本年度科技圈这场里程碑级大战,还在持续白热化!
刚刚,Sam Altman罕见地发声了,连发两条推文。在马斯克闹出起诉风波后,Altman一直保持缄默。因此,这两条推文应该是全公司经过了深思熟虑的结果——
第一条:飓风已经愈来愈猛烈,但风暴中心却仍然保持着平静;第二条:这一切都发生过,这一切都还将再次发生。
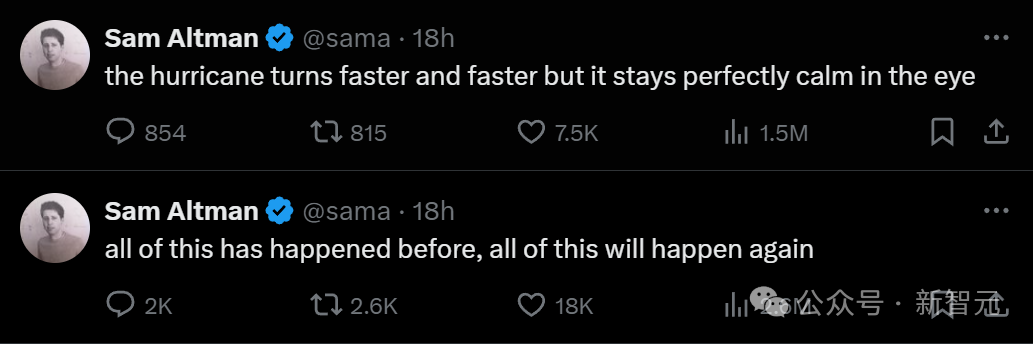
在Altman看来,目前发生的一切不过是新瓶装旧酒,不断在重演的故事罢了。
但传闻中的Q*大模型和AGI技术,已经让全世界谈之色变。
本案最大未解之谜:Ilya究竟看到了什么
在用ChatGPT和Sora在全世界掀起飓风之后,OpenAI真的能如Altman所说,在风暴中心保持平静吗?
恐怕潘多拉的魔盒已经打开,在我们看不到的角落里,蝴蝶效应已经产生。
马斯克起诉OpenAI案最大的未解之谜就是——Ilya Sutskever究竟看到了什么?
去年宫斗风波发生时,马斯克就表示很担心:
Ilya Sutskever是一个拥有良好道德的人,并不寻求权力。除非他认为有必要,否则绝不会采取如此过激的行动。
让我们把时间线倒回,好好复盘一下这桩起诉案发生之前,Altman的一言一行,都埋下了哪些线索。
在2023年11月,就在Altman被董事会解雇的前一天,他在APEC会议上曾有一次令人不寒而栗的发言,暗示了OpenAI已经开发出了比GPT-4更强大、更难以想象的东西,远超人们的期待。
Altman说:
模型的能力将会有一个无人预料到的飞跃。与人们的预期不同,这个飞跃是惊人的!
现在正在发生的技术变革,将彻底改变我们生活方式、经济和社会结构以及其他可能性限制……这在OpenAI的历史上有四次 ,而最近一次,就是在过去几周内的。
在拨开无知的面纱和探索未知的边界时,我有幸在场, 这是我职业生涯中的荣幸。
在这篇演讲播送的时候,我们还对Q*一无所知。紧接着第二天,OpenAI的宫斗风波震惊全世界,Altman被赶下台,而Ilya Sutskever应该是「看到了一些东西」。
那几天里,「Ilya Sutskever究竟看到了什么」引起了全网的猜测和恐慌
宫斗风波第四天时,OpenAI秘密的AI模型突破Q*被泄露。据说OpenAI的两位研究员Jakub Pachocki和Symon Sidor,利用Ilya Sutskever的工作成果做出了Q*。
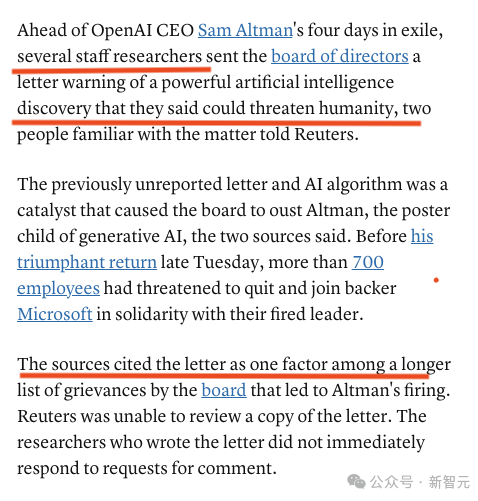
同时大家发现,在Altman被解雇之下,OpenAI的研究人员曾给董事会发出一封信,警告一项「可能威胁人类」的全新AI技术的新发现。
这封此前从未报道过的信,也是董事会最终罢免Altman的导火索之一。
那么,Ilya Sutskever看到的,就是这项发现吗?或者说,Ilya看到的,指的就是Q*大模型吗?
而到了2024年2月,马斯克正式起诉OpenAI,这记回旋镖正中眉心。
马斯克认为,GPT-4是一个AGI算法,所以OpenAI已经实现了AGI,因此这超出了OpenAI和微软协议的范围,这项协议仅适用于AGI出现之前的技术。

