前言
目前,关于领域驱动设计(Domain Driven Design)DDD的培训,材料,视频都比较多,大家对DDD的一些概念都有所了解,但是在实际使用过程中,有很多的问题。例如
- 为什么DDD的架构要表示成六边形和洋葱形呢?
- 从六边形图来看,有领域层的概念么?如果有的话,用户接口层能否直接访问领域层?
- 四种领域模型,应该优选那种模型?
- 领域跟功能模块有啥区别?
- DDD看上去与嵌入式开发挺契合的,但是结合业务,怎么理解和运用?
- DDD的格局有点大,思维的方式很好,但是套到我们的驱动开发上,是否能很好的匹配?
本文结合我们在显示重构使用DDD完成建模的实践,探讨一下如何在嵌入式开发中把DDD落地。欢迎大家提出问题,我们一起探讨。
1. 软件架构的演进和DDD的出现
首先,我们回顾一下软件架构的演进的历史和DDD出现的背景。
软件基础体系结构演进的历史
如下图,软件的基础体系架构的演进的大体时间线和一些标志性的技术。整个软件体系架构演进可以分为4个阶段:
-
单机时代
- 所有软件层都在一个PC机上实现。
- 那时候就有了软件分层的思想,主流的软件架构是MVC(数据模型,视图,控制器)
-
局域网时代: 1985 ~ 1995
- 客户端和服务器在一个局域网中
- 软件的功能细分成了客户端和服务器即C/S结构。UI和业务逻辑在客户端,服务器端是数据库。当时的王者是VB/Sybase/Oracle。
- 软件架构还是基于MVC三层的架构,但是面向对象设计OOD和UML设计开始流行,面向对象的编程(OOP)开始成为主流的编程语言。
- 面向对象的23中设计模式,也是在这个时代诞生的(1995 年,GoF合作出版了《设计模式:可复用面向对象软件的基础》一书,共收录了 23 种设计模式)。
-
互联网web1.0时代 : 1996 ~ 2006
- 互联网开始迅速流行,泡沫也开始产生,到了2000年到达了顶峰。
- 这个时代的基础体系架构是浏览器,客户端,服务器的架构(B-C-S)。UI被Web UI代替,同时Client端承载着web 服务器(提供web服务)和应用服务器(业务逻辑)两个作用,服务器端还是数据库服务器。
- 后来,web服务器和应用服务器也开始逐步的移植到了后端,基础体系结构也就进化到了浏览器-服务器(BS)结构。
- 这时,应用服务器和数据库服务器都是由使用者自己搭建物理主机系统和维护其运行,或外包给IDC和应用软件服务商。这种系统一般称作on promise - 在场或私有软件系统。
- 这个时代,基于互联网的架构模式开始大量涌现,REST,EDA,SOA等。主流的架构模式是Monolithic Architecture 单一式架构,即所有的功能都放在一起,只做了分层,纵向的属于同一业务的模块之间是形式松散上或只是逻辑上的Function Group 功能群组形式组织在一起。
- 随着后端系统的愈加复杂和庞大,单一式架构已经难以维护和局部升级。
- 为了解决这个问题,在2004年,Evans提出了领域驱动设计DDD(Domain Driven Design), 但是当时并没有收到太多的关注。 主要的原因还是基础设施体系还不够灵活,把一个单一系统分解成多个系统,维护和部署的工作量会成倍的增长。
-
云时代Web2.0 - 2007 ~
- 亚马逊开始推出EC2的云上虚拟机服务,软件体系架构就进入到了云时代。
- 企业不再需要自己搭建和维护物理主机了而是直接跑在云厂商提供的虚拟机上(IaaS模式),随着云厂商提供越来越多的服务,包括API网关,数据库,Web服务等一些列的服务(PaaS),尤其是在容器技术成熟之后,使得在不同的地域和云厂商上灵活的部署服务成为可能
- 云端的软件技术也突飞猛进,SOA,CQRS,ES,DCI, Actor等架构模式都从相继出现。
