虚拟机搭建gfs系统
系统环境:CentOS release 5.5 – 2.6.18-194.el5
gfs节点1:192.168.1.231 gfs1
gfs节点2:192.168.1.232 gfs2
gfs节点3:192.168.1.233 gfs3
iscsi-target存储设备:192.168.1.240 iscsi-storage (IP对应主机名)
GFS 简要说明,它有两种:
1. Google文件系统:GFS是GOOGLE实现的是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,但可以提供容错功能。它可以给大量的用户提供总体性能较高的服务。欲了解更多,可以访问:http://www.codechina.org/doc/google/gfs-paper/introduction.html
2. Redhat 的GFS(Global File System)
GFS(Global File System)自己以本地文件系统的形式出现。多个Linux机器通过网络共享存储设备,每一台机器都可以将网络共享磁盘看作是本地磁盘,如果某台机器对 某个文件执行了写操作,则后来访问此文件的机器就会读到写以后的结果。可以根据对性能或是可扩展性,或者以经济性多个原则进行不同方案的部署。
GFS 主要组件,集群卷管理,锁管理,集群管理,围栏和恢复,集群配置管理。
本文主要介绍Redhat的GFS系统。
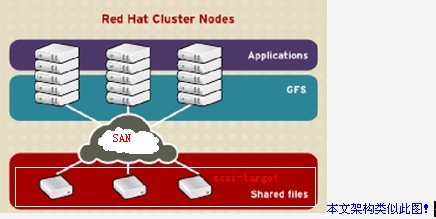
REDHAT CLUSTER SUITEWITH GFS :
RHCS(REDHAT CLUSTER SUITE)是一款能够提供高性能、高可靠性、负载均衡、高可用性的集群工具集,一个集群通常有两个或两个以上的计算机(称为“节点”或”成员“)共同执行一个任务。
RHCS主要组件:
· 集群架构:
提供一个基本功能使节点作为集群工作在一起:配置文件管理,成员关系管理,锁管理和栅设备。
· 高可用**管理:
提供节点失败转移服务,当一个节点失败后将服务转移到另一个节点上。
·集群管理工具:
通过配置和管理工具来配置和管理Red Hat集群。
· Linux Virtual Server (LVS)
LVS提供一个基于IP的负载均衡功能,通过LVS可以将客户请求均匀的分配到集群节点上。
其它Red Hat集群组件:
· Cluster Logical Volume Manager (CLVM)
提供逻辑卷管理集群存储。
· 集群管理器:
CMAN是一个分布式集群管理器(DLM),它运行在每一个集群节点上,CMAN通过监视集群节点提供一个法定节点数(quorum),当集群 中有多于一半的节点处于活跃状态时,此时符合法定节点数,集群继续可用,当只有有一半或少于一半的节点处于活跃状态是则已达到不到法定节点数,此时整个集 群变得不可用。CMAN通过监控集群中节点来确定各节点的成员关系,当集群中的成员关系发生改变,CMAN会通架构中其它组件来进行相应的调整。
· DLM锁管理:
分布式锁管理器,它运行在所有的集群节点上,锁管理是一个公共的基础结构,为集群提供一种共享集群资源的管理机制,GFS通过锁管理器使用锁机制来同步访问文件系统元数据,CLVM通过锁管理器来同步更新数据到LVM卷和卷组。
· 数据的完整保证:
RHCS 通过 Fence设备从共享存储切断失效节点的I/O以保证数据的完整性。当CMAN确定一个节点失败后,它在集群结构中通告这个失败的节点(组播),fenced进程会将失败的节点隔离,以保证失败节点不破坏共享数据。
REDHAT集群配置系统:
集群配置文件:(/etc/cluster/cluster.conf) 是一个XML文件,用来描述下面的集群特性:
集群名称:列出集群名称、集群配置文件版本和一个隔离时间,隔离相应时间当一个新节点加入或从集群中隔离时。
集群:列出集群中的每一个节点,指定节点名称,节点ID,法定投票数,和栅模式。
fence设备:定义fence设备。
管理资源:定义创建集群服务需要的资源。管理资源包括失败转移域,资源和服务。
iscsi的initiator与target简要说明:
iSCSI(Internet SCSI)是2003年IETF(InternetEngineering Task Force,互联网工程任务组)制订的一项标准,这种指令集合可以实现在IP网络上运行SCSI协议,使其能够在诸如高速千兆以太网上进行路由选择。 SCSI(Small Computer System Interface)是块数据传输协议,在存储行业广泛应用,是存储设备最基本的标准协议。iSCSI协议是一种利用IP网络来传输潜伏时间短的SCSI 数据块的方法,iSCSI使用以太网协议传送SCSI命令、响应和数据。iSCSI可以用我们已经熟悉和每天都在使用的以太网来构建IP存储局域网。通过 这种方法,iSCSI克服了直接连接存储的局限性,使我们可以跨不同服务器共享存储资源,并可以在不停机状态下扩充存储容量。
iSCSI的工作过程:当iSCSI主机应用程序发出数据读写请求后,操作系统会生成一个相应的SCSI命令,该SCSI命令在iSCSI Initiator层被封装成iSCSI消息包并通过TCP/IP传送到设备侧,设备侧的iSCSI Target层会解开iSCSI消息包,得到SCSI命令的内容,然后传送给SCSI设备执行;设备执行SCSI命令后的响应,在经过设备侧iSCSI Target层时被封装成iSCSI响应PDU,通过TCP/IP网络传送给主机的iSCSI Initiator层,iSCS Initiator会从iSCSI响应PDU里解析出SCSI响应并传送给操作系统,操作系统再响应给应用程序。要实现iSCSI读写,除了使用特定硬设 备外,也可透过软件方式,将服务器仿真为iSCSI的发起端(Initiator)或目标端(target),利用既有的处理器与普通的以太网络卡资源实现iSCSI的连接。
本文均已软件方式在Centos5.5虚拟机上实现gfs功能!
一、在192.168.1.240上安装iscsi的target端:
[root@iscsi-storage ~]#yum install scsi-target-utils (注意:scsi前面没有字母i)
(使用centos默认的yum源,将会安装软件scsi-target-utils-0.0-6.20091205snap.el5_5.3)
[root@iscsi-storage ~]#yum install libibverbs-devel libibverbs librdmacm librdmacm-devel
如果没有安装以上软件,则/var/log/messages里将会有以下报错:
iscsi-storage tgtd: libibverbs.so: cannot open shared object file: No such file or
directory – iser transport not used
iscsi-storage tgtd:librdmacm.so: cannot open shared object file: No such file or directory – iser
transport not used
磁盘sda装着系统,磁盘sdb用来存储,对其进行分区。
[root@iscsi-storage ~]# fdisk /dev/sdb
本人分成/dev/sdb1 3G , /dev/sdb2 7G.
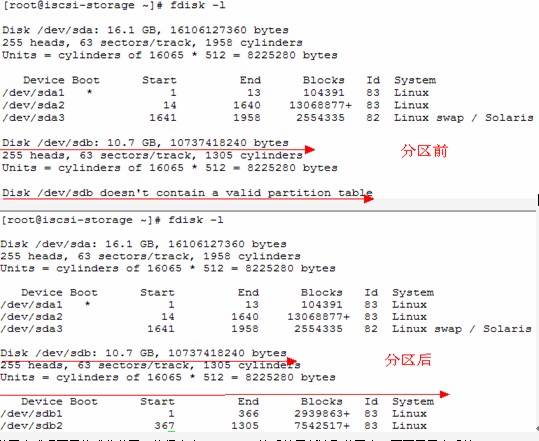
分区完成后不用格式化分区,执行命令partprobe让系统重新读取分区表,而不用重启系统。
[root@iscsi-storage ~]# partprobe
scsi-targe-utils装完后的服务名为tgtd,启动它,并设置为开机启动。
[root@iscsi-storage ~]# service tgtd start
Starting SCSI target daemon: Starting target framework daemon
[root@iscsi-storage ~]# chkconfig tgtd on
接下来建立target device. 在centos5中使用tgtadm指令来设置而不是4当中的 vi /etc/ietd.conf.
tgtadm命令的参数有点难记,但是scsi-target-utils套件中包含了利用tgtadm指令建立target device的步骤,我们可以参照文件来设置:/usr/share/doc/scsi-target-utils-0.0/README.iscsi
本人欲新增iqn名为iqn.2011-01.com.chinaitv:rhcs-storage的target device.
