标签:
本文读者基本要求:从事信息管理系统开发,略懂GOF设计模式及SOLID设计原则,对三层面向过程机械编码厌倦,并且不知道出路在何方,如果还掌握代码坏味和重构手法,那是极好的。
1. 三层架构
理论介绍-->实际经验-->总结反思
1.1
简单介绍三层架构
严格分层架构模式的特点是上层只能访问相邻的下层,其他层次间的调用都不允许。三层架构就是一种严格分层模式,它把职责划分为界面展示、业务逻辑、数据访问三层,还有一个业务实体,前面三层都要依赖它,所以它并不构成一个层。结构如图1。
三层架构的特点是一种面向过程的编程思想,特点如下:
a. 业务实体类中基本上只有属性没有方法。
b. 业务逻辑层的类基本上只有方法没有属性。
c. 将数据表结构映射为业务实体类是一个惯用做法,以至于有人将其称之为“传统”。这样的好处是只需要理解一套模型,能够通过自动化工具从数据表直接生成业务实体,还能够自然而然的通过自动化机制存储与检索业务实体。但对于复杂点的业务,这样做就是绝大部分问题的根源。
d.
当业务膨胀起来,需要划分模块的时候,我们有个常用的变形:提取一个服务层出来,用来组合模块间的交互,还为业务逻辑层提供了一个防腐层,可以把记录日志、验证权限、处理异常等职责分配给服务层。结构如图2。
上面介绍的就是我们常说的三层架构,由于采用了严格分层模式,用户界面层是绝对不能跨过业务逻辑层调用数据访问层的,同理服务层也是不能调用数据访问层。但是图2都有四层了,那它还是三层吗?这就需要见仁见智了,一般来说还是的。其实三层架构还有个更准确的名字----分层贫血领域模型架构,这样就不管多少层都能概括了,但是这名字没有三层那么朗朗上口。前面名字中的领域模型指的是业务实体,贫血意思业务实体中没有或很少方法。
1.2 实际应用中的三层架构
1.2.1 PetShop。
三层架构比较著名的例子就是PetShop,其技术内容比较丰富,MemberShip,ProfileProvider,各种接口,各种Factory, 可替换的数据访问层,缓存机制,消息队列等技术,看起来很牛的样子。但它的领域模型却比较简单,连模块都没有划分,只能算个玩具。很多年前,见识还比较少 的时候,微软就是我心中的神,只有微软提供的技术才是最正宗的,微软说的都是对的,没有用上微软提供的技术,心里就各种不对劲。后来学习设计模式,知道有 个模式痴迷症(如果在编码中没有用上模式,心里就各种不对劲),才明白原来自己之前患上了微软痴迷症。在我的实际工作经历中,微软痴迷症患者不在少数。就PetShop而言,微软只是展示一下他的技术而已,初学者们不明觉厉,盲目地奉它经典,以至于固步自封,不明白软件开发的路还很长很长,每种技术都有它的适用场景,选择权永远都在自己的手上(或在团队领导的手上)。
1.2.2 本人实际工作经历。
参加工作的前几年,都在小公司,经历的都是一个人开发的小项目,有时有个Web前端或美工配合一下,信息系统嘛,主要功能当然就是存储、检索、展示数据,业务操作就是CRUD了,业务逻辑最多就是验证一下业务实体填写的正确性,数据表的数量也非常有限。那时的我,在三层架构的统治下,做着一个快(枯)乐(燥)的数据搬运工(从数据库搬到界面或从界面搬到数据库)。
长期重复枯燥的工作会让人感觉前途无亮,穷则思变,结果就是人员的流动。对于短期小项目来说,人员流动根本不是个事,但是对于长期项目来说,可能就 没那么简单了,某些关键人物的离职,可能会引起很长期的震荡,接手的人加班、发脾气绝对是正常的(这视乎接手人员的技术水平),甚至可能使项目停滞不前。