- 软件的整体架构模式也从Monolithic Architecture 单一式架构跃升到了现在非常流行的 Microservice Architecture微服务架构。
- 而最近几年,以BaaS(Backend As A Service)和FaaS(Function As A Service)为基础的无服务器架构Serverless也越来越流行
- 随着基础设施体系的容器化和构建部署DevOps体系的自动化,使得部署和维护多个小系统的代价大大降低,微服务架构所带来的好处也极大的体现出来,而领域驱动设计DDD因为和微服务架构的思想十分契合,而且因此也收到了广泛的追捧。
我们接下来看一下,领域驱动设计是如何把对一个实际的系统进行设计建模的。
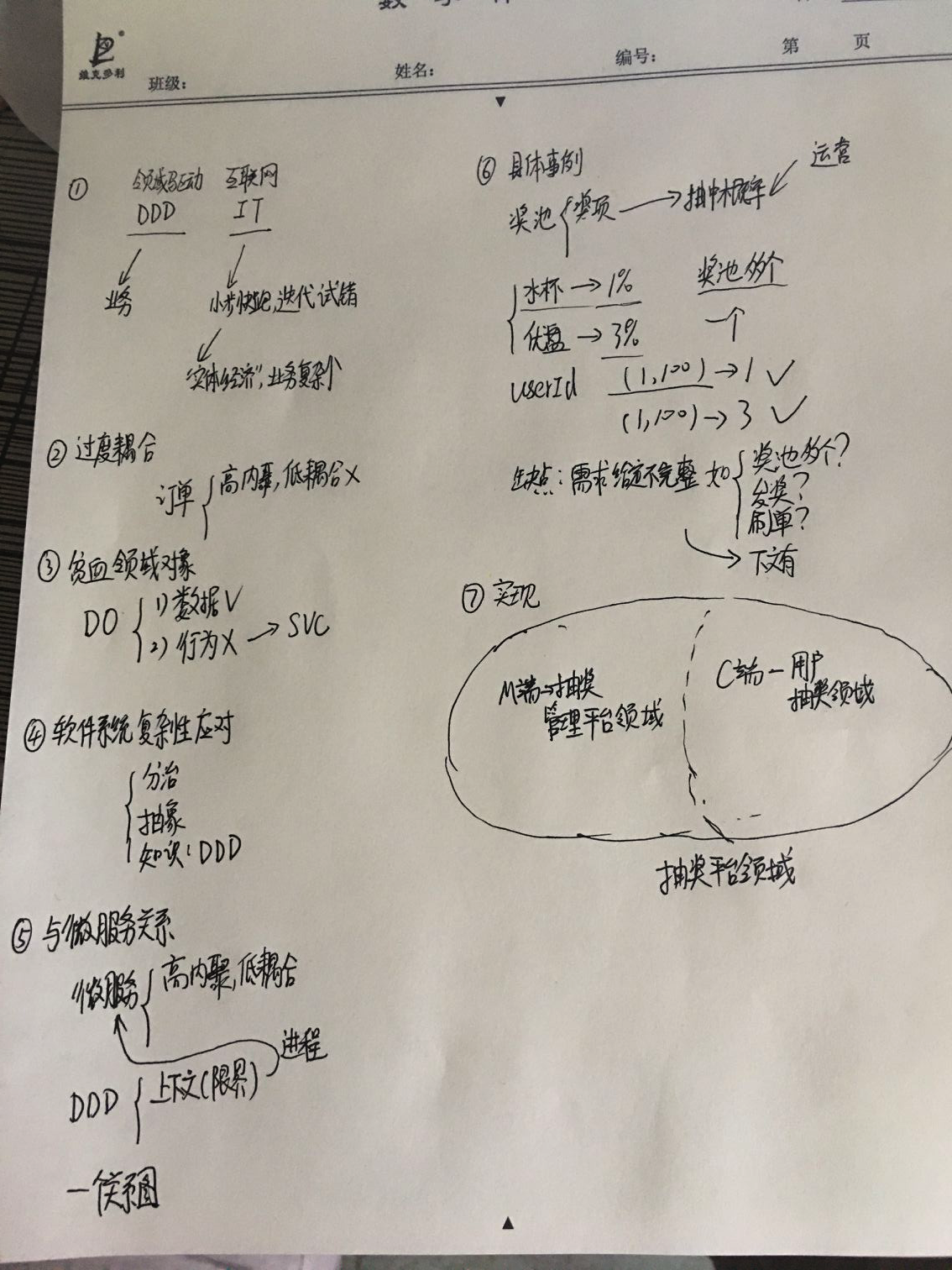
2. 领域驱动设计的要点
领域驱动设计由Eric Evans在2004年出版的书中首次提出。后面经过了很多改进。已经形成了一套从战略到战术一套的建模方法。关于领域驱动设计的细节,大家可以参考参考文献【5】~【7】。这里只概括一下要点。
DDD建模可以分为战略和战术两个层面
- 战略设计:主要是和领域专家一起通过事件风暴的方法做需求分析和领域建模。包括
- 识别限界上下文(Bounded Context)和划分子领域,核心子域,支撑子域,通用子域。
- 核心子域:决定产品和公司核心竞争力的子域是核心域,它是业务成功的主要因素和公司的核心竞争力。核心子域包含了业务的核心逻辑和核心的模型。
- 通用子域:没有太多个性化的诉求,同时被多个子域使用的通用功能子域是通用域。通常是提供一些通用的服务,例如日志,鉴权,性能管理,调试等
- 支撑子域:还有一种功能子域是必需的,但既不包含决定产品和公司核心竞争力的功能,也不包含通用功能的子域,它就是支撑域。支撑子域的功能甚至不用自己开发,可以直接购买。例如电商里的支付,物流等。
- 在识别限界上下文中建立该领域内的统一语言(Ubiquitous Language)
- 建立界限上下文之间的上下文关系(Context Map,上下文关系有9种,详情请参见文献【7】的第4章)
- 根据上下文映射选择合适的集成类型(Model Integrity,主要是RPC,RESTful API和消息机制,详情请参见“集成类型Model Integrity常用的架构模式”)
- 识别限界上下文(Bounded Context)和划分子领域,核心子域,支撑子域,通用子域。
如下图是一个限界上下文,上下文关系,子域的一个示意图。
- 图中虚线是子域的边界,实线是限界上下文的边界
- 限界上下文之间的连线,代表了上下文关系。一般用“U”代表上游(供应商),"D"代表下游(客户)。
注意:子域是从要解决的问题的角度划分的,限界上下文是从解决方案的角度划分的。两者并不一定能一一对应或严格包含。
- 战术设计:主要是为每一个子领域进行设计,包括
- 识别子域的最核心的业务数据,称之为聚合根实体
- 描述聚合根实体,还需要哪些实体和值对象
- 识别这个子域的领域事件,以及这个这个事件的业务流程
- 识别触发领域事件的命令和发出命令的用户是谁
注意:子域不一定要做的很大,包含很多的功能,有时子域可以简单到只包含一个模块,一个算法。这种简单的子域在实现时可以被实施成一个模块,从复杂的核心域中分离出来。
分层、六边形和洋葱架构
分层架构思想是软件架构的一个重要而基本的思想。
软件分层架构的演进
在单机时代,主流的软件架构是MVC(Model View Control)架构,即数据模型-视图-控制器模式。这种架构最开始是在C/S体系下做界面UI时的架构。
后来局域网和web1.0的时代,服务器后端软件依据此思想演进成了控制层-服务层-数据访问层(Controller-Service-DAO)的3层模式,分别对应MVC中的View层-Control层-Model层。
领域建模的分层模型的思想,也是从MVC的这种架构演进出来的。

