实时计算是什么?
请看下面的图:

我们以热卖产品的统计为例,看下传统的计算手段:
1将用户行为、log等信息清洗后保存在数据库中.
2将订单信息保存在数据库中.
3利用触发器或者协程等方式建立本地索引,或者远程的独立索引.
4join订单信息、订单明细、用户信息、商品信息等等表,聚合统计20分钟内热卖产品,并返回top-10.
5web或app展示.
这是一个假想的场景,但假设你具有处理类似场景的经验,应该会体会到这样一些问题和难处:
1、水平扩展问题(scale-out)
显然,如果是一个具有一定规模的电子商务网站,数据量都是很大的。而交易信息因为涉及事务,所以很难直接舍弃关系型数据库的事务能力,迁移到具有更好的scale-out能力的NoSQL数据库中。
那么,一般都会做sharding。历史数据还好说,我们可以按日期来归档,并可以通过批处理式的离线计算,将结果缓存起来。
但是,这里的要求是20分钟内,这很难。
2、性能问题
这个问题,和scale-out是一致的,假设我们做了sharding,因为表分散在各个节点中,所以我们需要多次入库,并在业务层做聚合计算。
问题是,20分钟的时间要求,我们需要入库多少次呢?
10分钟呢?
5分钟呢?
实时呢?
而且,业务层也同样面临着单点计算能力的局限,需要水平扩展,那么还需要考虑一致性的问题。
所以,到这里一切都显得很复杂。
3、业务扩展问题
假设我们不仅仅要处理热卖商品的统计,还要统计广告点击、或者迅速根据用户的访问行为判断用户特征以调整其所见的信息,更加符合用户的潜在需求等,那么业务层将会更加复杂。
也许你有更好的办法,但实际上,我们需要的是一种新的认知:
这个世界发生的事,是实时的。
所以我们需要一种实时计算的模型,而不是批处理模型。
我们需要的这种模型,必须能够处理很大的数据,所以要有很好的scale-out能力,最好是,我们都不需要考虑太多一致性、复制的问题。
那么,这种计算模型就是实时计算模型,也可以认为是流式计算模型。
现在假设我们有了这样的模型,我们就可以愉快地设计新的业务场景:
转发最多的微博是什么?
最热卖的商品有哪些?
大家都在搜索的热点是什么?
我们哪个广告,在哪个位置,被点击最多?
或者说,我们可以问:
这个世界,在发生什么?
最热的微博话题是什么?
我们以一个简单的滑动窗口计数的问题,来揭开所谓实时计算的神秘面纱。
假设,我们的业务要求是:
统计20分钟内最热的10个微博话题。
解决这个问题,我们需要考虑:
1、数据源
这里,假设我们的数据,来自微博长连接推送的话题。
2、问题建模
我们认为的话题是#号扩起来的话题,最热的话题是此话题出现的次数比其它话题都要多。
比如:@foreach_break : 你好,#世界#,我爱你,#微博#。
“世界”和“微博”就是话题。
3、计算引擎
我们采用storm。
4、定义时间
如何定义时间?
时间的定义是一件很难的事情,取决于所需的精度是多少。
根据实际,我们一般采用tick来表示时刻这一概念。
在storm的基础设施中,executor启动阶段,采用了定时器来触发“过了一段时间”这个事件。
如下所示:
(defn setup-ticks! [worker executor-data]
(let [storm-conf (:storm-conf executor-data)
tick-time-secs (storm-conf TOPOLOGY-TICK-TUPLE-FREQ-SECS)
receive-queue (:receive-queue executor-data)
context (:worker-context executor-data)]
(when tick-time-secs
(if (or (system-id? (:component-id executor-data))
(and (= false (storm-conf TOPOLOGY-ENABLE-MESSAGE-TIMEOUTS))
(= :spout (:type executor-data))))
(log-message "Timeouts disabled for executor " (:component-id executor-data) ":" (:executor-id executor-data))
(schedule-recurring
(:user-timer worker)
tick-time-secs
tick-time-secs
(fn []
(disruptor/publish
receive-queue
[[nil (TupleImpl. context [tick-time-secs] Constants/SYSTEM_TASK_ID Constants/SYSTEM_TICK_STREAM_ID)]]
)))))))
每隔一段时间,就会触发这样一个事件,当流的下游的bolt收到一个这样的事件时,就可以选择是增量计数还是将结果聚合并发送到流中。
bolt如何判断收到的tuple表示的是“tick”呢?
