InnoDB架构图
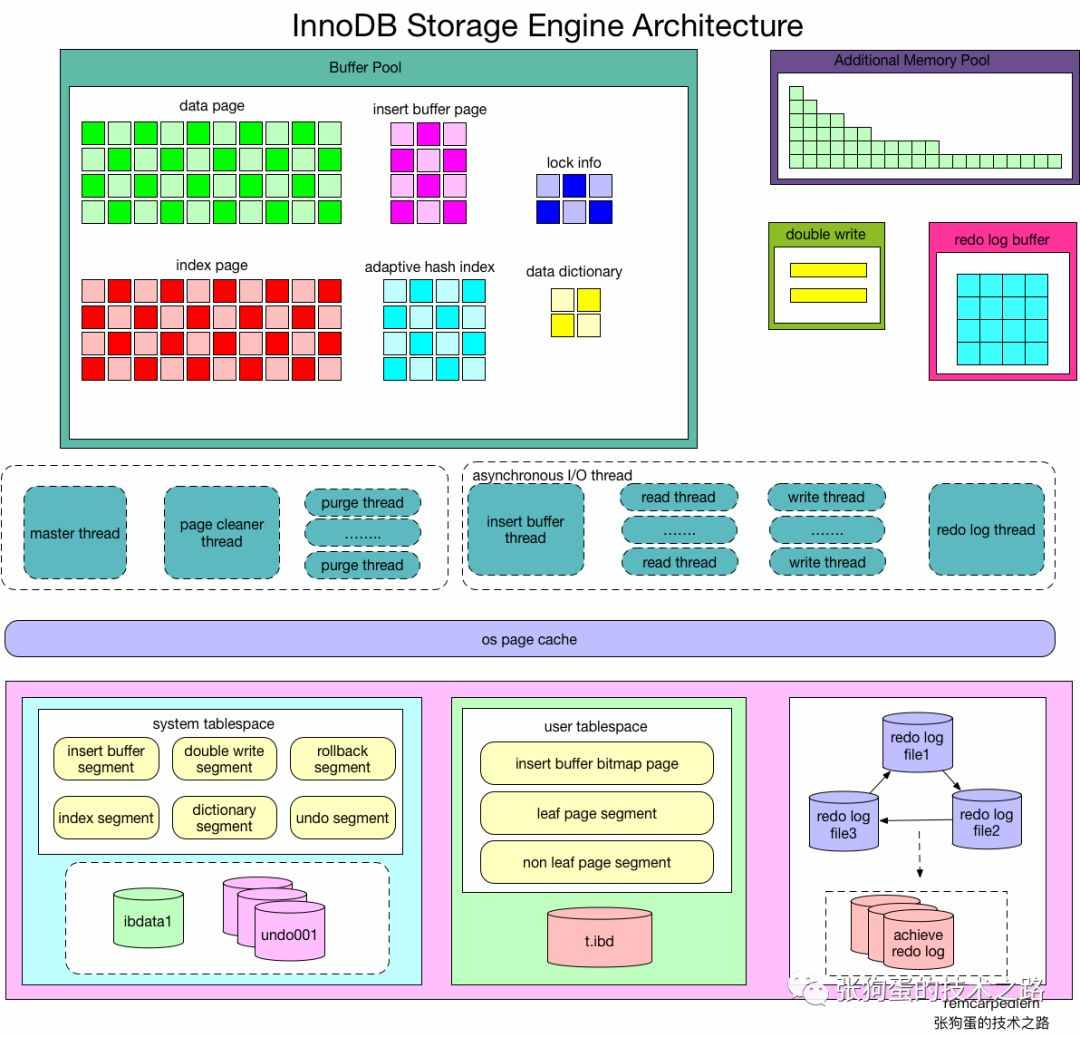
内存结构
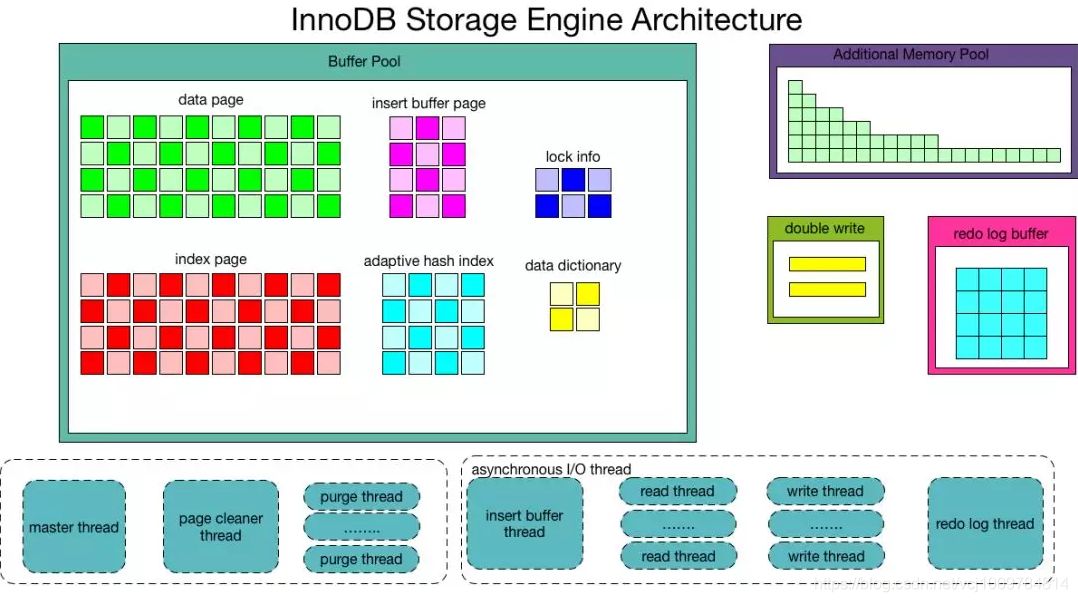
Buffer Pool
why buffer pool ?
InnoDB是基于磁盘存储,其存储的最基本单元是页,大小为16KB。而CPU和磁盘之间速度相差悬殊,所以通常使用内存中的缓冲池来提高性能。
what is buffer pool ?
缓冲池里主要缓存了:
data page 数据页
index page 索引页
insert buffer
what is insert buffer ?
插入缓冲, 用于将多个insert操作合并成一个,减少IO开销,提高插入性能。只能用在非唯一的辅助索引。
why ?
插入主键索引时是顺序的,不需要随机IO,速度会很快。但对于非唯一的辅助索引,插入的叶子节点是分散的,需要离散的访问索引页。
how does it work ?
对非唯一辅助索引,索引的修改并非实时更新索引树的叶子节点,而是把若干个对同一页的更新操作缓存起来,合并为一次操作,从随机IO转为顺序IO,减少IO次数,提高写入性能。
流程:
先判断要更新的索引页,是否在缓冲池中
- 若是,直接插入
- 若不是,则存入Insert Buffer,后交给Master Thread 来进行合并