终于,我顺从内心的呼唤,离开那个简单的环境,加入了一个比较复杂的长期项目。和以前一样,采用三层架构,信息系统项目嘛,CRUD就是基石,项目中绝大部分的工作就是搬运数据。不同的是,开发人员有10个以上(人生中第一个团队开发);数据表超过200个 (这是以前不敢想象的)。更加不同的是,有些功能,它可能牵涉到了所有的数据表,做这样一个功能,首先要把所有关联到的数据表都找出来,理解清楚表与表之 间的关系,比较痛苦的是别人写的代码你基本用不上,都要自己从头搞。对于那些平时只是埋头搞自己一块功能的人来说,简直是要命。还有更要命的,不知道什么 时候需求又变更了,而处理这个功能的人离职了。开始,接手的新人两眼泪汪汪求多给点时间,而领导不理解,以前谁谁不是很快就搞定了吗?那些站着说话不腰疼 的同事说,这功能简单,这个、这个、还有这个表,那个、那个、还有那个表,这样再那样就解决了。我把这种协作方式成为嘴炮协作,真正的协作应该是代码层面 的。新人没法辩驳一般最后会选择默默地加班。人员继续流动,这样的情形发生多次之后,领导开始意识到,情况没那么容易了。特别是如果几个关键开发者都离职 了,那境况更是难上加难。就算没有人离职,情况一样是越来越难,这我在后面的一个项目中有比较深刻的体会,但是并不是所有人都会把这种难归结于架构不对或 团队开发水平还有待提升,他们会认为这是需求的问题或者其他同事的问题,还有人会认为这是正常的必然的无解的事情。如果一段时间复杂的功能变更多起来,加 班就会成为常态,如果加班能够搞定,情况还不算最糟糕。“水很深,水太深,水不知道有多深”开始成为了团队的口头禅。比较幸运的是当时那个项目这样的功能 不算太多。最后有人总结出一句名言:“谁遇到谁倒霉 ,忍忍就过去了”。说到这里,很多人可能会说,让所有开发人员的熟读所有数据表不就行了?实际情况是,除了关键的几个人,其他开发人员往往没有那个愿意把 有限的生命浪费在阅读这些下个项目就毫无用处了的数据表上,而且表的数量可能会增长到没有任何一个人能够整体掌控的程度。而且一个牵涉多个模块的复杂功 能,不能调动相关模块来协助,反而都得直接与数据库打交道,其他模块的逻辑也需要自己处理,这是单打独斗的套路,体现不了团队的协作与效率;再有就是不能 复用那些久经考验的代码,导致重复代码慢慢积累,系统缺陷也比较多。而且由多人接手后,一旦有人理解出了偏差,需求变更导致致命缺陷的几率会很高。
虽然项目组的生活氛围不错,时不时有经费给同事们出去吃完玩乐一下,但是不能预料什么时候需求就会提出一些“险恶”的功能,对人的精神也是一种考验。为了应付随时可能出现的各种险恶情况,我学习掌握了一些重构手法,学会用了UML来分析问题,还在项目中成功地应用了两个设计模式来解决一个棘手问题。但是在三层架构的大环境下,能够发挥的余地也是非常有限,有种有技术没地方用的感觉,常有新建一个类不知道该往哪个层放的情况。
后来,我还在另外一个采用三层架构的长期项目里呆过,情况与上一个项目基本一样,除了人员比较上一个项目稳定很多。就三层架构实际遇到的问题,我咨询了一些项目经理朋友,他们的意见如下:
经理A:代码是不可能写成书上介绍那样规范好维护的。
经理B:需求是不可能稳定下来的,代码也是不可能稳定下来的。
经理C:项目到了后期代码乱?难道不都是这样吗?