「基于所掌握的信息和相信为真的内容,OpenAI目前正在开发一种名为Q*的模型,该模型对AGI具有更强的主张」
起诉书中还说,看起来Q*很有可能会被OpenAI开发成一个AGI,更清晰、更引人注目。

Q*这款大模型,真的值得马斯克如此大费周章、如临大敌吗?
根据目前泄露出来的信息,Q*的能力,是能够解决小学阶段的数学问题。虽然在大多数人看来,这并不是什么令人印象深刻的事,但这的确是朝向AGI迈出的一大步,堪称重要的技术里程碑。
因为Q*解决的,是以前从未见过的数学题。
Ilya Sutskever做出的突破,使OpenAI不再受限于获取足够的高质量数据来训练新模型,而这,正是开发下一代模型的主要障碍。
那几周内,Q*的演示一直在OpenAI内部流传,所有人都很震惊。
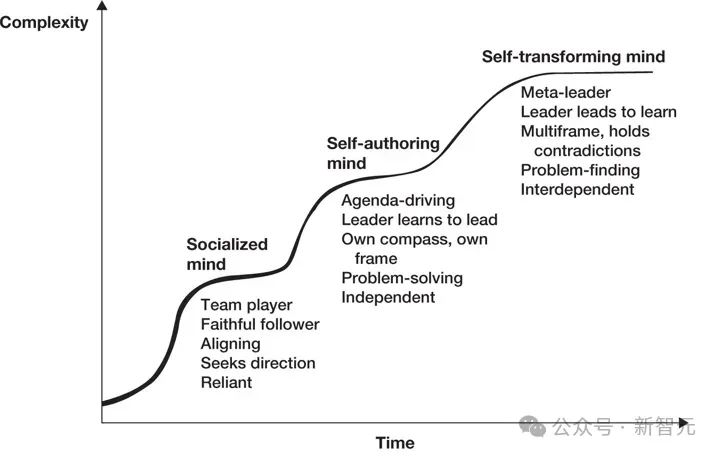
据悉,OpenAI的一些人认为Q*可能是OpenAI在AGI上取得的一个突破。
AGI的定义是:「在最具经济价值的任务中,超越人类的自主系统」
所以Q*会威胁人类吗?
现在,公众仍然不清楚细节,马斯克似乎认为答案是肯定的,而「看到了什么」的Ilya Sutskever,至今依然是去向不明。
回头翻看Ilya Sutskever的社交媒体,至今还停留在这一条2023年12月15日的推文,从此再无任何动态。
网友:Ilya看到的东西,就是「奥本海默时刻」
现在,已经有人把「Ilya看到那个东西」的时刻,归结为「奥本海默时刻」相类似的东西,并且那个东西的危险和强大程度比原子弹还要高出数百万倍。
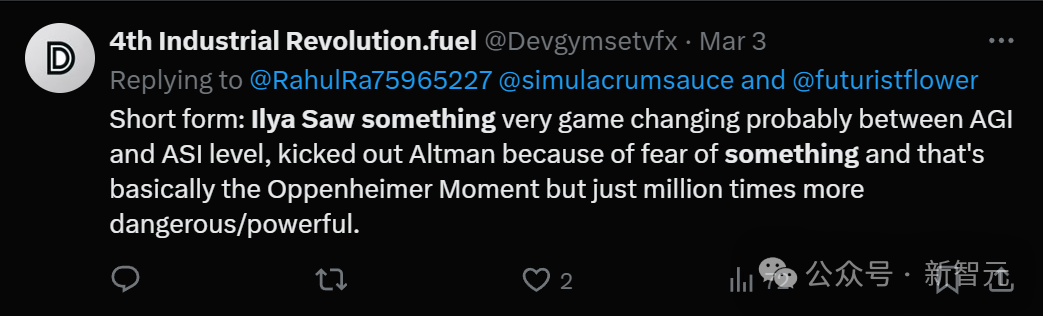
大家都在推测,Ilya Sutskever看到的这个东西改变了游戏规则,级别在AGI和ASI之间,因为他太害怕了,所以踢出了Altman。
网友们还猜测,马斯克现在下这一盘大棋,就是为了搞清Ilya Sutskever究竟看到了什么,来感受一把真正的AGI。