=====================================================================================
iqn (iSCSI Qualified Name)格式通常如下:
格式
意义
范例
yyyy-mm
年份-月份
2011-01
reversed domain name
把域名名称反过来写,通常把公司的域名反过来写
com.chinaitv
identifier
识别字,通常注明这个存储空间的用途
rhcs-storage
=====================================================================================
新增target device命令如下:
# tgtadm --lld iscsi --op new --mode target --tid 1 -T iqn.2011-01.com.chinaitv:rhcs-storage
执行后,利用如下命令来查看target device:
#tgtadm --lld iscsi --op show --mode target

将起初新建的分区加入target device。
# tgtadm --lld iscsi --op new --mode logicalunit --tid 1 -lun 1 -b /dev/sdb1
查看加入target device后的输出内容:
# tgtadm --lld iscsi --op show --mode target
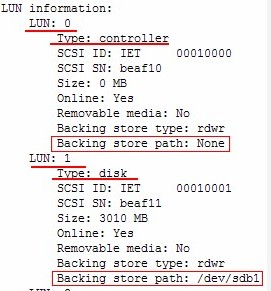
设置可以访问存取此target device的initiator节点。本机允许gfs1 gfs2 gfs3存取,设置如下:
#tgtadm --lld iscsi --op bind --mode target --tid 1 -I 192.168.1.231
#tgtadm --lld iscsi --op bind --mode target --tid 1 -I 192.168.1.232
#tgtadm --lld iscsi --op bind --mode target --tid 1 -I 192.168.1.233 (I为大写的i)
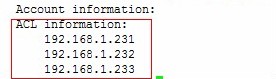
(如果允许所有的initiators存取的话,可以将ip换成ALL,如下:
#tgtadm --lld iscsi --op bind --mode target --tid 1 -I ALL
如果需要移除则需将bind换成unbind即可,例如
#tgtadm --lld iscsi --op unbind --mode target --tid 1 -I 192.168.1.233)
本次操作只使用sdb1来试验存储,因此只加入sdb1,如果需将多个分区用来存储的话可以如下操作:
tgtadm --lld iscsi --op new --mode target --tid 1 -T iqn.2011-01.com.chinaitv:rhcs-storage
tgtadm --lld iscsi --op new --mode target --tid 2 -T iqn.2011-01.com.chinaitv:rhcs-storage2
tgtadm --lld iscsi --op new --mode logicalunit --tid 1 -lun 1 -b /dev/sdb1
tgtadm --lld iscsi --op new --mode logicalunit --tid 2 -lun 1 -b /dev/sdb2
tgtadm --lld iscsi --op bind --mode target --tid 1 -I ip
tgtadm --lld iscsi --op bind --mode target --tid 2 -I ip
注意:如果重启tgtd服务的话,上面配置全部将会消失,因此不要随便重启,否则需要重新按上面步骤配置,为了在下一次开机自动运行,可以把上面的命令添加到/etc/rc.local文件里面。
首先在三个节点机hosts文件末尾添加以下内容: 上的
#vi /etc/hosts

二、安装iscsi-initiator-utils,在节点机上安装
#yum install iscsi-initiator-utils
安装需要的软件包
[root@gfs1 ~]# yum install -y cman gfs-utils kmod-gfs kmod-dlm cluster-snmp lvm2-cluster rgmanager
指定initiator alias name
#echo "InitiatorAlias=gfs1" >> /etc/iscsi/initiatorname.iscsi
创建cluster.conf配置文件,安装完成后并没有此文件,需自己创建:
#vi /etc/cluster/cluster.conf
<?xml version="1.0"?>
<cluster name="GFSCluster" config_version="1">
##这一行定义了cluster的名称,其中config_version是表示该配置文件被配置的次数
##(在RedHat Cluster中,各个节点是同配置版本数值也就是配置次数最高的配置文件进行学习同步报)
<clusternodes>
<clusternode name="gfs1" votes="1" nodeid="1">
##这一行定义了cluster节点的名称,节点id以及投票权,节点名一般就是节点的主机名
<fence>
<method name="single">
<device name="node1" nodename="gfs1"/>
</method>
</fence>
</clusternode>
<clusternode name="gfs2" votes="1" nodeid="2">
<fence>
<method name="single">
<device name="node2" nodename="gfs2"/>
</method>
</fence>
</clusternode>
<clusternode name="gfs3" votes="1" nodeid="3">
<fence>
<method name="single">
<device name="node3" nodename="gfs3"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice name="node1" agent="fence_manual"/>
<fencedevice name="node2" agent="fence_manual"/>
