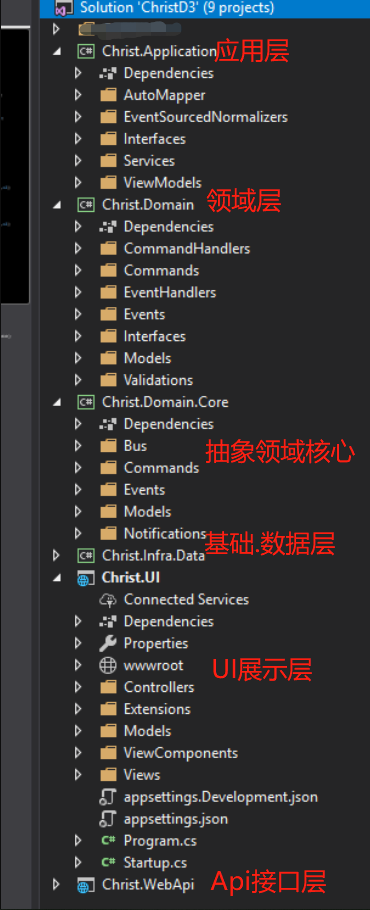
从壹开始微服务 [ DDD ] 之四 ║让你明白DDD的小故事 & EFCore初探
正文
缘起
哈喽大家好哟,今天又到了老张的周二四放送时间了,当然中间还有不定期的更新(因为个人看papi酱看多了),这个主要是针对小伙伴提出的问题和优秀解决方案而写的,经过上周两篇DDD领域驱动设计的试水,我发现一个问题,这个DDD的水是真的深啊~或者来说就是这个思想的转变是不舒服的,好多小伙伴就说有点儿转不过来,当然我也是,一直站在原地追着影子跑,当然这个系列我会一直坚持下去的,大家如果感觉我写的没有误人子弟或者感觉看着还有点儿意思,请不要着急,多多评论,我虽然没有更新,但是也一直在线,提出来的问题可以一起讨论,周末的时候,我又和“李大爷”一起从非专业的角度,从领域专家的角度思考了下DDD领域驱动设计的思想,感觉还有点儿领悟的,这里给大家分享下,如果你现在还对为什么使用DDD,或者还有DDD就像是一个三层架构或者MVC架构的想法的话,看完这一篇应该就能稍微的明白了。
很开森的是上周的问题大家评论很好,也上了24小时评论榜单,希望大家都可以多评论评论,真的很精彩,大家可以再去看看《二 ║ DDD入门 & 项目结构粗搭建》,评论席的内容的含金量,甚至都超过了我的正文内容,而且也能满足老张小小的虚荣感,今天呢,我就先在本文的上半篇重点说一下大家最最最热心的两个问题,然后再继续推进咱们的项目代码,就主要从以下三个大块铺开来说:
1、DDD的意义到底在哪里?为什么很难理解?
2、为什么要使用仓储,EFCore不就是一个仓储么?
3、限界上下文如何定义呢?包含了平时遇到的哪些东西?
