以下文章节选自丨新智元
人们总说,OpenAI的奥特曼是营销鬼才。他总能在恰当的时机,公开一些产品新动态让世界为之瞩目、让竞争对手感到胆颤。
3月13日,《华尔街日报》放出了针对OpenAI CTO Murati的专访视频。客观地说,接受此次采访对于OpenAI而言,本身是一次不错的产品公开展示机遇。

在访谈的前半部分,Murati很好地回应了外界对于Sora视频模型生成1分钟短视频的时长花费——也就几分钟到10分钟。
此前有网友推测,Sora生成视频的耗时会非常长,无法取代传统影视工作流。而采访视频无疑给竞争对手以及好莱坞从业者沉重的心理打击。

更令人拍案叫绝的是,Murati在采访中通过一台iPad展示Sora提示词当场生成多个视频,营销手法令人拍案叫绝!
尽管Sora生成的视频还有诸多Bug,但它依然足够惊艳。
比如,瓷器店里行走的公牛,它碰到的盘子竟然支棱起来~

让Sora生成「接受女记者采访的机器人」,结果生成了扛着摄像机的女记者忽然变成了机器人。

拿着手机的小美人鱼,旁边是她的蟹老板助理。

Murati还在现场拉踩竞争对手Runway,直接对标生成「镜头前的两位女记者」。

Sora生成

Runway生成
虽然Runway表现可圈可点,但Sora的效果明显更自然,也更逼真。
不过并非所有公关活动都是机遇,也可以是惨案……
就在多个风光无限的技能输出之后,最令人不可思议的一幕发生了——Murati对Sora的训练数据来源,语焉不详、支支吾吾。
现在已经成为科技圈的热议话题。Murati采访大翻车,在网上掀起了轩然大波。

Murati的「痛苦表情包」Be like——你看我是想回答的样子吗?
《华尔街日报》记者显然有备而来,她要放大招了:「请问Sora是用什么数据训练的?」

Murati接下来的神情,十分值得玩味。
她快速眨了数次眼睛、目光闪烁,思考几秒之后,略带迟疑地给出了一个公关味道十足的答案。
——「我们训练Sora使用的是公开可用的数据,以及经过许可的数据。」

记者并不打算就此放过Murati,她继续出招:「所以,你们是用了YouTube上的视频吗?」
Murati的反应亮了,她似乎毫无准备。
她撇了撇嘴,眼神茫然地望向空中,犹豫了几秒后勉强回应。
——「关于这部分,我不太确定。」
看到这个回答,我直接震惊了N秒有木有!!

记者步步紧逼毫不留情:「那Facebook和Instagram上的视频呢?」
Murati的表情仿佛处于崩溃的边缘。
——「你知道,如果这些平台的数据可以公开使用……对……可以公开使用的话……可能是用了一些数据。但我不确定,真的不太确定。」
「I'm not sure.」
最后她无奈地摊开双手,以“无辜”的眼神暗示记者“差不多得了”。♀️

但记者还在发问:「Shutterstock呢?我知道你们公司和他们有内容版权的合作。」
Shutterstock是一家知名的美国在线图片素材库和音乐素材库网站,在去年与OpenAI签订了内容授权协议。
Murati摇了摇头表示:「关于使用数据的细节,我是不会详细说的,但我们用的数据肯定是公开的,或者授权许可使用的。」

在面对公众舆论监督的镜头面前,仓促上阵的Murati显得那么稚嫩。
也许奥特曼就不该让一位技术官僚接受媒体采访。
她肯定没想到,WSJ的记者会如此咄咄逼人,以至于让她几乎直接掉进坑里。
如果她在镜头前的表述处理不够得当的话,明天OpenAI的法务恐怕就得在法庭加班了。

网友形容Murati的窘迫表现:她绝对会被做成表情包,全网热传。

Murati接受采访到底有多灾难,完整中字字幕视频如下,大家感兴趣可以观看,里边还有我们前文提到的Sora现场演示:
<iframe src="//player.bilibili.com/player.html?aid=1101625297&bvid=BV1aw4m1d7AS&cid=1469173689&p=1&autoplay=0" frameborder="no" scrolling="no" allowfullscreen="allowfullscreen"> </iframe>
训练AI模型数据所面临的巨大版权争议,过去一年已经累积不少了。
OpenAI和Sora更是这个辩论场里边最大的那棵树。
眼看价值数百亿美元的好莱坞电影工业就要被OpenAI收进荷包,视频内容生产者们分文无收,反而被掀了饭碗,直接引发网络舆情轰炸。
看过视频的网友都认为:「她的表情神态证明她正在说谎。」
有网友锐评:这个采访看起来很愚蠢,整个对话仿佛是下面这个样子——
你是坏人吗?
我不是。
你是坏人吧?
呃…不是吧?真不是!
你到底是不是坏人?
听着,我不是坏人……
还有网友展开了微表情分析:眼神飘忽不定不敢目视采访者,心理学表征此人正在说谎。