<fencedevice name="node3" agent="fence_manual"/>
</fencedevices>
<rm>
<failoverdomains/>
<resources/>
</rm>
</cluster>
(fence也是RedHat Cluster的产物,没有它GFS也没法工作,fence的作用就是当一个节点宕掉(和cluster断掉联系)后,其他的正常节点会通过fence设 备来把宕掉的设备fence掉,把宕掉的设备踢出cluster保证整个cluster的正常运行,而fence设备一般是服务器自带硬件设备,如hp的 ilo口,IBM和dell的ipmi等等,由于服务器硬件的不同,导致不同的fence设备的配置方法不同,我这里为虚拟机没有fence设备,因此采 用fence_manual的方法来手工设置,手工fence的功能是:当一个节点宕掉后我们需要在正常的节点上输入命令:“# fence_ack_manual -n 宕掉的节点名 ” 来把cluster的主机隔离掉,才能让正常的节点正常工作。现在本人对cluster.conf了解的也并不是非常的熟悉,故不能给出更详细的解答,不 过可以输入命令:man 5 cluster.conf查看帮助文件。在各个节点机上都需创建此cluster.conf文件。)
(注:配置文件并不是非常的标准,自己根据需要还可以添加更多的内容与修改,这里只是一个简单的例子)
启动iscsi daemon
#service iscsi start
#chkconfig iscsi on
利用iscsiadm命令探测iscsi device:
# iscsiadm -m discovery -t sendtargets -p 192.168.1.240:3260
192.168.1.240:3260,1 iqn.2011-01.com.chinaitv:rhcs-storage
登入iscsi target
#iscsiadm -m node -T iqn.2011-01.com.chinaitv:rhcs-storage -p 192.168.1.240:3260 -l
Logging in to [iface: default, target: iqn.2011-01.com.chinaitv:rhcs-storage, portal: 192.168.1.240,3260]
Login to [iface: default, target: iqn.2011-01.com.chinaitv:rhcs-storage, portal: 192.168.1.240,3260]: successful
登入成功后,利用fdisk -l可以发现多处两个硬盘分区。

(若想退出则使用:iscsiadm -m node -T iqn.2011-01.com.chinaitv:rhcs-storage -p 192.168.1.240:3260 -u)
在该节点上创建一个名为gfsvg的 LVM 卷组
#pvcreate -ff /dev/sdb
#vgcreate gfsvg /dev/sdb
列出VG大小:
#vgdisplay gfsvg |grep “Total PE “
Total PE 717
创建lv
# lvcreate -l 717 -n gfs gfsvg
Logical volume “gfs” created
# cman_tool status | grep “Cluster Name”
cman_tool: Cannot open connection to cman, is it running ?
原因是没有启动服务,启动服务:
# service cman start
在该节点上创建一个GFS卷,格式化GFS 文件系统,通过命令:
gfs_mkfs -p lock_dlm -t ClusterName:FSName -j Number BlockDevice
格式化gfs文件格式:
-p 这个参数后边跟的是gfs锁机制,一般情况下就用lock_dlm
-t 后边是ClusterName:FSName
其中ClusterName是cluster名,就是cluster.conf配置文件中指定的cluster名,FSName是给新格式化好的gfs分区的名字
-j 代表是journal的个数,一般情况是2个除非一些特殊情况否则不用再单作调整
BlockDevice 就是要被格式化的设备名称。
下面是一个格式化GFS命令的实例:
#gfs_mkfs -p lock_dlm -t GFSCluster:gfs -j 3 /dev/gfsvg/gfs

载入相应的gfs模块,并查看lv是否成功
# modprobe gfs
# modprobe gfs2
# chkconfig gfs on
# chkconfig gfs2 on
# chkconfig clvmd on
# /etc/init.d/gfs restart
# /etc/init.d/gfs2 restart
# /etc/init.d/clvmd restart
# lvscan
ACTIVE ‘/dev/gfsvg/gfs’ [2.80 GB] inherit ##表示成功
把新建的逻辑磁盘挂载到本地:
#mount -t gfs /dev/gfsvg/gfs /opt
#df -h
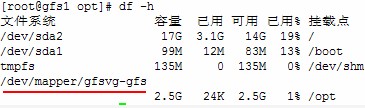
进入/opt目录,建立新文件(之后到新节点上挂载,以作验证是否gfs创建并挂载成功)
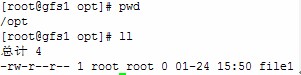
到gfs2节点和gfs3节点上分别执行以下操作
# modprobe gfs
# modprobe gfs2
# /etc/init.d/gfs restart
# /etc/init.d/gfs2 restart
# /etc/init.d/clvmd restart
#chkconfig –add cman
#chkconfig –add clvmd
#chkconfig –add gfs
#chkconfig –level 35 cman on
#chkconfig –level 35 clvmd on
#chkconfig –level 35 gfs on
# lvscan
#mount /dev/gfsvg/gfs /opt
进入/opt目录查看是否有之前在gfs1上建立的文件file1
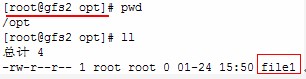
如图所示成功,可以在/opt目录里进行任何操作,三台机器将会保持一致,这样就达到了在一台机器上操作,其他机器保持同步的目的,用来提高可用性,当gfs1出了问题后,gfs2和gfs3同样可以用来提供服务!可以在各节点机器上执行命令clustat来查看gfs集群各节点的活动状态:

同样可以执行以下命令来检查是否连接成功
# ccs_test connect
Connect successful.
