plan--1.3.3.sql plpgsql--1.0.sql plpgsql--unpackaged--1.0.sql
2 加载插件
2.1 当前会话加载
LOAD 'pg_hint_plan';
注意这样加载只在当前回话生效。
2.2 用户、库级自动加载
alter user postgres set session_preload_libraries='pg_hint_plan'; alter database postgres set session_preload_libraries='pg_hint_plan';
配置错了的话就连不上数据库了!
如果配置错了,连接template1库执行
alter database postgres reset session_preload_libraries; alter user postgres reset session_preload_libraries;
2.3 cluster级自动加载
在postgresql.conf中修改shared_preload_libraries=‘pg_hint_plan'
重启数据库
3 检查是否已经加载
pg_hint_plan加载后在extension里面是看不到的,所以需要确认插件是否已经加载
show session_preload_libraries; session_preload_libraries --------------------------- pg_hint_plan
或者
show shared_preload_libraries;
如果使用load方式加载不需要检查。
4 使用插件定制执行计划
4.1 初始化测试数据
create table t1 (id int, t int, name varchar(255));
create table t2 (id int , salary int);
create table t3 (id int , age int);
insert into t1 values (1,200,'jack');
insert into t1 values (2,300,'tom');
insert into t1 values (3,400,'john');
insert into t2 values (1,40000);
insert into t2 values (2,38000);
insert into t2 values (3,18000);
insert into t3 values (3,38);
insert into t3 values (2,55);
insert into t3 values (1,12);
explain analyze select * from t1 left join t2 on t1.id=t2.id left join t3 on t1.id=t3.id;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Hash Right Join (cost=89.82..337.92 rows=17877 width=540) (actual time=0.053..0.059 rows=3 loops=1)
Hash Cond: (t3.id = t1.id)
-> Seq Scan on t3 (cost=0.00..32.60 rows=2260 width=8) (actual time=0.002..0.002 rows=3 loops=1)
-> Hash (cost=70.05..70.05 rows=1582 width=532) (actual time=0.042..0.043 rows=3 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 17kB
-> Hash Right Join (cost=13.15..70.05 rows=1582 width=532) (actual time=0.034..0.039 rows=3 loops=1)
Hash Cond: (t2.id = t1.id)
-> Seq Scan on t2 (cost=0.00..32.60 rows=2260 width=8) (actual time=0.002..0.002 rows=3 loops=1)
-> Hash (cost=11.40..11.40 rows=140 width=524) (actual time=0.017..0.017 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on t1 (cost=0.00..11.40 rows=140 width=524) (actual time=0.010..0.011 rows=3 loops=1)
Planning time: 0.154 ms
Execution time: 0.133 ms
创建索引
create index idx_t1_id on t1(id);
create index idx_t2_id on t2(id);
create index idx_t3_id on t3(id);
explain analyze select * from t1 left join t2 on t1.id=t2.id left join t3 on t1.id=t3.id;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Hash Left Join (cost=2.14..3.25 rows=3 width=540) (actual time=0.045..0.047 rows=3 loops=1)
Hash Cond: (t1.id = t3.id)
-> Hash Left Join (cost=1.07..2.14 rows=3 width=532) (actual time=0.030..0.032 rows=3 loops=1)
Hash Cond: (t1.id = t2.id)
-> Seq Scan on t1 (cost=0.00..1.03 rows=3 width=524) (actual time=0.005..0.006 rows=3 loops=1)
-> Hash (cost=1.03..1.03 rows=3 width=8) (actual time=0.007..0.007 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on t2 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=1)
-> Hash (cost=1.03..1.03 rows=3 width=8) (actual time=0.005..0.005 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on t3 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.002 rows=3 loops=1)
Planning time: 0.305 ms
Execution time: 0.128 ms
4.2 强制走index scan
/*+ indexscan(t1 idx_d)
/*+ indexscan(t1 idx_t1_id)
explain (analyze,buffers) select * from t1 where id=2;
QUERY PLAN