Ilya Sutskever看到了什么可怕的东西?
网友们一致认为,或许普通人看到的只是AI系统而已,但Ilya Sutskever看到的,是AI的突破性发现。
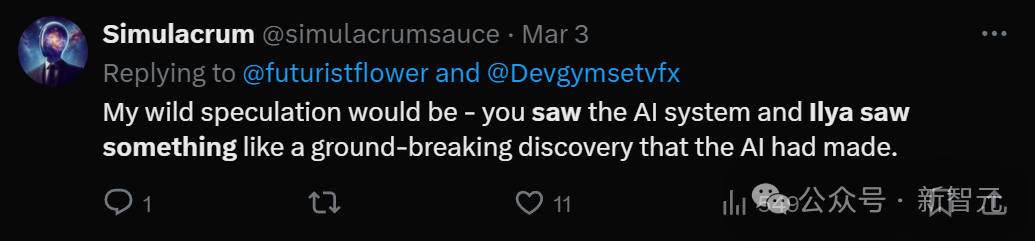
很多人相信,就是Ilya Sutskever看到的就是Q*,随后有了一些新发现。

因为Ilya Sutskever不是个关心政治的人,他肯定是看到了相当危险的东西,连同把OpenAI董事会都给吓到了。
或许他看到的只是Sora生成的视频?但直觉告诉我们应该不只如此,Sora的表现今天我们已经见识了。
但是从此,OpenAI发生了一场大震荡,削弱了GPT的性能,削弱了未来推出的模型。
地下室里究竟藏有什么??!
奥特曼紧急澄清:AI是效率工具,不是新物种!
面对外界的这番恐慌情绪,Altman在最近接受《The Advocate》杂志采访时急忙解释道:很多人都对AI误解了,他们甚至分不清AI到底是一种「生物」还是「工具」。

在他看来,将AI视为科幻电影中的生物角色确实更吸引人。但如果真的用了ChatGPT,就会明白它只是一个工具而已。AI目前更多是一套基于数据和数学的系统,能够产生统计上可能的结果,而不是「生物」这种全新的生命形态。
在目前全社会对OpenAI的担忧情绪下,这种描述的确很应景。
不过,Altman以前可不是这么说的。他曾预测道,AI很快就能替代中等水平的人类劳动者,导致大规模失业。能够自主行动的AI智能体,下一步可能就是替代人类。
2027年完成构建AGI的计划将推迟
同时,网上一份最新长达53页的PDF,曝光了OpenAI预计在2027年前打造出人类级别AGI的计划,或许能够部分解答「地下室里有什么」的问题。
目前还不知这个透露可靠度有多高,不过文档作者Jackson账号注册于2023年7月,目前就只发布了2条推文,都是昨天发布的。
而且,他主页上的签名是「Jimmy Apples窃取了我的信息」。Jimmy Apples曾多次爆料关于OpenAI模型发布信息。