1.3 三层架构的反思
Linus Torvalds :Bad programmers worry about the code. Good programmers worry about data structures and their relationships. (差的程序员纠结代码怎么写,好的程序员纠结数据结构和结构间的关系。)
三层架构的最大问题在于:实际应用中人们喜欢把内存模型和数据库模型保持一致。三层架构的大部分问题都是从这里衍生出来的。
数据库模型的粒度如果很小,那么大量的表连接很快就会让数据库跑不动了。
如果数据库模型的粒度如果很大(这是大部分项目的选择),代码的质量(重用性、稳定性、扩展性)就很差。由于没有从业务的角度去仔细定义每一个对象,每个人会根据自己的需要建立各种QueryModel或ViewModel,慢慢地类会多到想哭。或如果不建立各种Model,强行重用DataModel的话,那么接口提供的内容往往绝大部分都不是你想要的。
内存模型与数据库模型保持一致并非天生的,这是有很多原因造成的:
它建模的简单性让初学者无法拒绝,由于经验主义,以至于多年以后已经没有勇气去摆脱了;
没有专门论述三层与建模的书籍;
ORM工具误导,与数据表结构一致内存结构方便建立映射关系;
示范代码的误导,错误把示范代码当成产品代码;
等等......
种种误导导致很多人工作很多年后依然未能找到正确的路,忽略了一个重要的核心(业务建模)环节(业务模型要与代码的数据结构保持一致),但是他却坐 上了项目领导的职位,这就是更大的误导了。以至于让人产生无论你去到那个公司都是一样的错觉(在很多人的经历中,这的确是事实,包括我自己),但事实不应 该是这样的。
用户界面,领域模型,数据库它们应该具有同等的重要位置,领域模型在很多公司都是被忽略的角色。
我们应该相信:优秀的软件一定是由优秀的开发者制作的,团队的协作方式应该在代码层面,代码复用可以降低缺陷和提升效率。而这些都指向你应该离开“传统”三层架构。
还有一些三层开发人员最终患上了数据库痴迷症,他坚信程序就应该做个搬运工,其他的事情都应该交给数据库来完成,业务逻辑也应该写进存储过程里面去。
2. 三层分层到DDD分层的转变过程
优化层次关系-->重构到面向对象设计-->使用DDD相关模式深入重构
上面讲到,三层是“分层贫血领域模型架构”,那么DDD则可称为“分层充血领域模型架构”。从名字上看,它们就有亲戚关系,有亲戚好办事,嘿!