负责管理bolt的executor线程,从其订阅的消息队列消费消息时,会调用到bolt的execute方法,那么,可以在execute中这样判断:
public static boolean isTick(Tuple tuple) {
return tuple != null
&& Constants.SYSTEM_COMPONENT_ID .equals(tuple.getSourceComponent())
&& Constants.SYSTEM_TICK_STREAM_ID.equals(tuple.getSourceStreamId());
}
结合上面的setup-tick!的clojure代码,我们可以知道SYSTEM_TICK_STREAM_ID在定时事件的回调中就以构造函数的参数传递给了tuple,那么SYSTEM_COMPONENT_ID是如何来的呢?
可以看到,下面的代码中,SYSTEM_TASK_ID同样传给了tuple:
;; 请注意SYSTEM_TASK_ID和SYSTEM_TICK_STREAM_ID
(TupleImpl. context [tick-time-secs] Constants/SYSTEM_TASK_ID Constants/SYSTEM_TICK_STREAM_ID)
然后利用下面的代码,就可以得到SYSTEM_COMPONENT_ID:
public String getComponentId(int taskId) {
if(taskId==Constants.SYSTEM_TASK_ID) {
return Constants.SYSTEM_COMPONENT_ID;
} else {
return _taskToComponent.get(taskId);
}
}
滑动窗口
有了上面的基础设施,我们还需要一些手段来完成“工程化”,将设想变为现实。
这里,我们看看Michael G. Noll的滑动窗口设计。
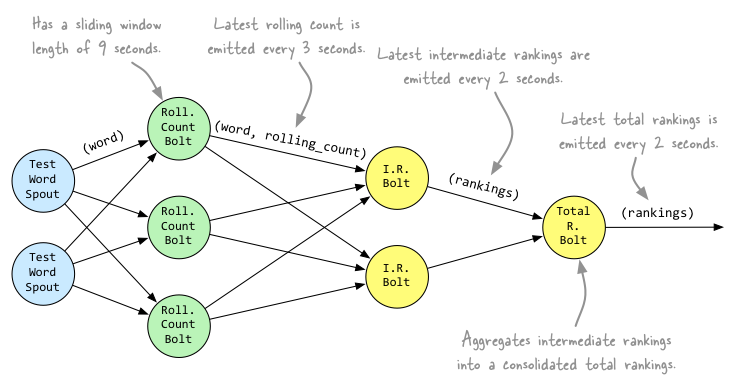
 Topology
Topology
String spoutId = "wordGenerator";
String counterId = "counter";
String intermediateRankerId = "intermediateRanker";
String totalRankerId = "finalRanker";
// 这里,假设TestWordSpout就是我们发送话题tuple的源
builder.setSpout(spoutId, new TestWordSpout(), 5);
// RollingCountBolt的时间窗口为9秒钟,每3秒发送一次统计结果到下游
builder.setBolt(counterId, new RollingCountBolt(9, 3), 4).fieldsGrouping(spoutId, new Fields("word"));
// IntermediateRankingsBolt,将完成部分聚合,统计出top-n的话题
builder.setBolt(intermediateRankerId, new IntermediateRankingsBolt(TOP_N), 4).fieldsGrouping(counterId, new Fields(
"obj"));
// TotalRankingsBolt, 将完成完整聚合,统计出top-n的话题
builder.setBolt(totalRankerId, new TotalRankingsBolt(TOP_N)).globalGrouping(intermediateRankerId);
上面的topology设计如下:
将聚合计算与时间结合起来
前文,我们叙述了tick事件,回调中会触发bolt的execute方法,那可以这么做:
RollingCountBolt:
@Override
public void execute(Tuple tuple) {
if (TupleUtils.isTick(tuple)) {
LOG.debug("Received tick tuple, triggering emit of current window counts");
// tick来了,将时间窗口内的统计结果发送,并让窗口滚动
emitCurrentWindowCounts();
}
else {
// 常规tuple,对话题计数即可
countObjAndAck(tuple);
}
}
// obj即为话题,增加一个计数 count++
// 注意,这里的速度基本取决于流的速度,可能每秒百万,也可能每秒几十.