悄悄说:经过周末的讨论,我发现上次咱们新建的那个关于 Customer 领域对象不好举例子,问答程序说起来也不是很顺口,所以我已经修改成了 Student 模型,然后我也想到了一个领域——教务系统,这个大家一定是熟悉的不能再熟悉了,每个小伙伴都是经过上学的噩梦里过来的(哈哈学霸就另说了),以后咱们就用这个教务领域来展开说明,大家也能都在一条思路上,而且也不会花心思去考虑问答系统这个不熟悉的领域。
零、今天要完成紫色的部分
一、举一个DDD的小栗子 —— 大意义
关于DDD的使用,网上已经有很多的栗子了,无论是各种粘贴复制的教科书,还是自我的一些心得,基本已经说完了,不过我每次读的时候,心里都是有点儿抗拒,一直都没办法看懂,今天我就决定用另一个办法,来和大家好好说一下这个DDD领域驱动设计的意义到底在哪里。这个时候请你自己先想一想,如果使用DDD会有哪些好处,如果说看完了我写的,感觉有共鸣,那很不错,要是感觉我写的认为不对,欢迎评论席留下你的意见哟,开源嘛,不能让我自己发表看法的,也让我的博客可以多在大家的面前展现下哈哈。
故事就从这里开始:咱们有一个学校,就叫从壹大学(我瞎起的名字哈哈),我们从壹大学要开发一套教务系统,这个系统涵盖了学校的方方面面,从德智体美劳都有,其中就有一个管理后台,任何人都可以登陆进去,学习查看自己的信息和成绩等,老师可以选择课程或者修改自己班级的学生的个人信息的,现在就说其中的一个小栗子 —— 班主任更改学生的手机号。我们就用普通的写法,就是我们平时在写或者现在在用的流程来设计这个小方法。
请注意:当前系统就是一个 领域,里边会有很多 子领域,这个大家应该都能动。
1、后台管理,修改学生的手机号
这个方法逻辑很简单,就是把学生的手机号更新一下就行,平时咱们一定是咣咣把数据库建好,然后新建实体类,然后就开始写这样的一批方法了,话不多说,直接看看怎么写(这是伪代码):

/// <summary>
/// 后台修改学生手机号方法
/// </summary>
/// <param name="NewPhoNumber"></param>
/// <param name="StudentId"></param>
/// <param name="TeacherId"></param>
public void UpdateStudentPhone(string NewPhoNumber,int StudentId,int TeacherId)
{
//核心1:连数据,获取学生信息,然后做修改,再保存数据库。
}
这个方法特别正确,而且是核心算法,简单来看,已经满足我们的需求了,但是却不是完整的,为什么呢,因为只要是管理系统涉及到的一定是有权限问题,然后我们就很开始和DBA讨论增加权限功能。
请注意:这里说到的修改手机号的方法,就是我们之后要说到的领域事件,学生就是我们的领域模型,当然这里边还有聚合根,值对象等等,都从这些概念中提炼出来。
2、为我们的系统增加一个刚需
刚需就是指必须使用到的一些功能,是仅此于核心功能的下一等级,如果按照我们之前的方法,我们就很自然的修改了下我们的方法。
故事:领导说,上边的方法好是好,但是必须增加一个功能强大的权限系统,不仅能学生自己登陆修改,还可以老师,教务处等等多方修改,还不能冲突,嗯。
/// <summary>
/// 后台修改学生手机号方法
/// </summary>
/// <param name="NewPhoNumber"></param>
/// <param name="StudentId"></param>
/// <param name="TeacherId"></param>
public void UpdateStudentPhone(string NewPhoNumber,int StudentId,int TeacherId)
{
//重要2:首先要判断当然 Teacher 是否有权限(比如只有班主任可以修改本班)
//注意这个时候已经把 Teacher 这个对象,给悄悄的引进来了。
//------------------------------------------------------------
//核心:连数据,获取学生信息,然后做修改,再保存数据库。
}
这个时候你一定会说我们可以使用JWT这种呀,当然你说的对,是因为咱们上一个系列里说到这个了,这个也有设计思想在里边,今天咱们就暂时先用平时咱们用到的上边这个方法,集成到一起来说明,只不过这个时候我们发现我们的的领域里,不仅仅多了 Teacher 这个其他模型,而且还多了与主方法无关,或者说不是核心的事件。