三层到DDD的 过程大体是这样的:首先推翻严格分层的理念,采用松散分层来重新定义服务层(松散分层的意思是上层可以访问下层,而不只是相邻的下层),把调用数据访问层 的职责交给服务层,接着把业务逻辑层移动到与业务实体在一起,再接着融合业务逻辑与业务实体,使之成为面向对象的设计,然后利用DDD的模式进行更深入的重构。在DDD技术掌握的还不是那么扎实的时候,三层技术基本仍然能够继续使用。
2.1
优化三层结构&重构到面向对象的设计
由于目前的服务层职责是非常轻的,甚至有很多空壳的调用,所以平衡一下职责,把调用数据访问层的职责从业务逻辑层提升到服务层,需要的数据通过参数传递给业务逻辑层。这样,对于那些简单到无业务逻辑的CRUD就不需要去访问业务层了,直接调用数据访问层。
结构如图3,我们看到业务逻辑与数据访问层已经没有依赖关系了。
然后我们就可以把业务逻辑与业务实体移到一块。
然后把属于业务实体的逻辑迁移到实体类中。
上
面简单单几句话和两张图就把问题搞定了,但是实际迁移过程中,风险是非常大的,如果没有充分掌握重构知识,建议不要在正式产品代码上尝试。有些逻辑无法归
类到任何一个业务实体上的,就让它留在原地,成为一个领域服务。有些逻辑连领域服务都无法归类的,就让它留在服务层,在坚持大方向的前提下,细节灵活处
理,因为每次重构都能够让你对未来的路看到更清楚,很可能下一次重构后你就会为这些流浪逻辑找到合适的家了。所有的建议都只是建议,最终决定权在你的手
上,受苦的人始终都是你自己。
一个事实是:掌握的编程思想越多,那么搬迁起来就越容易,倘若编程功底太差,可能根本无法搬动,不建议初学者进行这些危险的试验,因为你一定会把事情搞砸的,如果你把事情搞砸了,请自我反省一下是不是编程思想不太够用。
上面的过程并非要你一步到位,你可以把代码重构到任何一个时刻,等待后面知识跟上了,再进行下一步的重构。
到目前为止,代码还是那些代码,只是位置变了而已,所以如果严格按照重构手法进行,编译、运行应该都是没有问题的。就这样,在现有生活没有任何影响的情况下,你已经为你的职业生涯打开了另外一扇门,再也不怕编程技术拼不过那些年轻人了。
实际上,DDD只是让你重新回归到面向对象编程,没有什么更加神奇的魔法,当然DDD超越面向对象的地方在于对类的设计提出了更多的指导方法。
2.2 使用DDD相关模式进行深入重构
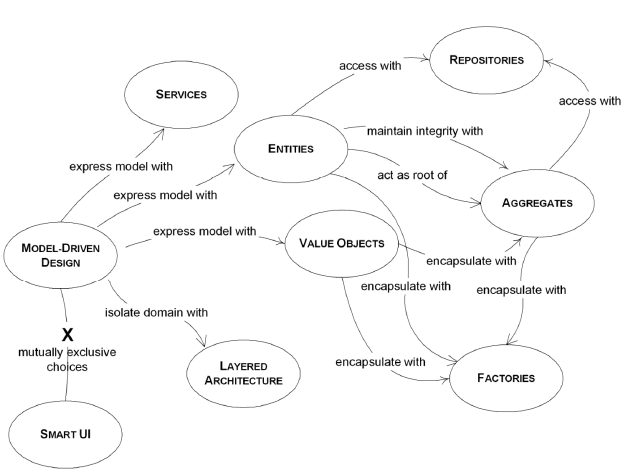
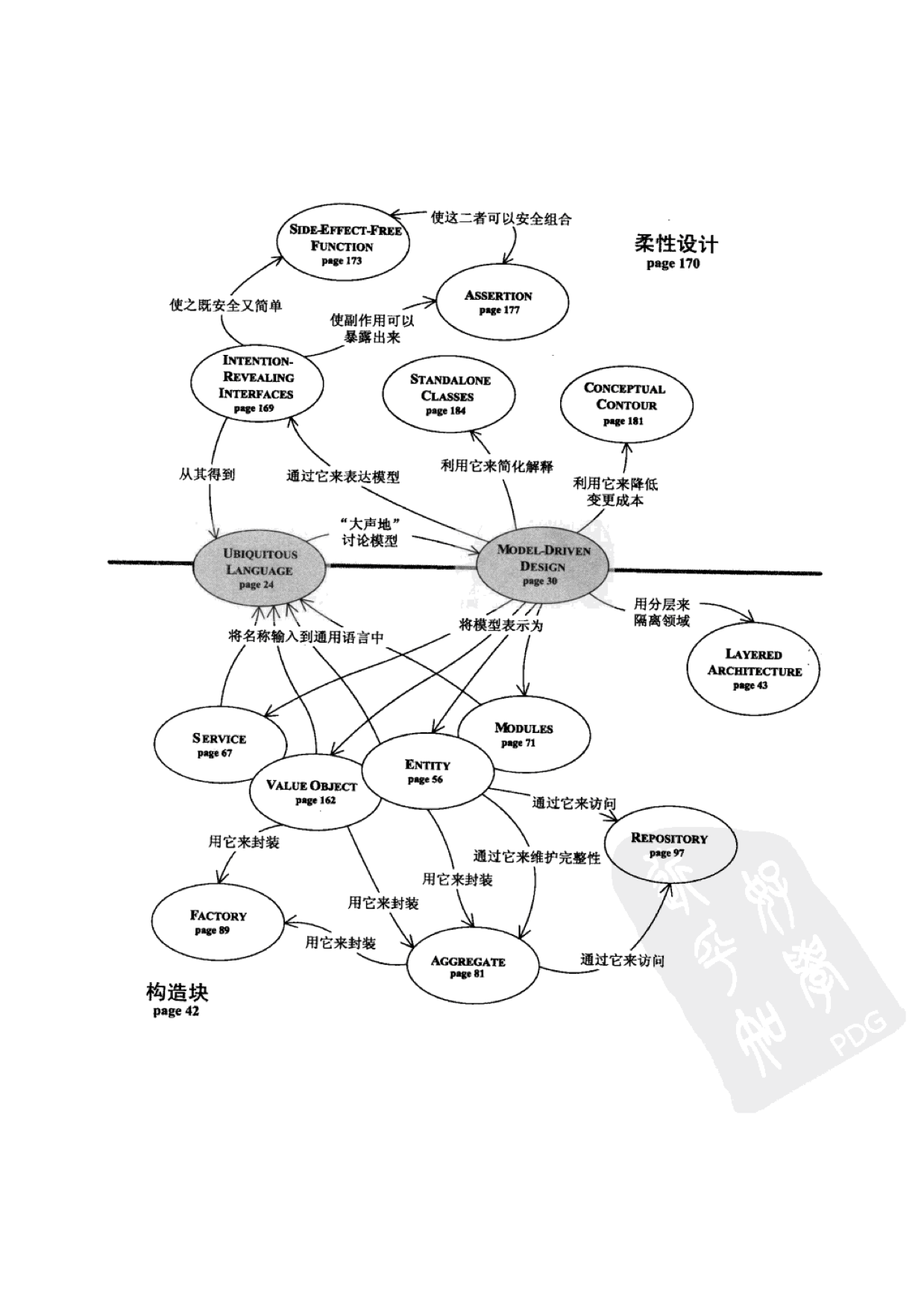
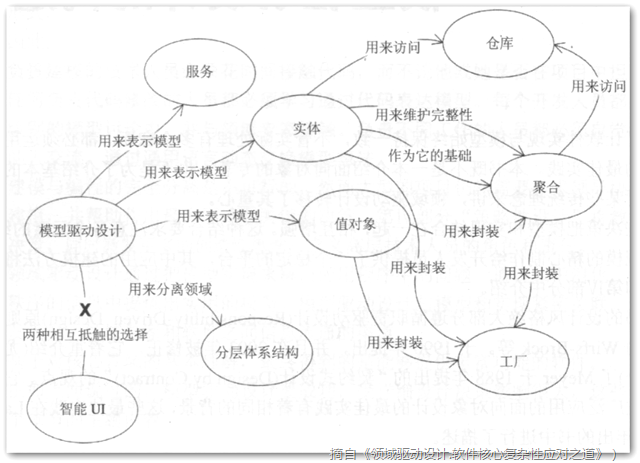