DDD中的分层架构
在DDD中,会经常听说六边形架构,洋葱架构和分层架构。示意图如下。

虽然表示的方式不同,但本质是一样的。都在强调一个分层的思想。
-
适配器层或用户接口层:负责接口转换,即是最外层请求处理类,将外部请求转化为内部API能理解的输入。
- 对于gRPC调用来说,是protobuf请求对象转换处理类;
- 对于REST接口可能是一个controller类;
- 对于消息机制来说,对应的是消息的监听器
- 如此采用端口适配器模式,可以不影响内部服务,只需在适配器层进行增改。
-
应用层:整个系统的功能外观,封装了领域层的复杂性并隐藏了其内部实现机制。映射到系统用例模型,意味着系统用例模型中的所有用例都可以在应用层接口中找到对应的方法。组织领域层完成这些功能。
-
领域层:实现业务逻辑。包括实体、值对象、领域服务、领域事件。
-
基础设施层:如数据库相关,消息总线等。这一层接收的是领域层处理后不会发生变化的,需要持久化的数据和信息
这里就回答了第1个问题
问题1. 为什么DDD的架构要表示成六边形和洋葱形呢?
- 这里主要强调各个接口的平等性,每一个外部用户都是通过接口和适配器与内部交互。例如,对外提供REST服务的API,外部用户是Web UI,由外部用户主动发起命令。而数据库的接口,外部用户是数据库,命令则由领域服务发起。虽然方向不同,但是在DDD中都认为是外部服务的接口。
- 类似于4+1视图中的用例视图的表示方法,一般把对领域服务发起命令的外部用户放在左边,而对接收领域服务命令的外部用户放在模型的右边。
- 因此,不管是六边形和洋葱形,其目的都是把系统分为外部和内部。
- 这里还有一层意思,就是 “依赖反转”或“依赖倒置” ,即外部的用户不依赖于领域服务的内部实现,而只依赖于接口定义。这样,可以有效的隔离领域内的业务逻辑和用户的业务逻辑,做到解耦。
关于六边形架构,还有一个问题
问题2. 从六边形图来看,有领域层的概念么?如果有的话,用户接口层能否直接访问领域层?
- 在《实现领域驱动设计》【文献6】中,六边形图中,中间的那个六边形“应用程序”就是应用层。其内的领域模型,就是领域层。
- 分层架构也有严格分层架构和松散型分层架构。在严格分层架构中,是不允许跨层调用的,需要跨层时,还需要一层包装,转接一下。在松散型分层架构中,由上到下可以跨层相调用。
- 一般的做法还是严格型的分层架构。这样有利于权限和逻辑控制,接口的管理
下面这个图更加形象的表示了六边形架构的原理

领域层、领域对象和领域服务
领域层是整个系统的核心,实现核心业务逻辑。领域层中包括
-
领域对象(Domain Object)
- 这个领域最核心的实体,称之为聚合根实体(Aggregate Root Entity)
- 和这个根实体包含的子实体对象(Entity)和值对象(Value)。
- 实体对象有唯一标识,判断是否是同一个实体,需要从ID来判断。
- 值对象只是一个值和操作这个值的方法,通常作为实体对象的属性。判断是否是同一个值,从值相等性判断。
- 操作这些对象的方法,简单的操作方法或只是本对象操作的原子方法放在实体或值的类里实现。
-
聚合(Aggregate)
- 根实体是领域层中最核心的对象,根实体往往比较复杂,包含很多属性和逻辑,一般会分为一些子实体和值
- 在操作根实体时(增删改查等),需要保证这些子实体,值可以一起提交,如果只提交了一部分,会造成数据的不一致
- 一般通过事务会话Transaction Session机制来保证提交的一致性,如果中间某个操作失败,会回滚所有同一事务内的操作
- 这个对数据一致性的封装就成为聚合。
- 往往一个领域内有一个或多个聚合包。每一个聚合包中都有一个聚合根实体。
-
除了这些实体和值这些领域对象之外,还有
-
领域服务:复杂业务逻辑,组合业务逻辑和跨多个实体或值对象的方法放在领域服务中。
-
领域事件:当方法执行后,需要通知其他领域做响应动作,这时会发出一个事件(通常通过消息总线,例如kafka),这个事件称为领域事件
-
-
工厂(Factory)
- 在一个业务逻辑比较复杂的领域中,根实体或子实体,值对象等,本身存在着一些业务和逻辑上的关系,约束,缺省值等,这时,创建一个实体或对象就会变得比较困难,这时,往往需要一个工厂类(Factory)或创建者(Builder)来一次性创建满足数据一致性的整个聚合中的实体,包括根实体和子实体。
-
资源库(Repository)
- 资源库是在领域对象和持久化数据对象之间的建立一个映射,封装数据持久化的接口。使得领域服务不需要考虑与数据库、消息或存储之类的数据持久化的连接,数据操作,事务会话等问题。
如下图,展示了在互联网开发中各个层的实现方式和各层包含的元素。

四种领域模型
在DDD中,针对领域中的实体对象,有四种实现方式,分别是:
- 失血模型:领域对象中只有对属性Getter和Setter的方法,所有的业务逻辑都在领域服务中实现
- 贫血模型:领域对象中除了对属性Getter和Setter的方法,还包括对本对象的一些原子操作,组合业务逻辑和复杂业务逻辑处理都在领域服务层中实现
- 充血模型:绝大多数业务逻辑都放在领域对象中处理,包括数据持久化的逻辑,领域服务层很薄,只封装事务和少量逻辑。
- 胀血模型:没有领域服务层,所有逻辑都在领域对象中实现。