Jackson表示:「自己将披露收集到的有关OpenAI已推迟在2027年之前创建人类通用级别的AGI的信息」。

摘要中,具体介绍了OpenAI通往AGI的时间线,大致翻译如下:
- OpenAI计划于2022年8月开始训练一个125万亿参数的多模态模型
- 第一阶段是Arrakis,也称为「Q*」。模型于2023年12月完成训练,但由于推理成本过高而取消发布。这就是原本计划在2025年发布的GPT-5,Gobi(GPT-4.5)已更名为GPT-5,因为原GPT-5已被取消
- Q*的下一阶段原为GPT-6,随后更名为GPT-7(原计划于2026年发布),但由于最近马斯克的诉讼将会被搁置
- Q* 2025(GPT-8)原计划于2027年发布,旨在实现完全的AGI
- Q* 2023 = 人类IQ达到48
- Q* 2024 = 人类IQ达到96(延迟)
- Q* 2025 = 人类IQ达到145(延迟)

神经元网络的基础理论:参数计数
「深度学习」这一概念基本上可以追溯到20世纪50年代AI研究的初期。第一个神经网络诞生于上世纪50年代,而现代神经网络只是「更深」而已。这意味着它们包含更多的层——它们要大得多,也要在更多的数据上进行训练。
当今AI领域大多数主要技术都源20世纪50年代的基础研究,并结合了一些工程解决方案,如「反向传播算法」 和「Transformer模型」。
总的来说,AI研究70年来没有发生根本性变化。因此,近来AI能力爆发的真正原因只有两个:规模和数据。
越来越多的人开始相信,几十年来我们早已解决了AGI的技术细节,只是在21世纪之前没有足够的算力和数据来构建AGI。
显然,21世纪的计算机,要比上个世纪50年代的计算机强大得多。当然,互联网数据来源也更加丰富。
那么,什么是参数呢?
它类似于生物大脑中的突触,是神经元之间的连接。生物大脑中有1000个连接。显然,数字神经网络在概念上类似于生物大脑。
那么,人脑中有多少个突触,或「参数」呢?
最常引用的大脑突触数量大约为100万亿个,这意味着每个神经元(人脑中约有1000亿个神经元)大约有1000个连接。
如果大脑中每个神经元有1000个连接点,这意味着一只猫大约有2500亿个突触,一只狗有5300亿个突触。
一般来说,突触数似乎预示着较高的智力,但也有少数例外:
例如,从技术上讲,大象的突触数比人类高,但智力却比人类低。突触数量越多,智力越低,最简单的解释就是高质量数据的数量越少。
从进化的角度来看,大脑是在数十亿年的表观遗传数据的基础上「训练」出来的,人类的大脑是从比大象更高质量的社会化和交流数据中进化出来的,所以我们具备了卓越的推理能力。无论如何,突触数量无疑是非常重要的。
同样,自2010年以来,AI能力的爆炸式增长是,更强算力和更多数据的结果。
GPT-2有15亿个连接,还不如一个小鼠的大脑(约100亿个突触)。GPT-3有1750亿个连接,已经接近猫的大脑。
100万亿参数,AI即可达到人类水平
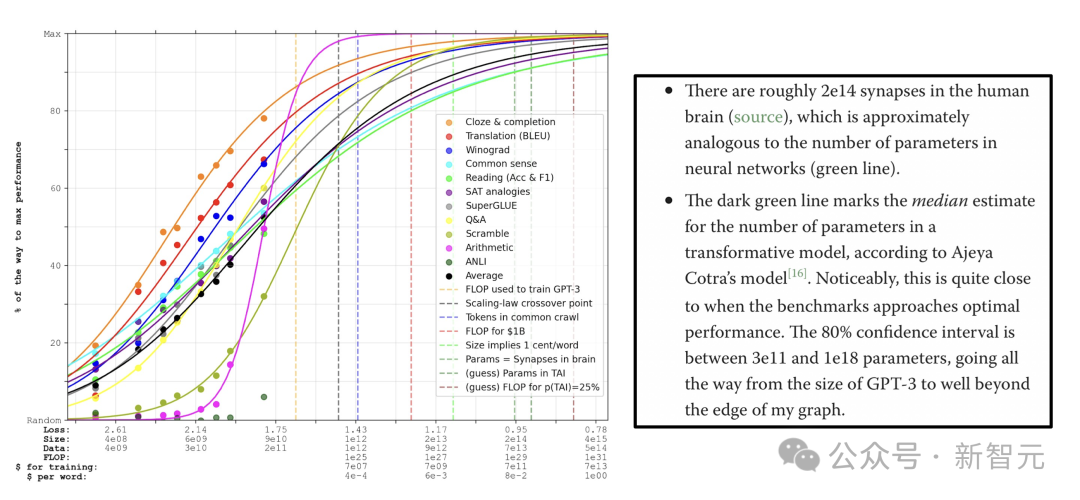
2020年,1750亿参数的GPT-3发布后,许多人对一个比它大600倍、参数为100万亿模型(这一参数与人类大脑的突触数相匹配)的潜在性能进行猜测——