// 内存不足? bolt可以scale-out.
private void countObjAndAck(Tuple tuple) {
Object obj = tuple.getValue(0);
counter.incrementCount(obj);
collector.ack(tuple);
}
// 将统计结果发送到下游
private void emitCurrentWindowCounts() {
Map<Object, Long> counts = counter.getCountsThenAdvanceWindow();
int actualWindowLengthInSeconds = lastModifiedTracker.secondsSinceOldestModification();
lastModifiedTracker.markAsModified();
if (actualWindowLengthInSeconds != windowLengthInSeconds) {
LOG.warn(String.format(WINDOW_LENGTH_WARNING_TEMPLATE, actualWindowLengthInSeconds, windowLengthInSeconds));
}
emit(counts, actualWindowLengthInSeconds);
}
上面的代码可能有点抽象,看下这个图就明白了,tick一到,窗口就滚动:
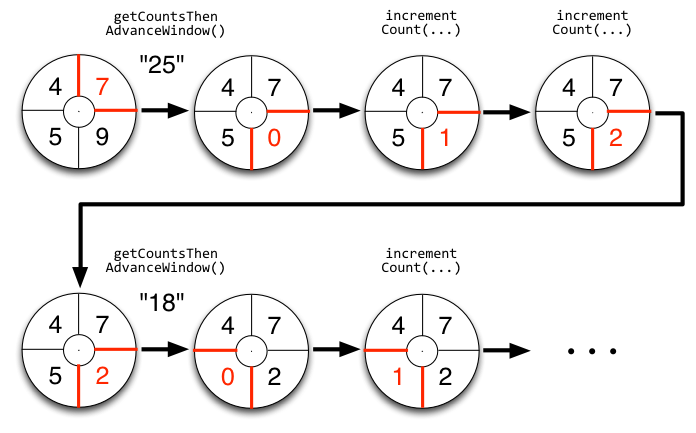
IntermediateRankingsBolt & TotalRankingsBolt:
public final void execute(Tuple tuple, BasicOutputCollector collector) {
if (TupleUtils.isTick(tuple)) {
getLogger().debug("Received tick tuple, triggering emit of current rankings");
// 将聚合并排序的结果发送到下游
emitRankings(collector);
}
else {
// 聚合并排序
updateRankingsWithTuple(tuple);
}
}
其中,IntermediateRankingsBolt和TotalRankingsBolt的聚合排序方法略有不同:
IntermediateRankingsBolt的聚合排序方法:
// IntermediateRankingsBolt的聚合排序方法:
@Override
void updateRankingsWithTuple(Tuple tuple) {
// 这一步,将话题、话题出现的次数提取出来
Rankable rankable = RankableObjectWithFields.from(tuple);
// 这一步,将话题出现的次数进行聚合,然后重排序所有话题
super.getRankings().updateWith(rankable);
}
TotalRankingsBolt的聚合排序方法:
// TotalRankingsBolt的聚合排序方法
@Override
void updateRankingsWithTuple(Tuple tuple) {
// 提出来自IntermediateRankingsBolt的中间结果
Rankings rankingsToBeMerged = (Rankings) tuple.getValue(0);
// 聚合并排序
super.getRankings().updateWith(rankingsToBeMerged);
// 去0,节约内存
super.getRankings().pruneZeroCounts();
}
而重排序方法比较简单粗暴,因为只求前N个,N不会很大:
private void rerank() {
Collections.sort(rankedItems);
Collections.reverse(rankedItems);
}
结语
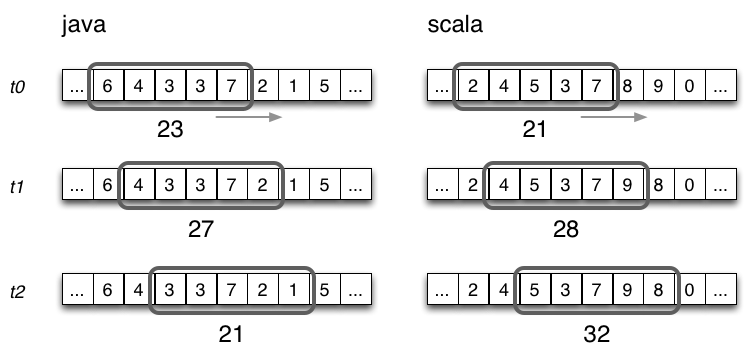
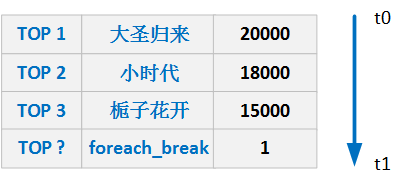
下图可能就是我们想要的结果,我们完成了t0 - t1时刻之间的热点话题统计,其中的foreach_break仅仅是为了防盗版 : ].
以上就是本文的全部内容,希望大家喜欢。