领域驱动设计-聚合,一种极简的思维模式
引言
作为IT技术产业飞速发展的产物,软件工程学已经成为当今时代非常重要的一个学科。作为一名资深的软件开发从业者,我们需要学习的东西实际上已经远远超出了原本在大学教育阶段所接受的知识深度和广度,领域驱动设计更是如此。当然必须承认的是大学阶段开了很多扇窗,直到今天才深刻体会那些平时看起来毫不起眼的学科(如图论、概率论、高等代数),实际上对软件领域的影响已经远远超出了我们的想象,例如,如果想做AI,没有扎实的数学和图论基础,显然只能成为工具的使用者,而非技术专家。
有许多读者提到,笔者的内容缺乏实际例子,在具体阅读时,很难形成带入感。主要是因为领域驱动设计思想本身体系庞大,细节非常多,这需要在日常学习之余多加思考,细细的品味知识中的奥妙,笔者也是按照同样的思路来指导自己的学习过程的。坦率而言,要把这些概念的名词都记住,显然很容易,但是要理解这些名词的具体含义以及实际应用场景,却需要更多的思考,这也同样是软件工程博大精深的奥妙所在。
领域生命周期的复杂性是如何影响设计的
我们都清楚领域驱动设计,作为应对复杂情形下的软件工程思路,实际上受到了传统软件思维的广泛影响,例如之前提到的实体和值对象、以及服务和包(模块)实际上在非领域驱动设计中同样普遍存在。但是聚合和聚合根的思想,应该属于领域驱动设计中独特的知识点,进一步加强这个知识点的认识,将有助于我们更好的进行聚合设计,从而更好的设计一个符合实际应用场景的应用系统。
在上一篇文章中,我们了解到,领域驱动的五个基本部分(关联,实体,值对象,服务和模块),他们是构成软件体系的最基础元素。在一个简单的软件系统中,往往只需使用这些元素的简单组合即可完成单个模块功能的开发,而且显然速度非常迅速。但是我们也将同样面对一些对象,他们具有更长的生命周期,也许有相当一部分时间,是通过复杂的数据持久化处理机制、甚至是跨数据源、跨服务来完成,这意味着不是单纯的依靠一块内存空间来度过的。它们与其他对象有着复杂的依赖关系,在它们漫长的生命周期中,会根据不同场景的规则、经历许多次状态的变化。对于这些对象的操作,稍不留心,就会导致代码间的耦合度急剧提升,甚至成为软件系统中最难以维护的代码块,这实际上偏离了模型驱动设计的理想轨道,成为经验设计史上的一大典型问题。
领域驱动设计认为,这种复杂过程的操作对模型驱动设计带来的影响主要包括以下两个方面:
1、维护对象间,在整个生命周期中的完整性:对象依赖不同的数据源或存储机制或内存单元时,完整性将难以保障。
2、陷入管理生命周期复杂性造成的困境中。同上,要维护这套具有复杂体系的模型结果,本身成为一个问题。
聚合,让设计简化
领域驱动设计思想针对这两种场景,设计了聚合(Aggregate)对象来解决这个问题,并使用工厂对象和仓储对象来对生命周期进行管理,由于时间和篇幅的关系,我这一篇先介绍聚合对象和聚合根,下一篇在介绍工厂对象和仓储对象。
实际上我们很容易就设计出一个具有复杂关系的对象,例如,Person对象,实际上可能关联了地址和工作等不同的实体或者值对象,如果要对数据进行删除,可能倾向于直接删除Person对象,而保留其他对象;或者删除Person对象时,同时删除地址对象。但是这两种方式都并非非常合理的策略,在于方式一,会在数据库中形成冗余数据,不利于后期数据的维护管理;而后者则可能导致依赖于地址的其他Person出现异常。
即使是再简单的场景,遇到并发访问时,也会存在问题。由于不同的用户对系统中的数据的访问是随机分布的,意味着有可能会造成多个用户同时修改相互依赖的对象,进而造成系统可用性的急剧下降。