extend :
一开始只针对INSERT操作,所以叫insert buffer,后来能够支持 INSERT/UPDATE/DELETE,所以改叫change buffer了
若是唯一索引,在插入时需要检查索引列的值是否存在,故在修改索引之前,需要把相关的索引页读出来,去判断是否唯一,这时Insert Buffer就失效了。
lock info 锁信息
data dictionary 数据字典(主要包括了一些元数据信息,如表结构信息)
adaptive hash index 自适应hash索引,InnoDB为热点页建立的索引,用以提高查询效率
how does it work ?
数据库的读操作,会先判断欲读取的页是否在缓冲池中,若是,则命中缓冲;否则,从磁盘上读取,并将读取到的页放入缓冲池。
数据库的写操作,是先修改缓冲池中的页,再以一定频率,将缓冲池刷新到磁盘。将数据从缓冲池刷新到磁盘,是通过一种checkPoint的机制完成的
practice ?
可通过配置参数innodb_buffer_pool_size来设置缓冲池大小
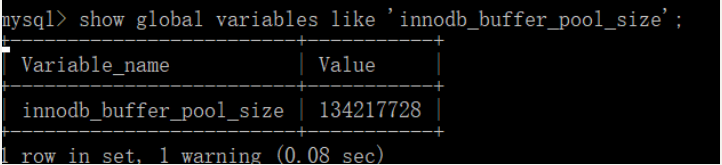
可以看到本机的mysql缓冲池大小为134217728B,换算后是128MB
Redo log buffer
why redo log buffer ?