这个时候,我们在某些特定的方法里,已经完成权限,我们很开心,然后交给学校验收,发现很好,然后就上线了,故事的第一篇就这么结束了,你会想,难道还有第二篇么,没错!事务总是源源不断的的进来的,请耐心往下看。
请注意:这个权限问题就是 切面AOP 编程问题,以前已经说到了,这个时候你能想到JWT,说明很不错了,当然还可以用Id4等。
3、给系统增加一个事件痕迹存储
这个不知道你是否能明白,这个说白了就是操作日志,当然你可以和错误日志呀,接口访问日志一起联想,我感觉也是可以的,不过我更喜欢把它放在事件上,而不是日志这种数据上。
故事:经过一年的使用,系统安静平稳,没有bug,一起正常,但是有一天,学生小李自己换了一个手机号,然后就去系统修改,竟然发现自己的个人信息已经被修改了(是班主任改的),小李很神奇这件事,然后就去查,当然是没有记录的,这个时候反馈给技术部门,领导结合着其他同学的意见,决定增加一个痕迹历史记录页,将痕迹跟踪提上了日程。我们就这么开发了。
/// <summary>
/// 后台修改学生手机号方法
/// </summary>
/// <param name="NewPhoNumber"></param>
/// <param name="StudentId"></param>
/// <param name="TeacherId"></param>
public void UpdateStudentPhone(string NewPhoNumber,int StudentId,int TeacherId)
{
//重要:首先要判断当然 Teacher 是否有权限(比如只有班主任可以修改本班)
//注意这个时候已经把 Teacher 这个对象,给悄悄的引进来了。
//------------------------------------------------------------
//核心:连数据,或者学生信息,然后做修改,再保存数据库。
//------------------------------------------------------------
//协同3:痕迹跟踪(你可以叫操作日志),获取当然用户信息,和老师信息,连同更新前后的信息,一起保存到数据库,甚至是不同的数据库地址。
//注意,这个是一个突发的,项目上线后的需求
}
这个时候你可能会说,这个项目太假了,不会发生这样的事情,这些问题都应该在项目开发的时候讨论出来,并解决掉,真的是这样的么,这样的事情多么常见呀,我们平时开发的时候,就算是一个特别成熟的领域,也会在项目上线后,增加删除很多东西,这个只是一个个例,大家联想下平时的工作即可。
这个时候如果我们还采用这个方法,你会发现要修改很多地方,如果说我们只有几十个方法还行,我们就粘贴复制十分钟就行,但是我们项目有十几个用户故事,每一个故事又有十几个到几十个不等的用例流,你想想,如果我们继续保持这个架构,我们到底应该怎么开发,可能你会想到,还有权限管理的那个AOP思想,写一个切面,可是真的可行么,我们现在不仅仅要获取数据前和数据后两块,还有用户等信息,切面我感觉是很有困难的,当然你也好好思考思考。
这个时候你会发现,咱们平时开发的普通的框架已经支撑不住了,或者是已经很困难了,一套系统改起来已经过去很久了,而且不一定都会修改正确,如果一个地方出错,当前方法就受影响,一致性更别说了,试想下,如果我们开发一个在线答题系统,就因为记录下日志或者什么的,导致结果没有保存好,学生是会疯的。第二篇就这么结束了,也许你的耐心已经消磨一半了,也许我们以为一起安静的时候,第三个故事又开始了。
请注意:这个事件痕迹记录就涉及到了 事件驱动 和 事件源 相关问题,以后会说到。
4、再增加一个站内通知业务
故事:我们从壹大学新换了一个PM,嗯,在数据安全性,原子性的同时,更注重大家信息的一致性 —— 任何人修改都需要给当前操作人,被操作人,管理员或者教务处发站内消息通知,这个时候你会崩溃到哭的。
/// <summary>
/// 后台修改学生手机号方法
/// </summary>
/// <param name="NewPhoNumber"></param>
/// <param name="StudentId"></param>
/// <param name="TeacherId"></param>
public void UpdateStudentPhone(string NewPhoNumber,int StudentId,int TeacherId)
{
//重要:首先要判断当然 Teacher 是否有权限(比如只有班主任可以修改本班)
//注意这个时候已经把 Teacher 这个对象,给悄悄的引进来了。
//------------------------------------------------------------