正式介绍一下DDD的分层架构,当然DDD的架构并不限于分层,现在还有六边形架构、CQRS、EventSourcing等技术可以选用,但是不要好高骛远,先把分层架构掌握好。原版分层结构如图5,改进版结构如图4,图4基本上就是图3的各个层换了名字,并且UI可以访问基础设施层。而图4与图5的区别在于,图4是基础设施依赖领域层,图5是领域层依赖基础设施层,这两层的关系倒置了。这样的倒置会更凸显领域层的核心地位,也有人认为这样已经算是六边形架构了。
DDD各层次职责解析:
用户界面层:
原版----负责向用户展现信息以及解释用户命令。
补充---- MVC中V和C都属于UI层,V展现信息,C解析用户命令。UI像地图一样把各个控制器关联了起来。
应用层:
原版----很薄的一层,用来协调应用的活动。它不包含业务逻辑。它不保留业务对象的状态,但它保有应用任务的进度状态。
补充----协调应用的活动这句话太抽象了,我充实一下它:从数据访问中获取领域对象,调用领域对象的方法完成任务,然后再调用数据访问代码把领域对象的改变持久化。事务、权限检查、记录日志、处理异常的职责也归它管。这点和前面三层的服务层的职责其实是一样的。
领域层:
原版----本层包含关于领域的信息。这是业务软件的核心所在。在这里保留业务对象的状态,对业务对象和它们状态的持久化被委托给了基础设施层。
补充----业务对象的持久化工作我们已经提升到应用层了,一般情况下,这层最好不要涉及资源库的调用,但是并不绝对。资源库的抽象要么在领域层中,要么提升到了“应用程序框架”,领域层是不会依赖基础设施的。
基础设施层:
原版----本层作为其他层的支撑库存在。它提供了层间的通信,实现对业务对象的持久化,包含对用户界面层的支撑库等作用。
补充----这层的职责包含了三层的数据访问,但是并不代表UI层就可以调用数据访问的代码,而且职责范围扩充了,有人可能会把它当作存放公用代码的地方,但是建议这里只存放本项目公用的东西,如果能够跨项目公用的代码应该放在一个叫做“应用程序框架”的项目来完成,每个公司都应该有自己的应用程序框架。
对比一下三层分层与DDD分层:
a. UI层技术基本一样,一些比较智能的绑定可能无法进行了。
b. 服务层基本一样。
d. 业务实体+业务逻辑 = 领域层
e. 如果三层架构不采用业务实体与数据表一致的做法,这层也是一样。由于内存结构与数据表结构之间存在阻抗失配,存取领域对象没那么简单。
DDD模式: 聚合,实体,值对象,工厂,资源库,模块。如果完全没有DDD经验,建议首先阅读《领域驱动设计精简版》一书,可快速掌握DDD的理念。