当缓冲池中的页是脏页(修改数据时,是先修改缓冲池中的数据,此时缓冲池中的数据和磁盘上不一致,称为脏页)时,需要通过某种机制将脏页刷新到磁盘。若缓冲池中一有数据页发生改变,就马上刷新磁盘,效率会很低。所以InnoDB采用Write Ahead Log策略,事务提交时,先将redo log写入磁盘,这样就认为脏页已经写入到磁盘了。之后再通过checkpoint机制择时将脏页真正写入磁盘,脏页真正写入磁盘后,就可以删掉对应的redo log了。若脏页还没写入磁盘,发生了宕机,则由于redo log已经成功写入磁盘,故可以通过redo log进行数据恢复。
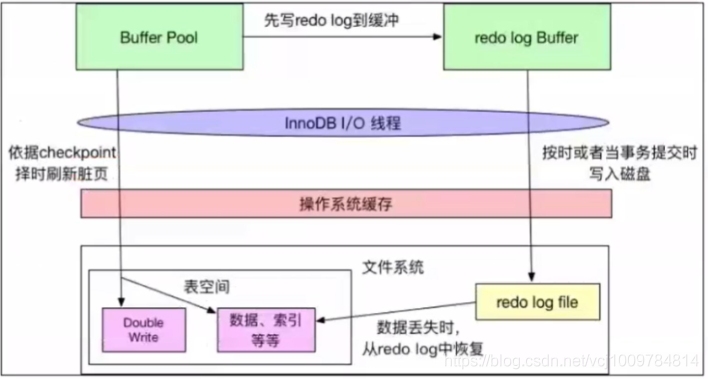
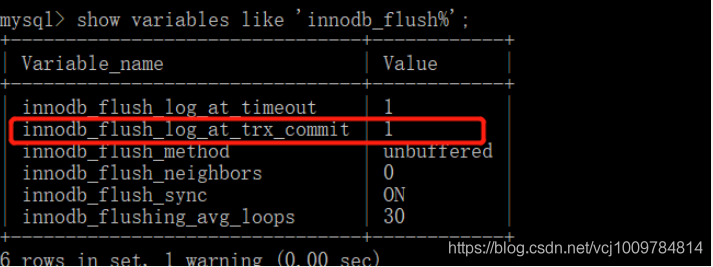
redo log保证了事务的持久性。写redo log时,先将redo log放入redo log buffer,再将redo log按一定策略刷新到磁盘,这是通过innodb_flush_log_at_trx_commit参数来配置的,参数名在不同的mysql版本或许有不一样,通过如下命令可以查看:
show variables like 'innodb_flush%';
innodb_flush_log_at_trx_commit参数配置有3个取值:0,1,2 其含义如下图所示

innodb_flush_log_at_trx_commit属性可以控制每次事务提交时InnoDB的行为。当属性值为0时,事务提交时,redo log被写到redo log buffer,然后等待主线程按时写入;当属性值为1时,事务提交时,会将redo log写入文件系统缓存,并且调用文件系统的fsync,将文件系统缓冲中的数据真正写入磁盘存储,确保不会出现数据丢失;当属性值为2时,事务提交时,也会将日志文件写入文件系统缓存,但是不会调用fsync,而是让文件系统自己去判断何时将缓存写入磁盘。
当参数值为0时,写入效率最高,但是数据安全最低;参数值为1时,写入效率最低,但是数据安全最高;参数值为2时,二者都是中等水平。一般建议将该属性值设置为1,以获得较高的数据安全性,而且也只有设置为1,才能保证事务的持久性。
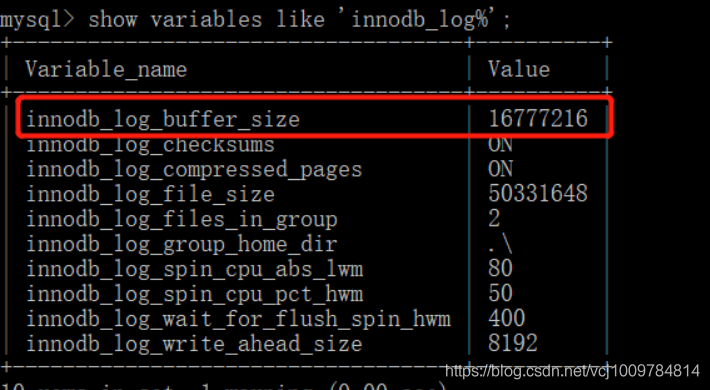
redo log buffer的大小可以通过innodb_log_buffer_size去控制
Double Write Buffer
双写缓冲,和磁盘文件中系统表空间里的Double Write Segment一起解决了页的部分写入失效问题。