这里,我们就可以解答问题3了。
问题3. 四种领域模型,应该优选那种模型?
在实际的使用中,一般都在贫血模型和充血模型中间选择。
- 当领域实体比较简单时,只有原子操作,没有复杂逻辑时,充血模型比较合适。
- 但是当实体之间存在复杂的,组合逻辑时,选择贫血模型就会比较好。
集成类型Model Integrity常用的架构模式
在微服务的实施中,有几个比较流行的架构模式。这里列出了常用的一些架构模板,虽然我们不能在嵌入式开发中直接使用这些模板,但是其中有很多的思想我们是可以借鉴的。
- 事件驱动架构(EDA) :基于消息总线的发布/订阅模型或事件流模型,对订阅的的消息进行捕获、通信、处理和持久保留。
- 命令和查询职责分离(CQRS) :把对象的操作分成命令(不返回结果,会改变对象状态)和查询(不改变对象状态,但返回数据)两个部分。用不同的方法来实现。
- 事件溯源(ES) :使用append-only的存储,把对数据的所有操作存储在一个事件表中,而不是直接更改数据库内容。这个事件可以作为领域事件通过消息总线发送出去,其他的服务进行响应,例如,可以更新数据库中物化视图(Materialized View)来提供快照数据。这种模式适合需要对过程进行记录,重放和审计的场景。
- 响应式架构和Actor模型(RAA) :响应式架构是指业务组件和功能由事件驱动,每个组件异步驱动,可以并行和分布式部署及运行。Actor是一种无锁的并发代理对象。Actor系统通过代理管理,任务管理和分发的框架(例如Akka)把任务分发给各Actor代理,并接收Actor代理执行的结果。
- 具象状态传输(REST):通过一个统一的URL定位到资源后,将操作通过动作词(GET/PUT/POST/DELETE)进行传递,从而让资源与操作相互隔离。
- 面向服务的架构(SOA):将应用程序的业务功能封装成“服务”,以接口和契约的形式暴露并提供给外界应用访问(通过交换消息),达到不同系统可重用的目的。
- 微服务架构(Microservices) :是指开发应用所用的一种架构形式。 通过微服务,可将大型应用分解成多个独立的组件,其中每个组件都有各自的责任领域。 在处理一个用户请求时,基于微服务的应用可能会调用许多内部微服务来共同生成其响应。 容器是微服务架构的绝佳示例,因为它们可让您专注于开发服务,而无需担心依赖项。
- 无服务器架构(Serverless) :一般来说,Serverless架构分为 Backend as a Service(BaaS,后端即服务) 和 Functions as a Service(FaaS,函数即服务) 两种技术。Baas的应用架构由大量第三方云服务器和API组成的,应用中关于服务器的逻辑和状态都由服务提供方来管理。FaaS指开发者可以直接将服务业务逻辑代码部署,运行在第三方提供的无状态计算容器中,开发者只需要编写业务代码即可,无需关注服务器,并且代码的执行它是由事件触发的。典型代表是AWS的Lambda服务
- 防腐层模式(Anti-corruption Layer) :通过在旧系统和新系统之间使用防腐层来隔离它们。该层转换两个系统之间的通信,允许旧系统保持不变,同时可以避免损害新应用程序的设计和技术方法。
微服务架构
下图所展示的是一个典型的微服务架构。每个业务逻辑都被分解为一个微服务(不同颜色的六边形块),微服务之间通过REST API通信。一些微服务也会向终端用户或客户端开放API接口。但通常情况下,这些客户端并不能直接访问后台微服务,而是通过API Gateway来传递请求。API Gateway一般负责服务路由、负载均衡、缓存、访问控制和鉴权等任务。
微服务架构有什么优势
在2010年开始,掀起了异常从单一式架构到微服务跃迁的热潮,越来越多的公司花费了大量的人力物力财力来完成此次架构跃迁,那么与单一式架构相比,微服务架构有什么优势,值得大家花这么大的精力去做迁移呢?
下图是单一式架构和微服务架构的比较

总结:微服务使得独立部署,独立升级和独立扩展变得十分的容易,新产品上市的速度大大加快,软件系统的TCO(Total cost of Ownership总体拥有成本)成本也会因此而降低。
DDD和微服务的关系
从上面微服务的体系架构图中,我们可以看到,微服务的体系架构与DDD中的分领域,分层,领域事件驱动,数据和事务一致性等等原则是完全吻合和一致的。
- 每一个微服务就是一个领域或子域,图中核心区域的四个六边形颜色块就是核心域,而下面的Management, Service Discovery等都是通用子域。
- API 网关,包括了暴露出来的RESTful API,负载均衡,鉴权等是接口层和应用层
- 基础设施层被包在了微服务中。
二者之间的关系可以理解为:DDD是设计方法,而设计出来的架构就是微服务架构。
3. 在嵌入式系统中使用DDD Lite进行设计
嵌入式系统中使用DDD,有很多地方可以借鉴互联网架构模式,也有很多不同点。 首先,我们看一下嵌入式系统的一般特征。

- Linux Kernel是一个宏内核,内核程序都在一个进程空间内。由内核驱动程序负责驱动硬件,包括SoC芯片和设备。
- HAL层包含对硬件的抽象,提供接口给上层的lib和应用框架层调用,对内核程序调用一般是通过设备节点的ioctl socket进行通讯,内核态与用户态的跨界内存共享可以通过ashmem来处理
- 用户态的Lib层和应用框架层作为HAL层的用户,调用HAL层的接口
- 用户态可以支持多进程,支持C++,内核态只支持C
- 用户和服务都在一个嵌入式系统中,没有前端和后端通过互联网连接的结构。
没有免费午餐
在最优化理论界,有一个著名的定理,No Free Lunch(NFL)没有免费午餐定理【9】,意思是没有任何一种算法或模式可以在所有场景中都能产生准确的结果。
同样,软件架构和设计模式也都需要根据场景做出调整,不能1:1照搬。关于DDD,有很多的材料、视频和赋能宣讲,还包括多彩建模等等。也有很多人试图在嵌入式开发中引入DDD,但是同时也有很多人产生了疑惑,DDD是从互联网开发和基于微服务的架构中产生和发展的,他是否能够适合嵌入式开发?
我的回答是,DDD的设计思想、建模方法以及架构模式中的很多内容都可以在嵌入式开发中应用,但是需要一些调整和适应,不能简单的照搬。
因此,为了适应嵌入式系统的设计,尤其是重构的设计,我们参考了业界的一些优秀实践,提出了轻量级DDD,即DDD Lite的设计模式。
DDD Lite的设计模式
下面,我们以显示子系统作为例子,看一下如何使用DDD来进行建模。整个建模分为7步,每一步的第一个英文字母串在一起就是 BUSLANE(公交快速道). 由以下7步组成:
- B - Boundary of Domain 识别域边界
- U - Use Case 用例
- S - Subdomain 划分子域
- L - Layered Architecture 分层结构
- A - Architecture Pattern 架构模式的选择
- N - Non-sticky design 非粘性设计
- E - Entity UML Modeling 实体UML建模
第一步:识别领域边界(Boundary of Domain)
我们在重构时,一般是针对一个嵌入式系统中的一部分或一个子系统进行重构。在重构时需要遵循一个原则:即无损替换原则。就是只替换这一部分,保持对外的接口不变,整个嵌入式系统在重构之后依然可以工作,不产生功能和性能上的损失。这步工作可以分成以下几个步骤:
- 识别出重构部分的边界:包括上下左右边界,这个边界可以称之为领域边界(Boundary of Domain )。(这里没有用boundary of context,为了避免与bounded context 混淆)这里领域边界与4+1视图中的上下文模型(UML Context Diagram)中的边界(Boundary)是一个概念。
- 明确边界的功能目标和看护:对边界建立基于接口的测试看护体系,来最终验证重构是否满足需求。
- 明确边界的性能目标和看护:对边界内的子系统,性能方面需要达到什么目标?怎么验证。
这里,我们把DDD的六边形或洋葱形的架构图改一下,改成一个长方形。