Connection descriptor = 9600
检查一下是否正常
#ccs_tool lsnode
#ccs_tool lsfence
#cman_tool services
注:在gfs2和gfs3节点上必须启动clvmd服务,不然无法挂载/dev/gfsvg/gfs设备。
如果要在存储服务器上即本实验的iscsi-storage 上,如果有外部节点连接着此存储,要想停止tgtd(service tgtd stop)服务, 有如下提示:
Stopping SCSI target daemon: Stopping target framework daemon
Some initiators are still connected – could not stop tgtd
表示无法停止,而采取杀掉tgtd的pid的方法来停止时,在此用service tgtd start来启动tgtd服务的时候,有如下的提示:

实际上tgtd并没有启动成功,用ps查看是查看不到tgtd服务进程的,要想解决此问题,是因为有个/var/lock/subsys/tgtd文件存在,只需删除掉即可。
# rm /var/lock/subsys/tgtd

在节点机上,如果想开机自动挂载则修改/etc/fstab文件,加入以下内容:
/dev/mapper/gfsvg-gfs /opt gfs defaults 0 0
本人在虚拟机上部署此gfs集群存储的时候,碰到很多问题,在查阅各种资料后才得以实现虚拟机上的gfs,也花费了很长的时间,其中就有很多的报错,举个例子:
Jan 19 04:04:00 gfs1 ccsd[19610]: Cluster is not quorate. Refusing connection.
Jan 19 04:04:00 gfs1 ccsd[19610]: Error while processing connect: Connection refused
Jan 19 04:04:01 gfs1 dlm_controld[18685]: connect to ccs error -111, check ccsd or cluster status
此报错跟fence的启动有关系,这是因为我 在第一个节点上启动cman的时候fencing无法启动,原因在于要开启fence功能,必须多个机器节点都开启了,单独开启一个的时候他是不生效的, 也就是说必须有一半的fence都开启了才能生效,因此需在多台节点上执行service cman start 这样才能够快速的解决fenc的启动问题。
最后疑问:
1 查看target的状态总是ready而不能得到running状态

2 在输入tgtd命令时总是有以下报错:
[root@iscsi-storage ~]# tgtd
librdmacm: couldn’t read ABI version.
librdmacm: assuming: 4
CMA: unable to get RDMA device list ##注,是虚拟机故没有rdma设备,下面socket就有点不理解
(null): iscsi_rdma_init(1217) cannot initialize RDMA; load kernel modules?
(null): iscsi_tcp_init(222) unable to bind server socket, Address already in use
(null): iscsi_tcp_init(222) unable to bind server socket, Address already in use
No available low level driver!
本文只是写了个大概的框架,并非很完整,还有待完善,如朋友有更好的更改意见欢迎提出指正。这也是本人第一次接触red hat cluster suite的gfs系统,并把操作的经过记录于此,方便大家与自己。
完毕!
欢迎大家拍砖–本人真诚的希望您能够提出宝贵的意见,最好是能够说出文章中的不足和错误之处,谢谢!!!
文章资源转载来自:http://suceo.sinaapp.com