因此,在具有复杂关联的模型中,要想保证数据更改的一致性是很困难的。不仅互不关联的对象需要遵守一定的规则,而且紧密关联的对象间操作同样也存在规则。经常使用的一种方式可能是事务锁,但是设计谨慎的锁机制,固然可以解决这个问题,但是可能导致用户间的操作不可控,系统变得不可用。事实上数据库层面的行锁和表锁,也是为了解决这些问题提供的思路,但是这种方案实际上分散了人们对于模型的注意力,使得系统流程的设计过程本身就相当臃肿。这也是古老的系统用户体验不佳的一个主要原因。
领域驱动设计认为,表面上看是对数据操作层面的技术问题,但是它的根源依然是由于模型的设计依然是基于实体关系模型的设计,而缺乏明确定义的边界。认为通过一个合理的模型的设计,可以是模型更加理解,并且使设计过程更易于沟通。当模型被修改时,它也将引导我们对实现进行修改。
这种模式,就是聚合模式(Aggregate)。这种来源于制造业体系中的模型,简单但严格,但是可以提供新的思路。
领域驱动设计中,认为实现这个聚合模型,应当包含以下要素:
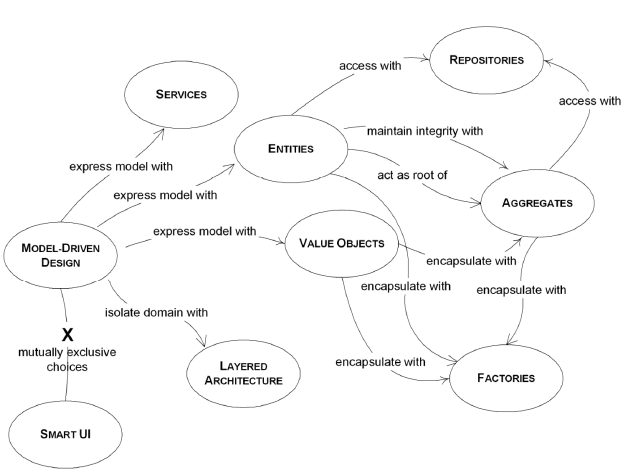
1、通过一个顶层抽象来封装模型中的引用。使用Aggregate对象,实现一组相关对象的集合,作为数据修改的单元。
2、每个Aggreate对象具有一个根和边界。边界,用以定义Aggreate内部都有什么。而根是Aggregate对外暴露的特定实体。对Aggregate而言,外部对象只可以引用根,而边界内部的对象则可以相互引用。
3、除根之外的所有实体,在Aggregate内部都有唯一标识,但外部对象只能看到根实体而无法看到其他实体。
对Aggregate的操作,应该按照一定的规则,确保数据变化时,能够保持一致性。而任何跨越Aggregate的规则,则不要求每时每刻都保持最新状态,跨越通过事件处理、批处理或者其他更新机制,使依赖项在规定的时间内得到解决。但是在Aggregate内部,规则必须得到满足。
这意味着,对于这个Aggregate的操作,必须应用更加具体的规则,包括但不限定于以下内容。
1、聚合根Entity,具有全局标识,代表整个Aggregate对外提供服务,并最终负责检查规则。
2、边界内的对象具有本地标识,但仅限于Aggregate内部保持唯一性。
3、Aggregate外部的对象不能引用除根Entity之外的其他内部对象。根可以将内部对象的引用传递给外部对象,但是外部对象只能使用,而不能保持引用更不能操作。这也意味着,根可以将值对象的副本传递给外部对象,因为它只是一个属性值,而不是一个完整的生命周期对象。
4、只有Aggregate的对象才能通过数据库查询直接完成,而其他对象应该在创建后,通过根的对象遍历关联来发现。
5、Aggregate内部对象,可以引用外部的Aggregate根对象的引用(不能反过来)
6、删除操作,应该一次性删除Aggregate边界内的所有对象。
7、对Aggregate内部任何对象的操作,必须保证上述规则都得到满足。
总结
Aggregate对象实际上是通过划分一个界限清晰的范围,确保在Aggregate对象的生命周期内,对范围内对象每个阶段的操作都满足规定规则。
对Aggregate对象的定义和分析是一件非常细致的工作,我们应该根据实际应用场景,将实体和值对象分别聚集到Aggregate中,定义好边界和根后,通过根Entity来控制对边界内部其他对象的访问。只允许外部对象引用根,并在一次操作中,临时引用内部成员。但不能通过根来修改内部对象,这种设计有利于Aggregate内部的对象满足规则,也能保证它本身能够作为一个整体满足规则。而对Aggregate对象上的操作,是通过下一篇提到的Factory和Repository来实现的,它们分别在不同的阶段,实现了对象转化的复杂性封装。
领域驱动设计思想是一个博大精深,内涵丰富的策略,这个系列主要是我在阅读相关文献过程中的笔记的积累,同时也是期望能够将相关内容梳理、形成自己的设计思想的一部分,如果大家想了解更多的知识,强烈推荐大家阅读《领域驱动设计-软件核心复杂性应对之道》。