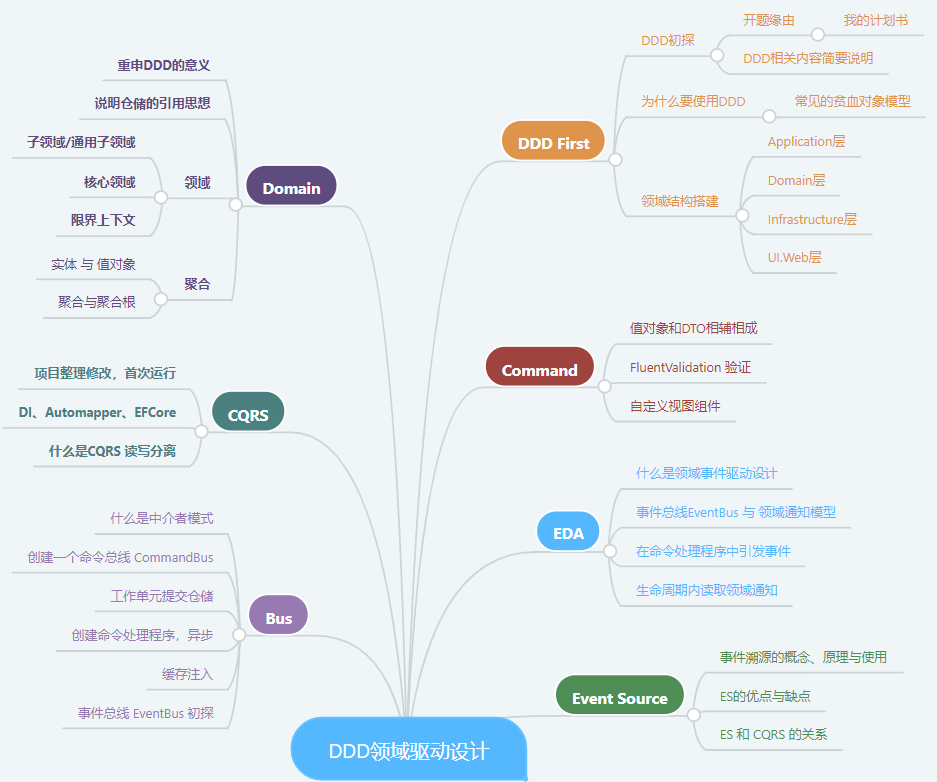
Repository设计思路
像模块化系统、模块化代码一样,模块化数据库中的表。使得每个模块之间有清晰的界限。
Repository代码设计可以将Reposi
Repository设计思路
像模块化系统、模块化代码一样,模块化数据库中的表。使得每个模块之间有清晰的界限。
Repository代码设计
- 可以将Repository理解为一个集合(这里的集合更偏重于是Collection,而不是Set),它包括了对存储对象基本的增删改查(CURD)功能。同时,Repository还包括满足领域层的一些特定的功能(注:在Repository中包括这些功能是合理的,首先这些功能是底层设施应该提供给上层的领域层的,其次在这里实现可以更好的利用底层设施的特点来进行性能优化)(注:在一般领域驱动设计的项目中分层都是上层依赖下层,这里的设计却更偏向于下层基础设施层依赖于上层领域层。应该可以发现,这里Respository的需要包含的功能都是由上层领域层需要什么决定的,而不是由下层基础设计层能提供什么决定的。笔记认为这样的设计其实是更合理的,《Clean Architecture》一书的作者也与笔者持有相同的观点。这个问题的讲述可以单独写一篇博客,再这篇文章里不再细究)。
- 不是每张表都需要有一个Repository(在Mybatis中aka:Mapper)与之对应,更准确的说:应该将数据库中的全部表表聚积到几个根对象上(聚积方法后面讲),这个根对象应该有Repository,而聚积在这个根上的对象不应该有Repository。对这些非根对象的访问,应该通过于根对象的对象关系来实现。
- (注:和第一条紧密相关,我暂时没有想清楚他俩之间的联系)正确的组合搜索于关联。搜索,即通过给Repository传递查询参数来获取对象;关联,即通过要访问对象与通过搜索得到的对象的关联来获取对象。
- Repository应该是一个接口,将其实现与领域层的需求解耦。同时,方便测试时进行插桩和mock。
- 虽然通过接口解耦了Repository与领域层,但是即便是领域层的开发人员,也应该清楚Repository的实现。避免出现性能问题。
- Repository不插手事务,将事务管理交由上层领域层和应用层管理。
- Repository应该让客户感觉到那些对象就好像驻留再内存中一样。
- 根是Aggregate中包含的一个特定的Entity。在一个Aggregate中,根是唯一允许外部对象保持对它的引用的元素,而边间内部的对象之间则可以互相引用。
数据库模式(database schema)设计
笔者认为的书中不严谨的地方
- P104,书中写道:
当然,如果在Java中查询所返回的对象是集合时,客户不管怎样都要执行这样的转换。
Java1.4添加了泛型之后,返回集合时,不再需要用户进行强制类型转换。作者写书时,Java1.4应该还没有发布,所以这样描述并没有错误。但是,这可能给后来的读者造成一些困惑。
TODO
- P102页中提到的一种灵活的、声明式的表示搜索标准的方法于Mybatis中的Example的概念有点儿像,之后研究一下俩者的关系。
- 书中反复提到的ENTIRY与VALUEOBJECT的区别笔者一直没有太明白,之后需要研究一下这块儿。