----------------------------------------------------------------------------------------------
Seq Scan on t1 (cost=0.00..1.04 rows=1 width=524) (actual time=0.011..0.013 rows=1 loops=1)
Filter: (id = 2)
Rows Removed by Filter: 2
Buffers: shared hit=1
Planning time: 0.058 ms
Execution time: 0.028 ms
explain (analyze,buffers) /*+ indexscan(t1) */select * from t1 where id=2;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Index Scan using idx_t1_id on t1 (cost=0.13..8.15 rows=1 width=524) (actual time=0.044..0.046 rows=1 loops=1)
Index Cond: (id = 2)
Buffers: shared hit=1 read=1
Planning time: 0.145 ms
Execution time: 0.072 ms
explain (analyze,buffers) /*+ indexscan(t1 idx_t1_id) */select * from t1 where id=2;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Index Scan using idx_t1_id on t1 (cost=0.13..8.15 rows=1 width=524) (actual time=0.016..0.017 rows=1 loops=1)
Index Cond: (id = 2)
Buffers: shared hit=2
Planning time: 0.079 ms
Execution time: 0.035 ms
4.3 强制多条件组合
/*+ indexscan(t2) indexscan(t1 idx_t1_id) */
/*+ seqscan(t2) indexscan(t1 idx_t1_id) */
explain analyze SELECT * FROM t1 JOIN t2 ON (t1.id = t2.id);
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Hash Join (cost=1.07..2.14 rows=3 width=532) (actual time=0.018..0.020 rows=3 loops=1)
Hash Cond: (t1.id = t2.id)
-> Seq Scan on t1 (cost=0.00..1.03 rows=3 width=524) (actual time=0.006..0.007 rows=3 loops=1)
-> Hash (cost=1.03..1.03 rows=3 width=8) (actual time=0.005..0.005 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on t2 (cost=0.00..1.03 rows=3 width=8) (actual time=0.001..0.003 rows=3 loops=1)
Planning time: 0.114 ms
Execution time: 0.055 ms
(8 rows)
组合两个条件走indexscan
/*+ indexscan(t2) indexscan(t1 idx_t1_id) */explain analyze SELECT * FROM t1 JOIN t2 ON (t1.id = t2.id);
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Merge Join (cost=0.26..24.40 rows=3 width=532) (actual time=0.047..0.053 rows=3 loops=1)
Merge Cond: (t1.id = t2.id)
-> Index Scan using idx_t1_id on t1 (cost=0.13..12.18 rows=3 width=524) (actual time=0.014..0.015 rows=3 loops=1)
-> Index Scan using idx_t2_id on t2 (cost=0.13..12.18 rows=3 width=8) (actual time=0.026..0.028 rows=3 loops=1)
组合两个条件走indexscan+seqscan
/*+ seqscan(t2) indexscan(t1 idx_t1_id) */explain analyze SELECT * FROM t1 JOIN t2 ON (t1.id = t2.id);
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.13..13.35 rows=3 width=532) (actual time=0.025..0.032 rows=3 loops=1)
Join Filter: (t1.id = t2.id)
Rows Removed by Join Filter: 6
-> Index Scan using idx_t1_id on t1 (cost=0.13..12.18 rows=3 width=524) (actual time=0.016..0.018 rows=3 loops=1)
-> Materialize (cost=0.00..1.04 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=3)
-> Seq Scan on t2 (cost=0.00..1.03 rows=3 width=8) (actual time=0.004..0.005 rows=3 loops=1)
4.4 强制指定join method
/*+ NestLoop(t1 t2) MergeJoin(t1 t2 t3) Leading(t1 t2 t3) */
/*+ NestLoop(t1 t2 t3) MergeJoin(t2 t3) Leading(t1 (t2 t3)) */
explain analyze select * from t1 left join t2 on t1.id=t2.id left join t3 on t1.id=t3.id;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Hash Left Join (cost=2.14..3.25 rows=3 width=540) (actual time=0.053..0.056 rows=3 loops=1)
Hash Cond: (t1.id = t3.id)
-> Hash Left Join (cost=1.07..2.14 rows=3 width=532) (actual time=0.036..0.038 rows=3 loops=1)
Hash Cond: (t1.id = t2.id)
