1、面向过程
面向过程 是流水线线式的编程,按照排好的顺序,一环扣一环,每个环节都是承上启下的,就行像是汽车的流水生产线,如果要修改,
就是牵一发而动全身,其他的地方都要修改,不宜扩展新功能
优点是:极大的降低了程序的复杂度
缺点是:一套流水线或者流程就是用来解决一个问题,生产汽水的流水线无法生产汽车,即便是能,也得是大改,改一个组件,牵一发而动全身。
应用场景:一旦完成基本很少改变的场景,著名的例子有Linux內核,git,以及Apache HTTP Server等
2、面向对象
把一个个功能和目标分开,单独来做,不分先后,不按顺序,可以开发那个功能就开发那个功能,彼此之间不受影响,可以随时 添加,修改
新的功能和旧的功能,在互联网时代,需求更新加速,面向对象的扩展性就得到了发挥。
优点是:解决了程序的扩展性。对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
缺点:可控性差,无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法预测最终结果。于是我们经常看到一个游戏人某一参数的修改极有可能导致阴霸的技能出现,一刀砍死3个人,这个游戏就失去平衡。
应用场景:需求经常变化的软件,一般需求的变化都集中在用户层,互联网应用,企业内部软件,游戏等都是面向对象的程序设计大显身手的好地方
面向对象的程序设计并不是全部。对于一个软件质量来说,面向对象的程序设计只是用来解决扩展性。
3、类 和 对象
在Python中,一切皆对象
在现实生活中,任何东西,都有自己的特征和技能,这是区分其他东西的重要特征,特征即数据属性,技能即方法属性,特征与技能的结合体就一个对象。
类: 就是从一组对象中提取相同的特征和技能,
在Python中,用变量表示特征,用函数表示技能,类就是变量和函数的结合体,
对象就是变量和方法(类的函数)的结合体。
举列子:定义类
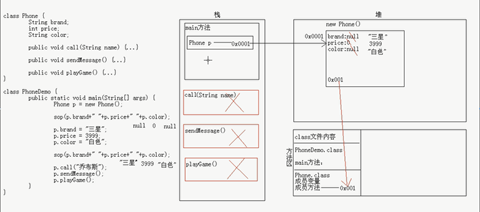
class Chinese: #class定义一个中国人的类 ,同常类的首字母是大写 # 特征是数据属性 country='chinese' #共同的特征是说中国话 #技能是方法属性 def eat(self): #共同的技能eat,用函数eat() 表示 print('eating') def talk(self): #共同的技能talk,用函数talk()表示 print('talking') Chinese() #根据特征和技能得到对象
定义类 得到 对象
1 class Chinese: 2 #共同的特征 3 country='china' 4 5 def __init__(self,name ,age,color): 6 #初始化,不能返回值 7 # 每个人除了相同的技能(方法属性),还有其他不同的地方, 8 #在这里给每个人传入自己的独有的(方法属性) 9 self.name=name 10 self.age=age 11 self.color=color 12 13 #共同的技能 14 def eat(self): 15 print('eating') 16 17 def talk(self): 18 print('talking') 19 20 def sleep(self): 21 print('sleeping') 22 #通过类得到对象p1 类名+()就是 在实例化对象 23 p1=Chinese('alex',11,'pink') #_init_(p1,'alxe',11,'pink') 实例化 得到一个p1的个人特征信息 24 p2=Chinese('egon',12,'black') #_init_(p2,'egon',12,'black') 实例化 得到一个p2的个人特征信息
1 print(p1) #<__main__.Chinese object at 0x000001D6D65CD358> 2 print(p1.name) #alex 打印实例化对象的name的值 3 print(p1.age) #11 打印实例化对象age的值 4 print(p1.color) #pink 打印实例化对象color的值, 5 print(Chinese.__dict__) #打印出一个字典, 6 print(Chinese.__name__) #Chinese 7 print(Chinese.__doc__) #None 8 print(Chinese.__bases__) #(<class 'object'>,) 9 print(Chinese.__class__) #<class 'type'> 10 print(p1.__class__) #<class '__main__.Chinese'>
类名加括号就是实例化,会自动触发__init__函数的运行,可以用它来为每个实例定制自己的特征
实例化:类名+括号
self的作用是在实例化时自动将对象/实例本身传给__init__的第一个参数,self可以是任意名字,但是瞎几把写别人就看不懂了。
总结:
对象.数据属性--》 数据属性的值 print(s1.school) #偶的博爱
类.数据属性--》类的属性值 print(Student.school) #偶的博爱
对象.变量名--》对象的值 print(s1.name) #gu
print(s1.__dict__) #{'name': 'gu', 'age': 19}
1 class Student: 2 school='偶的博爱' 3 l=[] 4 def __init__(self,name,age): 5 self.name=name 6 self.age=age 7 self.l.append(self) 8 def study(self): 9 print('studying') 10 11 def walk(self): 12 print('walking') 13 14 s1=Student('gu',19) 15 s2=Student('fu',33) 16 17 #对象本身只有数据类型,但是可以访问类的方法(函数) 18 print(Student) #<class '__main__.Student'> 类的内存地址 19 20 print(s1) #<__main__.Student object at 0x0000029749E450F0>对象的内存地址 21 print(s2) #<__main__.Student object at 0x0000029749E45128>对象的内存地址 22 23 print(s1.name) #gu 24 print(s1.age) #19 25 26 print(s1.__dict__) #{'name': 'gu', 'age': 19} 27 print(s2.__dict__) #{'name': 'fu', 'age': 33} 28 29 print(s1.name,s1.age) #gu 19 30 print(s2.name,s2.age) #fu 33 31 32 print(s1.__dict__['age']) #19 通过字典的键得到值 33 34 print(s1.school,id(s1.school)) #偶的博爱 2688844734264 对象s1的数据属性 35 print(s2.school,id(s2.school)) #偶的博爱 1717227462456 对象s2的数据属性 36 37 print(Student.school) #偶的博爱 类的数据属性 38 39 print(s1.school) #偶的博爱 ,school是对的数据属性,调用对象的数据属性 40 41 s1.school='oldboy' 42 print(s1.school,id(s1.school)) #oldboy 1267820306360 # 43 print(Student.school,id(Student.school)) #偶的博爱 1267788259128 类本身的数据属性没有改变 44 print(s2.school,id(Student.school)) #偶的博爱 1267788259128 对象2的数据属性也没有改变 45 46 Student.school='OLDBOY' 47 print(Student.school) #OLDBOY 48 print(s1.school) #oldboy 49 print(s2.school) #OLDBOY
####注意!!
1 s1.school='oldboy' #对象 s1 是在自己的内存空间里定义了一个school变量,值为oldboy,与student类里的school没有任何关系,只是变量名重名而已 2 print(s1.school,s1.__dict__) #oldboy {'name': 'gu', 'age': 19, 'school': 'oldboy'} 3 print(Student.school,Student.__dict__) # 偶的博爱 {'__module__': '__main__', 'school': '偶的博爱',
#student类里的变量值不受影响,除非student自己修改 Student.school='OLDBOY'
print(s1.walk()) #对象调用方法属性 print(s2.study()) #对象调用方法属性
s1