//核心:连数据,或者学生信息,然后做修改,再保存数据库。
//------------------------------------------------------------
//协同:痕迹跟踪(你可以叫操作日志),获取当然用户信息,和老师信息,连同更新前后的信息,一起保存到数据库,甚至是不同的数据库地址。
//注意,这个是一个突发的,项目上线后的需求
//------------------------------------------------------------
//协同4:消息通知,把消息同时发给指定的所有人。
}
这个时候我就不具体说了,相信都已经离职了吧,可是这种情况就是每天都在发生。
请注意:上边咱们这个伪代码所写的,就是DDD的 通用领域语言,也可以叫 战略设计。
5、DDD领域驱动设计就能很好的解决
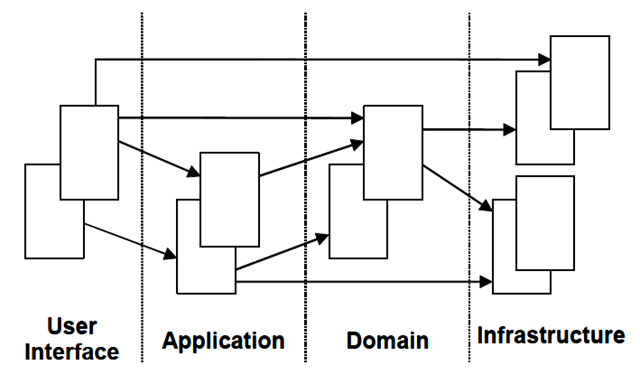
上边的这个问题不知道是否能让你了解下软件开发中的痛点在哪里,二十年前 Eric Evans 就发现了,并提出了领域驱动设计的思想,就是通过将一个领域进行划分成不同的子领域,各个子领域之间通过限界上下文进行分隔,在每一个限界上下文中,有领域模型,领域事件,聚合,值对象等等,各个上下文互不冲突,互有联系,保证内部的一致性,这些以后会说到。
如果你对上下文不是很明白,你可以暂时把它理解成子领域,领域的概念是从战略设计来说的,上下文这些是从战术设计上来说的。
具体的请参考我的上一篇文章《三 ║ 简单说说:领域、子域、限界上下文》
你也许会问,那我们如何通过DDD领域驱动设计来写上边的修改手机号这个方法呢,这里简单画一下,只是说一个大概意思,切分领域以后,每一个领域之间互不联系,有效的避免了牵一发而动全身的问题,而且我们可以很方便进行扩展,自定义扩展上下文,当然如果你想在教学子领域下新增一个年级表,那就不用新建上下文了,直接在改学习上下文中操作即可,具体的代码如何实现,咱们以后会慢慢说到。

总结:这个时候你通过上边的这个栗子,不知道你是否明白了,我们为什么要在大型的项目中,使用DDD领域设计,并配合这CQRS和事件驱动架构来搭建项目了,它所解决的就是我们在上边的小故事中提到的随着业务的发展,困难值呈现指数增长的趋势了。
二、一个安静的数据管理员 —— 仓储
这里就简单的说两句为什么一直要使用仓储,而不直接接通到 EFCore 上:
1、我们驱动设计的核心是什么,就是最大化的解决项目中出现的痛点,上边的小故事就是一个栗子,随着技术的更新,面向接口开发同时也变的特别重要,无论是方便重构,还是方便IoC,依赖注入等等,都需要一个仓储接口来实现这个目的。
2、仓储还有一个重要的特征就是分为仓储定义部分和仓储实现部分,在领域模型中我们定义仓储的接口,而在基础设施层实现具体的仓储。
这样做的原因是:由于仓储背后的实现都是在和数据库打交道,但是我们又不希望客户(如应用层)把重点放在如何从数据库获取数据的问题上,因为这样做会导致客户(应用层)代码很混乱,很可能会因此而忽略了领域模型的存在。所以我们需要提供一个简单明了的接口,供客户使用,确保客户能以最简单的方式获取领域对象,从而可以让它专心的不会被什么数据访问代码打扰的情况下协调领域对象完成业务逻辑。这种通过接口来隔离封装变化的做法其实很常见,我们需要什么数据直接拿就行了,而不去管具体的操作逻辑。
3、由于客户面对的是抽象的接口并不是具体的实现,所以我们可以随时替换仓储的真实实现,这很有助于我们做单元测试。
总结:现在随着开发,越来越发现接口的好处,不仅仅是一个持久化层需要一层接口,小到一个缓存类,或者日志类,我们都需要一个接口的实现,就比如现在我就很喜欢用依赖注入的方式来开发,这样可以极大的减少依赖,还有增大代码的可读性。
三、建立我们第一个限界上下文
限界上下文已经说的很明白了,是从战术技术上来解释说明战略中的领域概念,你想一下,我们如何在代码中直接体现领域的概念?当然没办法,领域是一个通过语言,领域专家和技术人员都能看懂的一套逻辑,而代码中的上下文才是实实在在的通过技术来实现。
大家可以在回头看看上边的那个故事栗子,下边都一个“请注意”三个字,里边就是我们上下文中所包含的部分内容,其实限界上下文并没有想象中的那么复杂,我们只需要理解成是一个虚拟的边界,把不属于这个子领域的内容踢出去,对外解耦,但是内部通过聚合的。
0、在基础设施层下新建一个 appsetting.json 配置文件
用于我们的特定的数据库连接,当然我们可以公用 api 层的配置文件,这里单独拿出来,用于配合着下边的EFCore,进行注册。
{
"ConnectionStrings": {