-
北向:提供给上层的接口,即向上提供的接口。
-
南向:调用下层的接口,即向下的调用接口
-
西向:提供给同层其他子系统的接口,即向左提供的接口
-
东向:调用同层其他子系统的接口,即向右调用的接口
我们在识别了上下左右的外部用户和接口之后,这个边界内的部分,我们就可以作为一个领域来进行建模。进一步划分子域和进行战术设计。
例如,在显示子系统中,北向或向上的接口有
SurfaceFlinger的接口 - hwc
Linux wayland的接口 - drm_client
displayEffect的接口 - displayEngine
南向接口基本上就是输出给屏驱动

第二步:建立用例视图(Use Case View)
这一步的目标是让需求清晰化,为后面的识别限界上下文和聚合提供一个完整的输入列表。在DDD的战略层面的建模,就是要和领域专家一起,带领团队搞清楚需求(从领域事件风暴开始)。而对于一个重构项目来说,需求基本上是清楚的,不需要重新头脑风暴来建立。而是需要一种好的工具来清晰的表达出来,让每个参与人都清楚需求。这里,选择用例视图来梳理和展示需求是比较好的办法,而且与我司的4+1视图,端到端追溯等要求是一致的。
如“架构设计4+1视图实践分享(2):我们如何设计用例视图”【10】中所讲述的方法,我们通过从需求的特性建立用例视图。用例视图的表现方式有多种,我们一般采用三种方式:
-
UML用例图:UML用例图往往只需要画出最关键的不超过20个用例。可以分成概要层和用户目标层两层来画。注意:UML用例图中的用例(即椭圆型)往往是一个简单的短语,并不能准确的表达系统的需求,而且不能画太多的用例,因此,我们需要用例表和用例描述(Spec)来补充描述。

-
用例表:把系统中所有的用例,按照外部用户分组,列在一张表里,除了用例名,还有用例的描述。比UML可以更加全面的展示用例。

-
用例描述:是对每一个用例的详细的描述,包括用例的名称,前置条件,后置条件,基本流程,备选流程,异常流程。有了用例描述Spec,工程师可以照此开始编码实现。

例如,在显示子系统中,叠加的UML用例图可以表示为
部分用例表如下:


第三步:建立限界上下文和划分子域(Subdomain)
建立限界上下文(Bounded Context)
从第二步中,我们得到了系统最关键的用例,之后,我们需要分析每个用例,识别出每个用例中,是哪个命令(或接口)触发此用例,和这个用例中的核心的实体是什么。在这个过程中,我们会发现,有一些用例的命令和实体都是一样的,这时,这些用例就应该被合并到一个限界上下文中。
例如,在显示子系统中,各种叠加的用例,其命令都是由送显这一个动作发起,其根实体都是帧,每一个叠加的动作都是针对于帧来说的,而且不能都丢掉其中的图层,这时就有了数据一致性的需求,因此帧就可以作为聚合根实体。
此外,还包括了图层等子实体,以及图层的格式,大小,颜色等值实体。

上下文关系(Context Map)
在《领域驱动设计精要》【7】中,作者给出了9种限界上下文映射关系,这里,我们在嵌入式系统种主要讨论其中的5种:
-
客户 - 供应商关系( Customer-Supplier): 描述的是两个限界上下文之间一种调用关系:供应商位于上游(U ),客户位于下游(D )。
-
客户与供应商之间需要指定接口契约,由供应商来根据契约向客户提供满足契约的数据和服务
-
存在这种集成关系的团队常常会采用一种被称为消费者驱动契约( Consumer Driven Contract, CDC )的实践,通过契约测试来保证上游(生产者或供应商) 和下游(消费者或客户〉之间的协作。而利用一些工具(如Pact ) ,客户可以在进行测试时,将对供应商接口的期望记录下来,并将其变成供应商的接口测试,作为供应商持续集成流水线的一部分持续地进行验证。
-
在嵌入式系统中的实践:供应商需要提供一个接口头文件,其中包含一个接口类,放到公共的include目录下。在接口类中可以加入接口的约束验证。而在接口头文件中暴露的接口需要遵循迪米特原则(最小知识原则),只需要暴露最小的接口集,而实现的细节需要放在实现类中。命名的方式一般是 xxxInterface 类和 xxxImpl 类。例如,在显示重构中的networkGenerator类,在公共include目录下,有一个NetworkGenerator.h头文件,但是实现的细节,都在NetworkGeneratorWrapper类中

-
-
跟随者( Conformist )上游的团队或限界上下文没有动机和理由满足下游团队的具体需求,下游团队也无法投入资源去翻译上游模型的通用语言来适应自己的特定需求,只能是顺应着上游的模型来开发。
- 驱动开发团队与芯片团队之间的关系就是跟随着的关系。驱动只能按照芯片的规格和约束来做。
-
防腐层( Anticorruption Layer )是最具防御性的上下文映射关系, 下游团队在其通用语言(模型)和位于它上游的通用语言(模型)之间创建了一个翻译层。
- 这种防腐层关系在嵌入式系统中经常使用,尤其是在重构时需要保持向前兼容,做接口转换和翻译。
-
已发布语言( Published Language )是一种有着丰富文档的信息交换语言,可以被许多消费方的限界上下文简单地使用和翻译。
- 需要读写信息的消费者们可以把共享语言翻译成自己的语言, 反之亦然
- 这种己发布语言可以用XML Schema 、JSON Schema 或更佳的序列化格式定义,比如Protobuf 或Avro 。
-
消息机制:消息机制由订阅-发布模式和定向消息发布等两种模式
- 发布-订阅模式(Message Bus or Pub-Sub):通过客户端限界上下文订阅由它自己或另一个限界上下文发布的领域事件( Domain Events ) 来完成的。
- 使用消息机制是最健壮的集成方法之一,因为发布者和订阅者可以做到充分解耦,而且无阻塞
- 消息可以触发多个订阅者响应,来完成特定的动作。这个也就是EDA 事件驱动的架构模型
- 例如,Graphics BufferQueue就是一种嵌入式的发布-订阅模式。通过生产者画图形,添加到队列中,timeline keeper来根据时间线的设定触发那些绑定在这个图形buffer的消费者,同时,通过Fence机制来避免资源的冲突。
- 定向发布模式:也可以叫做P2P模式,一对一发送模式。只有一个消息发送者和一个消息接收者。P2P模式下,发送者无需事先约定传输消息的Topic,发送者可以直接按照规范发送消息到目标的接收者。接收者无需事先订阅即可接收消息,从而简化接收者的程序逻辑,节省订阅成本。
- Actor模式可以理解为是一种定向发布模式,Actor System定向发送任务给每个worker的邮箱,并从worker那里得到运行结果。
- 定向发布模式,发送端可以控制发送的时序和逻辑。而发布-订阅模式,则是一种无时序的响应模式。
- IoT物联网中经常运用此模式来完成IoT设备的数据上报和指令下发。MQTT是其中一种应用最广泛的一个消息协议和中间件。
- 发布-订阅模式(Message Bus or Pub-Sub):通过客户端限界上下文订阅由它自己或另一个限界上下文发布的领域事件( Domain Events ) 来完成的。
显示子系统部分上下文关系图如下:

注意: 在开始建模时,我们不太可能一下子把整个系统的全貌和各个上下文之间的关系搞得非常清楚和精确。这个过程是一个逐步修正的过程。“Context Map上下文关系图是一个识别限界上下文边界的工具,通常是在一块白板上边讨论边添加内容,它并不是一个严格定义的UML图。它可以让我们对各个上下文之间的关系进行一个模糊的映射,而且从某种程度上说,一定的模糊度是必要的”。【5】
划分子域(Sub Domain)
从第2章DDD的要点介绍中,可以知道一般我们会对领域进一步划分为子域,子域又分为三种,核心域,支撑子域,通用子域。我们在实际的建模中,应该如何华为子域呢?
我们还是根据第二步用例视图中得到的用例,来划分一下限界上下文 BC,然后把BC按照功能组合并成子域。例如,在显示子系统中,叠加预处理,叠加送显,送显的通道选择等都分别是限界上下文,但是这些BC都属于叠加子域。
得到了子域的划分之后,如何判断是核心子域还是其他的呢?主要看这个子域是否是核心的业务。
例如,显示子系统,核心的业务是叠加,效果,连接,和屏这个业务链。在这个业务链上的子域都是核心子域,因为这些子域可以体现出这个子系统的竞争力。而配置,日志,DFX维测系统这些公用的功能,都应该属于通用子域。而屏的驱动程序,MCU小核或用到的二进制包等这些外部依赖或核心业务之外的部分,都属于支撑子域。
第四步:对子域进行分层设计(Layered Architecture)
在第三步中,我们划分好了子域,接下来,我们按照DDD的分层架构的思想,对子域进行架构。例如,对显示叠加子域,我们可以用分层的架构来对子域进行划分。左边是严格分层的架构,右边是六边形架构(或洋葱架构)。我们一起看一下:
- 接口层:包括了SurfaceFlinger对接的接口hwc和Linux Wayland接口的DRM client. 主要的作用是一个适配器的功能,接收外部客户发出的命令,然后调用应用层进行处理,并且把结果返回给外部客户。
- 应用层:接收到接口层的命令后,对每个显示设备,调用领域层的服务进行预处理和送显,然后,把结果返回给接口层。
- 领域层:这一层包含整个子域的核心逻辑
- 重构之前很多的业务逻辑被实现在了内核层,这样做会使得内核过于庞大复杂,而且由于开源责任,需要公开内核源码,容易暴漏业务关键技术。
- 重构后,核心业务逻辑被放在了HAL层。这一层主要负责选择合适的策略,管理算子状态,生成叠加网络,进而生成cmdlist。
- 基础设施层:基础设施层通常理解为把数据和信息进行持久化。即数据传或信息送给基础设施层后,就不会发生变化了。
- 那么在嵌入式系统中,我们在领域层可以处理业务逻辑,包括选择叠加策略,生成叠加网络和生成cmdlist。这些实体在领域层是变量,即可以发生变化,例如,在选择叠加策略时,我们需要检查算子可用状态和场景,来确定每个图层是怎么叠加的,这里,需要尝试走在线,不行走离线,再不行走GPU等,这是一个变化和尝试的过程。一旦这个过程结束了,那么叠加策略和命令已经确定了,就需要驱动芯片来执行了。这时,数据,图片和命令就已经确定了,不会改变了。
- 基础设施层,按照洋葱模型,也是另一个适配器,外部的用户是芯片或连接器(MIPI/DP)。这里,基于依赖倒置原则,我们把它分成了两个子层,内核接口层,主要是内核驱动的设备节点。内核层是真正的内核驱动的实现

第五步:为子域选择合适架构模式(Architecture Pattern)
这里,架构模式除了我们知道的23种设计模式之外,我们着重讨论以下互联网开发的一些模式,以及如何在嵌入式系统中使用。
事件驱动架构(EDA)
基于消息总线的发布/订阅模型或事件流模型,对订阅的的消息进行捕获、通信、处理和持久保留。
事件驱动编程通常只是用一个执行过程,在处理多任务的时候,事件驱动编程是使用协作式处理任务,而不是多线程的抢占式。事件驱动简洁易用,只需要注册感兴趣的事件,在回调中设计逻辑就可以了。在调用的过程中,事件循环器(Event Loop)在等待事件的发生,跟着调用处理器。事件处理器不是抢占式的,处理器一般只有很短的生命周期。
Linux操作系统本身其实也是基于事件驱动架构的。
事件驱动编程的优势
- 在大部分的应用场景中,事件编程优于多线程编程。
- 相对于多线程编程来讲,事件驱动编程比较容易,复杂度低,开发者乐于接受。
- 大多数的GUI框架,都是使用事件驱动编程架构的。每一个事件会绑定一个处理器,这些事件通常是点击按钮,选择菜单,等等。处理器来实现具体的行为逻辑。
- 事件驱动经常使用在I/O框架中,可以很好的实现I/O复用。很多高性能的I/O框架都是使用事件驱动模型的。
- 易于调试。时间依赖只和事件有关系,而不是内部调度。问题容易暴露。
事件驱动编程的劣势
- 如果处理器占用时间较长,那会阻塞应用程序的响应。
- 无法通过时间来维护本地状态,因为处理器必须返回。
- 通常在单CPU环境下,比多线程编程要快,因为没有锁的因素,没有线程切换的损耗。CPU不是并发的,这样的话就不适合用在一些科学计算的应用中。
那么, 在我们在嵌入式开发中,有没有一个可以参考的EDA的例子?
【例子1】显示系统中用的DMA-Fence