聚合:这是个难点,一般建议是要设计小聚合,聚合与聚合之间用ID关联,不要直接引用。聚合包含实体,值对象。表达聚合的对象叫做聚合根。聚合内部所有对象的变更必须通过聚合根。聚合根的本质是一个实体。如果聚合要传递给其他模块(系统),一般不要直接传递聚合根,新建一个粗粒度的值对象来进行传递,即DTO对象,DTO也可由接收方建立,由接收方决定需要什么数据,这样就解耦了模块间的关联,至于数据库中是否需要把这个DTO冗余存储,则看实际情况。聚合的数据表设计原则:大表小类。即数据表采用粗粒度,聚合根内部使用细粒度对象,有可能的话,尽量每一条数据表记录就是一个聚合。
实体:特点是必须要有一个ID来标识自己,可包含值对象和其他实体。
值对象:特点是个只读对象,没有ID标识。
工厂:由于聚合的创建可能是个非常麻烦的事情,用工厂来封装这个复杂麻烦的过程。
资源库:资源库就是持久化聚合的地方,就是说数据存储的最小粒度是聚合。但是数据查询的需求可能非常灵活,实践中这条规则有点僵化,一般使用是读写分离方案,就是写的时候使用聚合对象,但是读的时候可以根据业务仔细建立一些查询模型(QueryModel)进行读取。至于数据库是否需要分成读写两个模型,还是要看实际情况,在系统更复杂和需要更高性能的时候,数据库的模型也要分成两个,不过它们之间的同步就比较麻烦了。领域事件、CQRS、Event Sourcing等技术就是用来解决这个麻烦的。
领域服务:总有一些需要多个聚合进行合作才能完成的业务,它们不能简单地划归参与的其中一个聚合,要用一个领域服务来表达,注意领域服务不是应用层的服务。
模块:如何划分模块,一般有横向划分和纵向划分两种,横向划分例如:实体模块,工厂模块,资源库模块。纵向划分例如:商品模块,订单模块,支付模 块,每个模块内部都会具备聚合,资源库,值对象等元素。一般的经验是横向划分对项目没有什么帮助,纵向划分可以减少系统的复杂度。模块间的交互在应用层进 行。
在重构的过程中,用各种代码坏味作为切入点,DDD模式、设计模式等作为方向,利用成熟的重构手法掌控重构过程,然后用SOLID设计原则评估你的重构成果。进行改动架构的重构,必须要整个团队取得共识,并且需要掌握DDD的人加强代码走查,确保一直走在正确的道路上。
再次强调,重构,是很多人的口头禅,但是对整个系统架构进行重构,这是个高风险的大工程,必须在团队中取得共识,并有明确的目的地和到达目的地的安全路径。
至此,三层到DDD的转换完成了。这是三层的终结,也是DDD的开端。路,还长。
3. DDD技术支撑框架
comming soon...
4. DDD领域建模经验
comming...
5. 数据库设计与性能优化
comming...
6. DDD实际工作经验及例子
comming...