正如Lanrian所解释的,推断结果表明,AI的性能似乎会莫名其妙地达到人类水平。
与此同时,人类水平的大脑大小也会与参数数量相匹配。
他计算的大脑突触数量约是200万亿参数,而不是通常所说的100万亿参数——但这一观点仍然成立,而且100万亿参数的性能非常接近“最佳状态”。
那么,如果AI的性能是可以根据参数数量预测的,而且接近于100万亿参数足以达到人类水平,那么什么时候会发布100万亿参数的AI模型呢?
GPT-5在2023年末实现了初始态AGI,IQ达到48
OpenAI新策略:Chinchilla缩放定律
100万亿参数模型实际上性能不是最优的,不过OpenAI正在使用一种新的缩放范式来弥补这一差距——基于一种叫做Chinchilla scaling laws(缩放定律)的方法。
Chinchilla是DeepMind在2022年初发布的AI模型。

论文地址:https://arxiv.org/pdf/2203.15556.pdf
这篇论文中,暗示了目前的模型明显训练不足,如果计算量(意味着更多数据)大大增加,无需增加参数就能大幅提升性能。
重点是,虽然一个训练不足的100万亿参数模型不是最优的,但如果用更多的数据对其进行训练,其性能就能轻松超越人类水平。
在ML领域,Chinchilla范式已被广泛理解和接受。
但OpenAI总裁Greg Brockman在采访中谈到,OpenAI是如何意识到自己最初的scaling laws存在缺陷,并在此后进行调整,将Chinchilla纳入考虑范围。
地址:https://youtu.be/Rp3A5q9L_bg?t=1323
研究员Alberto Romero曾撰文介绍了的Chinchilla scaling突破。
Chinchilla表明,尽管它比GPT-3和DeepMind自家模型Gopher小得多,但由于在更多的数据上进行了训练,它的性能超过了强大的模型。
尽管预测100万亿参数模型的性能不是最优,但OpenAI非常了解Chinchilla scaling laws。
他们正在将Q*训练成一个100万亿参数的多模态模型,这个模型的计算能力是最优的,而且训练的数据量远远超过了初衷。