-> Seq Scan on t1 (cost=0.00..1.03 rows=3 width=524) (actual time=0.007..0.007 rows=3 loops=1)
-> Hash (cost=1.03..1.03 rows=3 width=8) (actual time=0.009..0.009 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on t2 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=1)
-> Hash (cost=1.03..1.03 rows=3 width=8) (actual time=0.006..0.006 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on t3 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=1)
强制走循环嵌套连接
/*+ NestLoop(t1 t2) MergeJoin(t1 t2 t3) Leading(t1 t2 t3) */
explain analyze select * from t1 left join t2 on t1.id=t2.id left join t3 on t1.id=t3.id;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Merge Left Join (cost=3.28..3.34 rows=3 width=540) (actual time=0.093..0.096 rows=3 loops=1)
Merge Cond: (t1.id = t3.id)
-> Sort (cost=2.23..2.23 rows=3 width=532) (actual time=0.077..0.078 rows=3 loops=1)
Sort Key: t1.id
Sort Method: quicksort Memory: 25kB
-> Nested Loop Left Join (cost=0.00..2.20 rows=3 width=532) (actual time=0.015..0.020 rows=3 loops=1)
Join Filter: (t1.id = t2.id)
Rows Removed by Join Filter: 6
-> Seq Scan on t1 (cost=0.00..1.03 rows=3 width=524) (actual time=0.005..0.005 rows=3 loops=1)
-> Materialize (cost=0.00..1.04 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=3)
-> Seq Scan on t2 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=1)
-> Sort (cost=1.05..1.06 rows=3 width=8) (actual time=0.012..0.013 rows=3 loops=1)
Sort Key: t3.id
Sort Method: quicksort Memory: 25kB
-> Seq Scan on t3 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=1)
控制连接顺序
/*+ NestLoop(t1 t2 t3) MergeJoin(t2 t3) Leading(t1 (t2 t3)) */
explain analyze select * from t1 left join t2 on t1.id=t2.id left join t3 on t1.id=t3.id;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Nested Loop Left Join (cost=1.07..3.31 rows=3 width=540) (actual time=0.036..0.041 rows=3 loops=1)
Join Filter: (t1.id = t3.id)
Rows Removed by Join Filter: 6
-> Hash Left Join (cost=1.07..2.14 rows=3 width=532) (actual time=0.030..0.032 rows=3 loops=1)
Hash Cond: (t1.id = t2.id)
-> Seq Scan on t1 (cost=0.00..1.03 rows=3 width=524) (actual time=0.008..0.009 rows=3 loops=1)
-> Hash (cost=1.03..1.03 rows=3 width=8) (actual time=0.007..0.007 rows=3 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on t2 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.004 rows=3 loops=1)
-> Materialize (cost=0.00..1.04 rows=3 width=8) (actual time=0.001..0.002 rows=3 loops=3)
-> Seq Scan on t3 (cost=0.00..1.03 rows=3 width=8) (actual time=0.002..0.003 rows=3 loops=1)
4.5 控制单条SQL的cost
/*+ set(seq_page_cost 20.0) seqscan(t1) */
/*+ set(seq_page_cost 20.0) seqscan(t1) */explain analyze select * from t1 where id > 1;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Seq Scan on t1 (cost=0.00..20.04 rows=1 width=524) (actual time=0.011..0.013 rows=2 loops=1)
Filter: (id > 1)
Rows Removed by Filter: 1
set seq_page_cost 200,注意下面的cost已经变成了200.04
/*+ set(seq_page_cost 200.0) seqscan(t1) */explain analyze select * from t1 where id > 1;
QUERY PLAN
------------------------------------------------------------------------------------------------
Seq Scan on t1 (cost=0.00..200.04 rows=1 width=524) (actual time=0.010..0.011 rows=2 loops=1)
Filter: (id > 1)
Rows Removed by Filter: 1
以上为个人经验,希望能给大家一个参考,也希望大家多多支持好代码网。如有错误或未考虑完全的地方,望不吝赐教。