这个例子的实现,实际上是一种中断驱动的架构,从大的架构思想上,也是事件驱动架构的一种。其基本原理是:
-
类似graphics buffer queue, 一次性申请多块DMA Buffer或将来自其他模块的DMA buffer,加入到队列中,需要使用buffer时到队列中去申请。不用时释放回到队列中
-
注册Buffer的消费者和回调:当一块buffer申请到后,注册此buffer的消费者,回调函数和回调时间点,并加回到队列中
-
DMA Buffer队列管理者负责建立和管理时间线(timeline),每一次中断,时间线加1,同时比较队列中各buffer的注册消费者的时间点和fence状态是否可以触发(Signal),如果满足,则触发回调函数
-
消费者的回调函数被触发,则加fence,开始操作buffer
-
操作结束,释放控制权,减fence
-
没有fence的buffer可以被分配给下一个生产者
具体可以参见利用fence框架支持生产者消费者模型同步技术
注意:这种基于队列,回调函数,触发Signal和Fence的模式,可以很好的解决多个进程对同一资源的操作时的冲突和时序的问题。
【例子2】基于消息总线的软件框架
另外一个可以参考的例子是基于消息总线的软件框架。这个框架可以支持进程内、跨进程和基于网络三种不同的消息通道。三种不同的消息通道使用一个消息总线管理器管理,收发消息使用统一的接口。
这个例子可以说是一个标准的基于消息总线发布-订阅(pub-sub)模式的事件驱动架构。
具体可以参见“基于ZeroMQ的嵌入式跨平台消息总线软件框架”。

响应式架构和Actor模型(RAA)
响应式架构是指业务组件和功能由事件驱动,每个组件异步驱动,可以并行和分布式部署及运行。Actor是一种无锁的并发代理对象。Actor系统通过代理管理,任务管理和分发的框架(例如Akka)把任务分发给各Actor代理,并接收Actor代理执行的结果。
- Camera组的实践(待补充)
命令和查询职责分离(CQRS)
把对象的操作分成命令(不返回结果,会改变对象状态)和查询(不改变对象状态,但返回数据)两个部分。分成不同的类来实现。每个类只负责单一的职责。这和我们所说的SOLID中的单一责任原则的思想是一致的。
深入分析一下,CQRS有2个层面的好处或应用场景:
- 减少不稳定依赖:每个职责(查询和命令)的依赖对象不同,所以可能对该类产生的变化需求的事件和方向也不同,分离后,可以把每个职责的不稳定依赖降低到一个方向或维度。
- 实现冷热模块和数据的分离:每个职责的热度不同,有可能造成负载不同。如果不进行分离,那么这个模块会处于两个热度叠加的状态。而进行了责任分离后,两个模块的热度都会有所降低,而且热度大的职责可以给与更多的资源,来优化效率。
【例子1】Vulkan Renderpass 查询与控制分离
由 付强 提供
在改造前,Renderpass类负责两个方面的工作:
- 关联Vulkan 标准,接收来自Vulkan API的状态查询指令,返回FrameBuffer和Pipeline等相关对象的状态
- 工作流逻辑控制,通过commandBuffer控制流程和desc的配置
这两个方面的工作,
- 一个是负责状态查询,并不修改内部各模块的状态。这个部分要与vulkan API标准进行关联,当API标准升级时,这个部分也要而做出相应的改变。
- 而另一部分工作是命令工作,只负责按照workflow Logic组织命令,发出命令。这部分工作与Vulkan API的标准无关,与内部的模块的逻辑相关联。

这个模块的两个方面的变化不是同步的,任何一个方面发生了变化,这个类就要改动,而这也违反了单一责任原则(SRP)。
在经过了CQRS改造后,把原来的Renderpass类分成了两个类,一个是Renderpass负责第一个职责,对接Vulkan标准,处理状态查询。另一个新分出来的类RenderpassInstance负责第二个职责,控制业务流和desc配置。
【例子2】冷热分离的例子
(例子待补充)
面向服务的架构(SOA)
将应用程序的业务功能封装成“服务”,以接口和契约的形式暴露并提供给外界应用访问(通过交换消息),达到不同系统可重用的目的。
(例子待补充)
防腐层模式(Anti-corruption Layer)
通过在旧系统和新系统之间使用防腐层来隔离它们。该层转换两个系统之间的通信,允许旧系统保持不变,同时可以避免损害新应用程序的设计和技术方法。
第六步:子域之间的非粘性连接和非耦合接口(Non-sticky Connection Non-coupled Interface)
非粘性连接设计
粘性会话(Sticky Session)在互联网领域中指负载均衡器为一个客户client,分配一个固定的服务器,一直服务该客户,直到会话结束。粘性会话的好处是用户体验会比较好,比较稳定,而且网络资源的优化也比较容易。
但是,问题也很明显,就是一个客户独占了一个资源不释放,当这样的会话越来越多时,服务器负载就会处于不均衡的状态。
对应于嵌入式,我们也有类似的问题,例如,在重构前的显示系统中,软件为每一个显示设备分配了一个固定的硬件通道,只要是这个设备过来的图层,都会走这个通道,通道中的算子也是固定的,即便是这个设备没有过来任何图层,这个通道也依然保留,不能给其他设备使用。
这个问题,我们可以借鉴互联网的名词,称之为粘性连接设计。即叠加子域和外部客户之间有一个粘性连接。
非粘性连接设计,就是要打破这种固定通道,固定算子的模式,而采用配置驱动开发(CDD)的模式,预先设定几种叠加模式,由策略管理器来决定选用那种模式,选用了模式后,我们可以采用静态的算子通道配置表或动态生成算子网络的方式,来动态优化算子的负载。