MySQL数据库IO的最小单位是16KB,文件系统(File System)IO的最小单位是4KB,磁盘IO的最小单位是512B。(具体的大小可能有差异,但意思就是这么个意思,MySQL的基本存储单位和文件系统的基本存储单位大小不一致)。由于MySQL的1个单位(页),相当于文件系统中的4个单位,在将内存中的脏页刷新到磁盘时,一页会分4次进行写入,若在写入过程中发生意外情况,比如断电,宕机,则可能成功写入2次,即写入了8KB,那另外8KB还是旧的数据,这叫做部分写失败,导致这一页的数据,一半是新的,一半是旧,数据不完整,成为坏页,最终数据不一致。此时redo log 也无能为力,因为redo log记录的是对物理页的修改操作,此时页本身已经损坏,再对损坏的页应用修改操作,也无法恢复为完整数据。
Double Write就是为了解决这个问题。
Double Write 由2部分组成
- 内存中的Double Write Buffer(2M)
- 磁盘共享表空间中的Double Write Segment(2M)
它的工作机制是这样的
- 当触发了脏页刷新时,脏页并不直接写入磁盘文件,而是先拷贝到内存中的Double Write Buffer
- 接着将Double Write Buffer,分两次写入到共享表空间中,每次写1MB
- 最后再将Double Write Buffer中的脏页数据,写入到实际的各个表空间里,写入完成后,即标记对应的Double Write 数据可被覆盖
若发生意外宕机等情况,先从共享表空间中取出Double Write数据,复制到表空间中,再应用redo log,这样即完成了数据恢复。
优点:
提高了数据的可靠性
缺点:
由于Double Write 实际是一个物理文件,即是一个file,它会导致操作系统进行更多的fsync刷盘操作,所以它会降低mysql的性能。然而,double write buffer往磁盘写的时候是顺序写入,性能很高。
可以关闭Double Write的场景
- 频繁的DML
- 不担心数据损坏和丢失
- 系统主要负载集中在写操作
简单来说,就是加了一个中间层,先将要写入磁盘的数据,暂存到一个中继站,成功存到中继站之后,再进行实际的写磁盘,写完磁盘后,再告诉中继站说,刚才暂存到你那里的数据我已经落盘了,你可以把它标记为无用数据了。相当于拿这个中继站做了数据的保险。如果在实际写磁盘时,发生意外,那么损坏的数据块,我可以从中继站那里拿到一份完整的拷贝,保证了数据的完整性。
磁盘文件
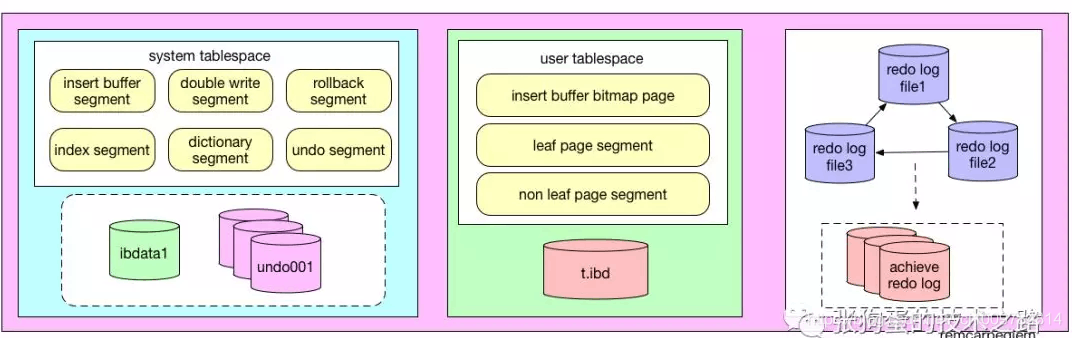