"DefaultConnection": "server=.;uid=sa;pwd=123;database=EDU"
},
"Logging": {
"IncludeScopes": false,
"LogLevel": {
"Default": "Debug",
"System": "Information",
"Microsoft": "Information"
}
}
}
1、新建系统核心上下文
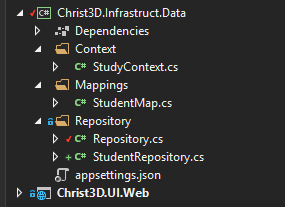
在Christ3D.Infrastruct.Data 基础设施数据层新建 Context 文件夹,以后在基础设施层的上下文都在这里新建,比如事件存储上下文(上文中存储事件痕迹的子领域),
然后新建教务领域中的核心子领域——学习领域上下文,StudyContext.cs,这个时候你就不用问我,为啥在教务系统领域中,学习领域是核心子领域了吧。
/// <summary>
/// 定义核心子领域——学习上下文
/// </summary>
public class StudyContext : DbContext
{
public DbSet<Student> Students { get; set; }
/// <summary>
/// 重写自定义Map配置
/// </summary>
/// <param name="modelBuilder"></param>
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.ApplyConfiguration(new StudentMap());
base.OnModelCreating(modelBuilder);
}
/// <summary>
/// 重写连接数据库
/// </summary>
/// <param name="optionsBuilder"></param>
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
// 从 appsetting.json 中获取配置信息
var config = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json")
.Build();
// 定义要使用的数据库
optionsBuilder.UseSqlServer(config.GetConnectionString("DefaultConnection"));
}
}
在这个上下文中,有领域模型 Student ,还有以后说到的聚合,领域事件(上文中的修改手机号)等。
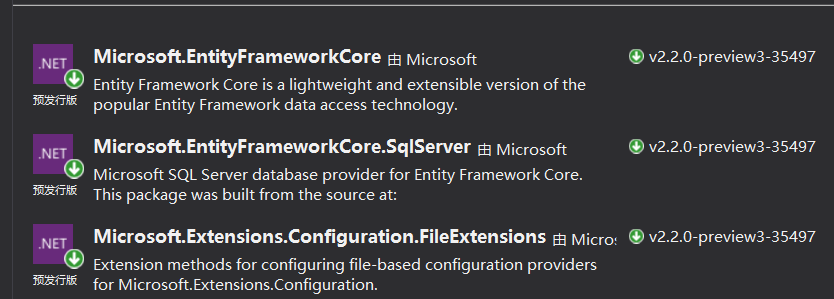
2、引入我们的ORM框架 —— EFCore
这里边有三个 Nuget 包,
Microsoft.EntityFrameworkCore//EFCore核心包 Microsoft.EntityFrameworkCore.SqlServer//EFCore的SqlServer辅助包 Microsoft.Extensions.Configuration.FileExtensions//appsetting文件扩展包 Microsoft.Extensions.Configuration.Json//appsetting 数据json读取包
这里给大家说下,如果你不想通过nuget管理器来引入,因为比较麻烦,你可以直接对项目工程文件 Christ3D.Infrastruct.Data.csproj 进行编辑 ,保存好后,项目就直接引用了
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netcoreapp2.1</TargetFramework>
</PropertyGroup>
<ItemGroup>
<ProjectReference Include="..\Christ3D.Domain\Christ3D.Domain.csproj" />
</ItemGroup>
//就是下边这一块
<ItemGroup>
<PackageReference Include="Microsoft.EntityFrameworkCore" Version="2.2.0-preview3-35497" />
<PackageReference Include="Microsoft.EntityFrameworkCore.SqlServer" Version="2.2.0-preview3-35497" />