非耦合接口
子域之间的连接,都要遵循依赖反转原则,即:
- 高层次的模块不应该依赖于低层次的模块,两者都应该依赖于抽象接口;
- 抽象接口不应该依赖于具体实现。而具体实现则应该依赖于抽象接口。
这种接口,我们就可以称为非耦合接口。
非耦合接口还有一个重要的原则,就是契约式设计 Design By Contract:
- 对于Client-Server方式的调用,把server是现成一个接口类和实现类的方式,把双方的调用约定(前置条件,动作和后置条件)放置在接口类中。
- 由接口类来约束client的调用和server动作和返回的行为
- 契约转包:当接口类由另一个实现时,新的实现类可以有不同的前置条件,动作和后置条件,但是他的前置条件必须弱于接口类的条件,而后置条件必须强于接口类的后置条件
- 遵循里氏替换原则:一个类的使用者可以使用这个类的子类,即子类中不应该出现与父类不一致的行为。
在这种契约式编程中,我们对父类进行测试,断言判断来约束整个子类的行为模式。
如何来理解这种契约转包呢?
契约转包的意思是,接口类中规定了最基本的约束,当一个实现类需要实现自己独有的约束时,它可以增加约束。但是需要满足里氏替换原则-也就是子类可以替换父类的作用。子类可以处理的情况需要包含父类的所有情况。那么子类约束的前置条件需要弱于父类。后置条件是相反的。后置条件的意思是,当类处理约束完毕后,需要判断它的输出是否实现了所有的后置条件,那么为了保证所有父类可以处理的情况被子类处理后不会产生问题,子类对输出的要求标准应该包含父类的后置条件。例如,父类的输出需要满足2项条件,而子类的输出在这2个条件的基础上,需要满足第3条。那么如果子类替换父类时,输出的结果标准高于父类的要求,也就是父类的后置约束一定会满足。
第七步:域实体和域服务的UML建模(Entity UML Modeling)
我们通过前六步,已经把一个系统分解到了子域,子域中已经识别出了根实体,子实体,值实体和领域服务,下一步要做的就是把这些设计进一步细化,达到可以编码的程度,进而可以使用工具生成代码。
从设计到开发的衔接
软件开发时,通常是架构师和领域专家,高级开发人员一起,把整个系统从需求特性分析和设计架构,设计到L2层(L2层是组件层,除了组件,还需要设计到子组件,以及组件中的一些关键模块)。这时,架构师会召开评审会,在这个层次上论证系统架构的可行性。
这个评审过了之后,就会进入到编码阶段,在编码阶段,会把一个子组件或模块交给一个核心开发人员,接着做编码层面的设计,完成关键的UML建模(类,时序和组件图),然后再交给架构师评审,评审通过后,才可以开始编码。
为什么还需要用UML建模
我们就要用到部分UML图作为工具来帮助我们整理清思路,清楚的表达划分为几个类,每个类之间的关系,以及类之间的调用顺序等一些实现层面的问题。
有人可能会有疑问,DDD本身就是一种架构设计的方法,UML也是一种建模方法,两者之间有什么关系?为什么用了DDD设计,还需要UML建模?
这里,我给出我的看法:
- 从作用上看:
- 领域驱动设计是在软件需求分析和设计架构上提出的一些做法。
- UML是表达分析和设计的可选表示法。因为一些UML图在表达类的构成,关系,时序方面可以非常清晰和严谨,还有很多的工具可以使用,因此,选用UML来作为编码层面的工具是十分合适的。
- 从阶段上看:
- 领域驱动设计是架构设计层面的方法(从需求分析到L2的设计)这个工作往往是架构师完成的。
- UML是开发设计层面用到的分析和表达工具,是开发人员需要用的。
如何建模
这里,主要用三个UML diagram。例如,显示子系统中的预处理和送显的部分组件图,时序图和类图
Component Diagram 组件图

Sequence Diagram 时序图

Class Diagram 类图

到这里,我们看一下第4个问题:
问题4:领域和功能模块有啥区别?
- 领域是一个更高层面的封装,里面包括了实体对象,值对象,领域服务,领域事件还有资源库等多个部分,这每个部分的实现都是一个或多个类,最终,通过服务类来进行跨实体和值进行业务操作,完成领域的业务逻辑。所以可以说领域包含了功能模块。(在极致的面向对象里,所有的功能都是类来包装的,功能是包装在类里的)
- 如果从需求分析的角度,领域与之前的功能群组(Function Group, 即在单一式架构下,跨层的属于同一个业务的模块组成功能群组)的概念类似。实现方式不同,在DDD的设计中,属于同一个业务的部分是被独立封装在一个域中,属于紧密集成的关系。而在单一式架构的功能群组中,每个功能组不同层的部分与同层的属于其他功能组的模块紧密集成,而功能组只是一个逻辑的概念。
4. 总结
本文以显示重构为例子,提出了将轻量级的领域驱动设计(DDD Lite)应用于嵌入式系统开发的模式,提出了BUSLANE的7步建模方法,这种建模方法是一套比较具体的,具有实际指导意义的方法,希望可以帮助大家提升对DDD软件设计应用的理解。
希望在本文结束时,大家对问题5和6有了一定的解答。
问题5. DDD看上去与嵌入式开发挺契合的,但是结合业务,怎么理解和运用?
问题6. DDD的格局有点大,思维的方式很好,但是套到我们的驱动开发上,是否能很好的匹配?
- 本文中所提出的BUSLANE七步建模的方法,应该是可以落地的一套可实施的方法。
- 但是在运用到其他的子系统过程中,可能会有一些需要适配的地方。我们可以按照DDD的思想,结合业务实际,对DDD进行一定的改造,使之适合我们的开发的实践。
参考文献:
【2】https://martinfowler.com/articles/microservices.html
【3】https://www.n-ix.com/microservices-vs-monolith-which-architecture-best-choice-your-business/
【4】https://hjwjw.github.io/posts/156e5ee9/
【5】《领域驱动设计》,Eric Evans, 2004
【6】《实现领域驱动设计》,Vaughn Vernon
【7】《领域驱动设计精粹》,Vaughn Vernon
【8】cloud design pattern, https://iambowen.gitbooks.io/cloud-design-pattern/content/
【9】 Wolpert, D.H., Macready, W.G. (1997), “No Free Lunch Theorems for Optimization”, IEEE Transactions on Evolutionary Computation 1, 67.
【10】Hongjie Liu, Danny Song, 架构设计4+1视图实践分享(2):我们如何设计用例视图, http://3ms.huawei.com/km/blogs/details/9714139?l=zh-cn
【11】https://c4model.com/
【12】Evans, 领域驱动设计,材料见附件“精简版(中文)DDD_Domain_Driven_Design.pdf”
【13】 Peter Coad,Eric Lefebvre,Jeff De Luca著,彩色UML建模(四色原型)Object Modeling in Color