表空间
系统表空间(共享表空间 ibdata1)
它是被多个表共享的,可以通过
innodb_data_file_path参数对系统表空间进行配置
# 格式 innodb_data_file_path = datafile1[,datafile2] # 可以指定多个文件,共同组成系统表空间 innodb_data_file_path = /db/ibdata1:1000M;/db/ibdata2:1000M # 设置了这个参数后,所有基于InnoDB的表,都会被存储到系统表空间
- 数据字典(各种元数据,如表结构的定义)
- Double Write Buffer
- Insert Buffer (Change Buffer)
- undo log
- 在系统表空间创建的表数据,索引数据
用户表空间(独立表空间 ibd)
# 开启独立表空间 innodb_file_per_table = 1 # 设置这个参数后,每个表都是一个单独的 .ibd 文件
我本机的MySQL是默认开启了这个参数
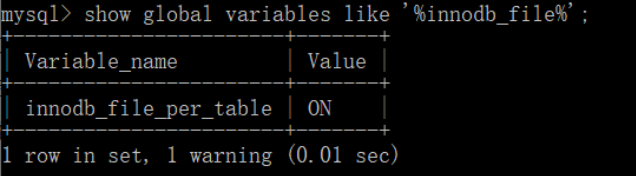
所以都是一个表一个ibd文件

但是独立表空间里,只存了数据,索引,插入缓冲bitmap。其余的信息还是存在系统表空间。
重做日志文件
redo log :
一般InnoDB的数据目录下,会有2个名为ib_logfile0和ib_logfile1的文件,这就是redo log文件

每个InnoDB引擎的表至少要有1个重做日志组(group),一个group下至少有2个重做日志。为了得到更高的可靠性,用户可设置多个镜像日志组
InnoDB根据checkpoint对2个文件进行循环写入。
可通过innodb_log_file_size设置redo log的大小。若设置太大,数据丢失时,恢复可能要花很长时间;若设置太小,则会导致checkpoint进行频繁检查,并将脏页刷新到磁盘,导致性能抖动。
重做日志的落盘机制在上面的redo log buffer里已经说明,简单总结起来就是2个机制:Write Ahead Log + Force Log at Commit
这两者保证了事务的持久性
一次写操作的事务流程如下图所示:
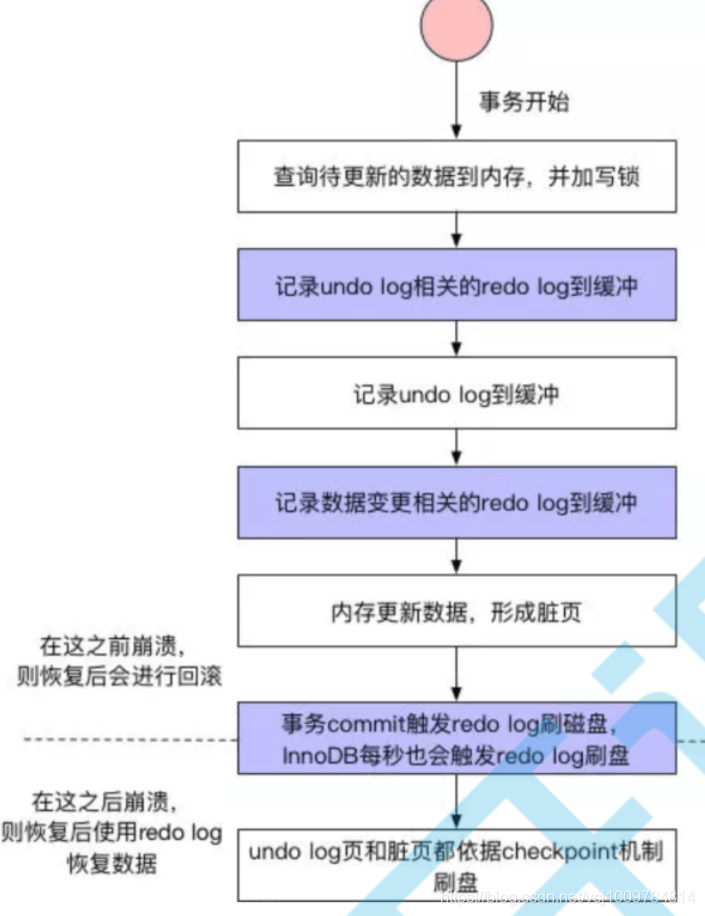
若发生了崩溃,则恢复数据的过程如下图所示:
binlog是维护在SQL Layer层的,故不包含在InnoDB中。
以上就是MySQL学习之InnoDB结构探秘的详细内容,更多关于InnoDB结构探秘的资料请关注好代码网其它相关文章!