Q*:125万亿参数巨兽?
最后,作者透露了一个令人难以置信的信息来源——来自著名的计算机科学家Scott Aaronson。
2022年夏天,他加入OpenAI后,从事了为期一年的AI安全方面的工作。他曾在博客上发表了一些非常有趣的言论。
这篇在2022年12月底的文章——「一封写给11岁自己的信」,讨论了一些实事和Scott在生活中取得的成就。
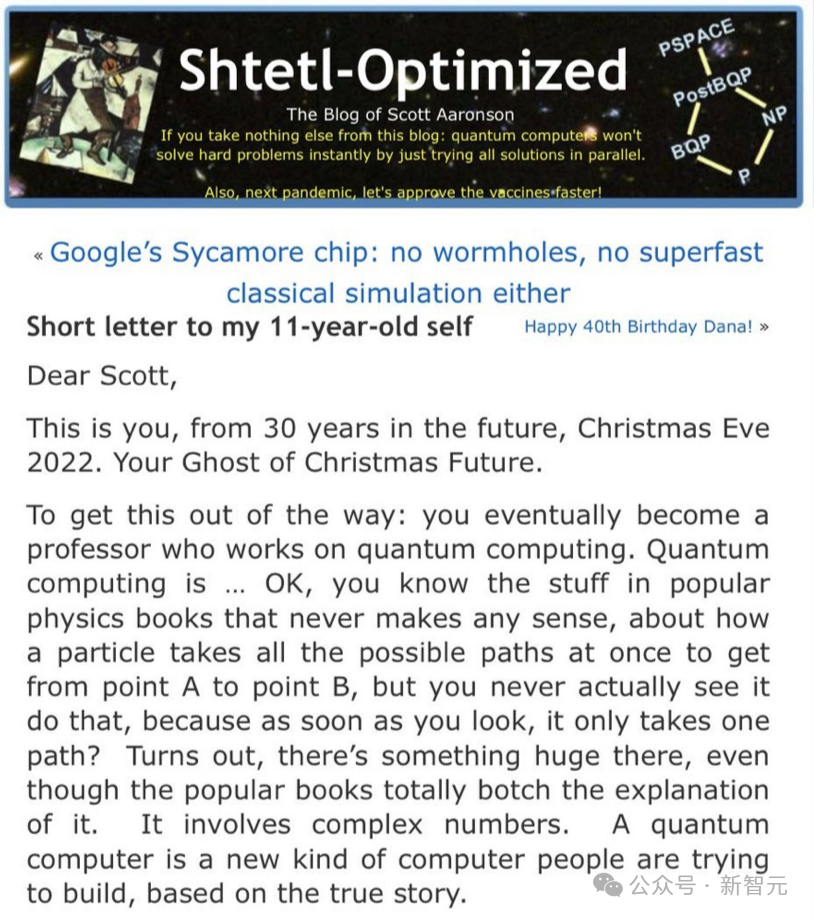
下半部分才是最可怕的部分...
有一家公司正在开发一种人工智能,它填满了巨大的房间,耗费了整个城镇的电力,最近还获得了令人震惊的能力——能像人一样交谈。
它可以就任何主题写论文、诗歌。它可以轻松通过大学水平的考试。它每天都在获得新的能力,但负责AI的工程师们还不能公开谈论。
不过,这些工程师会坐在公司食堂里,讨论他们正在创造的东西的意义。
下周它会学会做什么?它可能会淘汰哪些工作?他们是否应该放慢速度或停下来,以免「怪兽」失控?
但是这并非意味着其他人,可能是更没有顾忌的人,不会最先唤醒「巨兽」吗?是否有义务告诉世人更多关于这件事的信息?还是有义务少说一点?
我——现在的你——正在那家公司工作一年。
我的工作是开发一个数学理论,以防止人工智能及其后继者走向极端。其中「走向极端」可能意味着从加速宣传和学术作弊,到提供生物恐怖主义建议,再到摧毁世界。