<PackageReference Include="Microsoft.Extensions.Configuration.FileExtensions" Version="2.2.0-preview3-35497" />
<PackageReference Include="Microsoft.Extensions.Configuration.Json" Version="2.2.0-preview3-35497" />
</ItemGroup>
//就是上边这些
</Project>
3、添加我们的实体Map
Christ3D.Infrastruct.Data 基础设施数据层新建 Mappings 文件夹,以后在基础设施层的map文件都在这里建立,
然后新建学生实体map,StudentMap.cs
/// <summary>
/// 学生map类
/// </summary>
public class StudentMap : IEntityTypeConfiguration<Student>
{
/// <summary>
/// 实体属性配置
/// </summary>
/// <param name="builder"></param>
public void Configure(EntityTypeBuilder<Student> builder)
{
builder.Property(c => c.Id)
.HasColumnName("Id");
builder.Property(c => c.Name)
.HasColumnType("varchar(100)")
.HasMaxLength(100)
.IsRequired();
builder.Property(c => c.Email)
.HasColumnType("varchar(100)")
.HasMaxLength(11)
.IsRequired();
}
}
4、用EFCore来完成基类仓储实现类
将我们刚刚创建好的上下文注入到基类仓储中
/// <summary>
/// 泛型仓储,实现泛型仓储接口
/// </summary>
/// <typeparam name="TEntity"></typeparam>
public class Repository<TEntity> : IRepository<TEntity> where TEntity : class
{
protected readonly StudyContext Db;
protected readonly DbSet<TEntity> DbSet;
public Repository(StudyContext context)
{
Db = context;
DbSet = Db.Set<TEntity>();
}
public virtual void Add(TEntity obj)
{
DbSet.Add(obj);
}
public virtual TEntity GetById(Guid id)
{
return DbSet.Find(id);
}
public virtual IQueryable<TEntity> GetAll()
{
return DbSet;
}
public virtual void Update(TEntity obj)
{
DbSet.Update(obj);
}
public virtual void Remove(Guid id)
{
DbSet.Remove(DbSet.Find(id));
}
public int SaveChanges()
{
return Db.SaveChanges();
}
public void Dispose()
{
Db.Dispose();
GC.SuppressFinalize(this);
}
}
5、完善实现应用层Service方法
这个时候我们知道,因为我们的应用层的模型的视图模型 StudentViewModel ,但是我们的仓储接口使用的是 Student 业务领域模型,这个时候该怎么办呢,聪明的你一定会想到咱们在上一个系列中所说到的两个知识点,1、DTO的Automapper,然后就是2、引用仓储接口的 IoC 依赖注入,咱们今天就先简单配置下 DTO。这两个内容如果不是很清楚,可以翻翻咱们之前的系列教程内容。

1、在应用层,新建 AutoMapper 文件夹,我们以后的配置文件都放到这里,新建DomainToViewModelMappingProfile.cs
/// <summary>
/// 配置构造函数,用来创建关系映射
/// </summary>
public DomainToViewModelMappingProfile()
{
