为什么做优化??
因为数据量太多了,项目部署上线再到用户使用,每天数据增长几十万条,给服务器带来非常大的负担,互联网一直追求高性能,可是随着业务规模变大,用户数量变多,服务器的性能越来越差,因此我们不得不对数据库有更高要求。
从哪些方面入手??
第一,是查询的速度,我们期望数据量到达TB级别仍然能够实现百万级别查询速度。
第二、是并发量,我们对它的要求能够同时处理几千甚至上万的并发访问,还要配合Redis、MQ等。
第三,高可用,随着业务规模不断变大,我们要随时准备对服务器进行扩展,可能由原来几十台服务器扩展到上百台甚至上千台服务器,所以我们要搭载MySQL集群。
第四,事务的安全性,当业务出现高并发访问,怎么保证读写一致性???保证事务的安全性??? 参考多线程的思路。。
解决方案是什么???
第一个思考的是应该用什么样的存储引擎,因为存储引擎决定着它的性能,好比你是用汽车、飞机还是坦克, 每个引擎都有它特殊的作用。 业务上常用的是两种,INNODB和MYISAM。
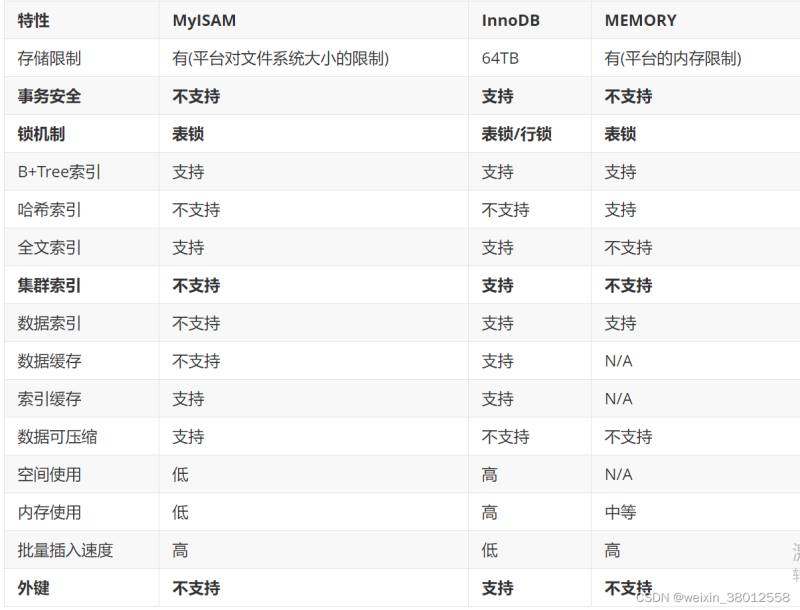
要怎样选择???
当我们对业务没有过多的读写要求,以查询为主,使用MyISAM,当我们对事务完整性要求较高,并发要求高,增删频繁,经常进行读写操作,使用INNODB更好。
第二个我们要给加快查询速度, 所以要给表特殊字段添加索引,索引的原理是改变数据的存储结构,这里分为两种:第一是BTree,第二是B+Tree。 我们业务上一般使用的是B+Tree,BTree有一个特点,是根节点和叶子节点都会存放数据,这会造成比如查询最底层叶子节点,会一层一层读根节点的数据,会增加磁盘I/O次数,无形当中又会增加数据库的压力。 所以要用B+Tree
第三实现高可用方案, 这里我们会为数据库服务搭载主从结构集群,缓解读和写的压力
第四是安全问题,这里可以参考线程的安全问题,比如怎么解决高并发访问??如何能保证事务的完整性?? 像RocketMQ也涉及事务消息, 如何避免这类问题, 我们可以上锁。 以下是锁的分类。

SQL优化
1、查询尽量避免全表扫描,首先考虑在where、order by字段上添加索引
2、避免在where字段上使用NULL值,所以在设计表时尽量使用NOT NULL约束,有些数据会默认为NULL,可以设置默认值为0或者-1
3、避免在where子句中使用!=或<>操作符,Mysql只对<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE使用索引
4、避免在where中使用OR来连接条件,否则可能导致引擎放弃索引来执行全表扫描,可以使用UNION进行合并查询
select id from t where num = 30 union select id from t where num = 40;
5、尽量避免在where子句中进行函数或者表达式操作
6、最好不要使用select * from t,用具体的字段列表代替"*",不要返回用不到的任何字段
7、in 和 not in 也要慎用,否则会导致全表扫描,如
select id from t where num IN(1,2,3)如果是连续的值建议使用between and,select id from t where between 1 and 3;
8、select id from t where col like %a%;模糊查询左侧有%会导致全表检索,如果需要全文检索可以使用全文搜索引擎比如es,slor
9、limit offset rows关于分页查询,尽量保证不要出现大的offset,比如limit 10000,10相当于对已查询出来的行数弃掉前10000行后再取10行,完全可以加一些条件过滤一下(完成筛选),而不应该使用limit跳过已查询到的数据。这是一个==offset做无用功==的问题。对应实际工程中,要避免出现大页码的情况,尽量引导用户做条件过滤
总结
到此这篇关于MySQL数据库性能优化介绍的文章就介绍到这了,更多相关MySQL性能优化内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!