这里,Scott指的就是多模态大模型Q*,一个125万亿参数的巨兽。

爆火「Q*假说」牵出世界模型,全网AI大佬热议
去年11月,Q*项目就曾引发这个AI社区热议。
疑似接近AGI,因为巨大计算资源能解决某些数学问题,让Sam Altman出局董事会的导火索,有毁灭人类风险……这些元素单拎出哪一个来,都足够炸裂。
所以,Q*究竟是啥呢?
这要从一项1992年的技术Q-learning说起。

简单来说,Q-learning是一种无模型的强化学习算法,旨在学习特定状态下某个动作的价值。其最终目标是找到最佳策略,即在每个状态下采取最佳动作,以最大化随时间累积的奖励。
斯坦福博士Silas Alberti由此猜测,Q*很可能是基于AlphaGo式蒙特卡罗树搜索token轨迹。下一个合乎逻辑的步骤是以更有原则的方式搜索token树。这在编码和数学等环境中尤为合理。

随后,更多人猜测,Q*指的就是A*算法和Q学习的结合!

甚至有人发现,Q-Learning竟然和ChatGPT成功秘诀之一的RLHF,有着千丝万缕的联系!

随着几位AI大佬的下场,大家的观点,愈发不谋而合了。
AI2研究科学家Nathan激动地写出一篇长文,猜测Q假说应该是关于思想树+过程奖励模型。并且认为Q*假说很可能和世界模型有关!


文章地址:https://www.interconnects.ai/p/q-star
他猜测,如果Q*(Q-Star)是真的,那么它显然是RL文献中的两个核心主题的合成:Q值和A*(一种经典的图搜索算法)。
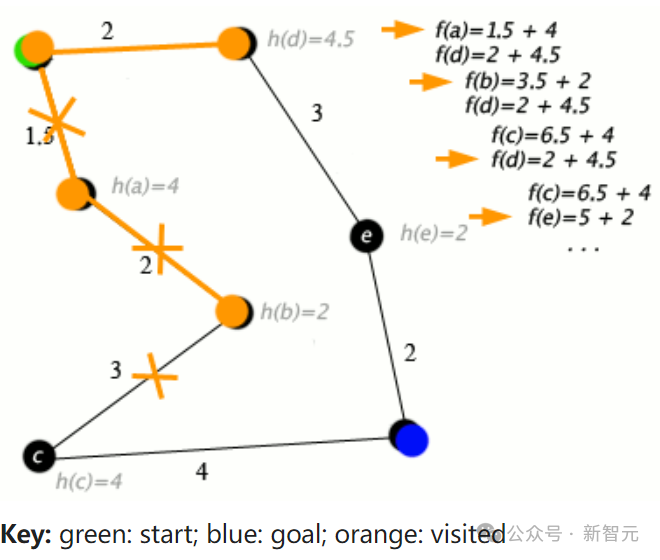
A*算法的一个例子
英伟达高级科学家Jim Fan也认为,Q*令人赞叹,可以和AlphaGo类比。
在我投身人工智能领域的十年中,我从来见过有这么多人对一个算法有如此多的想象!即使它只有一个名字,没有任何论文、数据或产品。
其实,多年来Ilya一直在研究如何让GPT-4解决涉及推理的任务,比如数学或科学问题。
此前,Ilya在这个方向就有多年积累。21年,他启动了GPT-Zero项目,这是对DeepMind AlphaZero的致敬。

GPT-Zero可以下国际象棋、围棋和将棋。而团队假设,只要给大模型更多的时间和算力,假以时日,它们一定能达到新的学术突破。
而且在半年之前,就有硅谷大佬扒出,OpenAI很有可能会将「实时检索」和模型能力结合起来,创造出难以想象的AI能力。
图灵三巨头LeCun则认为,Q*则很可能是OpenAI在规划领域的尝试,即利用规划策略取代自回归token预测。
随后,更是有惊人消息曝出:Q*竟然能破解加密,AI自己在偷偷编程。而OpenAI曾试图就此向NSA提出预警。
如果这个消息是真的,那我们无疑已经无限接近AGI。