CreateMap<Student, StudentViewModel>();
}
这些代码你一定很熟悉的,这里就不多说了,如果一头雾水请看我的第一个系列文章吧。
2、完成 StudentAppService.cs 的设计
namespace Christ3D.Application.Services
{
/// <summary>
/// StudentAppService 服务接口实现类,继承 服务接口
/// 通过 DTO 实现视图模型和领域模型的关系处理
/// 作为调度者,协调领域层和基础层,
/// 这里只是做一个面向用户用例的服务接口,不包含业务规则或者知识
/// </summary>
public class StudentAppService : IStudentAppService
{
//注意这里是要IoC依赖注入的,还没有实现
private readonly IStudentRepository _StudentRepository;
//用来进行DTO
private readonly IMapper _mapper;
public StudentAppService(
IStudentRepository StudentRepository,
IMapper mapper
)
{
_StudentRepository = StudentRepository;
_mapper = mapper;
}
public IEnumerable<StudentViewModel> GetAll()
{
return (_StudentRepository.GetAll()).ProjectTo<StudentViewModel>();
}
public StudentViewModel GetById(Guid id)
{
return _mapper.Map<StudentViewModel>(_StudentRepository.GetById(id));
}
public void Register(StudentViewModel StudentViewModel)
{
//判断是否为空等等 还没有实现
_StudentRepository.Add(_mapper.Map<Student>(StudentViewModel));
}
public void Update(StudentViewModel StudentViewModel)
{
_StudentRepository.Update(_mapper.Map<Student>(StudentViewModel));
}
public void Remove(Guid id)
{
_StudentRepository.Remove(id);
}
public void Dispose()
{
GC.SuppressFinalize(this);
}
}
}

6、思考:这样就是DDD领域驱动设计了么
好啦,其实这个时候,我们的接口已经可以使用了,可能还有些注入呀,没有实现,但是基本的逻辑就这么施行了,你一定看着很熟悉,无论是DTO还是IOC,无论是EFCore还是仓储,一切都那么熟悉,但是这就是DDD领域驱动设计么,你一定要带着这个问题好好想想。答案当然是否定的。
到这里,我们的核心学习子领域的上下文的创建已经完成,请注意,这是上下文的定义创建完成,里边的核心内容还没有说到。
当然,我们在完成应用层的调用后,直接就可以用了,这个时候的你可能会发现,到目前为止,咱们还是一个普通的写法,和我们上个系列是一样的,没有体现出哪里使用了领域驱动设计的思想,无非就是引用了EFCore和定义了一个上下文。
没错,你说的是对的,目前为止还没有实现领域设计的核心,但是至少我们已经把领域给划分出来了,而且你如何看明白了上边的我说的内容,也应该有一定的想法了,明天咱们就重点说说领域事件和聚合的相关概念。
四、结语
今天重点重申了下DDD的意义,简单说明了下仓储的设计思想,然后也将我们的项目引入EFCore,并实现了接口等。这里我要说明三点,看看大家读完这篇文章的心情属于哪一种:
1、入门:如果你看到我上边的小故事,还对为什么使用DDD而疑惑,那就请再仔细看看,好好想想。不要往下看,就看第一部分。
2、了解:如果你看懂了我说的第一部分的意思,并了解了使用领域驱动设计的意义,但是看下边第三部分的代码结构又好像和平时的多层设计很像,而又去和多层对比,那麻烦请结合我的Git代码看看。
3、优秀:如果你明白了DDD的意义,并且很想了解我的架构到底是如何进行领域驱动的,恭喜你,已经成功了,剩下的时间我就会带你去深入了解 中介者模式下的事件驱动——CQRS。
核心内容要来了,你准备好了么 【机智表情】