还有人直言:当你试图说谎的时候,请记住这张脸Be like。

《洛杉矶时报》科技专栏作家Brian Merchant尖锐批评Murati的表现:
「作为OpenAI的CTO如此表现,要么是对自己公司的产品惊人的无知,要么就是在谎言——无论哪种可能,都非常可怕!」

有人直言,对于一家全球最顶尖的人工智能机构,这样的CTO表现可谓失格。
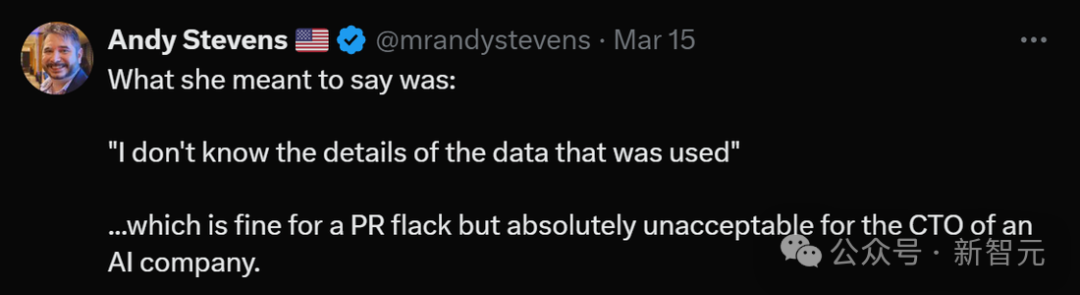
WSJ视频下方有1500+点赞的这条评论:「一个CTO说她不知道数据来自哪里……」

那么问题来了,到底Murati为何要“撒谎”呢?
如果她意识到自己需要通过撒谎来掩盖某些事实,那就说明,她其实早就明白OpenAI的某些做法是在违规的边缘疯狂试探。

Murati今天的一切言论,都有可能在将来的「大型诉讼」当中,成为呈堂证供。
目前,OpenAI与其金主微软正面临着好几场诉讼,多家新闻出版机构与文学作者声称,他们的作品未经许可就被OpenAI用来训练ChatGPT等大模型。

与此同时,还有媒体直接大标题嘲讽Murati在采访中极其不专业的表现。

公司CTO的这个表现,对官司缠身的OpenAI可不是个好消息。
如果CTO无法给出明确的公关式答复,这就证明了,OpenAI的高层们甚至对这个问题根本就没在意,压根没准备话术。
《华尔街日报》在采访视频的最后尝试给OpenAI“找回场子”。他们刊登了一段文字:Murati证实,Shutterstock授权的视频确实包含在Sora的训练集当中。

不过,这则稍显滞后的答复话术并不能证明OpenAI没有从其他地方获取训练数据,无论它是合规or不合规。
那么一切问题的根本在于,我们普通人在公共领域发布的任何言论、上传的各种数据,所属权到底属于个人,还是公有?

杂音之下,我们还是以法律条文作为最终裁量。
就在《华尔街日报》上传这则采访视频的同时,欧盟旗下欧洲议会通过全球首部AI监管法案《人工智能法案》。
法案规定,为了保障当事人的合法权益以及提高大模型的透明度,大模型的提供商应制定并公开用于训练通用模型的内容所足够详细的摘要。

如果美国法律“收拾”不了OpenAI,那么欧盟地区的法律应该可以。
毕竟苹果、微软、谷歌、亚马逊这些大厂都被“收拾”过了……
树大招风OpenAI正在面临严重的信任危机,剧情正朝着死对头马斯克所乐见的方向偏转。刚刚宣布Grok AI开源的他,又可以肆意吟唱:
——OpenAI是一家「谎话连篇的公司」。
相关阅读:

马斯克突然开源Grok:3140亿参数巨无霸,免费可商用
马斯克说到做到:旗下大模型Grok现已开源!代码和模型权重已上线GitHub。官方信息显示,此次开源的Grok-1是一个3140亿参数的混合专家模型——就是说,这是当前开源模型中参数量最大的一个。

Sora还在不断掀起关于人工智能技术的高速发展与现实冲突的现在进行时故事。
AI在影视、游戏、广告传媒这些行业还会掀起怎样的飓风,让我们拭目以待吧!